DINOv3在语义分割中的应用:从遥感影像到地物识别的完整实战指南
0. 引言
在计算机视觉的发展历程中,从早期的图像分类到目标检测,再到语义分割和实例分割,任务的复杂度和精细度在不断提升。传统的卷积神经网络虽然在许多任务中表现良好,但在处理全局语义理解和密集预测任务时存在局限性。近年来,Vision Transformer(ViT)架构的出现突破了这一瓶颈,而Meta AI推出的DINO系列模型更是在自监督学习领域取得了重大突破。
DINOv3作为DINO系列的第三代版本,拥有70亿个参数的ViT-7B/16主干网络,在2024年推出了专针对卫星遥感影像的SAT-493M预训练模型。这个模型在包含4.93亿张卫星影像的数据集上进行了大规模自监督学习,使其在遥感影像特征提取方面具有独特的优势。与通用视觉基础模型不同,SAT-493M针对遥感数据的统计特性进行了优化,能够更好地捕捉土地覆盖、地物分布等遥感学科相关的特征。本文将详细介绍如何利用DINOv3的SAT-493M模型进行语义分割任务的训练和部署,特别是针对土地利用和土地覆盖分类的实际应用场景。
1. DINOv3:新一代自监督视觉基础模型
1.1 DINOv3的创新之处
DINOv3是Meta AI在2024年推出的自监督学习模型的第三代版本。与之前版本和其他基础模型相比,DINOv3具有多项创新:
首先是更强的密集特征。传统的自监督学习模型在处理密集预测任务(如分割)时常常存在特征退化问题。DINOv3引入了Gram anchoring这一新的训练目标,专门设计用来保护patch级别的特征在大规模训练中不被破坏。通过在ViT的不同层进行patch对齐,DINOv3确保了从浅层到深层的所有特征都保持良好的质量,这对于语义分割任务特别重要。
其次是规模化的预训练。DINOv3的SAT-493M版本在4.93亿张卫星遥感影像上进行了预训练,这个数据集规模远超之前的同类模型。大规模预训练使得模型能够学习更丰富的遥感影像特征,包括不同季节的植被变化、各种地表覆盖类型的光谱特性等。这种预训练的覆盖广度和深度为下游任务提供了更好的特征基础。
第三是多尺度特征提取。DINOv3在多个transformer层提取特征,使得模型能够捕获不同尺度的信息。浅层特征捕捉的是细节信息和边界特征,而深层特征捕捉的是语义信息和整体结构。这种多尺度特征对于精确的分割边界定位尤为重要。
1.2 Vision Transformer架构基础
为了理解DINOv3,我们需要了解Vision Transformer(ViT)的基本原理。传统的卷积神经网络通过滑动卷积核提取局部特征,这种设计天然地倾向于学习局部的判别特征。相比之下,ViT采用了Transformer架构,这是在自然语言处理领域被广泛验证的架构。
ViT的核心创新是将图像分解成不重叠的patch,每个patch被线性编码为一个向量,然后这些向量序列被输入到标准的Transformer编码器中。通过自注意力机制,ViT能够学习全局的特征依赖关系,而不受限于局部的感受野。这使得ViT在学习全局语义特征方面具有天然优势。
DINOv3中使用的ViT-L/16指的是"Large"大小的ViT,其中"16"表示patch大小为16×16像素。这意味着对于224×224的输入图像,被分为14×14=196个patch。与常见的卷积网络相比,ViT的参数更少但计算量更大,这也是为什么DINOv3倾向于采用蒸馏或冻结特征抽取器的方式应用到下游任务中。
1.3 SAT-493M预训练的特殊性
DINOv3的SAT-493M版本是专门为遥感领域优化的版本。与通用的LVD-1689M预训练版本不同,SAT-493M版本在以下方面进行了专门优化:
数据集特性:SAT-493M使用的数据来自Sentinel-2卫星和其他遥感平台,这些数据具有特定的光谱特性和空间分布规律。相比自然图像,遥感影像往往具有更多的多光谱信息,同时在纹理和色彩分布上与自然图像差异很大。
特征转换参数:SAT-493M的数据预处理参数针对卫星影像进行了优化。具体来说,图像归一化使用的均值和标准差与通用模型不同。标准的ImageNet归一化参数反映的是自然图像的统计特性,而SAT-493M的参数如下:
Mean: (0.430, 0.411, 0.296)
Std: (0.213, 0.156, 0.143)
这些参数反映了卫星遥感影像的真实统计分布,使用这些参数进行数据预处理可以确保输入特征与模型的预训练数据分布保持一致,从而获得最优的特征提取效果。不使用正确的参数会导致特征提取性能下降,这是一个容易被忽视但非常重要的细节。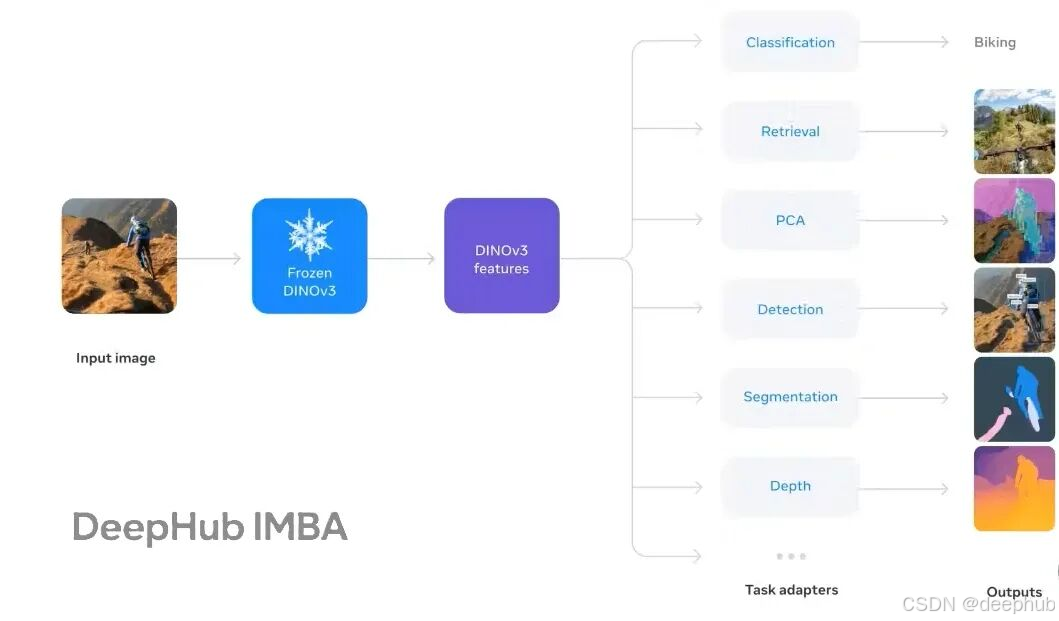
