4 卡 Intel B60(48G) 服务器llama.cpp测试
4 卡 Intel B60(48G) 服务器
llama.cpp完整安装及性能调优指南
一、系统与硬件准备(必做)
1.1 系统要求
- 推荐:Ubuntu 25.04 LTS(64位)
- 内核:6.14.0-1011-intel
1.2 硬件检查
|
Bash |
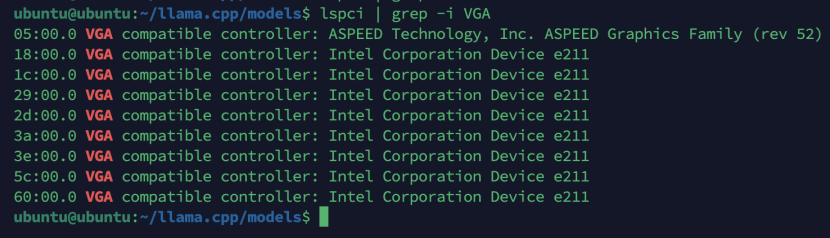
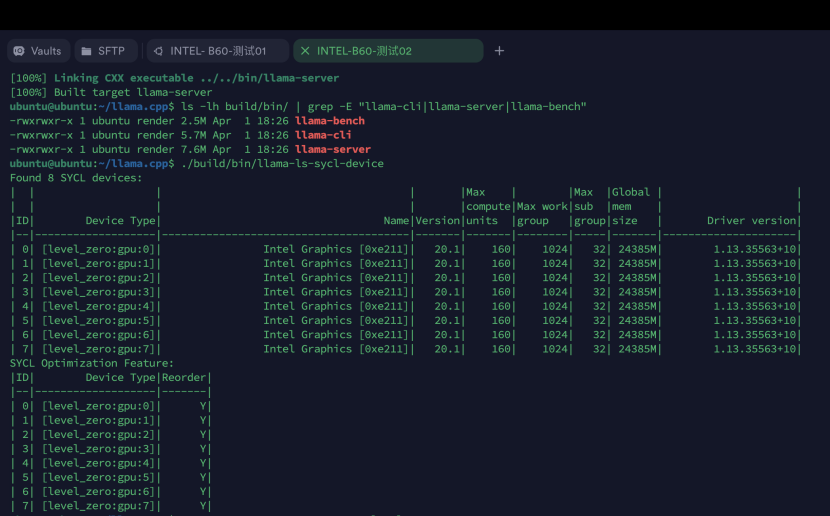
实际识别为8张显卡
二、安装Intel oneAPI工具包
2.1 下载并安装Base Toolkit
|
# 下载最新版oneAPI Base Toolkit(约3GB) cd /tmp wget https://registrationcenter-download.intel.com/akdlm/IRC_NAS/6caa93ca-e10a-4cc5-b210-68f385feea9e/intel-oneapi-base-toolkit-2025.3.1.36_offline.sh # 静默安装(接受EULA) sudo sh ./intel-oneapi-base-toolkit-2025.3.1.36_offline.sh -a --silent --cli --eula accept # 默认安装路径:/opt/intel/oneapi |
2.2 配置环境变量
|
# 临时加载(当前终端) source /opt/intel/oneapi/setvars.sh # 永久添加到bashrc echo 'source /opt/intel/oneapi/setvars.sh' >> ~/.bashrc source ~/.bashrc # 验证安装 which icx icpx icx --version |
2.3 验证SYCL设备识别
|
