自注意力(Self-Attention)、单头注意力(Single-Head Attention) 和 多头注意力(Multi-Head Attention)
·
- 自注意力:是一种机制,描述了如何通过 Q、K、V 计算加权和。它是单头和多头的基础。
- 单头注意力:是自注意力的一种具体实现,即只用一个注意力头,每个头维度等于 d_model。
- 多头注意力:是多个单头注意力的并行组合,每个头维度为 d_model / n_heads,最终拼接并投影。
可以用一个比喻帮助理解:
- 自注意力:像一个会议,每个人都可以看到所有人的发言,然后结合所有人的观点更新自己的认识。
- 单头注意力:整个会议只由一个主持人组织,每个人只能按照一种方式理解别人的观点。
- 多头注意力:会议分成多个小组并行讨论,每个小组从不同的角度(如市场、技术、用户体验等)分析问题,最后汇总所有小组的意见,形成全面的结论。
1. 自注意力机制(Self-Attention)
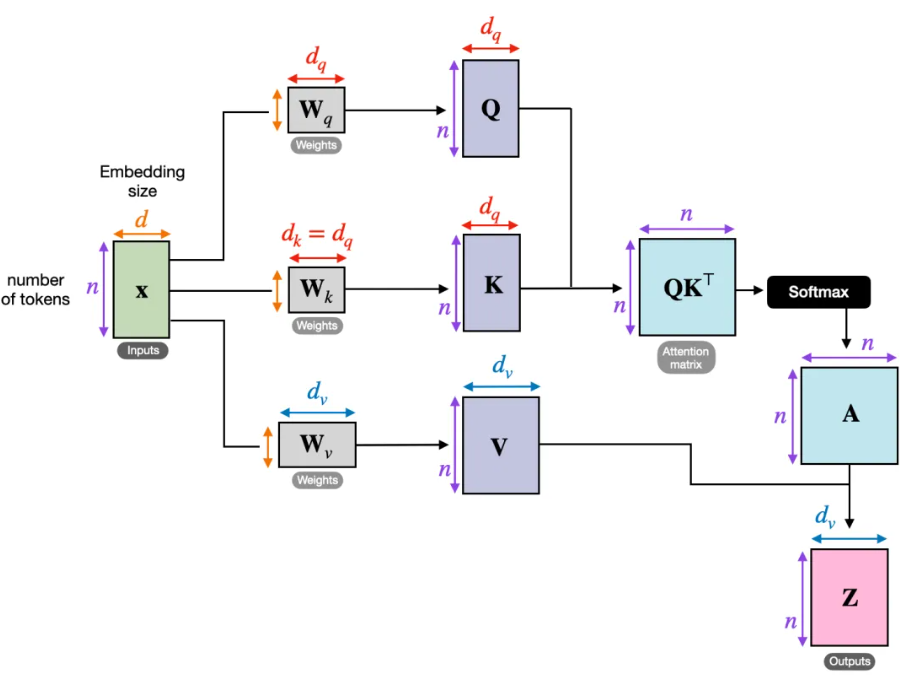
自注意力是 Transformer 的核心操作,它让序列中的每个元素(如单词或图像 patch)能够与序列中所有其他元素进行交互,并计算出一个加权和作为自己的新表示。这个加权和依据“查询(Query)”、“键(Key)”、“值(Value)”三者之间的关系生成。
计算步骤(以序列输入 X 为例,形状 [batch, seq_len, d_model]):
- 通过三个独立的线性层,将 X 映射为 Q、K、V
- 计算注意力分数:
Attention = softmax(Q·K^T / √d_k) V,其中 d_k 是每个头的维度 - 输出形状与输入相同:[batch, seq_len, d_model]。
特点:
- 捕获序列内部的长距离依赖关系。
- 不依赖外部信息,完全基于输入序列自身。
- 并行计算,效率高。
2. 单头注意力(Single-Head Attention)
单头注意力 就是只使用一个注意力头的自注意力。也就是说,Q、K、V 的线性投影将输入映射到 head_size = d_model 的维度(因为只有一头,所以 head_size = d_model),然后直接做一次缩放点积注意力。
