(2026|ICLR Oral|首尔大学,扩散模型,扩散线索转实例边缘,实例涌现点,自注意力边界散度,单步自蒸馏)TRACE:扩散模型是实例边缘检测器
TRACE: Your Diffusion Model is Secretly an Instance Edge Detector

论文地址:https://arxiv.org/abs/2503.07982
项目页面:https://shjo-april.github.io/TRACE/
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
高质量的实例分割与全景分割传统上依赖于昂贵的像素级标注(如掩码、边界框或点),这些标注成本高昂、标注者间存在不一致性,且难以规模化。无监督和弱监督方法虽能减轻标注负担,但受限于语义主干网络和人为偏见,常产生合并或碎片化的输出。
本文的核心洞察是,文本到图像扩散模型中的自注意力图在去噪早期便编码了实例感知的线索。
- 如下图 (a) 所示,即使有明确的文本提示,交叉注意力也无法可靠地分离相邻物体;而特定时间步的自注意力则揭示了实例级别的结构。
- 在去噪过程中,模型从噪声过渡到实例级结构,再过渡到语义内容。
- 这引出了一个核心问题:扩散模型的自注意力能否本身就成为无需标注的实例级边缘图来源?
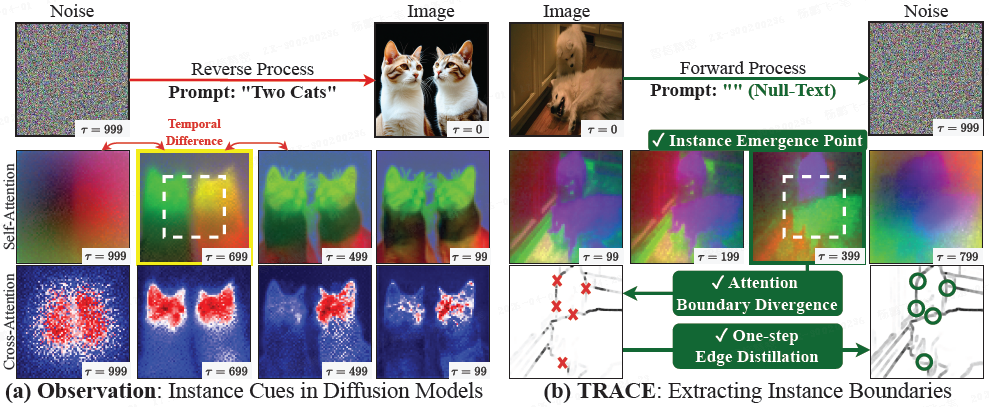
TRACE(TRAnsforming diffusion Cues to instance Edges,将扩散线索转化为实例边缘)正是为解答这一问题而设计,它直接从预训练的文本到图像扩散模型中解码实例边界。如图1(b)所示,
- TRACE 首先通过测量时间散度来识别 实例涌现点(Instance Emergence Point,IEP),选择实例结构最突出的时间步。
- 随后应用 注意力边界散度(Attention Boundary Divergence,ABDiv),通过评分自注意力图中纵横方向的差异来生成初始边缘图。在此阶段,同一物体内部的像素具有几乎相同的自注意力分布,而不同物体的像素则差异显著;这种差异在真实实例边界处达到峰值,为实例边缘提取提供了直接信号。
- 为降低测试时逐张图像前向传播的计算成本,这些边缘被提炼成一个单步预测器,该预测器结合了扩散主干网络和一个边缘解码器。
