AI智能体全栈部署指南:从工具到生产环境的完整路径
目录
引言
部署一个AI智能体,远比调用一个API复杂。它需要你掌握一套融合了大模型原理、编程框架、基础设施、运维实践的综合技术栈。
本文将系统梳理智能体部署的全栈知识体系,从核心概念到具体工具,再到分阶段的学习路径,帮助你在复杂的技术生态中找到清晰的方向。
一、必备知识概念
在动手部署之前,你需要理解以下核心概念,它们是智能体运行的底层基础。
1.1 大语言模型核心原理
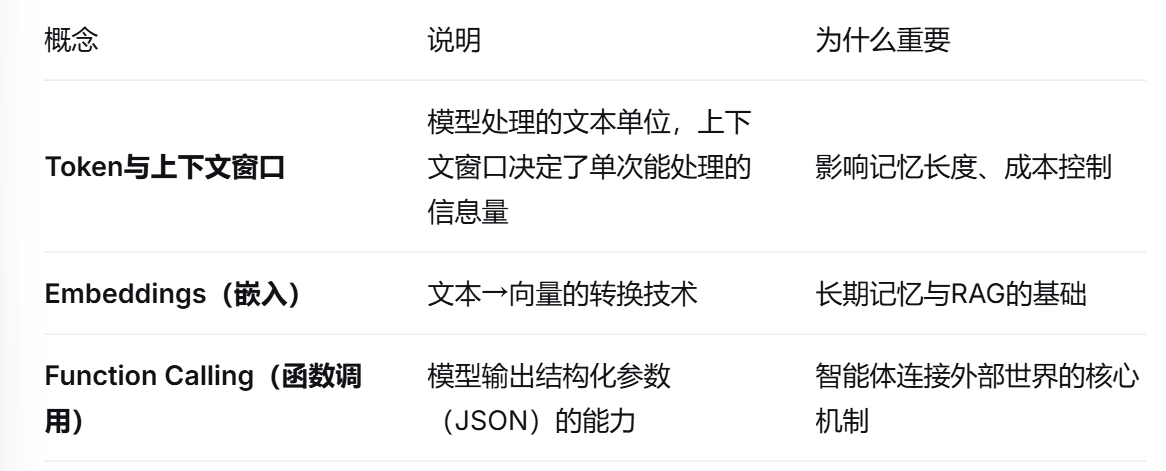
1.2 提示工程
智能体的行为逻辑完全由提示词驱动:
-
系统提示词:定义智能体的角色、能力边界、输出格式
-
思维链(Chain of Thought, CoT):引导模型分步推理,避免逻辑跳跃
-
ReAct 模式:让模型交替输出“思考”和“行动”,是实现规划与执行的经典范式
1.3 检索增强生成(RAG)
当智能体需要访问私有数据或实时信息时,RAG是核心机制:
-
分块策略:如何将文档切分成合适的片段
-
向量检索:相似度搜索(余弦相似度)的原理
-
元数据过滤:在检索时按时间、类别等条件筛选
1.4 异步编程
智能体在执行多步任务如同时查询多个API或处理多用户请求时,需要异步能力:
-
理解
async/await模式 -
避免因IO操作(API调用、数据库读写)阻塞整个程序
1.5 状态管理
智能体本身是无状态的,但任务执行需要状态:
-
短期记忆:当前对话/任务上下文
-
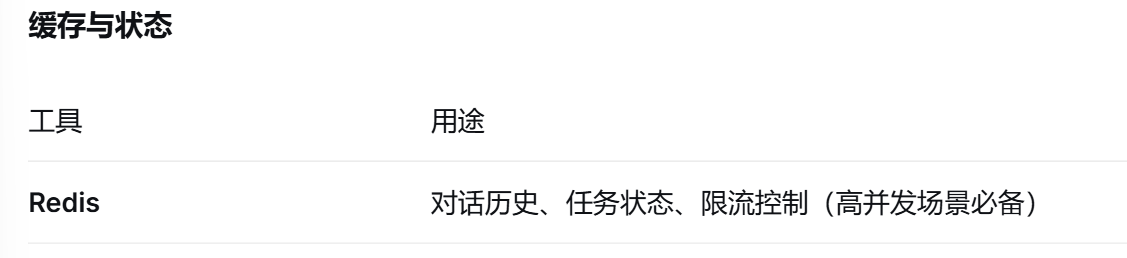
长期记忆:跨会话持久化(向量数据库、Redis)
-
需要掌握如何通过对话历史、缓存来维持状态
二、核心工具栈
根据部署层次,工具可以分为四层:开发框架、基础设施、模型服务、可观测性。
2.1开发框架层
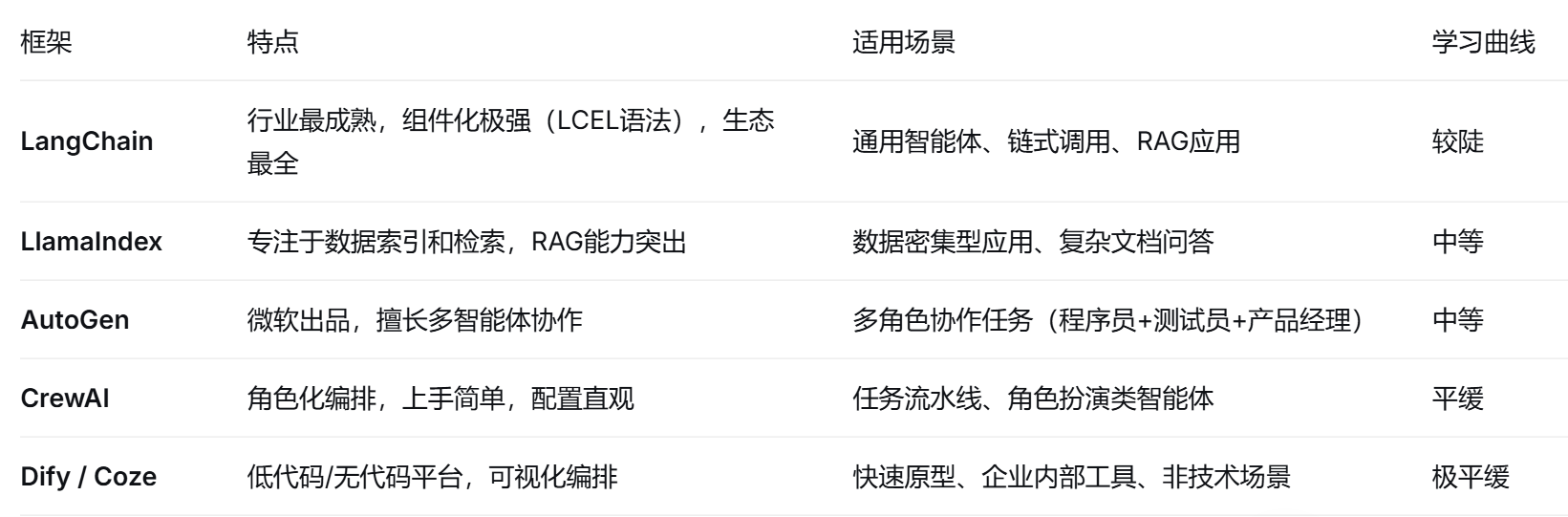
2.2基础设施层
向量数据库(长期记忆)
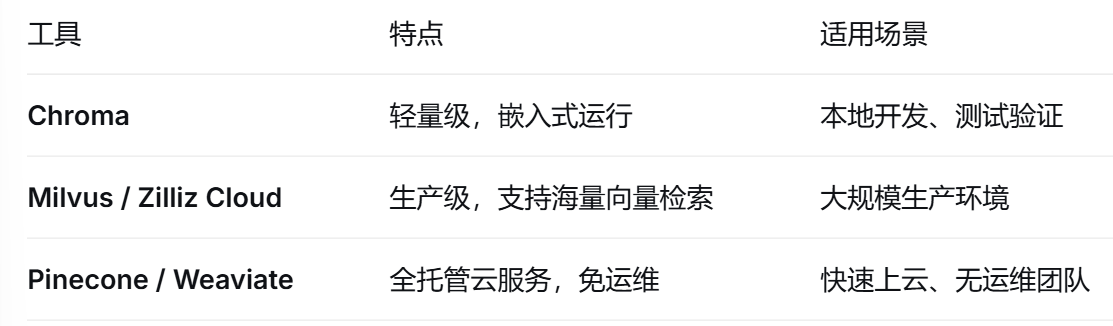
2.3模型服务层

2.4可观测性层
