并行iTransformer-GRU-SHAP分析的轴承寿命预测,不只是模型,更是一个寿命预测对比的框架,可以添加任何对比模型
在时间序列预测中,iTransformer通过“维度倒置”的巧妙设计,突破了传统Transformer的局限,能同时捕捉变量关系与时间动态。为充分发挥其优势,我们创新性地搭建了iTransformer-GRU并行网络,并将其应用于轴承的剩余寿命预测。更值得一提的是,本期推文通过SHAP可解释性分析,深入揭示了影响轴承寿命的关键变量,让预测结果不仅精准,而且透明、可信任。
本期推文不仅仅是搭建一个创新网络,更是提供一个基于深度学习轴承寿命预测的框架,在这个框架中你可以非常方便的添加自己的模型进行对比,并且得到丰富的可视化图形。
本期推文依旧是采用经典的PHM2012数据进行实验。关于PHM2012数据的介绍,前几期推文就曾介绍过了,本期就不再赘述。数据介绍推文
iTransformer-GRU并行网络
本期网络采用了pytorch搭建,使用torchviz工具箱可视化一下网络。

网络具体参数信息如下:
Input dimension (enc_in): 93, Sequence length: 1
iTransformerGRUModel(
(variable_embedding): Linear(in_features=1, out_features=16, bias=True)
(transformer_encoder): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=16, out_features=16, bias=True)
)
(linear1): Linear(in_features=16, out_features=64, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
(linear2): Linear(in_features=64, out_features=16, bias=True)
(norm1): LayerNorm((16,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((16,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.2, inplace=False)
(dropout2): Dropout(p=0.2, inplace=False)
)
)
)
(gru): GRU(93, 32, num_layers=2, batch_first=True, dropout=0.2, bidirectional=True)
(transformer_proj): Sequential(
(0): Linear(in_features=1488, out_features=64, bias=True)
(1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
)
(gru_proj): Sequential(
(0): Linear(in_features=64, out_features=64, bias=True)
(1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
)
(attention_weights): Sequential(
(0): Linear(in_features=128, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=2, bias=True)
(3): Softmax(dim=1)
)
(fusion_layer): Sequential(
(0): Linear(in_features=64, out_features=32, bias=True)
(1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(2): ReLU()
(3): Dropout(p=0.13999999999999999, inplace=False)
(4): Linear(in_features=32, out_features=16, bias=True)
(5): ReLU()
(6): Linear(in_features=16, out_features=1, bias=True)
)
)轴承寿命预测
本期代码流程:
1,读取原始数据
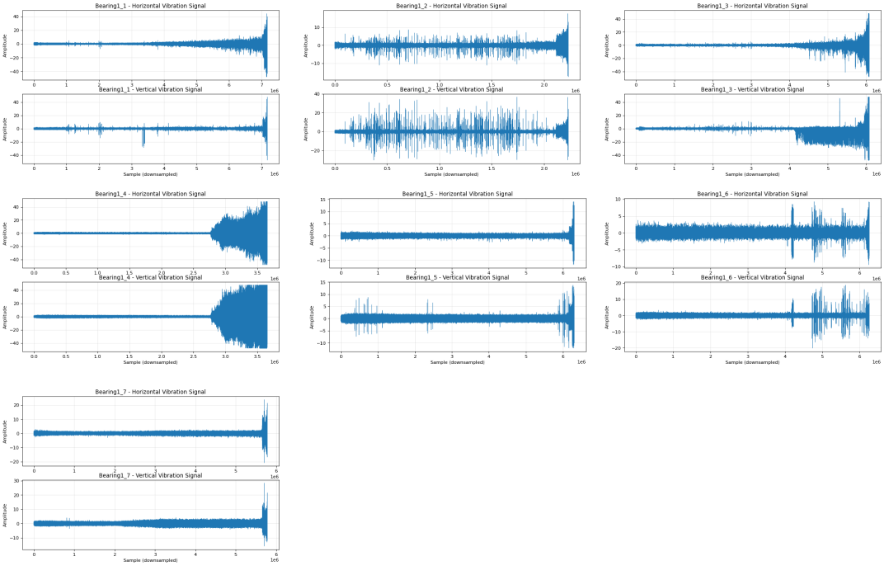
读取PHM2012数据集,并绘各个轴承的制时域波形。这里只列举Bearing1~7。
2,滑窗操作
为什么要进行滑窗操作呢?
PHM2012数据集每次采样得到的数据存储在CSV文件中,采集数据间隔为10s,每次采集0.1s,采集频率为25.6kHz,则其长度为2560行,包括时间信息(时-分 秒-微秒)和水平加速度,竖直加速度信息。若将每10秒中采集到的这0.1秒数 据作为输入进行训练,则模型可以观测到的时间尺度范围十分有限,这会使得模型过度关注局部特征,而忽略了轴承运行过程的整体趋势变化,影响模型对于轴 承所处寿命阶段的判断。而将轴承整个寿命周期的数据直接作为输入,如轴承1_1 约7175680 个数据点的数据,则会让模型忽略局部产生的寿命退化信号降低模型 预测精度,甚至无法学习到正确的寿命退化特征,同时过长的信号输入,使得模 型维度过大,使得模型参数增多训练困难,消耗过多计算资源。 因此采用滑窗操作,选取一定时间内采集到的数据作为输入,既可以保证模 型对于整体趋势的观测,也保证了局部退化特征的提取。滑窗大小(window size) 为𝑙,假如𝑙=3,也就是将30秒内获得的0.3秒数据作为模型输入,同 时滑窗具有滑动量𝑠(slide length),由窗口大小和滑动量共同决定输入数据的选择,具体操作方式如下图,图中表示为当窗口大小为3,滑动量为1时,从原 始振动数据中对数据进行切片,并制作训练数据样本的过程。
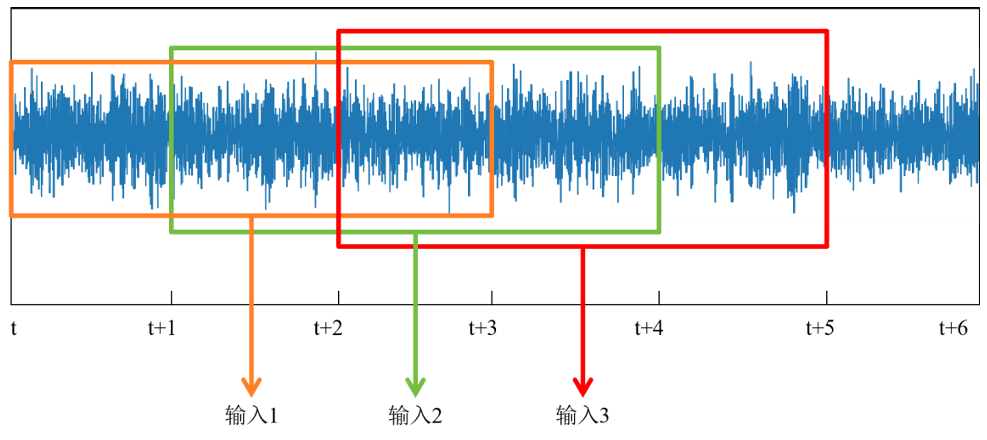
滑窗操作制作训练样本示意图
3,划分训练集与测试集
采用torch自带的Data.DataLoader可以非常方便的划分训练集与测试集。在代码中,设置了一个可以快速切换训练集与测试集的函数。使用方法如下:
train_loader, test_loader, scaler,feature_names = quick_load_data(
batch_size=16,
workers=2,
force_reload=True, # force_reload,当值为False,则加载上一次的训练集和测试集,当当值为True,此时按照你设置的参数进行数据的划分与处理。也就是说,只有当force_reload为True的时候,你设置的batch_size,train_bearings等参数才能起作用哦!
