FM/FFM/DeepFM/PNN算法
背景
目的
旨在解决稀疏数据下的特征组合问题。
为什么进行特征组合?
下面以一个示例引入FM模型。假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。源数据如下:
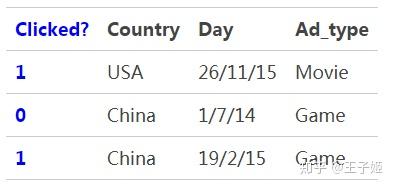
“Clicked?”是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。

由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。数据稀疏性是实际问题中不可避免的挑战。One-Hot编码的另一个特点就是导致特征空间大。例如,商品品类有550维特征,一个categorical特征转换为550维数值特征,特征空间剧增。
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如<“化妆品”类商品,“女”性>,<“球类运动配件”的商品,“男”性>,<“电影票”的商品,“电影”>品类偏好等。
交叉类特征区别
1 FM所实现的特征交叉指的两个特征的共现,比如"用户喜欢军事 并且 物料带有坦克标签"。
2 手动可以计算一些统计意义上的交叉,比如“用户携带的tag与物料携带的tag之间的重合度”。注意,是重合度,不是且的关系。
http://blog.csdn.net/pipisorry/article/details/42167987
FM(Factorization Machines)算法

从公式(1)可以看出,组合特征的参数一共有 n*(n-1)/2个,任意两个参数都是独立的。然而,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是:每个参数 的训练需要大量xi 和xj 都非零的样本;由于样本数据本来就比较稀疏,满足都非零的样本将会非常少。训练样本的不足,很容易导致参数 不准确,最终将严重影响模型的性能。
矩阵分解
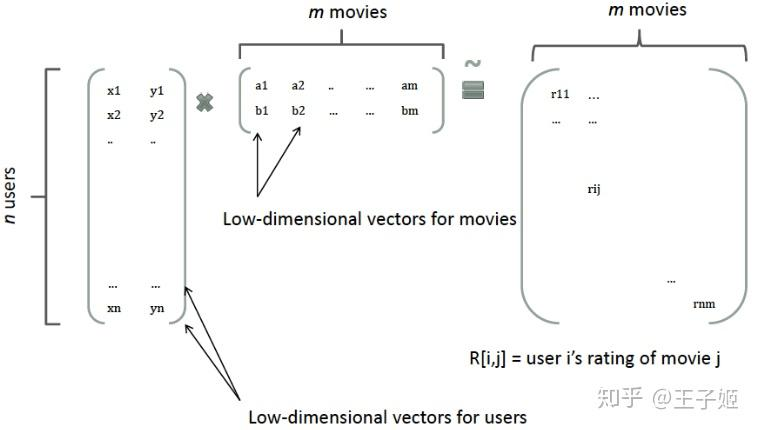

矩阵对角线上面的元素即为交叉项的参数。
FM的模型方程为(本文不讨论FM的高阶形式):
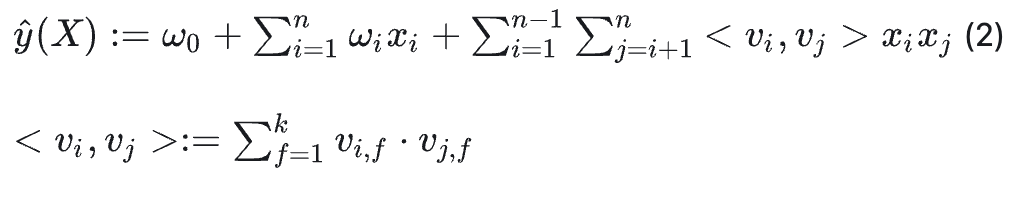
隐向量可以表示之前没有出现过的交叉特征,假如在数据集中经常出现 <男,篮球> ,<女,化妆品>,但是没有出现过<男,化妆品>,<女,篮球>,这时候如果用 w_ij 表示<男,化妆品> 的系数,就会得到0。但是有了男特征和化妆品特征的隐向量之后,就可以通过来求解 <
v男, v化妆品> 来求解。
直观上看,FM的复杂度是 O(kn^2) 。但是,通过公式(3)的等式,FM的二次项可以化简,其复杂度可以优化到 O(kn) 线性时间。推导如下:

隐向量的长度为k(k<<n).
