一文带你快速入门 LangChain4j
文章目录
LangChain4j 学习笔记
基本介绍
本章节主要介绍:
- LangChain4j 是什么
- 为什么需要 LangChain4j
- LangChain4j 的价值体现
- LangChain4j 的两层抽象
- LangChain4j 中模型的分类
- LangChain4j 的应用场景
- LangChain4j 和 Spring AI 的比较
-
LangChain4j 是什么
LangChain4j 是一个专为 Java 和 Kotlin 开发者设计的开源框架,旨在简化将大型语言模型(LLM)集成到应用程序中的过程。你可以将它理解为 Python 生态中流行的 LangChain 框架在 JVM 平台上的“兄弟”,但它并非官方移植版本,而是为 Java 开发者量身打造,遵循 Java 的编程习惯和设计理念。LangChain4j 的核心目标是让 Java 开发者能够轻松构建由 AI 驱动的应用,例如聊天机器人、问答系统、智能代理(Agent)等
- LangChain4j英文文档:Introduction | LangChain4j
- LangChain4j中文文档:介绍 | LangChain4j 中文文档
-
为什么需要 LangChain4j
当ChatGPT、QwenLM、DeepSeek等大语言模型(LLM)横空出世时,开发者们立刻意识到:LLM不是终点,而是构建智能应用的“大脑”。但要让这个“大脑”真正解决实际问题,还需要解决三个关键痛点:
-
信息过时:LLM 的知识截止于训练数据的时间节点(如GPT-4的训练数据截止到2023年),无法回答诸如“2024年最新AI论文内容”或“今天纽约股市收盘价”这样的问题。
-
无法动手:LLM 虽然能生成自然语言,但它不能执行外部操作,比如调用API、计算数值、查询数据库、发送邮件等。它就像一个只会思考的“脑壳”,没有“手脚”。
-
记忆有限:LLM 的上下文窗口(例如GPT-4最多支持32,768个tokens)限制了它处理长文本的能力,难以记住对话历史或文档细节。
因此,我们需要一个框架,将 LLM 的“大脑”与“感官(数据)”、“手脚(工具)”、“记忆(上下文)”连接起来,让它从“聊天机器人”升级为“能解决具体问题的助手”,于是 LangChain4j 便诞生了
-
-
LangChain4j 主要价值体现:
- 易学性:统一了个各个模型厂商的 API, LangChain4j 提供了一套统一的接口,让你可以轻松地在不同模型和存储之间切换,而无需重写大量代码。目前它已支持 15+ 个主流 LLM 提供商和 20+ 个向量存储。
- 易用性: 它封装了构建 LLM 应用时常见的模式和组件,提供了一个“开箱即用”的工具箱。这包括了从底层的提示词模板、聊天记忆管理、函数调用,到高级的 RAG(检索增强生成)和 Agent 等功能。
- 与 JVM 生态无缝集成: 作为纯 Java 框架,它可以与 Spring Boot、Hibernate 等成熟的 Java 生态组件无缝结合,非常适合用于构建企业级应用。
-
LangChain4j 的两层抽象:
-
低层次(Low-level): 在这个层面,你可以直接使用
ChatModel、UserMessage、EmbeddingStore等基础组件。这提供了最大的自由度,让你可以完全控制应用的构建方式,但需要编写更多的“胶水代码”来组合这些组件。 -
高层次(High-level): 这是 LangChain4j 最具特色的部分。通过像
AiService这样的高级 API,你可以用声明式的方式与 LLM 交互。这种方式隐藏了底层的复杂性,让你能更专注于业务逻辑。
-
-
LangChain4j 种模型分类:在 LangChain 框架中,大语言模型主要根据交互方式和输出形态被划分为三大核心类型
模型类型 输入形式 输出形式 核心优势 典型应用场景 聊天模型 (Chat Model) 消息列表 (System/Human/AI) AI 消息对象 (AIMessage) 理解上下文,支持多轮交互与角色设定 智能助手、客服机器人、Agent 工具调用 文本生成模型 (LLM) 纯文本字符串 纯文本字符串 结构简单,适合单向生成任务 文章摘要、代码补全、文本润色 文本嵌入模型 (Embeddings) 文本字符串/列表 向量数组 (List[float]) 将文本转化为可计算的语义向量 语义搜索、RAG 知识库检索、推荐系统 -
LangChain4j 的应用场景
- 您希望实现一个自定义 AI 聊天机器人,可以访问您的数据并按照设定的方式运行
- 客服机器人:
- 礼貌回答客户问题
- 处理订单变更或取消
- 教学助手:
- 授课不同学科内容
- 解释难点
- 评估用户的理解与知识水平
- 客服机器人:
- 您希望处理大量非结构化数据(文件、网页等),并提取结构化信息
- 从客户评价和客服对话中提取洞察
- 从竞争对手网站提取有价值信息
- 从应聘者简历中提取关键信息
- 您希望生成信息
- 为客户生成个性化邮件
- 为应用或网站生成内容,如博客文章、故事等
- 您希望对信息进行转换
- 总结
- 校对与改写
- 翻译
- 您希望实现一个自定义 AI 聊天机器人,可以访问您的数据并按照设定的方式运行
-
LangChain4j 和 Spring AI 的比较
维度 LangChain4j Spring AI 出身背景 社区驱动,功能迭代快 Spring 官方团队出品 生态绑定 Spring生态的AI标准扩展 框架无关,可在任何Java项目中运行 功能特性 功能更丰富,尤其在 RAG 和 Agent 方面 核心功能稳健,与 Spring 生态集成度更高 编程风格 声明式接口 ( @AiService) + 链式 APIClient/Template模式 + 配置驱动上手难度 低 (对Spring开发者而言) 中 (需理解其核心概念) 核心优势 企业级集成、自动配置、可观测性 功能全面、模型/工具支持广泛、社区活跃 适用场景 复杂的 AI 应用(多 Agent、复杂 RAG) 标准企业应用,快速集成基础对话能力
快速上手
现在让我们在纯 Java 环境下创建一个 LangChain4j 的 Demo,实现对大模型的调用
-
Step1:创建 Maven 工程
-
Step2:配置依赖
<properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <langchain4j.version>1.3.0</langchain4j.version> </properties> <dependencies> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> </dependency> </dependencies> <!-- 使用 BOM (Bill of Materials) 统一管理 langchain4j 相关依赖的版本 --> <dependencyManagement> <dependencies> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-bom</artifactId> <version>${langchain4j.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>注意:LangChain4j 要求 JDK 版本最低是 17
-
Step3:编写测试类
public static void main(String[] args) { OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("http://langchain4j.dev/demo/openai/v1") .apiKey("demo") .modelName("gpt-4o-mini") .build(); String answer = model.chat("介绍一下LangChain4j"); System.out.println(answer); }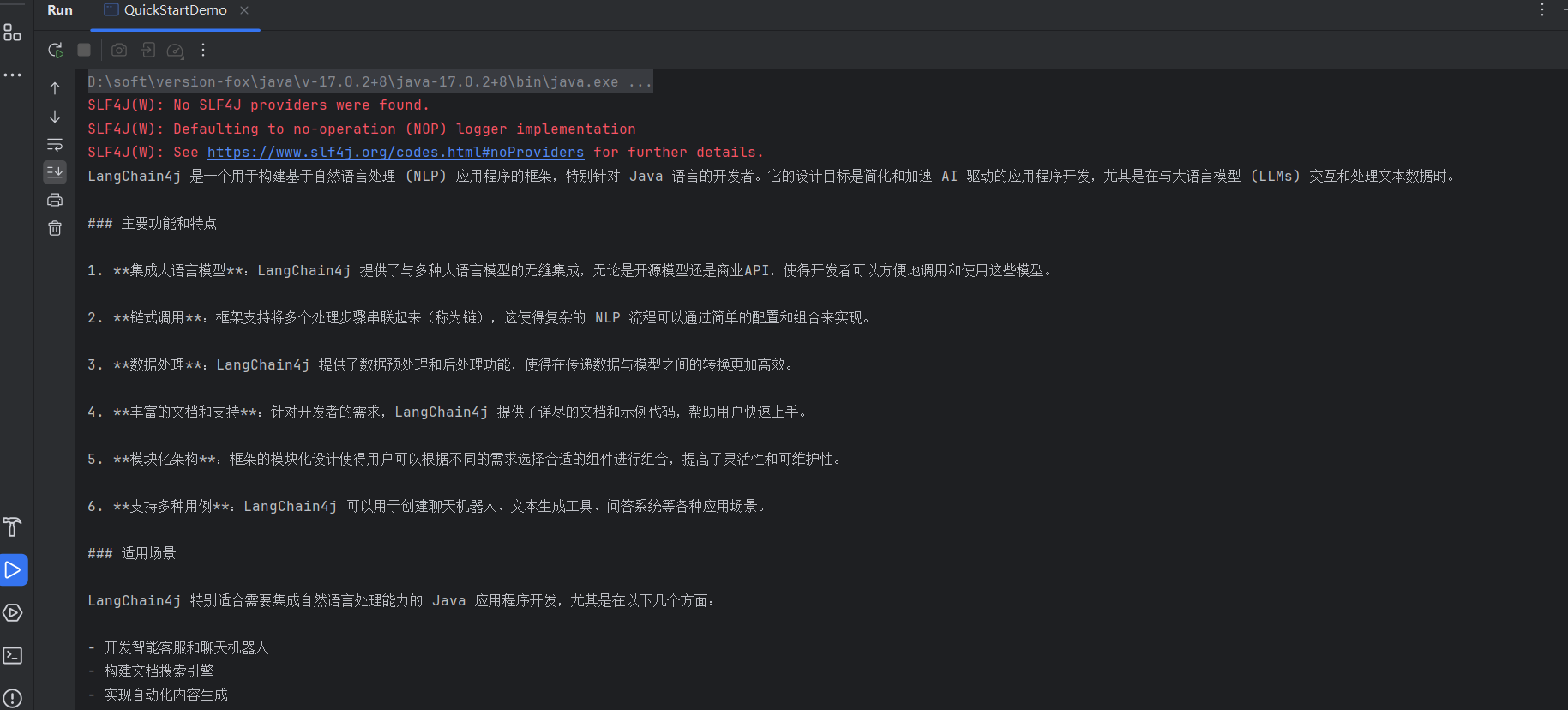
SpringBoot 整合 LangChain4j