train_bearings=['Bearing1_1', 'Bearing1_2', 'Bearing1_5', 'Bearing1_3', 'Bearing1_6', 'Bearing1_7'],
test_bearings=['Bearing1_4'],
window_size=3,
stride=1
)当你想要改变训练集与测试集的时候,只需要更改这里的轴承名字即可。除了轴承1,轴承2,3都可以的哦!另外batchsize,滑动窗口大小,步长等参数都写好了接口,非常方便即可更改。
4,提取数据的特征
代码提取了时域信号和频域信号,以及小波分解后的能量、熵值等,一共93种特征:
feature_names = [
# ==================== Time-Domain Features ====================
'time_mean', # 时域均值:信号的平均值,反映信号的直流分量
'time_var', # 时域方差:信号的离散程度,反映信号的波动大小
'time_skew', # 时域偏度:信号分布的不对称性,正值表示右偏,负值表示左偏
'time_kurtosis', # 时域峰度:信号分布的尖锐程度,反映异常值的存在
'time_peak', # 时域峰值:信号的最大绝对值,反映信号的最大冲击
'time_rms', # 时域均方根值:信号的有效值,反映信号的能量大小
'crest_factor', # 峰值因子:峰值与均方根值之比,反映信号的冲击特性
'pulse_factor', # 脉冲因子:峰值与平均值之比,反映信号的脉冲特性
'time_std', # 时域标准差:信号的标准偏差,反映信号的离散程度
'time_median', # 时域中位数:信号的中间值,对异常值不敏感
'interquartile_range', # 四分位距:第75百分位数与第25百分位数之差,反映数据的分散程度
'time_max', # 时域最大值:信号的最大值
'time_min', # 时域最小值:信号的最小值
'peak_to_peak', # 峰峰值:最大值与最小值之差,反映信号的振动幅度
'shape_factor', # 波形因子:均方根值与平均值之比,反映信号的波形特征
'clearance_factor', # 裕度因子:峰值与方根幅值之比,用于故障诊断
'impulse_factor', # 冲击因子:峰值与平均值之比,反映信号的冲击程度(与pulse_factor相同)
'shannon_entropy', # 香农熵:信号的信息熵,反映信号的复杂度和不确定性
