Claude Skills:AI 能力扩展的革命性架构
0. 引言
2025年10月,Anthropic 推出了 Claude Skills(Agent Skills)功能,这不是一次简单的产品迭代,而是对 AI 工具架构的根本性重构。资深开发者 Simon Willison 评价其影响力可能超过 MCP(Model Context Protocol),这一判断并非夸张。Claude Skills 解决了困扰 AI 应用开发的核心问题:如何让通用 AI 模型获得专业能力,同时避免上下文窗口(Context Window)过载导致的性能崩溃。
在过去的 AI 应用实践中,开发者面临着一个两难困境。要让 AI 精通某个专业领域,需要在系统提示词中注入大量领域知识,这会消耗数万个 Token,导致成本飙升和响应速度下降。更糟糕的是,即使当前任务只需要一项专业知识,其他无关的知识也会持续占用宝贵的上下文空间。Claude Skills 通过"渐进式揭露"(Progressive Disclosure)机制彻底改变了这一现状,让 AI 能够按需加载专业能力,实现了效率、成本和性能的三重优化。
本文将深入探讨 Claude Skills 的技术架构、设计哲学和实践应用,帮助你理解这一创新功能如何重塑 AI 工具的使用范式。
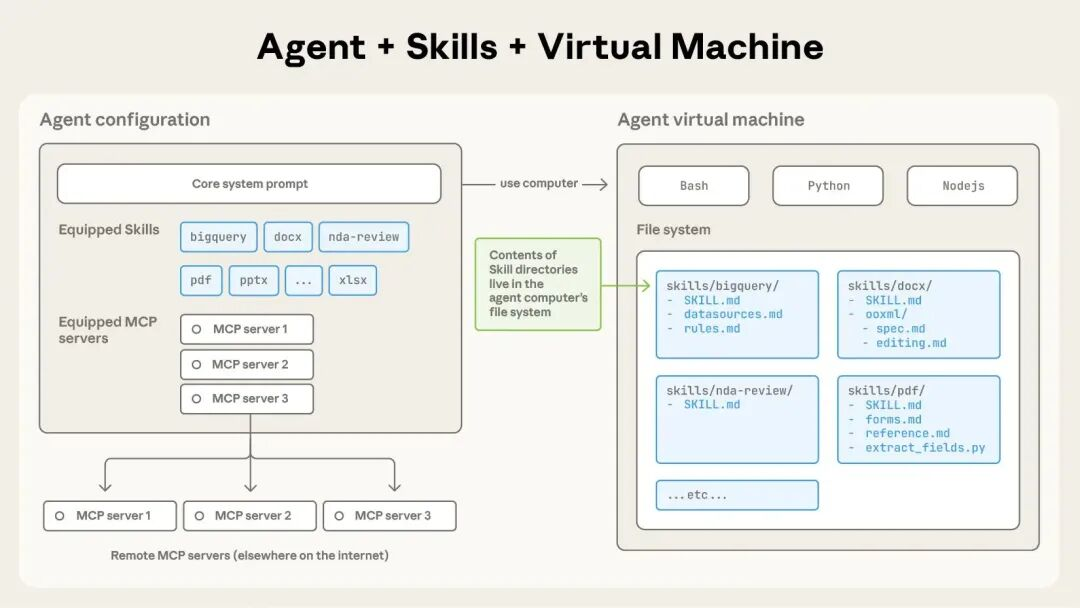
1. Skills 的本质:从知识库到工具箱的范式转变
1.1 什么是 Claude Skills
Claude Skills 本质上是一个包含指令、可执行脚本和参考资源的模块化包。从文件系统的角度看,一个 Skill 就是一个标准化的目录结构,核心组件包括:
- SKILL.md(必需):定义 Skill 的元数据、功能说明和使用指南
- scripts/(可选):存放 Python、JavaScript 等可执行代码
- resources/(可选):包含模板文件、参考文档、数据集等静态资源
这个设计遵循 UNIX “一切皆文件” 的哲学,开发者无需学习新的 API 或对接复杂的平台接口,只需要准备一组文件即可创建强大的专业能力扩展。Anthropic 官方将 Skills 比喻为"员工入职手册"或"标准作业程序"(SOP),这个类比准确地揭示了 Skills 的核心价值:不是让 AI 记住所有知识,而是教会 AI 如何在需要时调用正确的专业能力。
file-renamer/
├── SKILL.md # Skill 定义文件
├── scripts/
│ └── rename.py # 批量重命名脚本
└── resources/
└── patterns.json # 命名规则模板
1.2 Skills 与传统方法的根本区别
要理解 Skills 的创新性,需要明确它与 CLAUDE.md 等传统配置文件的本质差异。CLAUDE.md 是项目级的静态配置,在对话开始时一次性加载到上下文中,适合声明项目架构、编码规范等全局性信息。而 Skills 是任务级的动态工具,只在执行特定任务时才被激活。
更关键的区别在于可执行能力。CLAUDE.md 只能提供文本形式的指导,而 Skills 可以包含真实的可执行代码。这意味着 Skills 不仅能告诉 Claude “应该做什么”,还能提供 “如何精确执行” 的工具。例如,官方提供的 PDF Skill 包含调用 pypdf 库的 Python 脚本,能够直接操作 PDF 表单字段、合并文档、处理加密内容,这些操作远超纯文本指令所能达到的精度和效率。
从实际应用场景来看,这种差异带来了质的飞跃。假设你需要处理100行数据的排序任务,传统方式是让 Claude 生成排序代码,每次都要消耗 Token 生成完整的代码逻辑,还可能出现边界条件处理不当的错误。而使用 Skills,预先编写的 sort.py 脚本可以直接执行,快速、精确、成本低廉。对于确定性任务(排序、格式转换、数据清洗),脚本执行比让模型逐 Token 生成代码要高效几个数量级。
2. 技术架构:三层渐进式加载机制
2.1 Progressive Disclosure 的设计哲学
Claude Skills 最精妙的设计在于其三层渐进式加载机制,这个架构巧妙地平衡了功能丰富性和资源消耗。可以用企业组织结构来类比:公司总经理管理50位不同领域的专家,他不需要每天听取所有人的详细汇报,只需要一份通讯录,记录每个人的姓名和专长摘要。当需要处理并购案时,才邀请法务专家进入会议室详细讨论,任务完成后专家离开,办公桌不会被无关文档永久占据。
Claude Skills 的加载过程精确对应这个模型,分为三个层次:
第一层:元数据索引(Metadata Layer)