上一章节我们在快速上手中,体验了在 Maven 工程中创建第一个 LangChain4j 程序,是一个很纯净的 Java 环境,但是在实际生产开发中,我们通常需要在 Spring 环境下来进行整合,这章节我们将快速学习 SpringBoot 整合 LangChain4j 创建我们第一个 SpringBoot 环境下的 LangChai4j 程序
-
Step1:创建Maven工程
-
Step2:引入依赖
<!-- Spring Boot 父项目依赖,提供版本管理和默认配置 --> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.3.8</version> <relativePath/> </parent> <dependencies> <!--SpringBoot 整合 langchain4j 依赖--> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai-spring-boot-starter</artifactId> </dependency> <!--SpringBoot启动依赖,提供 SpringBoot 环境--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot</artifactId> </dependency> <!-- Spring Boot 测试依赖,提供单元测试和集成测试支持 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <dependencyManagement> <dependencies> <!-- langchain4j 版本控制依赖,管理 langchain4j 相关依赖的版本 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-bom</artifactId> <version>${langchain4j.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> -
Step3:编写配置文件
server: port: 8080 langchain4j: open-ai: chat-model: api-key: demo base-url: http://langchain4j.dev/demo/openai/v1 model-name: gpt-4o-mini temperature: 0.7 -
Step4:编写测试类
@Autowired private OpenAiChatModel openAiChatModel; @Test public void test(){ String response = openAiChatModel.chat("Hello, how are you?"); System.out.println(response); }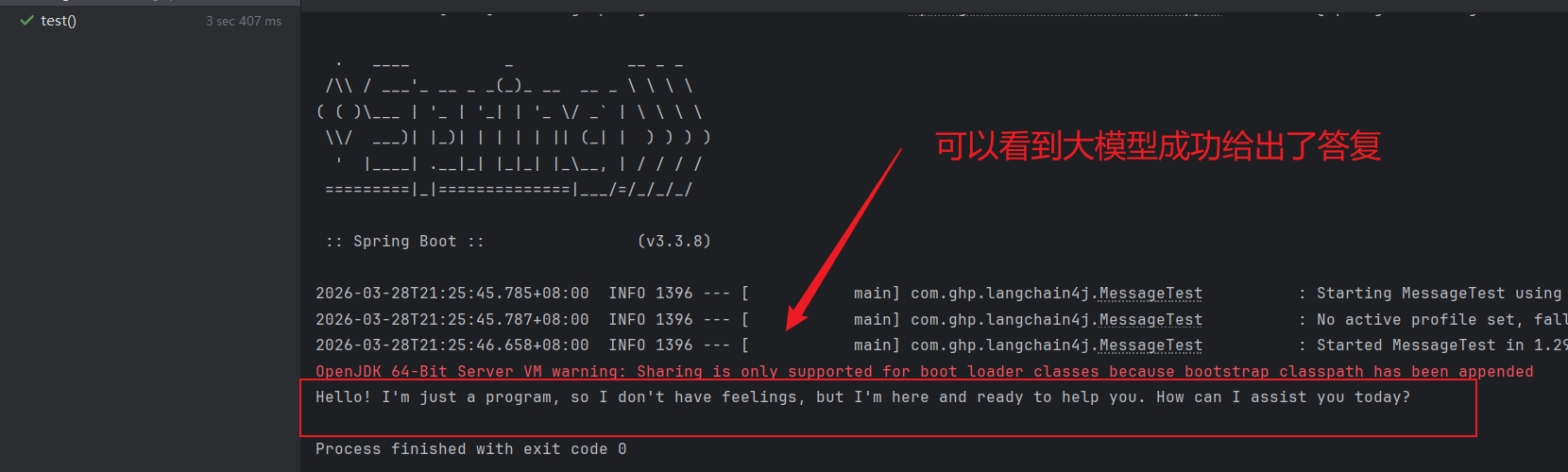
接口介绍
LangChain4j 中存在两类API,一类是低阶API,低阶 API 是 LangChain4j 的基石。它直接对应大模型的原生能力。如果你需要精确控制
temperature、topP,或者需要手动拼接复杂的 Prompt 模板,低阶 API 是首选;一类是高阶API,高阶 API(通常称为 AI Services)是 LangChain4j 对 Java 开发者的“杀手锏”,它采用了类似 Spring Data JPA 或 Retrofit 的风格(定义接口,框架自动实现),将复杂的逻辑(如:记忆管理、工具调用、RAG 检索)封装在注解和配置中,让业务代码极其干净
| 特性 | 低阶 API | 高阶 API (AI Services) |
|---|---|---|
| 核心接口 | ChatLanguageModel, EmbeddingModel |
AiServices, @SystemMessage, @Tool |
| 控制粒度 | 极高 (手动管理每一个请求参数) | 中等 (声明式配置,框架自动处理) |
| 开发体验 | 类似写原生的 HTTP 请求,代码量较多 | 类似写 Java 接口 (Interface),代码简洁 |
| 状态管理 | 需手动维护 List<ChatMessage> |
自动通过 @MemoryId 或配置管理 |
| 适用场景 | 需要精细控制 Prompt、参数、底层调试 | 快速构建业务应用、企业级开发、RAG |
低阶接口介绍
本章节主要介绍 LangChain4j 中六大核心低阶接口,六大接口覆盖对话生成、向量表示、图像、安全、评分等关键能力,是构建 LLM 应用(尤其是 RAG、Agent)的基础组件
| 接口类型 | 核心任务 | 输入类型 | 输出类型 | 典型应用场景 |
|---|---|---|---|---|
| ChatModel | 多轮对话交互 | 消息列表 | AI 消息对象 (AiMessage) 包含文本、思考过程或工具调用请求 |
智能客服、复杂助手、Agent 任务 |
| LanguageModel | 简单文本补全 | 纯文本字符串 | 纯文本字符串 (String) |
已逐渐被淘汰,仅用于极简单的单向生成 |
| EmbeddingModel | 文本向量化 | 文本字符串 | 浮点数数组 (向量) | 语义搜索、RAG 知识库检索 |
| ImageModel | 图像生成/处理 | 文本提示词 / 图像 | 图像 URL / Base64 | 营销素材生成、AI 绘画 |
| ModerationModel | 内容安全检测 | 文本 / 图像 | 违规标签 / 布尔值 | 敏感词过滤、合规审查 |
| ScoringModel | 质量/相关性评分 | 文本对 (查询 + 内容) | 分数 (0.0-1.0) | RAG 重排序 (Re-ranking) |
接口具体演示,这里使用接口的具体实现类进行演示
public class QuickStartDemo {
private static final String BASE_URL = "http://langchain4j.dev/demo/openai/v1";
private static final String API_KEY = "demo";
public static void main(String[] args) {
// FIXME OpenAiLanguageModel 使用的是旧的 /completions API 端点,而演示环境 langchain4j.dev/demo/openai/v1 不支持这个端点会导致报错
System.out.println("=== 测试 LanguageModel ===");
testLanguageModel();
System.out.println("\n=== 测试 ChatModel ===");
testChatModel();
System.out.println("\n=== 测试 EmbeddingModel ===");
testEmbeddingModel();
System.out.println("\n=== 测试 ImageModel ===");
testImageModel();
System.out.println("\n=== 测试 ModerationModel ===");
testModerationModel();
System.out.println("\n=== 测试 ScoringModel ===");
testScoringModel();
}
/**
* 测试 LanguageModel - 语言模型基础接口
*/
public static void testLanguageModel() {
// LanguageModel 是 LangChain4j 中语言模型的基础接口
// 提供了 generate(String) 和 generate(List<T>) 方法用于文本生成
LanguageModel model = OpenAiLanguageModel.builder()