矩阵表示
将二次交互项用矩阵形式表示:
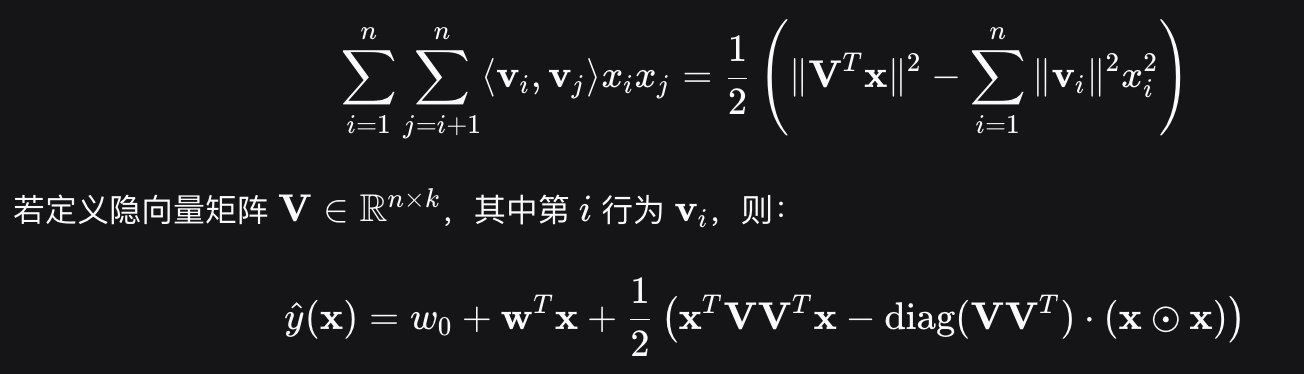
优势
FM能够将模型的最终打分拆解到每个特征和特征组合上,从而能够让我们分析出到底是哪些因素提高或拉低了模型的打分。最重要的是,区别于GBDT那种只能提供特征的全局重要性,FM提供的重要性是针对某一个、某一群样本的,使我们能够做更加精细化的特征分析。
FM存在一阶项,实际就是LR,能够记忆高频、常见模式
Embedding是提升推荐算法“扩展性”的法宝。FM通过feature embedding,能够自动挖掘低频、长尾模式。在这一点上,基于embedding的二阶交叉,并不比DNN的高阶交叉,逊色多少。
美团深度FFM原理与实践
https://zhuanlan.zhihu.com/p/37963267
https://zhuanlan.zhihu.com/p/50426292
FFM(Field-aware Factorization Machines)算法
FFM将域 (Field-aware) 的概念引入其中,因为作者认为一个特征在跟不同特征作交互时,会发挥不同的作用,因此应该具有不同的向量表示。即把相同性质的特征归于同一个 field,同一特征与属于不同域的特征作交互时,具有不同的隐向量表示。
FFM 将隐向量进一步细分,每个特征具有多个隐向量 (等于 field 的数目)。公式如下:
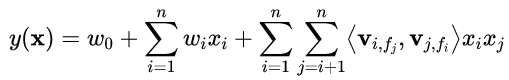
![]()
FM与FFM对比:

[注]:因为公式无法化简,FFM 训练复杂度要远高于 FM,这点在代码实践中有所体现。并且FFM 在特征数较多的场景中,复杂度指数级飙升,难以上线。FM 可保持为线性复杂度,性质较好。
https://zhuanlan.zhihu.com/p/348596108
DeepFM算法
如何利用好低阶和高阶的特征,就是DeepFM最大的特点。
区别:
* 逻辑回归(LR):更多考虑线性特征,缺少特征交叉性和高阶特征
* DNN:考虑了高阶特征,缺少了对于低阶特征的考虑
* CNN:考虑近邻特征的关系。较单一,适合图片分类
* RNN:考虑更多的是数据时序性,较单一
* FM:考虑更多低阶特征,缺少高阶特征
* Wide&Deep:同时考虑了低阶特征和高阶特征,但是低阶特征需要手动交叉生成,对用户不友好
