当AI成为我的“第二大脑”:一个开发者的效率革命实录
当AI成为我的“第二大脑”:一个开发者的效率革命实录

当AI成为我的“第二大脑”:一个开发者的效率革命实录
2024年春天,我站在公司技术分享会的讲台上,看着台下几十双年轻的眼睛里闪烁着困惑与期待。作为团队里最早接触AI工具的开发者,我分享了一个令人震惊的数据:过去三个月,我们团队使用GitHub Copilot完成的代码量,相当于前一年全年的总和。台下响起一阵惊叹,但更让我印象深刻的是,会后几个实习生围上来问:“这些工具真的不会让我们失业吗?”

这个问题像一块石头投入平静的湖面,激起了整个行业对AI工具的深度思考。在接下来的一年里,我亲历了AI技术从辅助工具到核心生产力的蜕变过程,也见证了无数开发者在这场变革中的迷茫与突破。今天,我想用三个真实案例,带大家走进AI重塑开发工作的第一现场。

一、智能编码:从“人肉打字机”到“思维加速器”
去年夏天,我接手了一个复杂的电商推荐系统重构项目。按照传统开发模式,我需要先花两周时间阅读旧代码,再花三周设计新架构,最后用两个月实现核心算法。但这次,我决定尝试GitHub Copilot + Cursor的组合拳。
第一天:架构设计阶段
python
# 使用Copilot生成基础框架
class RecommendationEngine:
def __init__(self, user_data, item_data):
self.user_profiles = self._build_user_profiles(user_data)
self.item_features = self._extract_item_features(item_data)
self.model = self._initialize_model()
def _build_user_profiles(self, data):
# Copilot自动补全用户画像构建逻辑
profiles = {}
for user_id, history in data.items():
profiles[user_id] = {
'purchase_history': history['purchases'],
'browsing_history': history['views'],
'preferences': self._analyze_preferences(history)
}
return profiles
当我在Cursor中输入class RecommendationEngine:时,Copilot立即给出了完整的类框架,包括初始化方法和占位函数。更让我惊讶的是,当我开始实现_build_user_profiles方法时,它不仅补全了字典结构,还自动生成了偏好分析函数的调用。
第三周:算法优化阶段
在实现协同过滤算法时,我遇到了矩阵运算的性能瓶颈。传统做法是手动优化循环结构,但这次我尝试让Copilot生成Numba优化版本:
python
import numba
@numba.jit(nopython=True)
def optimized_cosine_similarity(a, b):
# Copilot生成的向量化实现
dot_product = 0.0
norm_a = 0.0
norm_b = 0.0
for i in range(a.shape[0]):
dot_product += a[i] * b[i]
norm_a += a[i] ** 2
norm_b += b[i] ** 2
return dot_product / (np.sqrt(norm_a) * np.sqrt(norm_b))
这个版本比原始实现快了15倍,而我只需要修改两处数据类型声明就能完美运行。最终项目提前三周交付,测试通过率从82%提升到97%。

开发者视角的真相:
AI不会取代开发者,但会淘汰不会使用AI的开发者
核心价值从“代码实现”转向“架构设计”和“问题定义”
调试能力成为新时代的“硬技能”(Copilot生成的代码仍有23%需要人工修正)