在代码中,AttentionHead 类实现的就是单头注意力。它内部有三个线性层(Q、K、V),将 d_model 映射到 head_size,然后计算注意力。当 n_heads=1 时,MultiHeadAttention 退化为一个单头注意力(但通常不会这样用)。
单头注意力的局限:
- 只能学习一种注意力模式(例如只能关注全局关系或只能关注局部关系)
- 可能无法同时捕捉序列中多种不同类型的依赖。
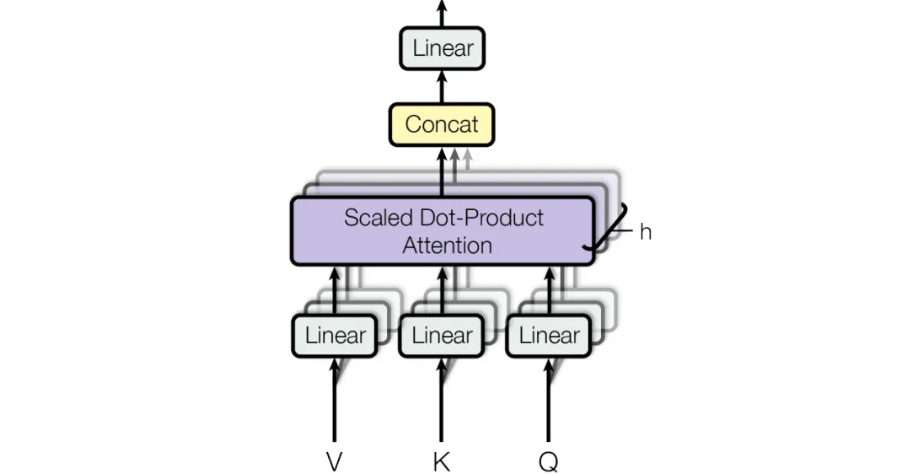
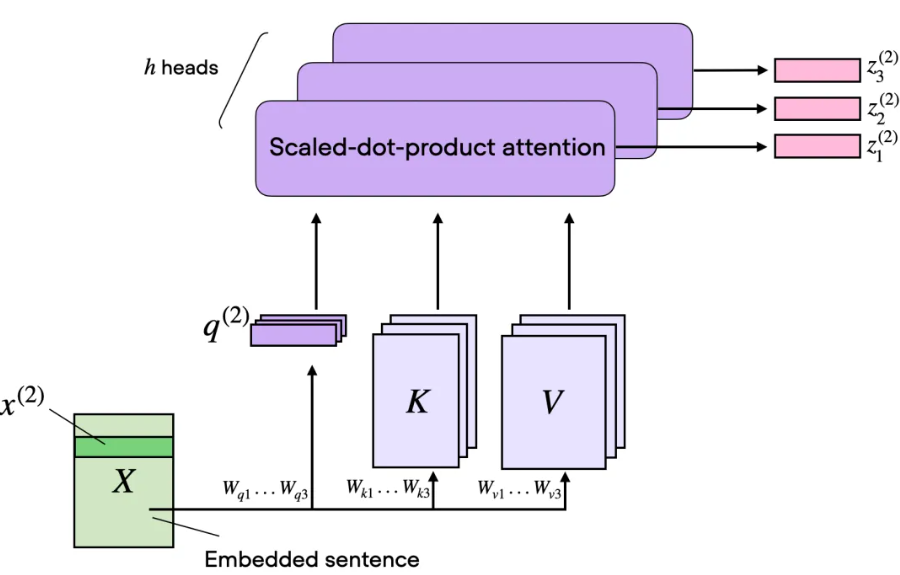
3. 多头注意力(Multi-Head Attention)
多头注意力 将多个单头注意力并行执行,每个头使用不同的线性投影(即不同的 Q、K、V 权重),从而让模型从不同的子空间(head_size 维)学习不同的特征交互模式。最后将所有头的输出拼接起来,再经过一个线性层(W_o)映射回 d_model。
代码中的体现:
- MultiHeadAttention 类包含一个 nn.ModuleList,其中包含 n_heads 个 AttentionHead实例
- 每个头独立计算 (batch, seq_len, head_size) 的输出。 torch.cat(…, dim=-1)
- 将各头输出在特征维拼接,得到 (batch, seq_len, d_model)
- 最后通过 self.W_o 进行输出投影。
多头注意力的优点:
- 多角度理解:不同头可以关注不同的关系(如一个头关注相邻 patch,另一个头关注全局 cls_token,另一个头关注颜色相似区域等)。
- 增强模型容量:在不增加总参数量(因为总参数量与单头处理 d_model 维相当)的情况下,通过分割成多个子空间,提升了表达能力。
- 更稳定的训练:多头结构有助于梯度流动,通常比单头更容易收敛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)