# ==================== Frequency-Domain Features ====================
# --- Hilbert Transform Based (if use_hilbert=True) ---
'hilbert_amplitude_mean', # 希尔伯特包络均值:瞬时幅值的平均值,反映调制信号的平均强度
'hilbert_amplitude_std', # 希尔伯特包络标准差:瞬时幅值的标准差,反映调制深度
'hilbert_frequency_mean', # 希尔伯特瞬时频率均值:瞬时频率的平均值
'hilbert_frequency_std', # 希尔伯特瞬时频率标准差:瞬时频率的变化程度
# --- General Spectral Features ---
'spectral_centroid', # 频谱质心:频谱的重心位置,反映频率分布的中心
'spectral_spread', # 频谱扩散度:频率分布的离散程度
'spectral_rolloff', # 频谱滚降点:包含85%能量的频率点,反映高频成分
'dominant_frequency', # 主频:能量最大的频率分量,反映主要振动频率
'spectral_kurtosis', # 频谱峰度:频谱分布的尖锐程度,用于检测瞬态故障
'spectral_skewness', # 频谱偏度:频谱分布的不对称性
'spectral_entropy', # 频谱熵:频谱的复杂度,反映频率成分的分散程度
# --- Band Energy Ratios (4 bands) ---
'band_energy_ratio_1', # 频带能量比1:第1个频带的能量占比
'band_energy_ratio_2', # 频带能量比2:第2个频带的能量占比
'band_energy_ratio_3', # 频带能量比3:第3个频带的能量占比
'band_energy_ratio_4', # 频带能量比4:第4个频带的能量占比
# --- Raw FFT Magnitude Features (n_fft_features = 40) ---
'fft_mag_0', 'fft_mag_1', 'fft_mag_2', 'fft_mag_3', 'fft_mag_4', # FFT幅值特征0-4:前5个频率分量的幅值
'fft_mag_5', 'fft_mag_6', 'fft_mag_7', 'fft_mag_8', 'fft_mag_9', # FFT幅值特征5-9:第6-10个频率分量的幅值