- 生成的边缘作为下游分割方法中的边界先验,通过沿实例边界分割合并区域,引导传播过程以清晰分离相邻物体,如下图所示。
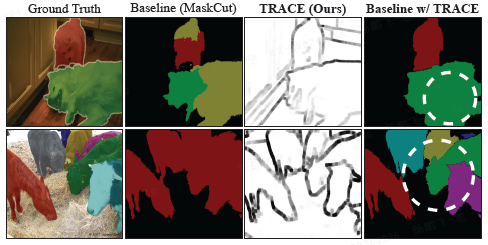
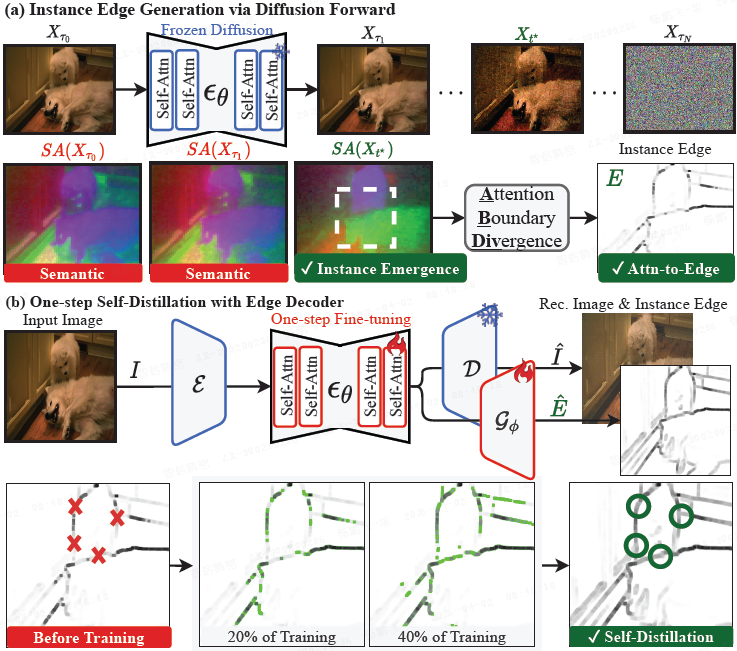
图 4:TRACE 概述。
- (a)扩散前向通过 KL 峰值定位 实例涌现点(IEP) t*,并提取实例感知注意力 SA(X_{t*});注意力边界散度(ABDiv)将其转换为伪边缘图 E。
- (b)在 t=0 时进行 一步自蒸馏,使用 E 训练边缘解码器 G_ϕ,掩蔽不确定像素。从 E 开始训练可填补碎片化边缘中的空隙(绿色圆圈),并生成连通边界 ˆE (预测的边缘图)。在推理时,TRACE 在单次传递中预测 ˆE,无需 IEP 或 ABDiv。
3. 方法
3.1 背景
模型。
- 扩散模型与流匹配模型通过从噪声到数据的逆向过程生成图像。尽管两者优化目标不同,但它们都使用带有自注意力和交叉注意力的 Transformer 主干网络。本文统称它们为扩散模型,因为 TRACE 与两者兼容。
- 在典型的文本到图像实现中,VAE 编码器将输入图像映射为隐变量,去噪网络在文本嵌入条件下迭代预测噪声,VAE 解码器将生成的隐变量还原为图像。TRACE 仅读取扩散模型的自注意力图,无需文本提示。
自注意力收集与聚合。
- 对于时间步的隐变量,本文计算查询(query)和键(key),得到每个注意力头、每个模块的自注意力图。
- 为了融合来自不同模块、不同空间尺度的注意力图,本文将所有图上采样到最大分辨率后取平均。本文使用 PyTorch 前向 hooks 实现这一过程,在不影响模型输出的情况下收集并聚合自注意力图。
3.2 识别实例感知的去噪步
本文提出 实例涌现点(IEP),即自注意力图在去噪轨迹中真正变得实例感知的时刻。
- 去噪早期,自注意力图近乎噪声;随后,连续时间步之间的 KL 散度急剧上升,其峰值对应清晰物体边界的出现;之后散度逐渐下降,物体形状趋于稳定而语义继续细化。
- 在反演过程中,轨迹顺序相反:语义 → 实例 → 噪声。
本文选择 KL 散度最大的时间步 作为实例涌现点。
![]()
- KL 散度是自然选择,因为自注意力图的每一行都是一个概率分布,其对数敏感性(log-scale sensitivity)能够放大与边界涌现直接相关的细微变化。
- 实践中,本文采用固定的 100 步反演步长以平衡效率与精度。