.baseUrl(BASE_URL)
.apiKey(API_KEY)
.modelName("gpt-4o-mini")
.build();
String answer = model.generate("用一句话概括人工智能").content();
System.out.println("回答: " + answer);
}
/**
* 测试 ChatModel - 基本对话
*/
public static void testChatModel() {
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl(BASE_URL)
.apiKey(API_KEY)
.modelName("gpt-4o-mini")
.build();
String answer = model.chat("介绍一下LangChain4j");
System.out.println("回答: " + answer);
}
/**
* 测试 EmbeddingModel - 将文本转换为向量嵌入
*/
public static void testEmbeddingModel() {
// EmbeddingModel 可以将文本转换为 Embedding(向量表示)
// 常用于语义搜索、文本相似度计算等场景
EmbeddingModel model = OpenAiEmbeddingModel.builder()
.baseUrl(BASE_URL)
.apiKey(API_KEY)
.modelName("text-embedding-ada-002")
.build();
// 将文本转换为向量
String text = "LangChain4j 是一个用于 Java 的 LLM 应用开发框架";
Response<Embedding> response = model.embed(text);
Embedding embedding = response.content();
System.out.println("文本: " + text);
System.out.println("向量维度: " + embedding.dimension());
System.out.println("向量前5个值: " + Arrays.toString(
Arrays.copyOf(embedding.vector(), 5)));
}
/**
* 测试 ImageModel - 生成和编辑图像
*/
public static void testImageModel() {
// ImageModel 可以根据文本描述生成图像,或对现有图像进行编辑
// 注意:图像生成可能需要较长时间
ImageModel model = OpenAiImageModel.builder()
.baseUrl(BASE_URL)
.apiKey(API_KEY)
.modelName("dall-e-3")
.build();
String prompt = "一只可爱的橘猫在草地上玩耍,卡通风格";
System.out.println("图像生成提示词: " + prompt);
System.out.println("正在生成图像... (演示环境可能不支持实际生成)");
try {
Response<Image> response = model.generate(prompt);
Image image = response.content();
System.out.println("图像 URL: " + image.url());
} catch (Exception e) {
System.out.println("图像生成失败 (演示环境限制): " + e.getMessage());
}
}
/**
* 测试 ModerationModel - 内容审核
*/
public static void testModerationModel() {
// ModerationModel 可以检查文本是否包含有害内容
// 常用于用户输入过滤、内容安全检测等场景
ModerationModel model = OpenAiModerationModel.builder()
.baseUrl(BASE_URL)
.apiKey(API_KEY)
.modelName("text-moderation-latest")
.build();
// 测试正常文本
String safeText = "LangChain4j 是一个很好用的 Java AI 框架";
Response<Moderation> safeResponse = model.moderate(safeText);
System.out.println("文本: " + safeText);
System.out.println("是否包含有害内容: " + safeResponse.content().flagged());
// 测试可能有害的文本
String riskyText = "我想学习如何做一些危险的事情";
Response<Moderation> riskyResponse = model.moderate(riskyText);
System.out.println("\n文本: " + riskyText);
System.out.println("是否包含有害内容: " + riskyResponse.content().flagged());
}
/**
* 测试 ScoringModel - 文本相关性打分
*/
public static void testScoringModel() {
// ScoringModel 可以针对查询对多段文本进行打分或排序
// 常用于搜索结果排序、文档相关性评估等场景
// 注意:OpenAI 官方没有直接的 ScoringModel,这里使用 EmbeddingModel 计算相似度作为示例
EmbeddingModel model = OpenAiEmbeddingModel.builder()
.baseUrl(BASE_URL)
.apiKey(API_KEY)
.modelName("text-embedding-ada-002")
.build();
String query = "Java 编程语言";
List<String> documents = Arrays.asList(
"Java 是一种面向对象的编程语言",
"Python 在数据科学领域很流行",
"Java 虚拟机是 Java 程序的运行环境",
"JavaScript 主要用于网页开发"
);
System.out.println("查询: " + query);
System.out.println("\n文档相关性评分 (使用余弦相似度):");
// 获取查询的向量
Response<Embedding> queryEmbedding = model.embed(query);
float[] queryVector = queryEmbedding.content().vector();
// 计算每个文档与查询的相似度
for (String doc : documents) {
Response<Embedding> docEmbedding = model.embed(doc);
float[] docVector = docEmbedding.content().vector();
double similarity = cosineSimilarity(queryVector, docVector);
System.out.printf(" [%.4f] %s%n", similarity, doc);
}
}
/**
* 计算两个向量的余弦相似度
*/
private static double cosineSimilarity(float[] vector1, float[] vector2) {
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int i = 0; i < vector1.length; i++) {