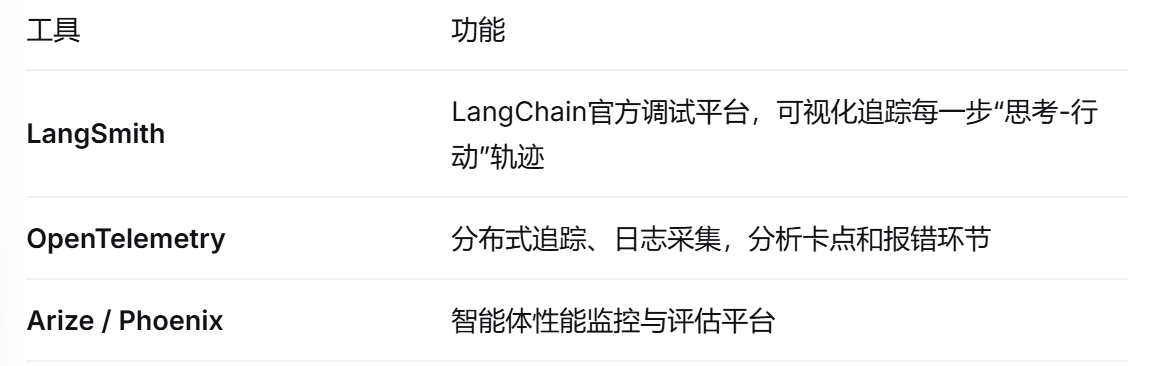
三、四阶段学习路径
根据你的目标和背景,可以选择不同的切入路径。
3.1 阶段一:基础原型
目标:快速体验智能体逻辑,理解工作流程
工具:Coze 或 Dify
学习内容:
-
可视化工作流编排
-
知识库配置(RAG)
-
插件(Tools)接入
-
变量与记忆管理
产出:一个能对话、能检索文档、能调用简单API的智能体
3.2 阶段二:单智能体开发(代码入门)
目标:编写一个能调用自定义API的智能体
语言:Python(首选)
框架:LangChain 或 CrewAI
核心代码实践:
# 示例:定义Tool并构建Agent
from langchain.tools import tool
from langchain.agents import create_react_agent
@tool
def search_weather(city: str) -> str:
"""查询指定城市的天气"""
return f"{city}天气晴朗,25℃"
# 构建Agent Executor
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)学习要点:
-
定义
Tool类 -
构建
Agent Executor -
配置
function_call -
理解 ReAct 模式的输出
3.3 阶段三:生产级部署
目标:高并发、高可用、可扩展的智能体服务
3.3.1 服务化封装
技术:FastAPI
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Request(BaseModel):
input: str
session_id: str
@app.post("/agent")
async def run_agent(req: Request):
# 加载会话状态
# 执行Agent
# 返回结果
return {"response": result}3.3.2 流式响应
技术:Server-Sent Events (SSE) 或 WebSocket