'fft_mag_10', 'fft_mag_11', 'fft_mag_12', 'fft_mag_13', 'fft_mag_14', # FFT幅值特征10-14:第11-15个频率分量的幅值
'fft_mag_15', 'fft_mag_16', 'fft_mag_17', 'fft_mag_18', 'fft_mag_19', # FFT幅值特征15-19:第16-20个频率分量的幅值
'fft_mag_20', 'fft_mag_21', 'fft_mag_22', 'fft_mag_23', 'fft_mag_24', # FFT幅值特征20-24:第21-25个频率分量的幅值
'fft_mag_25', 'fft_mag_26', 'fft_mag_27', 'fft_mag_28', 'fft_mag_29', # FFT幅值特征25-29:第26-30个频率分量的幅值
'fft_mag_30', 'fft_mag_31', 'fft_mag_32', 'fft_mag_33', 'fft_mag_34', # FFT幅值特征30-34:第31-35个频率分量的幅值
'fft_mag_35', 'fft_mag_36', 'fft_mag_37', 'fft_mag_38', 'fft_mag_39', # FFT幅值特征35-39:第36-40个频率分量的幅值
# ==================== Wavelet Features (level=4) ====================
# --- Level 4 Approximation Coefficients (cA4) ---
'cA4_energy', # 4级近似系数能量:低频成分的能量,反映信号的趋势
'cA4_entropy', # 4级近似系数熵:低频成分的复杂度
'cA4_mean_abs_coeff', # 4级近似系数平均绝对值:低频成分的平均幅度
'cA4_std_coeff', # 4级近似系数标准差:低频成分的波动程度
# --- Level 4 Detail Coefficients (cD4) ---
'cD4_energy', # 4级细节系数能量:最低频细节的能量
'cD4_entropy', # 4级细节系数熵:最低频细节的复杂度
'cD4_mean_abs_coeff', # 4级细节系数平均绝对值:最低频细节的平均幅度
'cD4_std_coeff', # 4级细节系数标准差:最低频细节的波动程度
# --- Level 3 Detail Coefficients (cD3) ---
'cD3_energy', # 3级细节系数能量:中低频细节的能量
'cD3_entropy', # 3级细节系数熵:中低频细节的复杂度