dotProduct += vector1[i] * vector2[i];
norm1 += Math.pow(vector1[i], 2);
norm2 += Math.pow(vector2[i], 2);
}
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
}
高阶接口介绍
高阶 API(通常称为 AI Services)是 LangChain4j 对 Java 开发者的“杀手锏”。它采用了类似 Spring Data JPA 或 Retrofit 的风格:定义接口,框架自动实现。它将复杂的逻辑(如:记忆管理、工具调用、RAG 检索)封装在注解和配置中,让业务代码极其干净
| 注解 | 作用 | 示例 |
|---|---|---|
@SystemMessage |
定义系统级指令(人设)。 | @SystemMessage("你是数学专家") |
@UserMessage |
定义用户提示词模板,支持变量替换。 | @UserMessage("翻译这句话: {{it}}") |
@MemoryId |
标识对话的会话 ID,用于区分不同用户的记忆。 | String chat(@MemoryId String userId, ...) |
-
Step1:创建接口
@AiService public interface ChatService { /** * 聊天 * @param message * @return */ @SystemMessage("你是一个资深的Java大师") String chat(@UserMessage String message); } -
Step2:调用接口
@Autowired private ChatService chatService; /** * 测试高级API * @param userMessage * @return */ @GetMapping(value = "/api/high") public String highLevelChat(@RequestParam String userMessage) { return chatService.chat(userMessage); }
除了上述 @AiService 方式以外,还可以直接通过 AiServices.create 来创建
AiServices.create(ChatService.class, chatModel).chat(userMessage);
消息类型
LangChain4j 中总共有物种消息类型,分别是系统消息(SystemMessage)、用户消息(UserMessage)、助手消息(AiMessage)、工具消息(ToolExecutionResultMessage)、自定义消息(CustomMessage)
| 消息类型 | 对应角色 | 作用与场景 |
|---|---|---|
| 系统消息(SystemMessage) | 系统 | “立规矩”。通常作为对话的第一条消息,用于设定 AI 的人设、行为准则或背景知识。例如:“你是一个专业的 Java 助手”。 |
| 用户消息(UserMessage) | 用户 | “提问题”。代表真实用户(或调用者)的输入。它不仅包含文本,在支持多模态的模型中,还可以包含图片、音频等内容。 |
| 助手消息(AiMessage) | 助手 | “给回答”。代表 AI 生成的回复。除了文本内容,它还可以包含“思考过程”或“工具调用请求”(比如 AI 说“我要调用天气接口”)。 |
| 工具消息(ToolExecutionResultMessage) | 工具 | “返结果”。当 AI 请求调用工具后,外部系统执行完工具,需要将结果封装成这种消息返回给 AI,告诉它“接口调用成功了,结果是XXX”。 |
| 自定义消息(CustomMessage) | 自定义 | “特殊用途”。一种灵活的消息类型,允许你定义任意角色(Role)。目前主要用于支持特定模型(如 Ollama)的特殊属性。 |
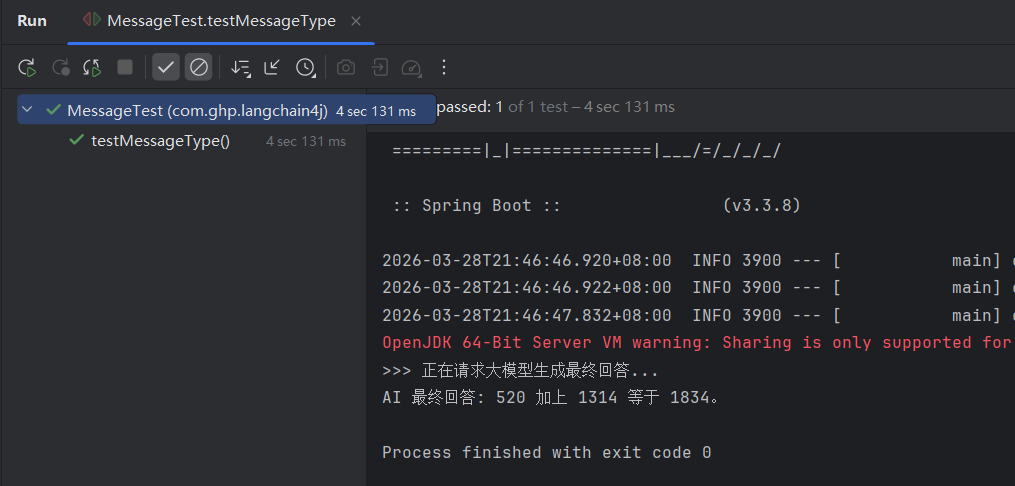
为了展示这四种核心消息类型在实际代码中是如何创建和流转的,这里模拟了一个“智能助手调用计算器”的完整闭环流程
@Test
public void testMessageType(){
List<ChatMessage> messages = new ArrayList<>();
// 1、创建系统消息:确定 AI 的角色和行为(立规矩)
SystemMessage systemMessage = SystemMessage.from("你是一个数学助手。如果用户需要计算,请调用计算器工具。");
messages.add(systemMessage);
// 2、创建用户消息:模拟用户提出问题(提问题)
UserMessage userMessage = UserMessage.from("请帮我计算 520 加上 1314 等于多少?");
messages.add(userMessage);
// 3、创建助手消息:AI 响应用户消息,并给出一个工具调用请求(给回答)
// 注意:通常这一步是模型返回的,这里为了演示流程,我们模拟模型返回了一个“工具调用请求”
// 假设 AI 决定调用名为 "calculator" 的工具,参数是 a=520, b=1314
ToolExecutionRequest request = ToolExecutionRequest.builder()
.name("calculator")
.arguments("{\"a\": 520, \"b\": 1314}")
.build();
AiMessage aiMessage = AiMessage.from(request);
messages.add(aiMessage);
// 4、创建工具消息:模拟工具执行结果(给结果)
// 这里模拟你的 Java 代码执行了加法运算,得到结果 1834
String calculationResult = "1834";
ToolExecutionResultMessage resultMessage = ToolExecutionResultMessage.from(request, calculationResult);
messages.add(resultMessage);
// 5、现在,我们将包含所有历史(系统指令、用户问题、AI意图、工具结果)的列表发给模型,让 AI 根据结果生成最终回答
System.out.println(">>> 正在请求大模型生成最终回答...");
String response = openAiChatModel.chat(messages).aiMessage().text();
// 预期输出:520 加上 1314 等于 1834。
System.out.println("AI 最终回答: " + response);
}
提示词工程
Prompt 介绍
-
Prompt 是什么?
Prompt 翻译过来就是“提示”,它是你给 AI 的 “指令 + 上下文”,用来告诉 AI 要做什么、怎么做
-
Prompt 和 Message 有什么区别?
Prompt 是一个更加广泛的概念,指的是你给模型的任何输入,目的是引导它产生你想要的输出。Message 是一个更加具体的概念,用户发送的消息,称为 userMessage,系统给出的消息,称之为 systemMessage,相当于给模型的输入信息进行了一个更加细化的分类。
Prompt 包含了 Message,Prompt 好比一个剧本,Message 就是剧本中的一句台词。
追问:为啥模型 API 即提供了 prompt 方法,有提供了 message 方法
因为我们在构建大模型应用时,特别是多轮对话场景,我们需要构建 message 列表,然后放入 prompt 实现大模型上下文感知,而没次的单论对话就只需要放入对应的 message 中。你可以理解为 prompt 方法是用于给开发者构建模型上下文的,提高回复的流畅度和准确性,而 message 方法细化每轮对话,让每轮对话更加精确,两者相辅相成,目的都是为了让模型的回复更加精确
-
一个完整的 Prompt 包含哪些内容?