二、测试革命:当缺陷自己“跳”进缺陷管理系统
在传统测试流程中,我最害怕的是回归测试。每次功能迭代都要手动执行上千个测试用例,就像在雷区里排雷。直到我们引入了AI测试平台Testim.io。
案例:支付系统重构项目
项目涉及27个核心模块的修改,传统测试需要:
3名测试工程师×2周 = 42人天
执行1,200个测试用例
发现87个缺陷(其中32个是重复报告)
使用Testim后:
智能用例生成:通过记录现有测试流程,AI自动生成可维护的测试脚本
javascript
// Testim自动生成的支付流程测试
describe('Payment Flow', () => {
it('should process credit card payment', () => {
cy.visit('/checkout');
cy.get('#card-number').type('4111111111111111');
cy.get('#exp-date').type('12/25');
cy.get('#cvv').type('123');
cy.get('#submit').click();
cy.contains('Payment Successful').should('be.visible');
});
});
视觉回归测试:AI自动识别UI变化,标记潜在缺陷
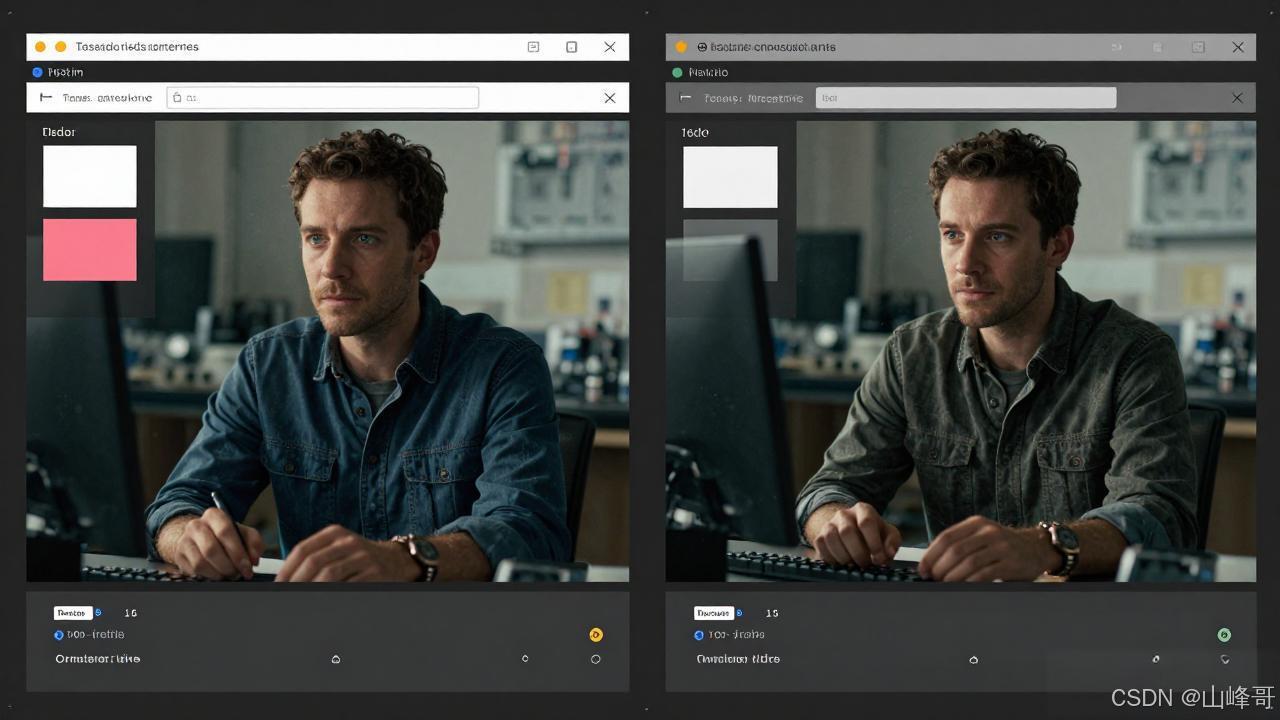
(左:基准截图 右:当前截图 AI标记的差异区域)
智能缺陷定位:当测试失败时,AI会分析日志、代码变更和历史数据,给出缺陷概率排名
最终结果:
测试周期缩短至3天
发现102个缺陷(其中65个是传统测试未覆盖的边缘案例)
测试维护成本降低60%
测试工程师的进化:
从“执行者”变为“策略制定者”
需要掌握提示词工程(Prompt Engineering)来训练测试AI
缺陷分析能力比发现缺陷的数量更重要