# 查看SYCL能识别到的所有设备 sycl-ls # 正常输出应该显示4张B60 GPU,类似: # [level_zero:gpu:0] Intel(R) Data Center GPU B60 ... # [level_zero:gpu:1] Intel(R) Data Center GPU B60 ... # [level_zero:gpu:2] Intel(R) Data Center GPU B60 ... # [level_zero:gpu:3] Intel(R) Data Center GPU B60 ... |
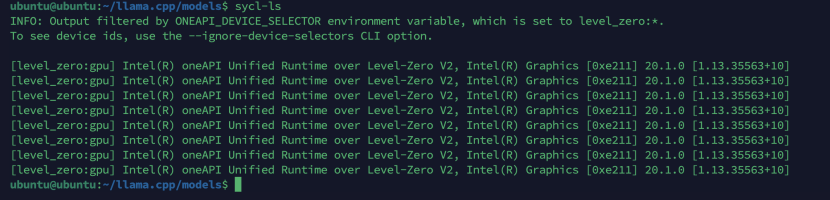
三、安装Intel多卡驱动(llama.cpp依赖)
3.1 专门的Intel多卡驱动来解决SYCL无法识别GPU的问题
|
# 1. 下载Intel多卡离线驱动(专门针对8卡B60配置) cd /tmp wget "https://cdrdv2.intel.com/v1/dl/getContent/873591/873592?filename=multi-arc-bmg-offline-installer-26.5.6.1.tar.xz" -O multi-arc-bmg-offline-installer-26.5.6.1.tar.xz # 2. 解压 tar -xvf multi-arc-bmg-offline-installer-26.5.6.1.tar.xz cd multi-arc-bmg-offline-installer-26.5.6.1 # 3. 安装驱动(会自动安装兼容内核6.14.0-1011-intel) sudo ./installer.sh # 4. 重启系统 sudo reboot |
|
uname -r # 应显示:6.14.0-1011-intel # 固定内核版本(防止自动更新破坏驱动) sudo apt-mark hold linux-image-generic linux-headers-generic # 禁用自动更新 sudo vim /etc/apt/apt.conf.d/10periodic # 将APT::Periodic::Update-Package-Lists从"1"改为"0" # 添加用户权限 sudo gpasswd -a ${USER} render sudo gpasswd -a ${USER} video newgrp render newgrp video # 验证GPU状态 xpu-smi discovery # 加载oneAPI环境并测试 source /opt/intel/oneapi/setvars.sh sycl-ls |