3.3 从自注意力中提取实例边缘
同一实例内部的相邻像素具有相似的自注意力分布,而跨越实例边界的像素则差异显著。本文将这一对比转化为边缘图,提出 注意力边界散度(ABDiv),一种简单的非参数评分方法。
ABDiv 作用于实例涌现点处的自注意力图,对于像素(i, j),通过聚合四邻域的对向散度来计算每个像素的边缘响应(如下图所示)。默认采用四邻域(左/右、上/下),八邻域虽精度相近但计算量翻倍。
![]()

3.4 带边缘解码器的单步自蒸馏
从实例涌现点的自注意力图出发,通过 ABDiv 获得初始边缘图。本文将边缘分数 > μ + σ 的像素标记为边缘,将边缘分数 < μ − σ 的标记为内部,其余标记为不确定,仅用确定的边缘和内部像素作为监督信号,以提升训练质量。
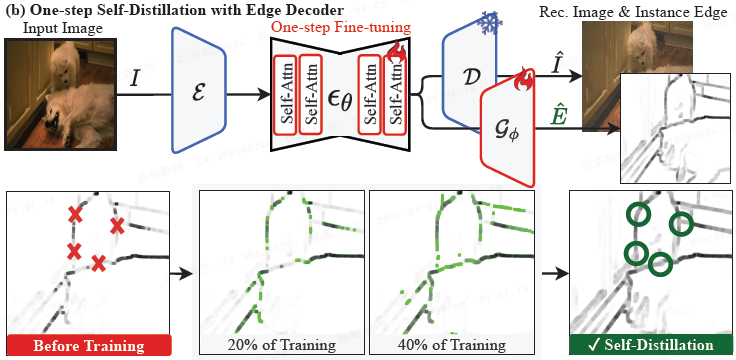
为实现实时推理,本文通过低秩适配(LoRA)微调扩散主干网络,并联合训练一个边缘解码器 G_ϕ。这不仅能避免在推理时逐张图像执行 IEP 和 ABDiv,解码器还能学习补全碎片化的边缘。
训练目标包括图像重建损失和边缘 Dice 损失:
![]()
![]()
其中,E 和 ^E 分别为 ABDiv 生成的伪边缘图与边缘解码器 G_ϕ 预测的边缘图。
训练完成后,单次前向传播即可生成连续精确的边缘图。
3.5 使用实例边缘进行语义到实例掩码的细化
本文将生成的实例边缘作为边界先验,用于正则化和完善分割掩码。
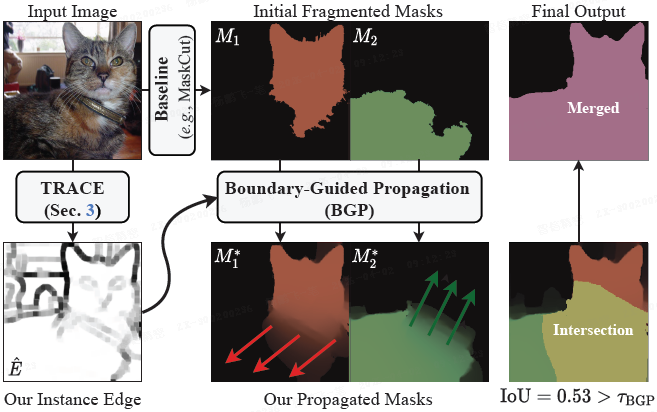
受相关工作启发,本文设计了 边界引导传播(Boundary-Guided Propagation,BGP):
- 将实例边缘视为分隔线,通过连通组件分析赋予不同实例以唯一标签;
- 随后在实例边界内部传播掩码以填补空洞、平滑区域;
- 最后迭代合并交并比超过阈值的重叠掩码,生成完整的实例掩码。
4. 实验
4.1 实验设置
为公平比较,本文遵循标准实验协议,所有实验均在单张 NVIDIA A100 GPU 上运行。
Stable Diffusion 3.5 Large(SD3.5-L)作为默认主干网络,在评估的五种扩散模型中表现最佳。
主要基准数据集为 VOC 2012 和 COCO。
4.2 无监督实例分割(UIS)
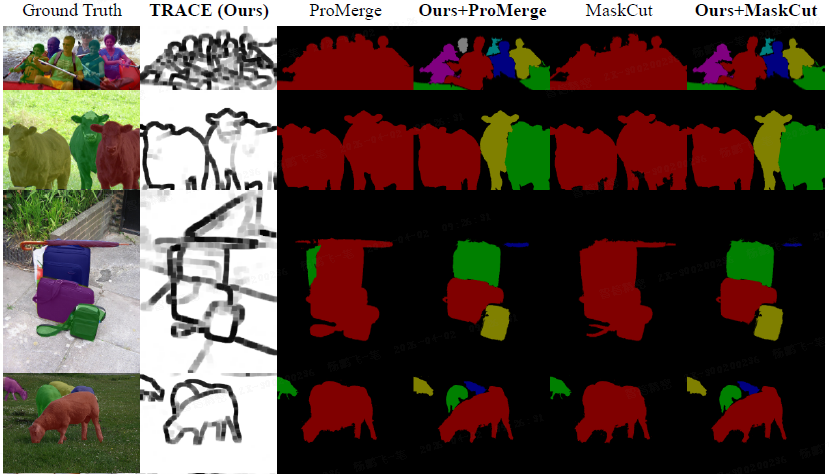