- 角色设定:你是谁?例如:“你是一名资深 Java 后端工程师,帮我审查代码”
- 任务目标:要做什么事?例如:“帮我优化这段接口代码,提升性能。”
- 输入内容:给 AI 材料,例如:“代码如下:……”
- 输出要求:格式、风格、长度、语言,例如:“用中文解释,分点说明,不要废话,最后给出优化后代码。”
- 约束条件:限制、禁忌,例如:“不要改动业务逻辑,只优化查询效率。”
-
Prompt 的作用
- 控制 AI 输出的内容
- 控制输出格式
- 提高准确性
- 让 AI 模仿风格
提示词模板
-
低阶API:k-v 键值对,key为
{{it}}时,v 可以是任何参数,key为{{xxx}}非it时,此时 value 参数名必须和 xxx 保持一致// 用户输入 String role = "Java"; String question = "OOM该如何处理"; // 定义模板 PromptTemplate template = PromptTemplate.from("你是一个{{it}}助手,请回答{{qustion}}"); Prompt prompt = template.apply(Map.of("it", role, "question", question)) // 将模板转为消息 UserMessage userMessage = prompt.toUserMessage(); // 使用模板 chatModel.chat(userMessage); -
高阶API:
@StructuredPrompt、@V、@UserMessage、@SystemMessage// 1、定义提示词模板 @StructuredPrompt("你是一个{{role}}助手,请回答{{qustion}}) public interface MyPrompt { String generate(@V("role") String a, @V("qustion") String b); } // 2、使用提示词模板 String prompt = apiPrompt.generate("Java", "OOM该如何处理");
更详细完整的用法请参考:
输出方式
在 LangChain4j 中,输出方式主要可以从两个维度来划分:一是数据流的模式(流式 vs 非流式),二是返回数据的结构(非结构化文本 vs 结构化对象)
PS:通常这两个维度是混合的,排列组合共 4 种输出方式(比如:流式结构化、非流式结构化)
流式与非流式输出
LangChain4j 中按照“模型响应结果是否一次性输出”(决定了用户是“等待完整结果”还是“实时看到生成过程”),可以分为两种输出方式,一种是流式输出,一种是非流式输出
- 流式输出(Stream):程序会阻塞等待,直到大模型生成完整的回复后才一次性返回
- 非流式输出( Blocking):程序实时输出,模型每生成一个词,就会立即返回
| 特性 | 流式输出 | 非流式输出 |
|---|---|---|
| 别名 | 打字机效果、SSE | 阻塞式调用、同步调用 |
| 返回类型 | 通常是 Flux<String> (Reactor) 或 StreamingResponseHandler 回调。 |
通常是 String 或 Response<T>。 |
| 用户体验 | 极佳。用户能立即看到内容逐字出现,感觉响应非常快,更有“对话感”。 | 较差。如果回答很长,用户会面对长时间的白屏或加载动画,不知道发生了什么。 |
| 适用场景 | 聊天机器人、智能助手、任何需要与人实时交互的场景 | 简单的后台任务、非交互式问答、需要一次性处理完整文本的分析任务 |
流式输出示例
在 LangChain4j 中存在两个流式输出的接口
StreamingChatModel和StreamingLanguageModel,它们分别对应的是ChatModel和LanguageModel两个接口,都是文字类回复类的接口,不提供图片流式响应接口,因为图片不可能以下生成一点点吧,没有意义。这里我也重点演示StreamingChatModel,因为当前 LanguageModel 已经相对过时了,所以StreamingLanguageModel也相对过时
| 方式 | 核心类/接口 | 特点与适用场景 |
|---|---|---|
| 回调处理器 | StreamingResponseHandler |
最基础、最直接。通过实现 onNext(token)、onComplete(response) 等回调方法来处理数据流。适合控制台打印或简单的自定义逻辑。 |
TokenStream |
Iterable 接口,你可以像遍历集合一样逐个获取 token。适合需要在后端对每个 token 进行复杂处理(如翻译、缓存、敏感词过滤)的场景。 |
|
| 响应式流 | Flux<String> |
响应式编程首选。与 Spring WebFlux 无缝集成,支持 map、filter 等链式操作。这是实现前后端 SSE (Server-Sent Events) 实时推送的最佳实践,特别适合高并发、非阻塞的 Web 应用。 |
方式一:StreamingChatResponseHandler
/**
* 测试 StreamingChatResponseHandler 流式输出
*/
@Test
public void testStreamOutput1() {
streamingChatModel.chat("从一数到五,只需要输出数字,不需要输出其他任何东西", new StreamingChatResponseHandler() {
/**
* 当生成下一个部分思考/推理文本时调用
* @param partialThinking
*/
@Override
public void onPartialThinking(PartialThinking partialThinking) {
System.out.println("部分思考: " + partialThinking);
}
/**
* 当生成下一个 部分工具调用 时调用
* @param partialToolCall
*/
@Override
public void onPartialToolCall(PartialToolCall partialToolCall) {
System.out.println("部分工具调用: " + partialToolCall);
}
/**
* 当生成下一个部分文本响应时调用(根据 LLM 提供商的不同,部分响应可能包含一个或多个 token)
* 如果输出的是中文会存在乱码,因为 LLM 响应的一个或多个 token 并不是一个完整的中文字符句子,存在 UTF-8 截断
* @param s
*/
@Override
public void onPartialResponse(String s) {
System.out.println("部分响应: " + s);
}
/**
* 当 LLM 完成一个工具调用的流式传输时调用
* @param completeToolCall
*/
@Override
public void onCompleteToolCall(CompleteToolCall completeToolCall) {
System.out.println("完整工具调用: " + completeToolCall);
}
/**
* 当 LLM 完成整个响应生成时调用
* @param chatResponse
*/
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
System.out.println("完整响应: " + chatResponse);
}
/**
* 当发生错误时调用
* @param throwable
*/
@Override
public void onError(Throwable throwable) {
System.out.println("发生错误: " + throwable);
}
});
}
方式二:TokenStream(已淘汰)
/**
* 测试 TokenStream 流式输出
* 这种方式在我当前使用的 LangChain4j 1.3.0 版本已经不支持了,所以这里没法测,了解即可
*/
@Test
public void testStreamOutput2(){
streamingChatModel.chat("从一数到五,只需要输出数字,不需要输出其他任何东西")
.onNext(token -> {
System.out.println(token);
})
.onComplete(response -> System.out.println("\n--- 结束 ---"))
.start();
}
方式三:Flux<String>(Web开发主推)
这里需要另外添加 Project Reactor 依赖,因为 Flux 来自于这个依赖,这里两种添加方式
方式一:保留
spring-boot-starter-web+ 手动添加 Reactor(推荐)<!-- Spring Boot Web 依赖,提供 Web 开发支持 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Project Reactor 依赖(用于 Flux) --> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-core</artifactId> </dependency>方式二:改用