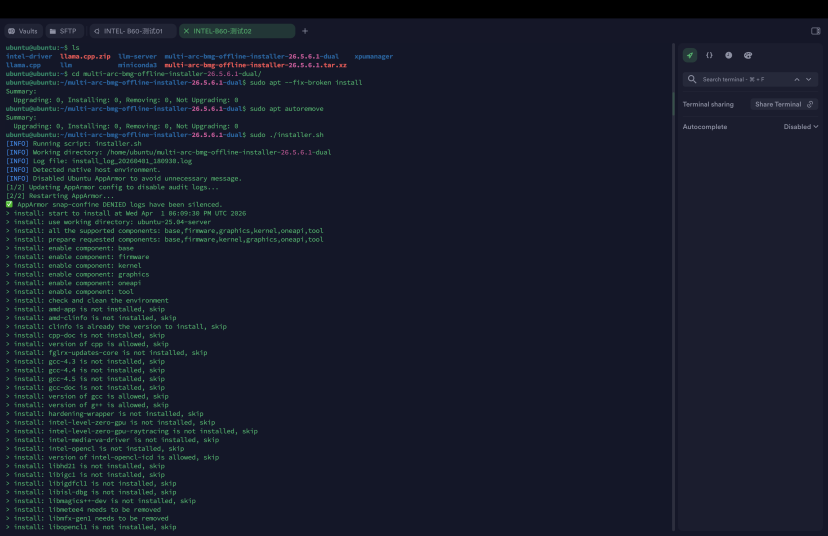
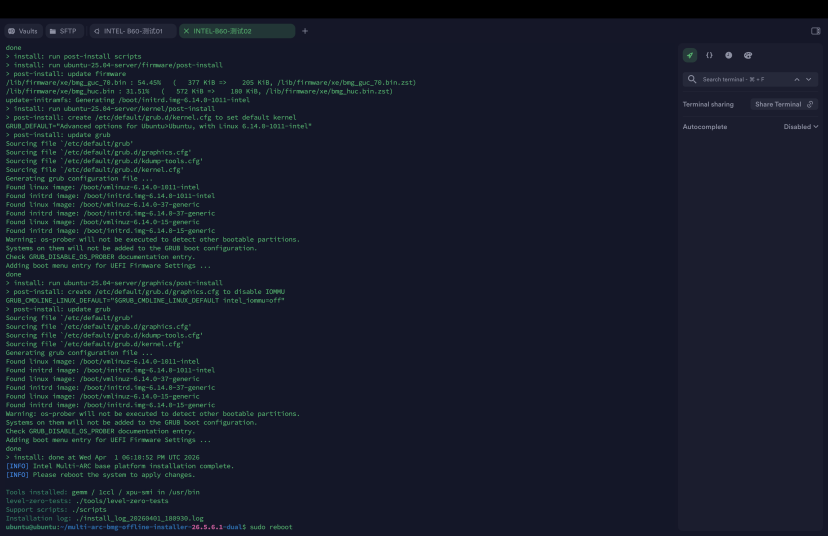
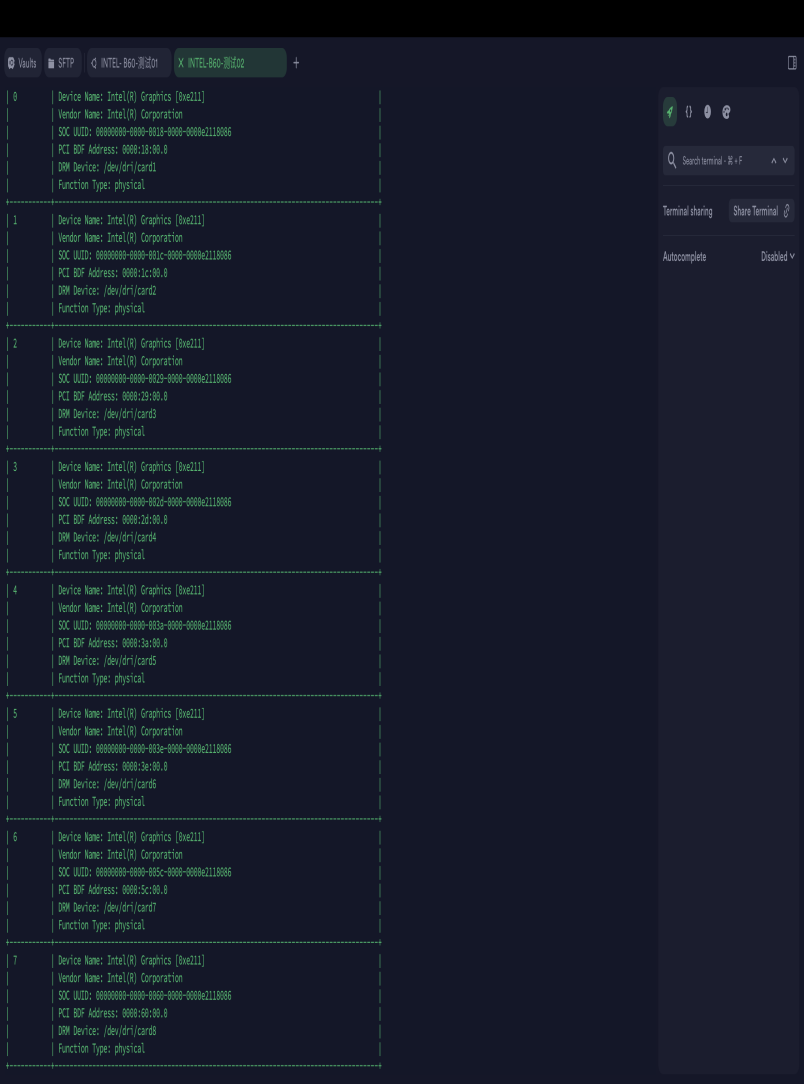
实际4卡48G被识别成为8卡
3.2 安装基础编译工具(llama.cpp多GPU核心依赖)
|
Bash |
四、安装llama.cpp编译依赖
|
Bash |
 五、编译llama.cpp
五、编译llama.cpp
5.1 克隆源码
|
Bash |
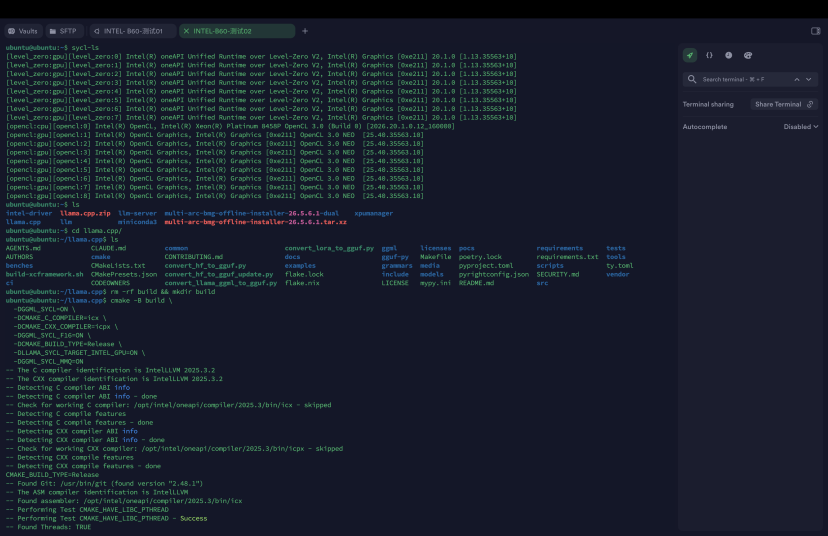
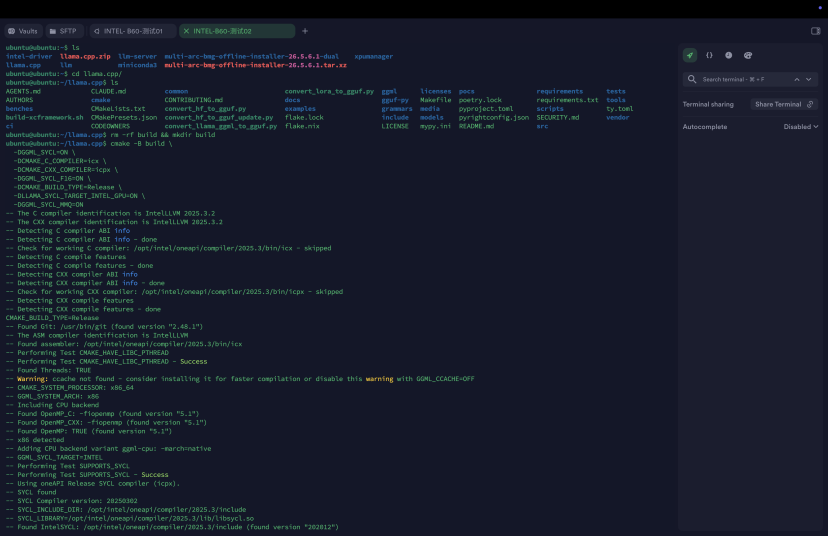
5.2 编译(开启oneAPI + 多GPU )
|
# 1. 创建项目目录 mkdir -p ~/llama-projects && cd ~/llama-projects # 2. 克隆源码(如果之前没做过) git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp git submodule update --init --recursive # 3. 确保oneAPI环境已加载 source /opt/intel/oneapi/setvars.sh --force # 4. 清理并创建构建目录 rm -rf build && mkdir build # 5. 配置CMake(针对8卡B60优化) cmake -B build \ -DGGML_SYCL=ON \ -DCMAKE_C_COMPILER=icx \ -DCMAKE_CXX_COMPILER=icpx \ -DGGML_SYCL_F16=ON \ -DCMAKE_BUILD_TYPE=Release \ -DLLAMA_SYCL_TARGET_INTEL_GPU=ON \ -DGGML_SYCL_MMQ=ON # 6. 并行编译(使用所有CPU核心) cmake --build build --config Release -j $(nproc) |
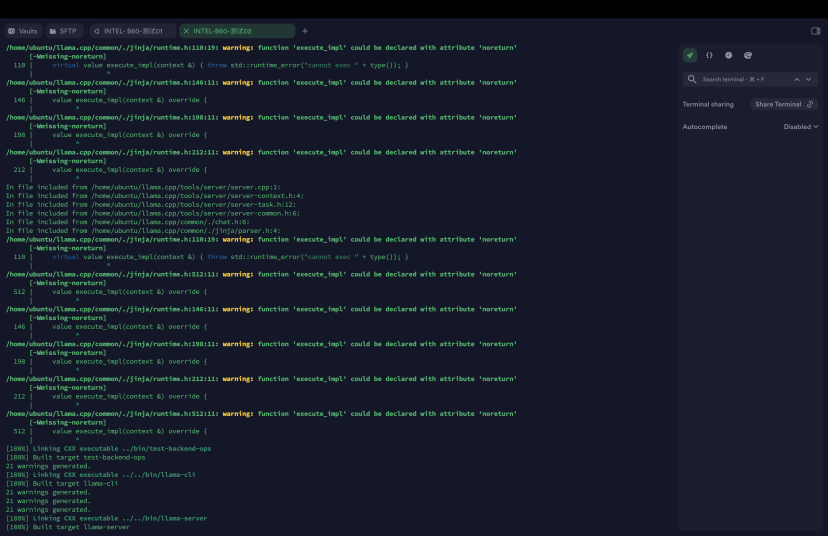