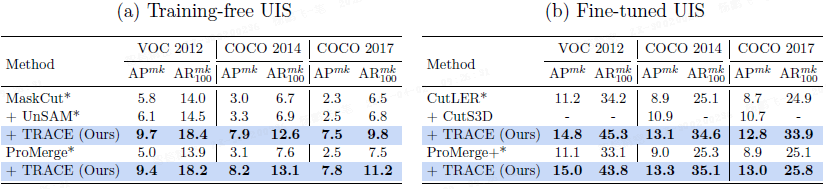
TRACE 在无需训练或微调的情况下,对现有无监督实例分割方法(如 MaskCut、ProMerge)生成的掩码进行细化(refinement),持续提升性能。平均精度(AP)提升幅度为 +3.6 至 +5.3。与基于深度先验的方法相比,TRACE 在 COCO 上取得了更高的 AP,凸显了扩散驱动实例边缘的优势。
4.3 弱监督全景分割

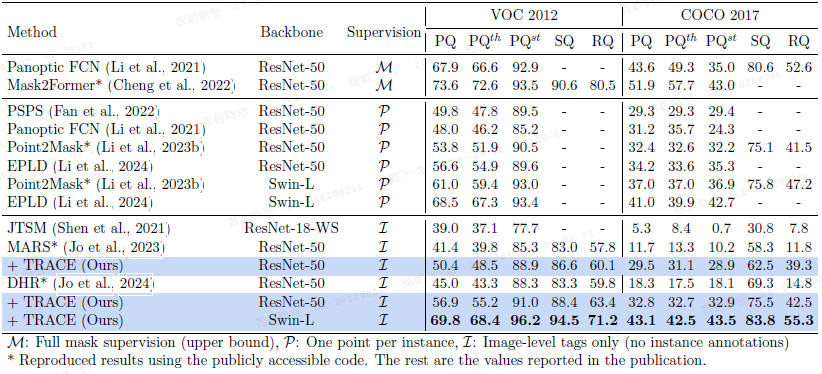
本文利用实例感知边缘(instance-aware edges),对标签监督方法(如 DHR)生成的语义掩码进行细化,形成伪全景掩码,随后按标准协议训练 Mask2Former。
结果显示,DHR + TRACE 仅使用图像级标签,即在 VOC 和 COCO 上超越了使用点监督的方法(如 Point2Mask、EPLD),表明 TRACE 提供的实例几何信息正是标签监督所缺失的关键。
4.4 消融研究
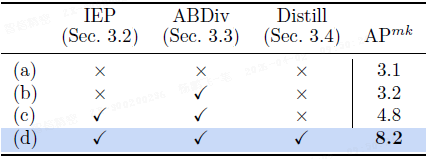
模块消融。实验验证了各模块的作用:
- 仅使用 ABDiv 在语义时间步上几乎无增益;
- 引入 IEP 后,ABDiv 能有效捕获实例边界;
- 加入单步自蒸馏后,不仅消除了逐张图像的 IEP 和 ABDiv 计算,将延迟从 3682ms 降至 45ms(加速约 81 倍),还增强了边缘的连通性。
自蒸馏中的重建损失。在单步自蒸馏中,同时优化边缘损失和图像重建损失,能稳定训练、抑制伪影,并在不增加推理成本的情况下提升准确率和感知质量(AP^mk:8.9 → 9.4; SSIM:0.71 → 0.83)。
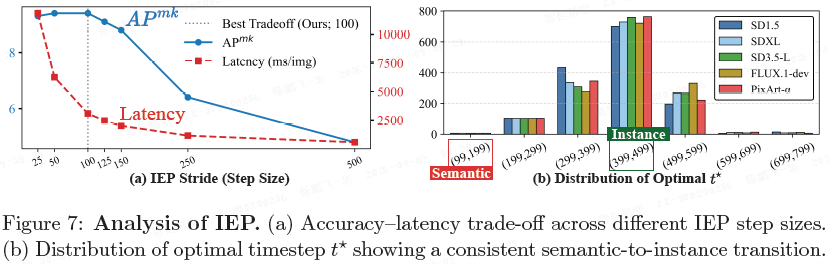
实例涌现点分析。
- 将反演步长设为 100 步,能在保持 AP 约 9.4 的同时,将 IEP 搜索时间控制在约 3s。
- 最优时间步在不同扩散模型间高度集中,表明语义到实例的转变具有模型无关性,支持使用固定步长。
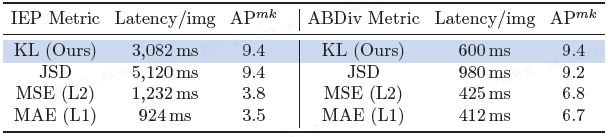
KL 散度对比。
- 与 Jensen-Shannon 散度相比,KL 散度在达到相似 AP 的同时延迟更低;
- 与 L2、L1 损失相比,KL 散度的精度显著更高,验证了其在平衡精度与效率方面的优势。