* DeepFM:兼顾了低阶和高阶特征,且计算过程中不需要用户干预
架构上可以拆解成FM部分和DNN部分
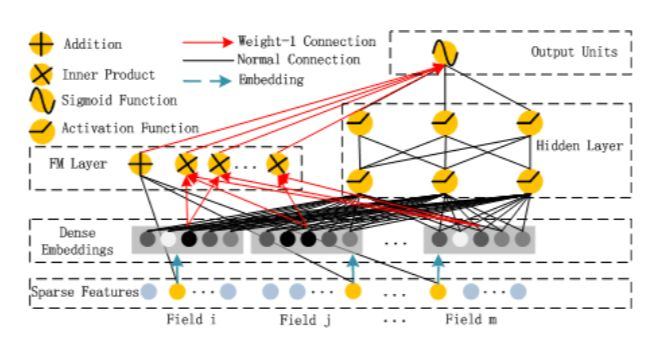
FM层,主要的工作是通过特征间交叉得到低阶特征,以二阶特征为主。这里面指的注意的是,FM算法的特征交叉不是直接拿原始特征相互交叉计算,而是交叉特征因子分解后的结果,这样更能挖掘出特征深层的信息。(也就是先分别映射到同一维度,再元素点乘,最后concate deep部分)
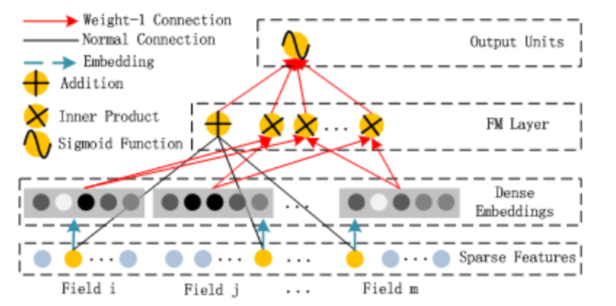
优势与设计思想
-
参数共享:避免重复学习,减少参数量。这是 DeepFM 的核心创新:FM 部分和 Deep 部分共享相同的特征嵌入。
-
端到端训练:FM 和 Deep 部分联合优化,无需预训练
-
互补性:FM 擅长记忆低阶模式,Deep 擅长泛化高阶模式
-
无需特征工程:自动学习特征交互,避免了传统 FM 需要手动构造交叉特征的麻烦
实现
# ---------- first order term ----------
self.y_first_order = tf.nn.embedding_lookup(self.weights["feature_bias"], self.feat_index) # None * F * 1
self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order, feat_value), 2) # None * F
self.y_first_order = tf.nn.dropout(self.y_first_order, self.dropout_keep_fm[0]) # None * F
# ---------- second order term ---------------
# sum_square part
self.summed_features_emb = tf.reduce_sum(self.embeddings, 1) # None * K
self.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K