2. 语义分割的原理与实现方式
2.1 语义分割的数学基础
语义分割的核心是像素级的多分类问题。给定一张输入图像I,其尺寸为H×W×3,我们需要输出一张标签图L,其尺寸为H×W,其中L[i,j]表示像素(i,j)所属的类别。
在深度学习框架中,这通常通过编码-解码架构实现。编码器(通常是一个预训练的主干网络如DINOv3)将输入图像映射到高维特征空间,得到特征映射F。由于网络中存在下采样操作,特征映射F的空间尺寸通常小于原始图像。解码器的任务是将这个低分辨率的特征映射上采样恢复到原始分辨率,并在每个像素位置进行分类,输出预测的类别概率。
数学上,语义分割可以表述为:
L p r e d = D e c o d e r ( E n c o d e r ( I ) ) L_{pred} = Decoder(Encoder(I)) Lpred=Decoder(Encoder(I))
其中Encoder输出特征映射,Decoder输出原始分辨率的类别预测。
2.2 编码-解码架构的作用
在DINOv3的语义分割应用中,我们采用冻结编码器的策略。这意味着DINOv3的所有参数都被固定不变,只有解码器(也称为"任务头")部分被训练。这种策略的优势在于:
计算效率:只需要反向传播解码器部分的梯度,大大降低了计算成本。DINOv3-ViT-7B虽然拥有70亿参数,但如果冻结这部分,我们只需要训练相对较小的解码器,内存占用和计算时间都会大幅下降。
特征保护:DINOv3在大规模数据上学习到的特征表示是宝贵的。冻结这些参数确保了已经学到的通用特征不被破坏,特别是当下游任务的标注数据较少时,这种保守的微调策略能够避免过度拟合。
迁移学习效果:研究表明,对于预训练充分的模型,冻结特征抽取器并在下游任务上训练线性分类器往往能够获得与全量微调相近的效果,这被称为"线性可分性"。DINOv3在大规模自监督学习中获得的特征具有很好的线性可分性。
2.3 不同的分割解码器设计
在冻结DINOv3的前提下,解码器的设计灵活性很大。常见的解码器设计包括:
简单的线性分类器:这是最基础的解码器,直接在冻结的特征映射上进行线性变换和softmax分类。对于特征质量很高的模型如DINOv3,简单的线性分类器往往能够获得不错的性能。
多层感知机(MLP)解码器:在特征映射上堆叠几层全连接层,增加了模型的表达能力。这种设计常用于需要更高精度的分割任务。
卷积解码器:使用卷积层而不是全连接层进行上采样和分类。卷积操作能够更好地利用特征映射的空间结构,通常在需要精细分割边界的场景中性能更好。
U-Net风格的解码器:结合多尺度特征和跳跃连接,从编码器的多个层提取特征,这种设计在医学影像分割中被广泛采用。
在本实战案例中,我们采用的是包含卷积层的轻量级解码器,这能在保持计算效率的同时获得较好的分割精度。
3. EuroSAT数据集与实际测试
3.1 数据集基本信息
EuroSAT是一个在遥感领域被广泛使用的标准基准数据集。该数据集由德国弗莱堡大学在2019年发布,源自欧洲地球观测计划Copernicus的Sentinel-2卫星遥感数据。EuroSAT包含总计27000张图像,覆盖欧洲的34个国家,这些图像都经过了精心的地理位置标注和类别标注。
数据集的设计目的是为了促进遥感影像的土地利用和土地覆盖(LULC)分类研究。在地理信息系统和城市规划领域,准确的LULC信息对于资源管理、环境监测、城市扩展分析等都至关重要。EuroSAT的出现提供了一个标准化的评估平台,使得不同研究者开发的算法能够在同一基准上进行公平比较。

3.2 数据集的构成和特性
EuroSAT数据集包含10个不同的土地覆盖和土地利用类别。这10个类别的选择涵盖了欧洲常见的主要地物类型,代表性和多样性兼具:
植被类:包括年生草本植物(Annual Crop)、多年生作物(Perennial Crop)、草本植被(Herbaceous Vegetation)和森林(Forest)。这些类别捕捉了自然和半自然植被的主要变异,从农业用地到自然生态系统都有覆盖。
建筑和基础设施类:包括工业区(Industrial)、住宅区(Residential)和高速公路(Highway)。这些类别代表了人类活动改造的景观,反映了城镇化和基础设施发展。
水体:包括河流(River)和海洋或湖泊(Sea and Lake)。虽然水体看起来简单,但在Sentinel-2卫星的不同光谱波段上表现出不同的特征,对分类算法也构成了挑战。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)