让智能体像ChatGPT一样一个字一个字地输出,避免长时间等待。
3.3.3容器化与编排

3.3.4 状态持久化
-
使用 Redis 存储会话状态和对话历史
-
使用向量数据库存储长期记忆
3.4 阶段四:多智能体系统
目标:多个Agent分工协作,完成复杂任务
框架:AutoGen 或 LangGraph
核心挑战:
-
通信协议设计:Agent间如何传递消息
-
协作收敛控制:如何防止Agent无限聊下去
-
任务分配策略:谁负责什么
-
错误处理与恢复:某个Agent失败后如何处理
四、从零开始实操指南
4.1 非技术背景:快速起步
-
注册 Dify 或 Coze 账号
-
创建新应用,选择“智能体”类型
-
配置知识库(上传文档)
-
添加插件(如搜索、天气)
-
设置提示词和变量
-
发布并测试
4.2 技术开发者:经典起步路径
4.2.1本地环境搭建
# 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 下载模型
ollama pull llama3.2
# 安装LangChain
pip install langchain langchain-community langchain-ollama4.2.2 第一个ReAct Agent
from langchain.ollama import ChatOllama
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import tool
llm = ChatOllama(model="llama3.2", temperature=0)
@tool
def get_current_time() -> str:
"""获取当前时间"""
from datetime import datetime
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
tools = [get_current_time]
# 创建Agent(需要定义提示词模板)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 运行
result = agent_executor.invoke({"input": "现在几点了?"})