'cD3_mean_abs_coeff', # 3级细节系数平均绝对值:中低频细节的平均幅度
'cD3_std_coeff', # 3级细节系数标准差:中低频细节的波动程度
# --- Level 2 Detail Coefficients (cD2) ---
'cD2_energy', # 2级细节系数能量:中高频细节的能量
'cD2_entropy', # 2级细节系数熵:中高频细节的复杂度
'cD2_mean_abs_coeff', # 2级细节系数平均绝对值:中高频细节的平均幅度
'cD2_std_coeff', # 2级细节系数标准差:中高频细节的波动程度
# --- Level 1 Detail Coefficients (cD1) ---
'cD1_energy', # 1级细节系数能量:高频细节的能量,对故障敏感
'cD1_entropy', # 1级细节系数熵:高频细节的复杂度
'cD1_mean_abs_coeff', # 1级细节系数平均绝对值:高频细节的平均幅度
'cD1_std_coeff', # 1级细节系数标准差:高频细节的波动程度
]5,开始训练,结果如下:
采用交叉验证的方式,依次交替进行测试验证模型的鲁棒性和泛化能力。例如:任务1:采用轴承1-6训练,那么就采用轴承7进行测试。任务2:采用轴承1,3,4,5,6,7训练,那么就采用轴承2进行测试。以此类推。轴承1_3-1_7模型预测结果如下:
基于并行iTransformer-GRU的寿命预测结果如下:
Bearing1-3预测结果:
==================================================
Test Set Metrics:
==================================================
MSE: 0.002176
RMSE: 0.046644
MAE: 0.038464
R2: 0.973848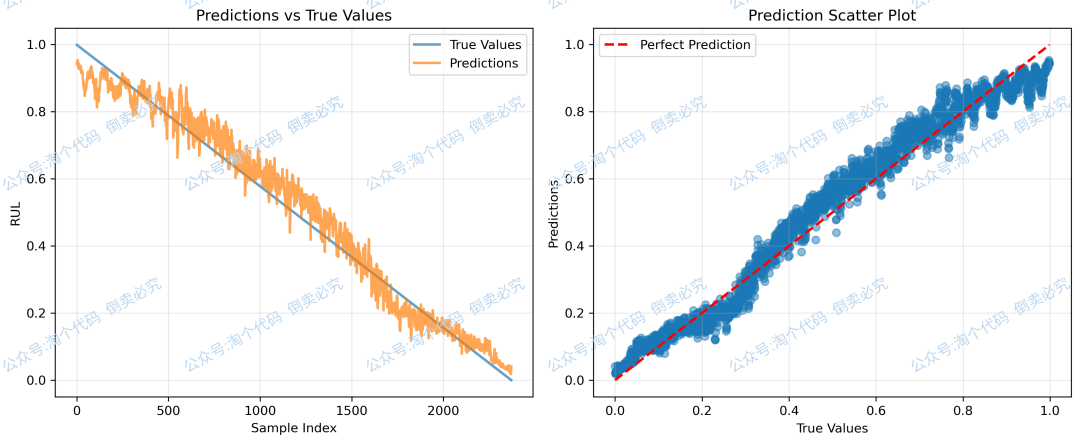
Bearing1-4预测结果:
==================================================
Test Set Metrics:
==================================================
MSE: 0.014618
RMSE: 0.120903
MAE: 0.104004
R2: 0.824342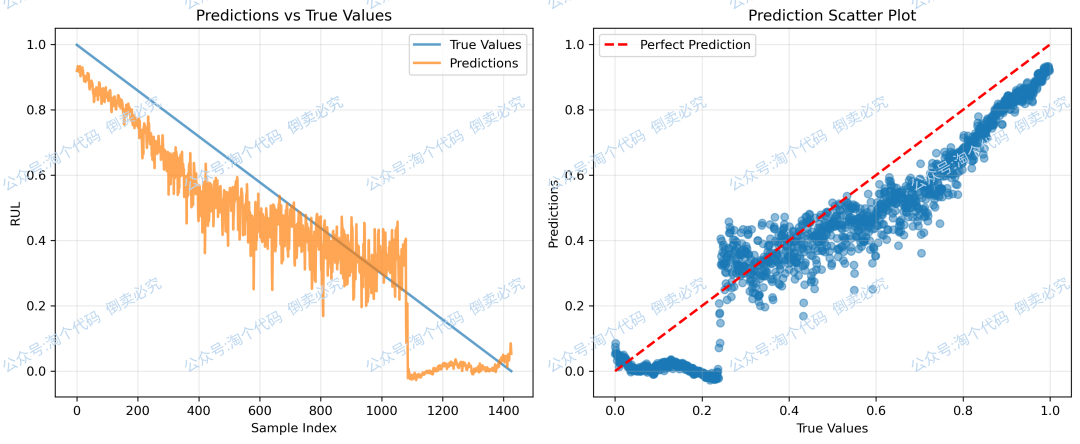
Bearing1-5预测结果:
==================================================
Test Set Metrics:
==================================================
MSE: 0.057202
RMSE: 0.239169
MAE: 0.176540
R2: 0.312461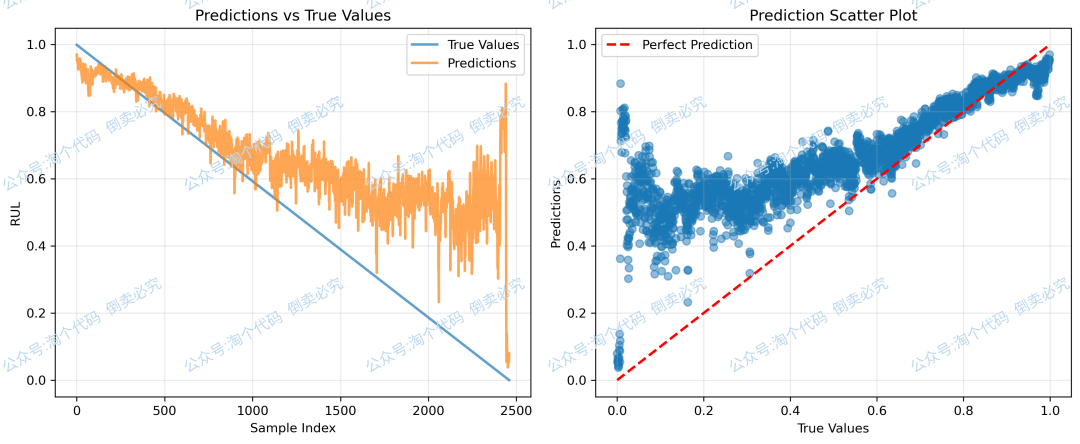
Bearing1-6预测结果:
==================================================
Test Set Metrics:
==================================================
MSE: 0.021220
RMSE: 0.145672
MAE: 0.110789
R2: 0.744941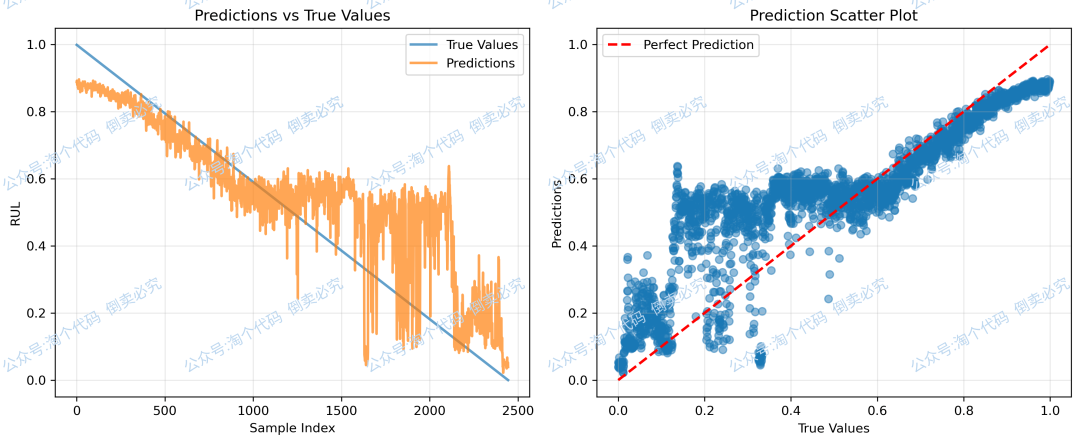
Bearing1-7预测结果:
==================================================
Test Set Metrics:
==================================================
MSE: 0.027104
RMSE: 0.164634
MAE: 0.116410
R2: 0.674171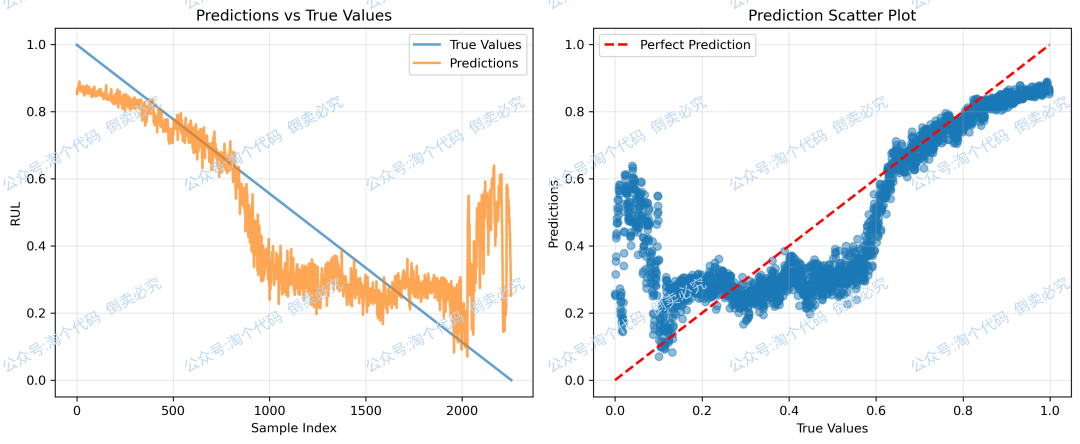
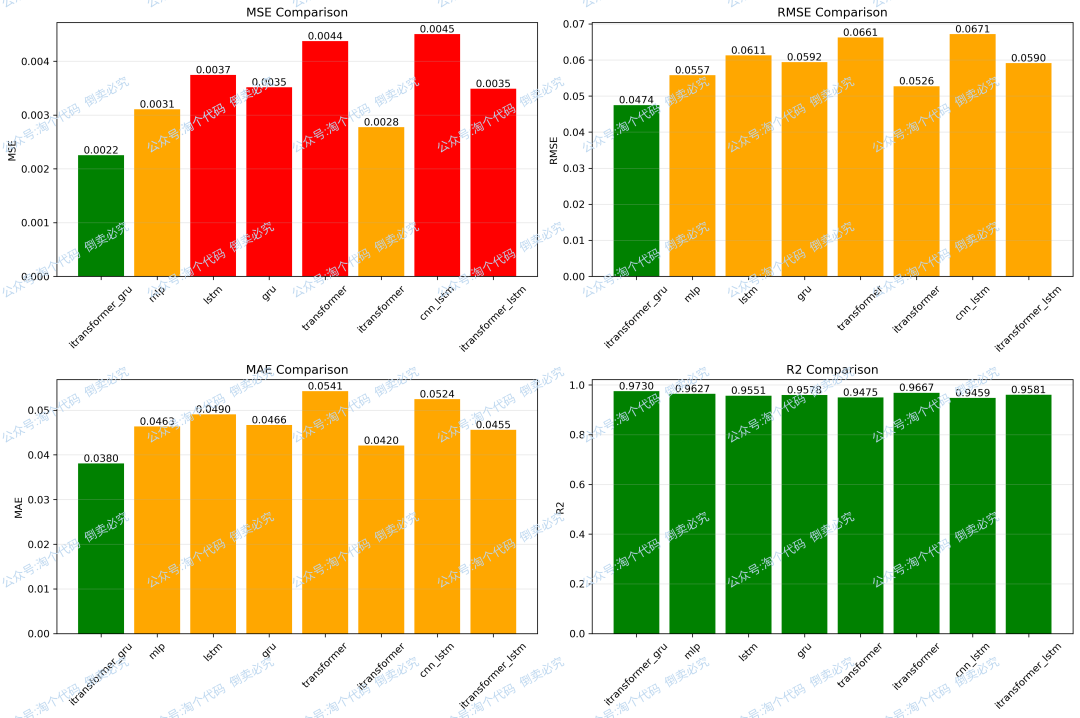
6,多模型进行比较
将并行iTransformer-GRU网络与MLP、LSTM、GRU、TRANSFORMER、ITRANSFORMER、CNNLSTM、ITRANSFORMER-LSTM进行比较,以轴承1-3为例进行实验,结果如下:
雷达图:
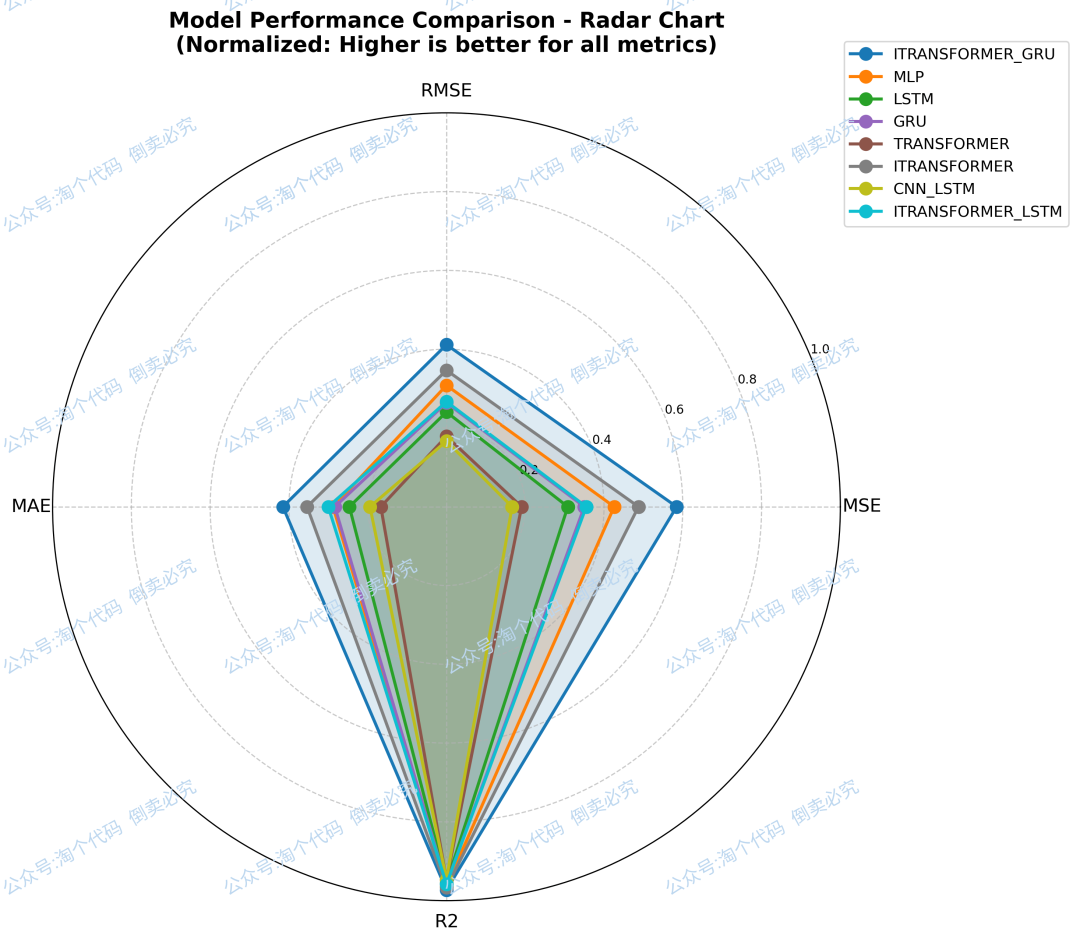
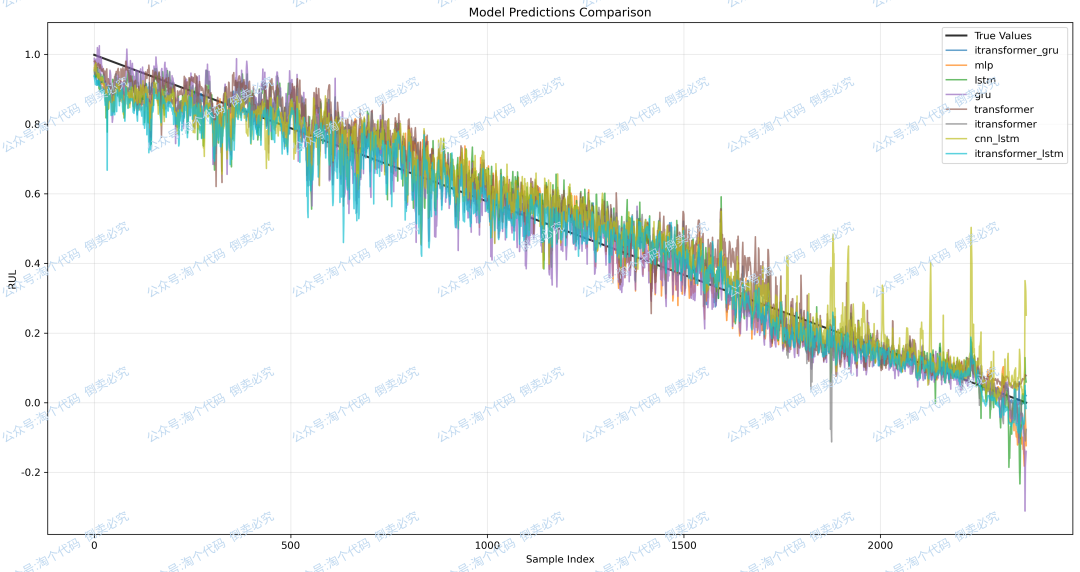
真实值与预测值的对比图:
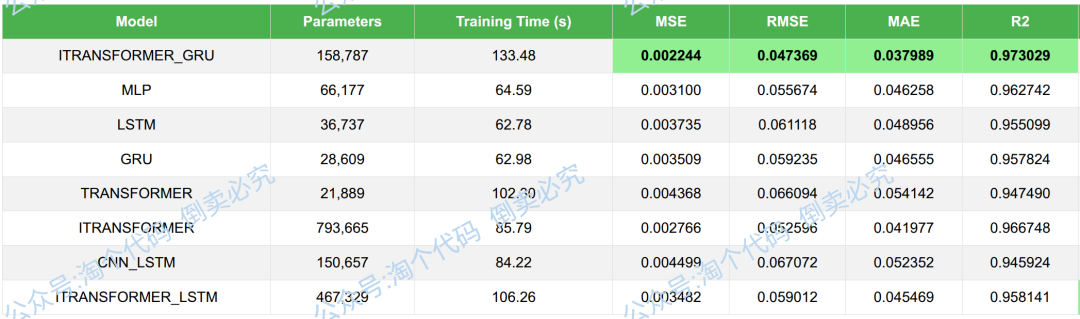
模型指标对比结果:
请注意,如果你想使用本文模型直接发文,那也是完全没问题的。但是如果你有自己想用的模型,在这个代码中添加你自己的模型,那也是非常方便的,需要改动的地方如下。
1.首先在models文件夹中添加你自己的模型代码
2.在models文件夹下的__init__.py文件中引一下你的模型,确保能被其他脚本调用
3.在models文件夹下的factory.py文件中加一下你的算法名字