5.3 验证编译
|
# 1. 验证可执行文件 ls -lh build/bin/ | grep -E "llama-cli|llama-server|llama-bench" # 2. 查看SYCL设备(专用工具) ./build/bin/llama-ls-sycl-device |
六、准备GGUF模型(测试用)
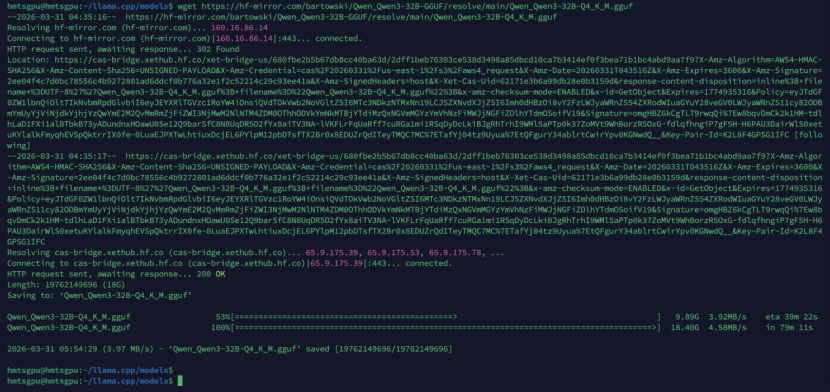
6.1 下载测试模型(以Qwen3 32B Q4_K_M为例)
|
Bash
|
七、4卡Intel B60 llama.cpp测试(核心步骤)
7.1 单卡基础测试(验证CUDA)
|
Bash ./build/bin/llama-cli \ -m models/Qwen_Qwen3-32B-Q4_K_M.gguf \ --gpu-layers 99 \ -t 64 \ -c 4096 \ -p "你好" |
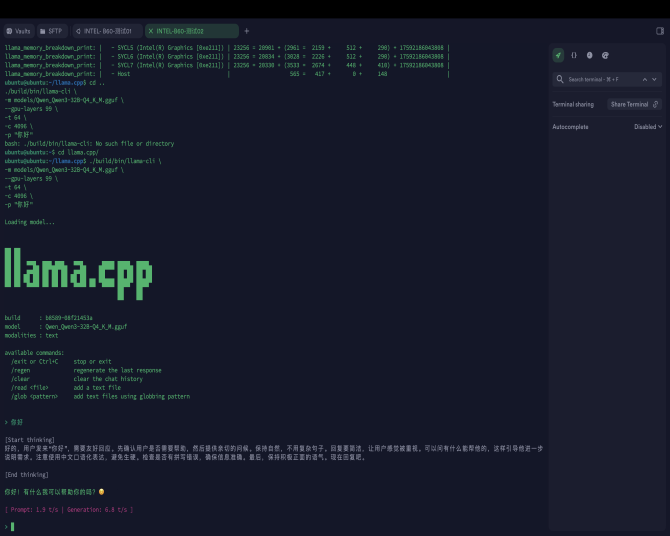
[ Prompt: 1.9 t/s | Generation: 6.8 t/s ]
7.2 8卡并行测试(多GPU自动负载均衡)
llama.cpp 自动识别所有NVIDIA GPU,无需手动指定卡ID。
|
Bash -m models/Qwen_Qwen3-32B-Q4_K_M.gguf \ -n 1024 \ --gpu-layers 99 \ -t 32 \ -c 16384 \ -p "撰写关于8x RTX 5090服务器用于大语言模型(LLM)推理的技术概述。" \ --batch-size 1024 \ --mlock \ --flash-attn on |
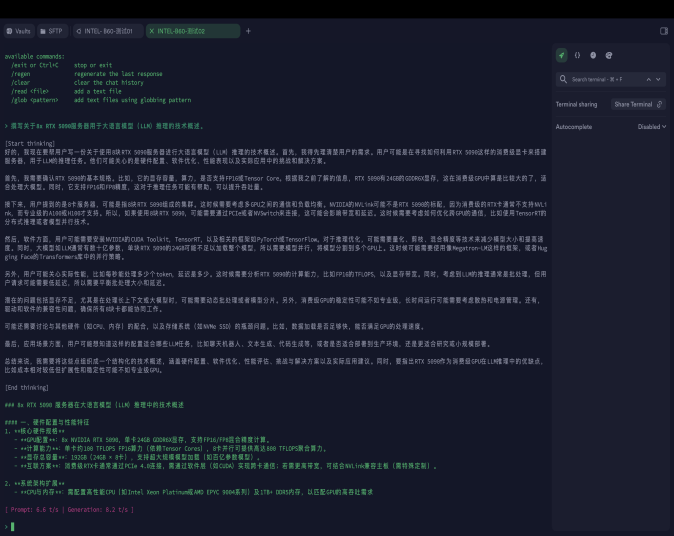
[ Prompt: 6.6 t/s | Generation: 8.2 t/s ]
7.3 4卡显存与负载验证
新开终端,实时监控:
|
Bash |
八、性能调优
8.1 关键参数优化
|