# square_sum part
self.squared_features_emb = tf.square(self.embeddings)
self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K
# second order
self.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square, self.squared_sum_features_emb) # None * K
self.y_second_order = tf.nn.dropout(self.y_second_order, self.dropout_keep_fm[1]) # None * Khttps://github.com/ChenglongChen/tensorflow-DeepFM
https://mp.weixin.qq.com/s/uOxu4SM_om8ketgq8hd-7Q
PNN模型
“product”相比“add”能更好得捕捉特征间的dependence,因此作者希望在NN中显示地引入“product”操作,从而更好地学习不同Field特征间的相关性,在DNN结构中引入product layer即是这样的一个尝试。
Product-based Neural Network(PNN),PNN的结构非常直观,如下图所示:
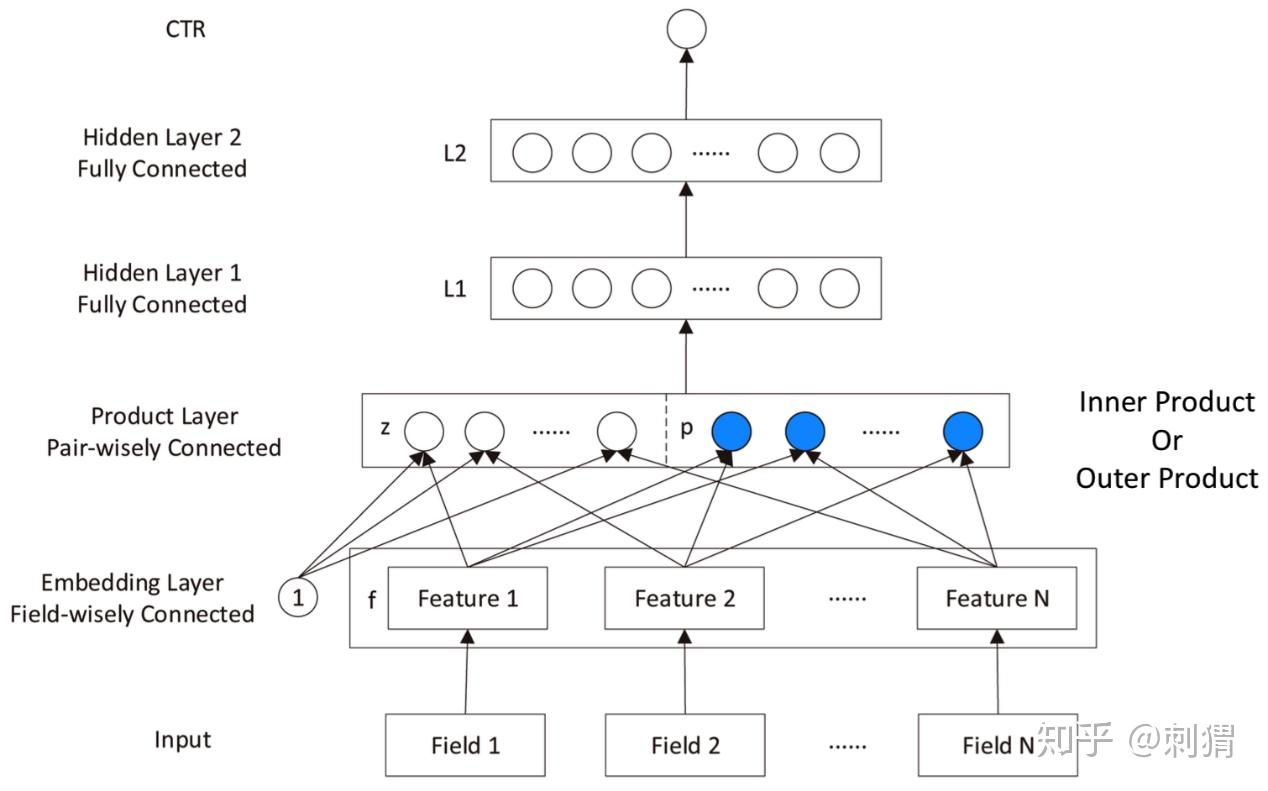
PNN与标准的「Embedding+MLP」差异仅在于引入了Product Layer。上图中Product Layer左边Z部分其实就是将Embedding层学到的嵌入直接原封不动地搬来,右边P部分才是我们讨论的重点。注意,product layer 中每个节点(见蓝色节点)是两两Field的embedding对应的“product”结果,而非所有Field的。
product 函数选择向量内积(inner product)和外积(outer product),对应 IPNN 和OPNN。
IPNN优化:k阶分解,即对右边P部分映射到L1层时,降秩。
from:-柚子皮-
ref:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)