4.在configs文件夹下的model_config.py文件中写一下你的模型参数
在这个代码中添加一个模型将会非常简单,整体改下来一分钟都不到,改完以上四步,直接就可以在训练的脚本文件中输入自己算法名字进行调用啦。
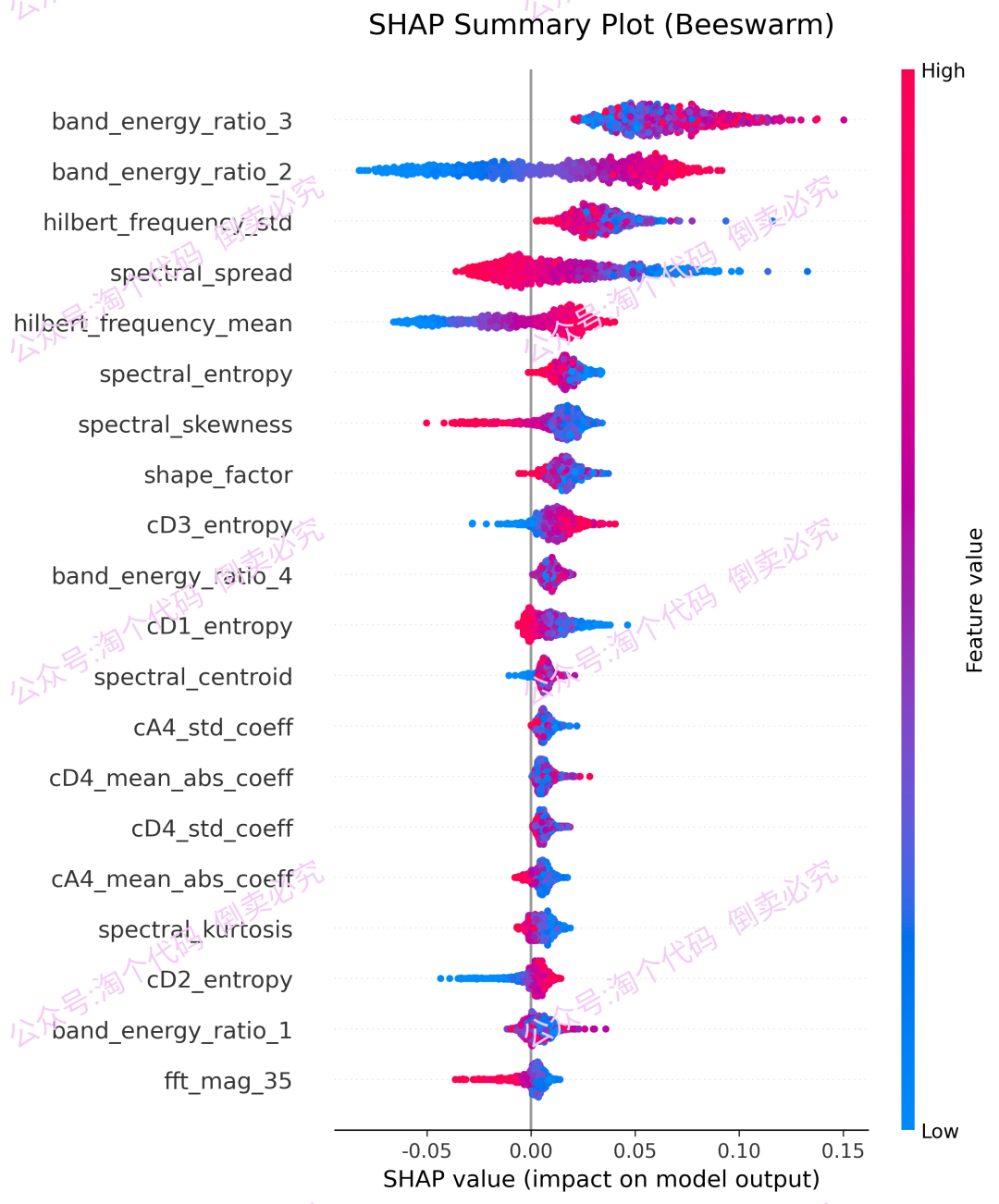
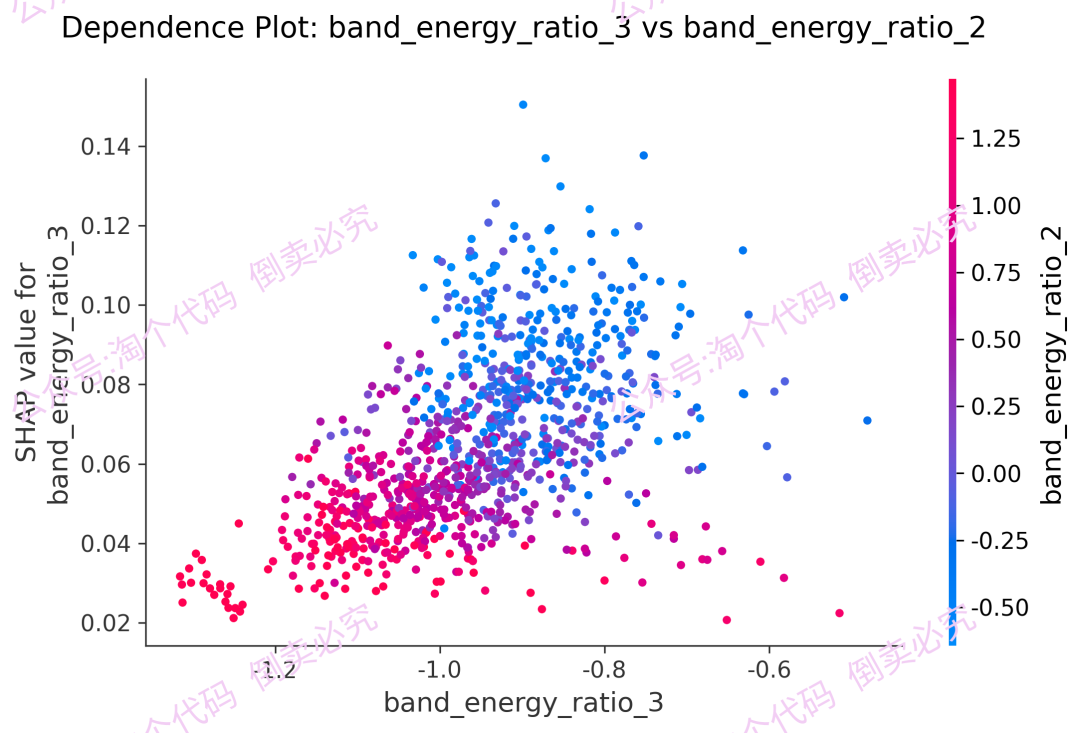
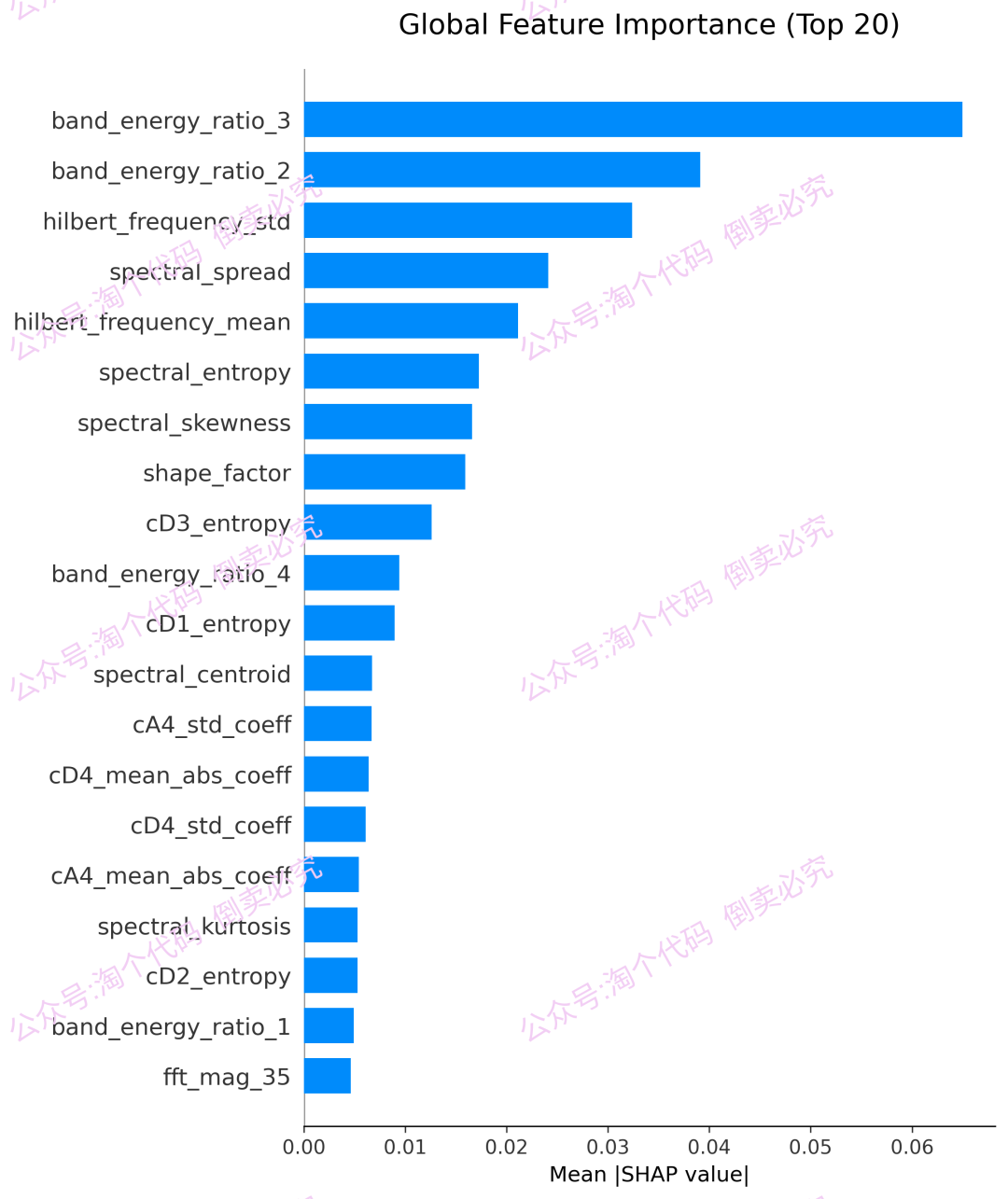
7,SHAP分析


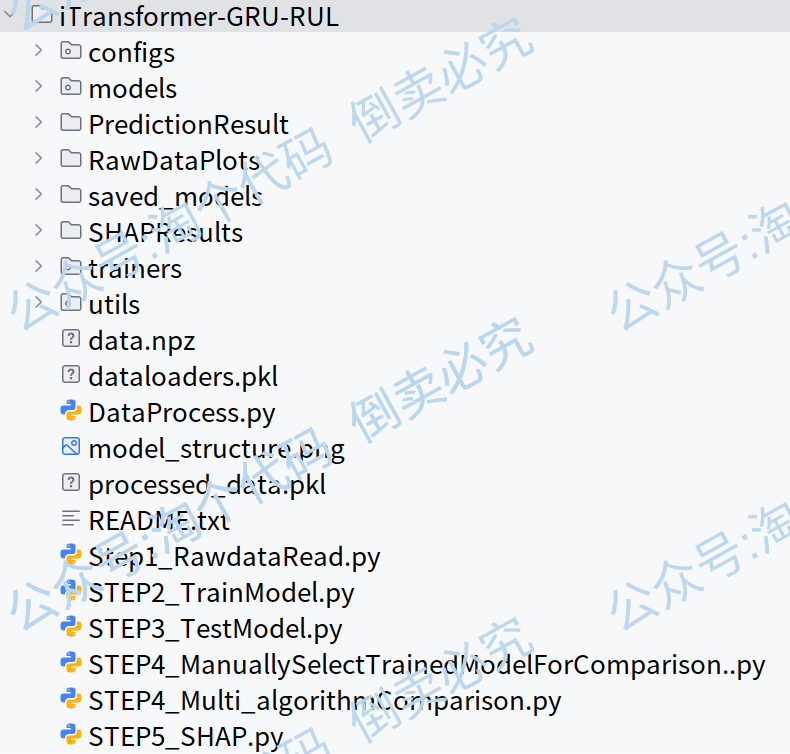
最后再给大家展示一下这份代码的README文件,那是相当清楚!
your_project/
│
├── models/ # 模型文件夹
│ ├── __init__.py # 使models成为一个包
│ ├── base.py # 基类和接口
│ ├── itransformer.py # iTransformer模型
│ ├── itransformer-gru.py # iTransformer-gru模型
│ ├── lstm.py # LSTM模型
├── gru.py 等等模型
│ └── factory.py # 模型工厂
│
├── configs/ # 配置文件夹
│ ├── __init__.py
│ └── model_config.py # 模型配置类
│
├── PredictionResult/ # 模型预测的结果会保存在这个文件夹内
│ └── itransformer_gru_20250928_150109 #以模型的名字和训练的时间作为命名
├── SHAPResults/ # SHAP分析的结果会保存在这个文件夹内
│ └── itransformer_gru_20250928_150109 #以模型的名字和训练的时间作为命名
├── RawDataPlots/ # 原始轴承数据趋势图
│ └── itransformer_gru_20250928_150109 #以模型的名字和训练的时间作为命名
├── saved_models/ # 保存训练好的模型
├── trainers/ # 训练相关
│ ├── __init__.py
│ └── trainer.py # 训练器类
│
├── utils/ # 工具函数
│ ├── __init__.py
│ └── visualization.py # 可视化相关函数
│
├── data.npz # 这是数据文件,将原始数据整理成一个文件,没有做任何处理,只是读取而已