Bash -m models/Qwen_Qwen3-32B-Q4_K_M.gguf \ -n 2048 \ --gpu-layers 99 \ -t 64 \ -c 32768 \ -p "撰写关于8x RTX 5090服务器用于大语言模型(LLM)推理的技术概述。" \ --batch-size 2048 \ --mlock \ --flash-attn on \ --no-mmap \ --numa distribute |
|
-n 2048:将最大生成token数提升至2048,满足更长篇幅的技术概述撰写需求; -t 64:分配64个CPU线程,匹配多GPU并行推理的CPU调度需求,提升协同效率; -c 32768:将上下文长度提升至32768,支持更长文本输入与生成,适配技术概述的深度撰写; --batch-size 2048:提升批量推理效率,适配8×RTX 5090多GPU并行算力; --mlock:锁定内存,避免内存交换(swap),提升多GPU推理稳定性; --flash-attn on:启用Flash Attention优化,充分发挥RTX 5090硬件性能,显著提升推理速度; --no-mmap:禁用内存映射(mmap),减少内存开销,进一步提升多GPU协同推理速度; --numa distribute:启用NUMA(非统一内存访问)优化,采用“distribute”模式,将执行任务均匀分配到所有CPU节点,适配多CPU节点服务器,平衡CPU与多GPU之间的内存访问效率,避免资源瓶颈 |
[ Prompt: 6.5 t/s | Generation: 8.3 t/s ]
九、最终验证
执行以下命令,确认 4卡B60 (48G)全量工作:
|
Bash -m models/Qwen_Qwen3-32B-Q4_K_M.gguf \ -n 4096 \ --gpu-layers 99 \ -t 64 \ -c 32768 \ -p "阐述8x RTX 5090在大型语言模型部署中的优势。" \ --batch-size 2048 \ --mlock \ --flash-attn on |
[ Prompt: 5.4 t/s | Generation: 8.2 t/s ]
十、输出测试效果:
# 使用 llama-bench 正确的参数格式
./build/bin/llama-bench \
-m models/Qwen_Qwen3-32B-Q4_K_M.gguf \
