机器学习进阶(10):随机森林
第十篇:随机森林——用多棵树解决过拟合的魔法
前面我们讲了决策树,它直观、易理解,但有一个很明显的问题:容易过拟合。
过拟合的意思就是:模型在训练集上几乎完美,但在新数据上表现不佳。
因为一棵树会把训练集里的每一个小波动、噪声甚至偶然规律都记住,泛化能力就差。
随机森林(Random Forest)就是为了解决这个问题而出现的。
1. 随机森林的直观思路
你可以把随机森林想象成:
“不要只问一棵树的意见,问一群树,然后让它们投票决定结果。”
每一棵树都是一颗单独的决策树,可能结构不同,可能看到了不同的训练数据或特征。
当你预测一个新样本时:
- 每棵树给一个预测结果
- 最后多数票决定最终结果
这就像在现实生活中,遇到不确定的事情时,你问多个人意见,再综合判断。
2. 为什么随机森林不容易过拟合
随机森林解决过拟合,靠两件事:
1)随机采样训练数据(Bagging)
每棵树训练时,并不是用全部训练数据,而是从训练集中随机抽取一部分样本(有放回)。
- 这叫 Bootstrap 采样
- 每棵树都看到略有不同的数据
- 这样训练出来的树不会完全相同,也不会同时记住训练集里的所有噪声
2)随机选择特征
在分裂每个节点时,每棵树不会看所有特征,而是随机挑选一部分特征来找最优分裂。
- 避免某个特别强的特征主导所有树
- 增加每棵树之间的多样性
- 最终组合时,多样性帮助减少过拟合
这两种随机性结合起来,就是“随机森林”名字的由来。
3. 随机森林和单棵决策树的区别
| 特性 | 单棵决策树 | 随机森林 |
|---|---|---|
| 是否容易过拟合 | 高 | 低 |
| 训练速度 | 快 | 慢(多棵树) |
| 预测速度 | 快 | 较慢(每棵树都预测) |
| 可解释性 | 高 | 较低(单棵树容易解释,但整体不容易) |
| 处理非线性 | 可以 | 可以,且更稳健 |
| 对异常值敏感 | 高 | 低(多树投票抵消) |
可以看到,随机森林就是用多棵树集体投票来弥补单棵树的缺点。
4. Python 示例:建立随机森林分类器
延续前面学生考试的数据,我们来看看随机森林是怎么做预测的:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# 特征:每天学习时长、作业完成率、是否参加辅导班
X_train = np.array([
[2, 50, 0],
[3, 60, 0],
[4, 65, 0],
[5, 70, 1],
[6, 75, 1],
[7, 80, 1]
])
y_train = np.array([0, 0, 0, 1, 1, 1])
# 新样本
X_test = np.array([
[3.5, 62, 0],
[6.5, 78, 1]
])
# 建立随机森林
rf = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=42)
rf.fit(X_train, y_train)
# 预测
y_pred = rf.predict(X_test)
print("预测结果:", y_pred)
# 每棵树的投票结果
print("每棵树预测结果:")
for i, tree in enumerate(rf.estimators_[:5], 1): # 只打印前5棵
print(f"树{i}: {tree.predict(X_test)}")
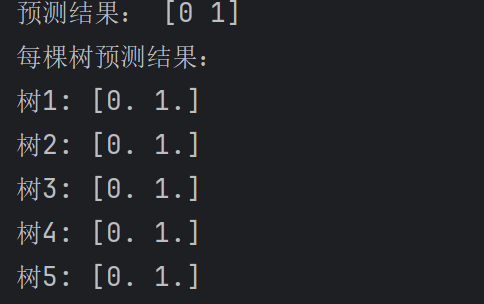
说明
n_estimators=100表示随机森林里有 100 棵树- 每棵树都是在随机抽样的训练数据和随机特征上建立的
max_depth=3限制每棵树的深度,避免单棵树过拟合- 预测时每棵树给一个结果,最终采用多数票
即便某些单棵树预测错误,最终结果通常更稳健。
5. 随机森林的优缺点
优点
- 不容易过拟合,泛化能力强
- 可以处理数值和类别混合特征
- 对异常值和噪声不太敏感
- 不需要太多特征工程,模型自带特征选择能力
缺点
- 可解释性差(很难像单棵决策树那样画出来分析决策路径)
- 预测速度比单棵树慢
- 占用内存大,尤其训练数据和树数量多的时候
6. 随机森林调参的重点
如果你要优化随机森林性能,可以关注几个主要参数:
-
n_estimators:树的数量- 多树通常更稳定,但训练和预测更慢
-
max_depth:限制树深度- 控制单棵树过拟合
-
min_samples_leaf:每个叶子最少样本数- 防止树分裂太细
-
max_features:分裂时随机选择的特征数量- 提高树的多样性
通常使用验证集或者交叉验证来挑选这些参数。
7. 为什么随机森林很适合做基线模型
在真实项目里,很多数据科学家会先用随机森林做一个基线模型:
- 数据不用做太复杂的预处理
- 不用担心特征尺度
- 对异常值和噪声相对稳健
- 预测准确率通常不错
基于这个基线,再考虑是否用梯度提升树或神经网络进一步优化。
8. 总结:为什么它叫“随机森林”
名字很形象:
- 随机:随机抽样样本 + 随机抽特征
- 森林:多棵树集体投票
你可以理解成:多棵树互相制衡,投票决定最终结果。
相比单棵树,随机森林:
- 泛化能力更强
- 不容易被个别噪声点影响
- 能处理更复杂的数据分布
如果你掌握了 KNN、单棵决策树,再理解随机森林,你就已经建立了分类任务从局部投票到条件分裂,再到集成学习的完整逻辑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 23
23 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)