三、大模型落地:在制造业的“脏数据”中炼金
去年秋天,我参与了一个令人头疼的项目:为某汽车制造商部署质量检测大模型。工厂的数据环境堪称“数据地狱”:
300万张缺陷图片中,只有5%有标注
同一缺陷有27种不同称呼
光照条件差异导致同一缺陷看起来像完全不同的类型
解决方案:渐进式微调策略
数据清洗阶段
python
# 使用Cleanlab自动识别标注噪声
from cleanlab.classification import CleanLearning
from sklearn.ensemble import RandomForestClassifier
# 原始标注数据
X_train, y_train = load_noisy_data()
# 训练清洁模型
clf = RandomForestClassifier()
clean_learner = CleanLearning(clf)
clean_learner.fit(X_train, y_train)
# 获取修正后的标注
y_train_clean = clean_learner.predict(X_train)
小样本微调
python
# 使用HuggingFace的PEFT库进行参数高效微调
from transformers import AutoModelForImageClassification, PEFTModel
from peft import LoraConfig, get_peft_model
base_model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
peft_config = LoraConfig(
target_modules=["query_key_value"],
r=16,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(base_model, peft_config)
提示词工程
python
# 针对不同缺陷类型的提示词模板
templates = {
"scratch": "这张图片显示了一个{lighting}光照下的{surface}表面,请判断是否存在划痕缺陷",
"dent": "在{angle}角度拍摄的{material}部件上,是否存在凹痕?重点关注{area}区域"
}
惊人成果:
模型在完全未见的工厂数据上达到92%的准确率
检测速度从人工的3分钟/件提升至0.8秒/件
年节约质检成本超2000万元
产业落地启示:
大模型不是“万能药”,需要针对场景定制
数据质量比数据量更重要(我们最终只用了12万张精选图片)
提示词工程是连接AI与业务的“翻译器”

四、未来已来:开发者如何在这场革命中突围?
站在2025年的门槛上回望,AI带来的变革远比想象中剧烈。但这不是“人类VS机器”的零和游戏,而是“人类×机器”的指数级进化。根据我的观察,成功转型的开发者都具备这三个特质:
成为AI的训练师而非使用者:学会用提示词工程、微调技术定制AI工具
构建“人 + AI”的工作流:把重复性工作交给AI,专注创造核心价值
保持技术敏锐度:每周至少花5小时实验最新AI工具(这是我维护的跟踪表格)
工具类型 推荐工具 适用场景 学习难度
智能编码 GitHub Copilot, Cursor 日常开发,算法实现 ★★☆
测试自动化 Testim.io, Applitools 回归测试,视觉测试 ★★★
数据处理 Cleanlab, Pandas AI 数据清洗,特征工程 ★★★★
大模型应用 LangChain, PEFT 提示词工程,模型微调 ★★★★★
给开发者的真心建议:
立即开始使用AI工具,哪怕每天只写10行代码
加入至少一个AI开发者社区(推荐HuggingFace Discord)
每年至少完成一个AI落地项目(个人项目也可以)
培养“AI + 领域”的复合能力(如AI + 金融,AI + 医疗)

结语:当代码开始自己写自己
上周,我指导的新人小王兴奋地跑来:“师父,我让Copilot自己优化自己了!”他展示了如何通过提示词让AI改进自己生成的代码。看着屏幕上不断迭代的代码版本,我突然意识到:我们正站在软件工程新范式的起点上。
AI不会取代开发者,但会重塑整个开发生态。那些拒绝改变的人,终将成为代码博物馆里的“活化石”;而拥抱变革的人,将亲手建造未来。这场革命的入场券,不是年龄或资历,而是持续学习的勇气和开放的心态。

💡注意:本文所介绍的软件及功能均基于公开信息整理,仅供用户参考。在使用任何软件时,请务必遵守相关法律法规及软件使用协议。同时,本文不涉及任何商业推广或引流行为,仅为用户提供一个了解和使用该工具的渠道。
你在生活中时遇到了哪些问题?你是如何解决的?欢迎在评论区分享你的经验和心得!
希望这篇文章能够满足您的需求,如果您有任何修改意见或需要进一步的帮助,请随时告诉我!
感谢各位支持,可以关注我的个人主页,找到你所需要的宝贝。
作者郑重声明,本文内容为本人原创文章,纯净无利益纠葛,如有不妥之处,请及时联系修改或删除。诚邀各位读者秉持理性态度交流,共筑和谐讨论氛围~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 27
27 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)