-t 64 \
-p 512,2048,8192 \
-n 128,512,2048 \
-ngl 99 \
-b 2048 \
-ub 512 \
-fa 1 \
-r 3 \
2>&1 | tee benchmark_results.txt
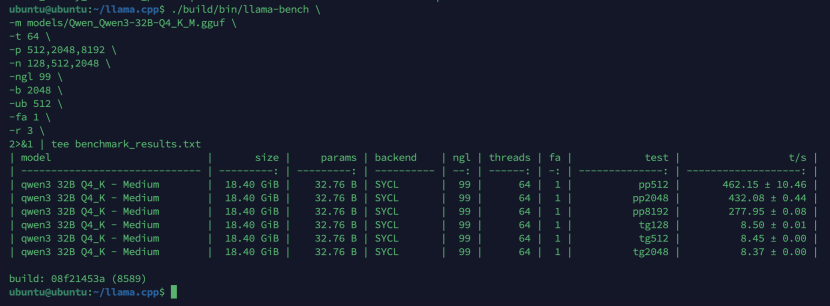
| model | size | params | backend | ngl | threads | fa | test | t/s |
| -------------------- | ------ | ----- : | ------ | --| --- : | -| -------: | ------------|
| qwen3 32B Q4_K - Medium | 18.40 GiB| 32.76 B | SYCL | 99 | 64 | 1 | pp512 | 462.15 ± 10.46 |
| qwen3 32B Q4_K - Medium | 18.40 GiB| 32.76 B | SYCL | 99 | 64 | 1 | pp2048 | 432.08 ± 0.44 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | SYCL| 99 | 64 | 1 | pp8192 | 277.95 ± 0.08 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | SYCL| 99 | 64 | 1 | tg128 | 8.50 ± 0.01 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | SYCL| 99 | 64 | 1 | tg512 | 8.45 ± 0.00 |
| qwen3 32B Q4_K - Medium| 18.40 GiB | 32.76 B | SYCL| 99 | 64 | 1 | tg2048 | 8.37 ± 0.00 |
build: 08f21453a (8589)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)