启动时,Claude 只读取所有 Skills 的 name 和 description 字段,每个 Skill 仅消耗约100个 Token。这个轻量级索引让 Claude 能够快速浏览所有可用的专业能力,而不会因为详细内容而占用宝贵的上下文空间。就像你翻阅员工名册,只看到"张明:财务分析专家"、"李娜:品牌设计顾问"这样的简要信息。
---
name: 数据清洗专家
description: 处理爬虫数据的清洗、去重和格式标准化。适用于JSON/CSV格式的原始数据,需要去重、填充缺失值、生成统计报表的场景。
---
第二层:指令加载(Instructions Layer)
当 Claude 通过语义分析判断某个 Skill 与当前任务相关时,才通过文件系统读取完整的 SKILL.md 内容。这是一个模型自主决策的过程,Claude 会根据用户请求的语义特征和 Skill 描述进行匹配,自动决定是否"聘请"这个专家。这个设计的关键在于:触发机制完全自动化,用户无需手动指定使用哪个 Skill。
第三层:资源访问(Resources Layer)
Skill 目录下的脚本文件、参考文档、数据模板等深度资源,只在执行阶段才被访问。更重要的是,当 Claude 执行 scripts/ 目录下的 Python 或 JavaScript 代码时,脚本的源代码本身不会被加载到上下文窗口,只有执行结果会返回给模型。这意味着你可以在 Skill 中包含数千行复杂的数据处理逻辑,而不用担心耗尽上下文预算。
2.2 与 MCP 的对比:修正 Token 消耗问题
Simon Willison 指出 Skills 修正了 MCP(Model Context Protocol)的 Token 消耗问题,这个观察切中要害。MCP 作为连接外部工具和服务的协议,在启动时会一次性展开所有可用工具的详细信息,某些复杂的 MCP 服务可能消耗数万个 Token。这就像把公司所有员工都塞进会议室开会,即使你只需要其中一位专家的建议。
Skills 通过渐进式加载将这个成本降低到几十个 Token 的级别。启动时只加载元数据索引,真正的指令内容和执行脚本按需加载。这不仅仅是量的优化,更代表了架构设计思路的质变:从"预先准备所有资源"转向"智能调度资源"。在算力有限的现实约束下,后者才是可持续的发展路径。

3. 核心优势:Automatically, Anytime, Anywhere
3.1 自动化标准化输出(Automatically)
Skills 最直接的价值在于将重复性任务标准化、自动化。在企业环境中,品牌形象的一致性至关重要。传统做法是制定品牌手册,但每个员工(或 AI)对手册的理解和执行存在偏差。通过创建品牌规范 Skill,可以将色彩代码、字体选择、语气风格等规则编码化,确保所有对外文档都符合统一标准。
# scripts/apply_brand_style.py
import json
from docx import Document
from docx.shared import RGBColor
def apply_brand_colors(doc_path, brand_config):
"""应用品牌配色方案到 Word 文档"""
doc = Document(doc_path)
colors = brand_config['colors']
# 应用主标题颜色
for paragraph in doc.paragraphs:
if paragraph.style.name == 'Heading 1':
for run in paragraph.runs:
run.font.color.rgb = RGBColor(
colors['primary']['r'],
colors['primary']['g'],
colors['primary']['b']
)
doc.save(doc_path)
return f"已应用品牌配色到 {doc_path}"
# 读取品牌配置
with open('resources/brand_guidelines.json', 'r') as f:
config = json.load(f)
apply_brand_colors('output.docx', config)
这种能力扩展超越了纯文本指令的局限。代码可以精确地操作文件格式、调用专业库的 API、执行复杂的数据转换,而这些操作通过自然语言指令很难达到同等的精度和可靠性。对于数据分析场景,可以创建标准化的探索性数据分析(EDA)Skill,包含检测离群值、填补缺失值、生成分布图表等步骤,确保每次分析都遵循相同的科学流程。
3.2 按需动态加载(Anytime)
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)