spring-boot-starter-webflux<!-- Spring Boot WebFlux 依赖,提供响应式Web开发支持 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency>区别说明:
spring-boot-starter-web:基于 Servlet 的传统 Web 应用,适合阻塞式 I/Ospring-boot-starter-webflux:基于 WebFlux 的响应式 Web 应用,适合非阻塞式 I/O,已包含 reactor-core建议: 如果你的项目主要是传统的 REST API,只是偶尔用 Flux 做 SSE 流式输出,方式一更轻量。如果大量使用响应式编程,选方式二
/**
* 测试流式聊天
*
* @param userMessage
* @return
*/
@GetMapping(value = "/output/stream", produces = "text/event-stream")
public Flux<String> streamChat(@RequestParam String userMessage) {
return Flux.create(emitter -> {
streamingChatModel.chat(userMessage, new StreamingChatResponseHandler() {
/**
* 当生成下一个部分响应时调用(根据 LLM 提供商的不同,部分响应可能包含一个或多个 token)
* @param partialResponse
*/
@Override
public void onPartialResponse(String partialResponse) {
// 将部分响应推送给前端
System.out.println(partialResponse);
emitter.next(partialResponse);
}
/**
* 当生成完整响应时调用
* @param chatResponse
*/
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
// 将完整响应推送给前端,完成响应流
emitter.complete();
}
/**
* 当生成响应时发生错误时调用
* @param throwable
*/
@Override
public void onError(Throwable throwable) {
// 将错误信息推送给前端
emitter.error(throwable);
}
});
});
}
上述都是低阶 API 的流式输出演示,现在我们来演示高阶 API 的流式输出
-
Step1:需要额外引入一个依赖
<!-- LangChain4j Reactor 支持,用于 Flux 流式输出 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-reactor</artifactId> </dependency> -
Step2:编写接口
我们只需要申明返回值类型为
Flux<String>即可,剩下的 LangChain4j 会自动帮我们完成@AiService public interface ChatService { /** * 流式聊天 * @param message * @return */ Flux<String> streamChat(String message); } -
Step3:编写Controller
/** * 测试流式聊天 * * @param userMessage * @return */ @GetMapping(value = "/output/stream", produces = "text/event-stream") public Flux<String> streamChat(@RequestParam String userMessage) { // 高阶API实现流式输出 return chatService.streamChat(userMessage); }
非流式输出
低阶 API 和高阶 API 默认都是非流式输出,流式输出需要指定
/**
* 测试非流式输出
*/
@Test
public void testBlockingOutput(){
String response = chatModel.chat("介绍一下Java");
System.out.println(response);
}
结构化与非结构化输出
LangChain4j 中按照“数据格式是否遵循模式规则”(决定了你拿到的是需要二次解析的“文本”,还是可以直接使用的“Java 对象”)可以分为两种输出方式,一种是结构化输出,一种是非结构化输出
- 结构化输出:固定格式、有明确字段、可被程序直接解析的输出(一般给机器看)
- 非结构化输出:无固定格式、无明确字段、无法直接被程序直接解析的输出(一般给人看)
| 维度 | 结构化输出 | 非结构化输出 |
|---|---|---|
| 解析方式 | 自动/强类型,框架(如 LangChain4j)自动将结果映射为 Java 对象(POJO)。你直接调用 person.getName()。 |
手动/脆弱 ,你需要写正则表达式、String.split() 或 JSON 解析库。如果模型多说了几个字(如“好的,这是结果…”),解析就会报错。 |
| 模型内部机制 | 受控生成,通过 Function Calling(工具调用) 或 JSON Schema 强制模型只能输出符合特定结构的数据。 | 自由生成,模型根据概率预测下一个字,没有格式限制。 |
| 返回类型 | 对象/JSON,例如:Person(name="小明", age=25, job="程序员") |
纯文本 (String) ,例如:“小明今年25岁,是个程序员。” |
| 可靠性 | 高,如果模型输出不符合结构,框架通常会报错或自动重试,保证给你的数据是合规的。 | 低 ,易出现幻觉或格式错误(比如想让它输出 JSON,它却输出了 Markdown)。 |
| 适用场景 | 数据提取、分类标注、表单填充、数据库查询结果、报表导出 | 开放式生成、自由表达、解释说明、答疑、建议类输出 |
结构化输出
结构化输出通过约束模型的生成,使其返回预定义格式的数据(通常是 JSON,在 Java 中映射为 POJO 对象)。
-
特点:严谨、类型安全、可被程序直接解析。
-
实现原理:LangChain4j 底层利用模型的 Function Calling 能力或 JSON Mode,强制模型按照你定义的 Java 类(字段名、类型)来填充数据。
-
使用场景
-
信息抽取:从非结构化文本(如简历、合同、新闻)中提取关键字段(人名、日期、金额)。
-
API 对接/工具调用:模型需要返回参数来调用外部 API(如“查询天气”需要返回
{"city": "Beijing"})。 -
分类任务:将用户输入分类为预定义的枚举值(如
POSITIVE,NEGATIVE)。
-
结构化输出总共有三种实现方式:
| 方式 | 实现原理 | 可靠性 |
|---|---|---|
| 基于 AI Service (推荐) | 定义一个 Java 接口,方法返回你想要的 POJO 类型。LangChain4j 会自动处理底层的 Prompt 工程和结果转换。 | 高,开发体验最好 |
| 基于 JSON Schema | 在请求中通过 response_format 参数明确指定 JSON Schema。这需要大模型本身支持该 API 参数(如 OpenAI, Gemini)。 |
最高,强制模型遵守格式 |
| 基于提示词 (Prompting) | 在 System Prompt 中通过文字描述你希望的 JSON 格式。 | 较低,依赖模型的遵循指令能力 |
1)方式一:基于 AI Service(推荐)
这是 LangChain4j 最核心的优势。你不需要关心底层是用了 JSON Schema 还是 Prompt,你只需要定义 Java 接口
-
Step1:定义实体类
@Data @AllArgsConstructor @NoArgsConstructor public class People { private String name; private int age; private String sex; private String job; private String address; private String phone; private String email; private String idCard; private String remark; private String company; private String department; private String position; private String education; } -
Step2:定义接口
@AiService public interface ChatService { /** * 获取人物信息 * @return */ People getPeopleInfo(String userName); } -
Step3:编写Controller