print(result)关键:打印出每一步的日志,亲眼看到它如何“思考”和“行动”。
4.2.3 接入更多工具
-
搜索API(SerpAPI、Tavily)
-
数据库查询
-
代码解释器
-
企业内部API
4.2.4添加长期记忆
from langchain.memory import ConversationBufferMemory
from langchain_community.vectorstores import Chroma
# 使用向量数据库存储历史
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)4.2.5 服务化部署
-
FastAPI封装
-
Docker打包
-
部署到云服务器或Kubernetes
五、调试与优化指南
5.1常见问题与解决方案

5.2 调试工具
-
LangSmith:追踪完整的执行轨迹,查看每一步的输入输出
-
本地日志:打印
Thought、Action、Observation的完整内容 -
单元测试:对每个工具单独测试,确保其稳定可靠
5.3 性能优化
-
缓存:相同查询结果缓存(Redis)
-
并行执行:无依赖的子任务并行调用
-
模型选择:简单任务用小模型(如GPT-3.5),复杂任务用大模型
-
流式响应:首字延迟对用户体验影响最大
总结
部署AI智能体需要掌握的知识体系可以概括为:
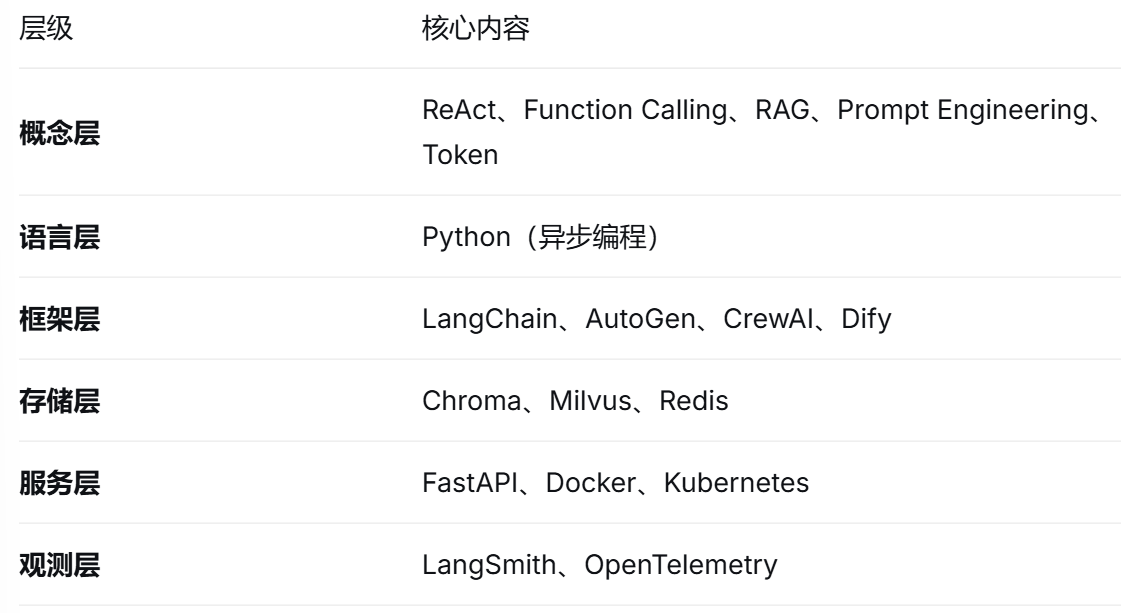
建议起步方式:
-
若目标是快速落地业务:从 Dify/Coze 入手
-
若目标是深入技术:从 LangChain + Ollama 的本地ReAct Agent开始,逐步扩展到生产级部署
掌握智能体部署,意味着你将有能力将大模型从“对话工具”升级为“自主行动主体”。这是一条充满挑战但回报丰厚的路径,希望这份指南能为你提供清晰的指引。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)