5. 讨论
5.1 扩散模型 vs. 非扩散主干网络
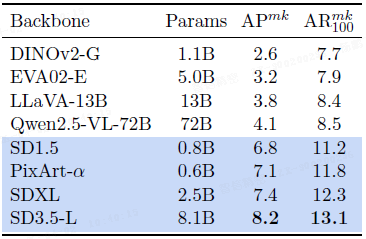
在固定无监督实例分割基线(ProMerge)下,本文将 TRACE 应用于不同视觉主干网络。
- 结果显示,扩散模型显著优于非扩散模型(如 DINOv2、EVA02、LLaVA、Qwen 等)。
- 原因在于,在实例涌现点处,扩散模型的自注意力会沿物体边界收紧;而非扩散主干网络仅能捕获语义相似性,无法分离相邻实例。TRACE 正是利用了扩散模型在IEP处边界对齐的自注意力。
5.2 为何无需标注的实例边缘有效?
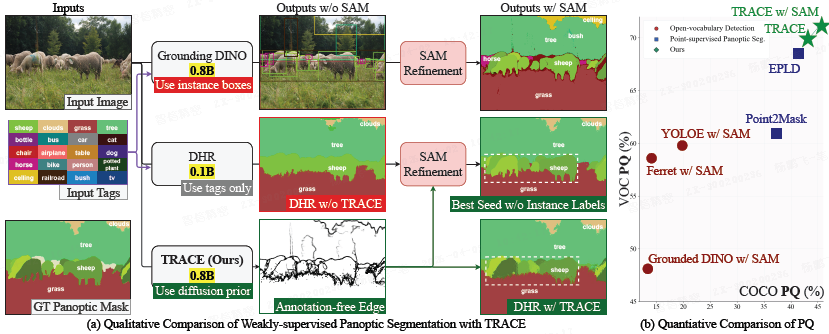
当前实例与全景分割的常用思路是结合开集检测器与 SAM,由检测器提供实例框,SAM 精修得到掩码。但这类流程仍依赖边界框标注,且在多物体、文本提示模糊的场景下易失效。
TRACE 提供了一条不同路径:直接从扩散自注意力中提取实例边缘,无需任何实例监督,却能实现清晰的物体分离(如上图所示)。这些边缘可作为 SAM 的高质量种子,组合效果超越所有有监督的开集基线。同时,当与标签监督的语义模型结合时,TRACE 提供了缺失的实例几何信息,将语义输出转化为完整的全景掩码,在 VOC 和 COCO 上超越了使用点监督的方法。
5.3 传统边缘检测器的局限
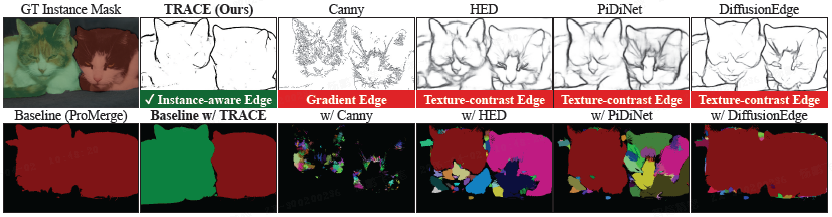
本文将 Canny、HED、PiDiNet、DiffusionEdge 等传统边缘检测器的输出替换到 BGP 流程中,结果 AP 从 TRACE 的 9.4 大幅下降至 1.2–4.3。这表明传统边缘检测器旨在预测 RGB 强度变化轮廓,而非实例边缘,因此对纹理和光照敏感,与实例分割的目标不匹配。
5.4 计算开销

TRACE 在不同设置下引入的额外成本很小。在训练阶段,使用 SDXL 或 SD3.5-L 在 ImageNet 上微调分别耗时 8 天和 10 天。在测试阶段,对 VOC 和 COCO 的推理时间仅为 0.1–2.4 小时,显存占用 20–32 GB(A100)。对于训练时无需微调的无监督实例分割,TRACE 仅增加约 6% 的运行时开销。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)