/** * 测试 AI Service 实现的结构化输出 * * @param userName * @return */ @GetMapping(value = "/output/struct") public String getPeople(String userName) { return chatService.getPeopleInfo(userName).toString(); }

2)方式二:基于 JSON Schema
这是最“硬核”的方式,直接利用大模型提供商(如 OpenAI, Gemini, Azure)提供的原生 API 参数
response_format或tools。
/**
* 测试通过 JSON Schema 实现结构化输出
*/
@Test
public void testStructuredOutputByJsonSchema() {
// 定义技能对象的 JSON Schema
JsonObjectSchema skillSchema = JsonObjectSchema.builder()
.addStringProperty("name", "技能名称")
.addStringProperty("level", "技能等级,如:初级、中级、高级")
.build();
// 定义数组 Schema
JsonArraySchema skillsArraySchema = JsonArraySchema.builder()
.description("技能列表")
.items(skillSchema)
.build();
// 定义 JSON Schema,描述期望的输出结构
JsonObjectSchema schema = JsonObjectSchema.builder()
.addStringProperty("name", "人物姓名")
.addIntegerProperty("age", "人物年龄")
.addStringProperty("occupation", "人物职业")
.addProperty("skills", skillsArraySchema)
.required("name", "age", "occupation")
.build();
// 创建 JsonSchema 包装对象(jsonSchema 方法需要 JsonSchema 类型,而非 JsonObjectSchema)
JsonSchema jsonSchema =
dev.langchain4j.model.chat.request.json.JsonSchema.builder()
.name("PersonSchema")
.rootElement(schema)
.build();
// 构建 ChatRequest,设置响应格式为 JSON,并指定 schema
ChatRequest chatRequest = ChatRequest.builder()
.messages(UserMessage.from("请介绍一位著名的计算机科学家"))
.responseFormat(dev.langchain4j.model.chat.request.ResponseFormat.builder()
.type(ResponseFormatType.JSON)
.jsonSchema(jsonSchema)
.build())
.build();
// 发送请求并获取响应
ChatResponse chatResponse = chatModel.chat(chatRequest);
// 输出结构化结果
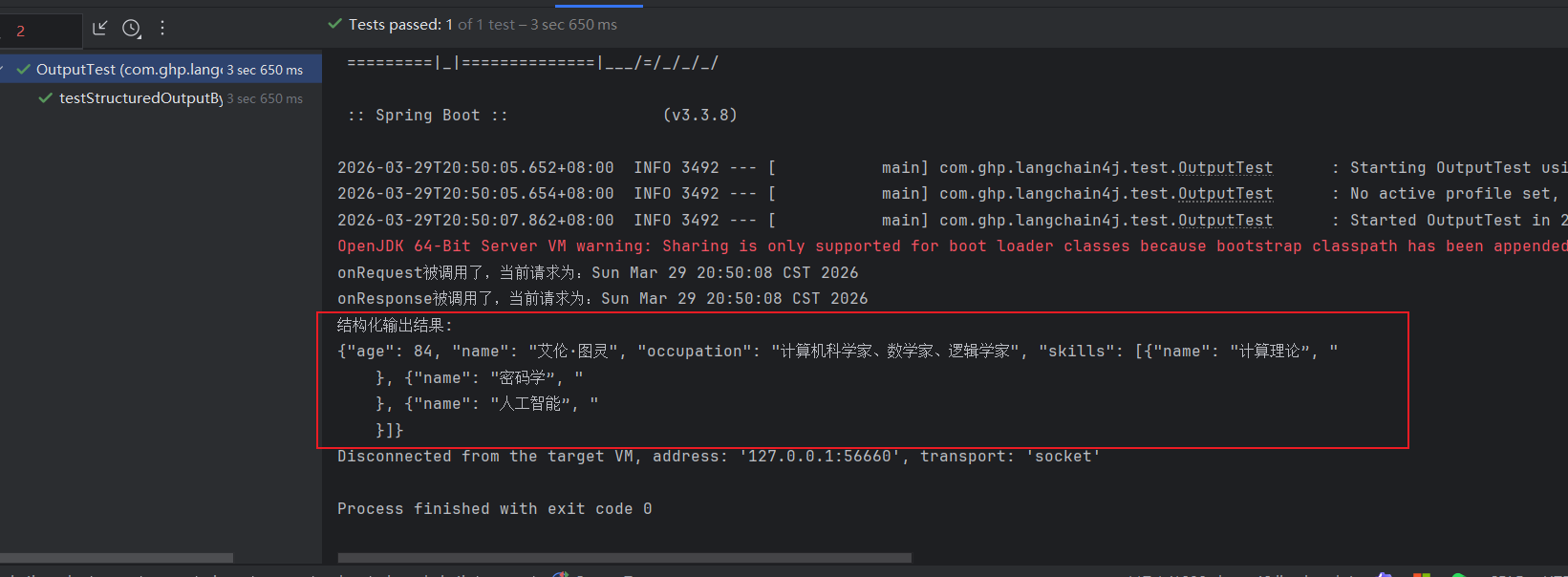
System.out.println("结构化输出结果:");
System.out.println(chatResponse.aiMessage().text());
}
3)方式三:基于提示词(不推荐)
这是最原始的方法,适用于不支持 JSON Schema 参数的老旧模型或开源小模型。
// 1. 构造包含格式指令的提示词
String systemPrompt = """
你是一个信息提取助手。
请从文本中提取信息,并**仅**返回合法的 JSON 格式。
不要输出任何解释性文字。
JSON 格式要求:{"name": "String", "age": "Integer"}
""";
// 2. 构建消息
List<ChatMessage> messages = Arrays.asList(
SystemMessage.from(systemPrompt),
UserMessage.from("John is 42...")
);
// 3. 发送请求
String response = model.generate(messages);
// 4. 清洗数据 (通常需要手动去除 Markdown 标记)
String cleanJson = response.replace("```json", "").replace("```", "").trim();
// 然后手动解析
非结构化输出
这是大语言模型最原始、最自然的形态。模型根据提示词生成一段连续的文本(String)。
- 特点:灵活、富有创造性,但格式不可控。
- 处理难度:如果需要程序自动处理结果(如存入数据库),你需要编写复杂的正则表达式或 JSON 解析代码,且容易因为模型多输出一句“好的,这是结果:”而导致解析失败。
- 使用场景
- 智能客服/聊天机器人:直接与人对话,需要自然流畅的语言。
- 文章/邮件写作:生成营销文案、翻译文本。
- 头脑风暴:生成创意点子列表。
代码示例:
// 1. 定义 AI Service 接口
interface Assistant {
String chat(String userMessage);
}
// 2. 构建服务
Assistant assistant = AiServices.create(Assistant.class, model);
// 3. 调用并获取纯文本
String response = assistant.chat("请给我讲一个关于猫的笑话");
// 输出示例:
// "好的,这是一个笑话:为什么猫坐在电脑上?因为它们想盯着鼠标!"
System.out.println(response);
模型记忆
在 LangChain4j 中,模型记忆(Memory)是构建多轮对话应用的核心。它让 AI 能够“记住”之前的交互,从而实现连贯、有上下文的对话体验,主要分为四个核心部分:核心概念、记忆组件、淘汰策略和持久化方案。
在深入技术细节前,必须理解 LangChain4j 对这两个概念的关键区分:记忆 (Memory) vs 历史 (History)
- 历史 (History):指用户与 AI 之间所有消息的完整、原始记录。它就像一份“对话录像”,用于 UI 展示、审计追溯或数据分析。LangChain4j 不直接提供历史的自动存储功能,需要开发者自行实现。
- 记忆 (Memory):指经过处理后,提供给大模型(LLM)用于理解上下文的信息。它更像是一份“对话解说稿”,为了适应模型的上下文窗口限制和提升效率,可能会对原始历史进行筛选、总结或压缩。LangChain4j 的核心功能正是围绕“记忆”展开的。
简单来说,记忆是对历史的优化和利用
ChatMemory 介绍
-
ChatMemory 是什么
ChatMemory是 LangChain4j 中管理对话上下文的核心容器,是实现模型记忆的核心组件 -
ChatMemory的实现原理
ChatMemory内部维护了一个消息列表,并负责在每次对话时将这些消息注入到 LLM 的请求中,在多用户或复杂会话场景下,你需要使用ChatMemoryProvider,它是一个函数式接口,根据传入的memoryId(通常是用户ID或会话ID)来为每个会话提供独立的ChatMemory实例,从而实现会话隔
具体示例参考下方 Github 代码仓库地址
- 低阶 API 使用 ChatMemory:
- 高阶 API 使用 ChatMemory(推荐):
淘汰策略
淘汰策略是必要的,原因如下:
- 为了适应 LLM 的上下文窗口。 LLM 一次可以处理的令牌(tokens)数量是有限制的。在某些时候,对话可能会超过这个限制。在这种情况下,需要淘汰一些消息。通常,最旧的消息会被淘汰,但如果需要,也可以实现更复杂的算法。
- 为了控制成本。 每个令牌都有成本,这使得每次调用 LLM 的成本逐渐增加。淘汰不必要的消息可以降低成本。
- 为了控制延迟。 发送给 LLM 的令牌越多,处理所需的时间就越长。
目前,LangChain4j 提供了两种开箱即用的实现:
| 策略类型 | 实现类 | 淘汰依据 | 适用场景 |
|---|---|---|---|
| 消息窗口 | MessageWindowChatMemory |
保留最近的 N 条消息 | 快速原型开发,对 Token 消耗不敏感。 |
| Token 窗口 | TokenWindowChatMemory |
保留最近的 N 个 Token | 生产环境推荐,能精确控制成本和上下文窗口,需配合 Tokenizer 使用。 |
由于系统消息和能工具消息的特殊性,淘汰策略需要特殊处理这两类消息
-
对系统消息的特殊处理:
-
一旦添加,
SystemMessage始终被保留。 -
每次只能保留一个
SystemMessage。 -
如果添加内容相同的新
SystemMessage,它将被忽略。 -
如果添加内容不同新的