├── processed_data.pkl # 这是数据文件,这个数据存储的是将data.npz进行滑动窗口处理,设置窗口大小为4,步长为1
├── dataloaders.pkl # 这是数据文件,这个数据是将processed_data划分训练集与测试集,并设置训练批次,采用的就是Data.DataLoader函数划分的
├
├
├── DataProcess.py # 数据处理文件,这个脚本实现了一些对第一步STEP1得到的原始数据data.npz处理的函数,包含滑动窗口处理,特征提取,划分测试集与训练集,
└── Step1_RawdataRead.py # 这个脚本文件对原始的IEEE数据进行读取,并保存成一个data.npz,并对每个轴承进行全寿命的绘图
└── STEP2_TrainModel.py # 这个程序开始调取第一步得到的数据文件,划分训练集和测试集,并可以手动选择模型进行训练。在quick_load_data函数中可以方便设置这些参数
└ #当训练完成,会提示你是否立即进行测试。最后会保存训练好的模型,以及测试的结果,绘图等
└── STEP3_TestModel.py # 这个程序可以手动选择你在STEP2训练好的模型进行测试,并保存测试结果
└── STEP4_ManuallySelectTrainedModelForComparison.py # 你可以手动选择N个已经训练好的模型进行对比测试,并保存绘图结果
└── STEP4_Multi_algorithmComparison.py # 执行这个脚本你可以一键实现自动化,指定你想要训练的N个模型开始训练,并在训练后直接进行对比测试,
└ # 与STEP4_ManuallySelectTrainedModelForComparison脚本不同的是,这个脚本的模型是要从头训练的
└── STEP5_SHAP.py # SHAP分析,并保存结果我给每个代码的作用都进行注释了,因此你不用担心你不会使用这个代码。
代码的目录也都非常简洁,你只需要运行下方的5个STEP_文件即可,按照步骤一步步来,你将会更快地入门轴承寿命预测。
建议用python3.9。pytorch的话有显卡的同学可以用GPU版本,没有显卡的就用CPU版本。其他包就缺哪个装哪个就行,实在搞不定的同学后台联系作者帮你装。
本期代码获取
点击下方阅读原文跳转链接。
或者直接复制下方链接跳转:
https://mbd.pub/o/bread/mbd-YZWYkpdtZg==
获取更多代码:
或者复制链接跳转:https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)