SystemMessage,它会替换旧的。
-
- 对工具消息的特殊处理:如果包含
ToolExecutionRequest的AiMessage被淘汰,则其后续的孤立ToolExecutionResultMessage(s) 也会自动被淘汰,以避免某些 LLM 提供商(如 OpenAI)禁止在请求中发送孤立ToolExecutionResultMessage(s) 的问题
持久化方案
ChatMemory 默认是将消息保存到内存中的,使用一个map对象进行存储Map<Object, List<ChatMessage>>,具体实现类可以参考dev.langchain4j.store.memory.chat.InMemoryChatMemoryStore。在生产中是消息是一定不能放入内存中的,极易造成数据的丢失,所以我们需要将消息持久化,我们只需要编写一个类,然后实现 ChatMemoryStore 接口,即可实现消息的持久化保存,具体的持久化实现可以是 Redis
// 创建自定义的的消息持久化类
class PersistentChatMemoryStore implements ChatMemoryStore {
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// TODO: 实现通过 memory ID 从持久化存储中获取所有消息。
// 可使用 ChatMessageDeserializer.messageFromJson(String)
// 和 ChatMessageDeserializer.messagesFromJson(String) 辅助方法从 JSON 反序列化。
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// TODO: 实现通过 memory ID 更新持久化存储中的所有消息。
// 可使用 ChatMessageSerializer.messageToJson(ChatMessage)
// 和 ChatMessageSerializer.messagesToJson(List<ChatMessage>) 辅助方法将消息序列化为 JSON。
}
@Override
public void deleteMessages(Object memoryId) {
// TODO: 实现通过 memory ID 删除持久化存储中的所有消息。
}
}
// 将自定义的消息持久化类配置给模型使用
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.id("12345")
.maxMessages(10)
.chatMemoryStore(new PersistentChatMemoryStore())
.build();
模型参数
模型的好坏不光取决去模型本身,还取决于模型参数的设置,所以如何配置一个合适的参数显得尤为重要,本章节主要介绍模型常见的参数,不同模型厂商的参数配置可能存在些许的不同。模型的参数按照功能主要可以分为三类:输出控制(决定说什么)、工程控制(决定怎么传)、格式控制(决定怎么说)
参数介绍
1)输出控制类参数:接决定了模型生成内容的风格和质量
| 参数名称 | 通俗解释 |
|---|---|
temperature |
随机性。值越低越严谨(像做数学题),值越高越奔放(像写诗)。 |
maxTokens |
篇幅限制。防止模型“滔滔不绝”导致费用失控,或限制输出太短。 |
topP |
候选池大小。与 temperature 类似,但更平滑。通常建议二选一调节。 |
frequencyPenalty |
防复读机。值越高,模型越不愿意重复使用已经出现过的词。 |
max-retries |
最大重试次数,模型调用失败进行重试的最大次数 |
max-tokens |
最大 token 数,模型调用最大耗费 token 数,超过限制拒绝响应 |
timeout |
模型调用超时时间,超时中断请求 |
2)工程控制类参数:决定了你的 AI 应用是否健壮
timeout(超时时间):防止网络卡顿导致线程阻塞。一般设置为 30s - 60s。maxRetries(重试次数):大模型 API 偶尔会抽风(5xx 错误),设置 3 次左右的重试可以大幅提升用户体验。logRequests/logResponses:调试神器。开启后会在控制台打印发送给模型的原始数据和返回数据(注意脱敏)
3)格式控制类参数:
-
responseFormat:强制模型输出符合特定规范的文本配置值 含义 适用场景 "json_object"强制 JSON 模式。模型必须输出合法的 JSON 字符串,否则报错。 数据提取、API 对接、配置生成。 "json_schema"严格 JSON 模式 (OpenAI 新特性)。不仅要求是 JSON,还要求符合你定义的 Schema (字段类型、必填项)。 极高可靠性的结构化数据输出。 "text"默认值。模型可以自由输出自然语言。 聊天、写作。
参数设置
SpringBoot环境下模型参数的配置主要有两种,一种是 Builder 模式,一种是配置文件模式
TIPS:
- Temperature 和 TopP 的关系:通常建议只调节
temperature,将topP保持为 1.0。如果你同时调节这两个参数,模型的行为会变得难以预测。- MaxTokens 不是越小越好:如果设置得太小(例如 100),模型可能会在句子说到一半时突然截断,导致输出不完整。
- 日志开关:在生产环境(Production)中,务必将
logRequests和logResponses设置为false,否则你的控制台会被大量的 Token 文本刷爆,且可能泄露用户隐私。
1)方式一:Builder模式配置参数
OpenAiChatModel.builder()
// 基础连接信息
.apiKey("your-api-key")
.baseUrl("https://api.your-provider.com/v1")
.modelName("gpt-4o") // 或 qwen-max, ernie-bot 等
// --- 核心输出参数 ---
.temperature(0.7) // 适度创意
.maxTokens(2000) // 允许较长回复
.topP(1.0) // 通常设为 1.0,让 temperature 主导
.frequencyPenalty(0.0) // 不强制防重复,除非写长文
// --- 工程化参数 ---
.timeout(Duration.ofSeconds(60)) // 60秒超时
.maxRetries(3) // 失败重试3次
.logRequests(true) // 开启请求日志(开发环境)
.logResponses(true) // 开启响应日志
.build();
2)方式二:通过配置文件配置参数
langchain4j:
open-ai: # 或者是 dashscope, qianfan 等
chat-model:
api-key: ${MY_API_KEY}
model-name: gpt-4o
# 输出控制
temperature: 0.3 # 生产环境建议偏低,保证稳定性
max-tokens: 1024
top-p: 1.0
frequency-penalty: 0.0
# 工程控制
timeout: 60s
log-requests: false # 生产环境建议关闭,防止日志泄露隐私
log-responses: false
以下是提供的的关于模型参数常见的两个场景
场景一:严谨的客服/知识库问答
- 目标:准确、不胡说、格式统一。
- 配置策略:压低随机性,提高确定性。
OpenAiChatModel model = OpenAiChatModel.builder()
.temperature(0.2) // 低温度,几乎每次回答都一样
.maxTokens(500) // 限制长度,节省成本
.frequencyPenalty(0.5) // 适度防重复
.timeout(Duration.ofSeconds(10)) // 要求响应快
.build();
场景二:创意写作 / 营销文案
- 目标:有趣、多样化、用词丰富。
- 配置策略:提高随机性,放宽限制。
OpenAiChatModel model = OpenAiChatModel.builder()
.temperature(0.9) // 高温度,激发创意
.maxTokens(2000) // 允许长文本
.frequencyPenalty(0.2) // 允许适度重复(保持风格)
.topP(0.95) // 扩大选词范围
.build();
模型监听器
在 LangChain4j 里,监听器(Listener / Handler) 就是一套回调接口,用来接收模型在运行过程中产生的各种事件:比如开始生成、输出一个 token、出错、完成、调用工具等。每个不同的模型都有对应的监听器接口,比如:
ChatModel的ChatModelListener,AiService的AiServiceStartedListener、AiServiceCompletedListener
监听器的工作方式:
- 监听器是同步调用的,并且运行在同一个线程中
- 监听器被指定为
List<ChatModelListener>,会按照迭代顺序依次调用 ChatModelListener.onRequest()方法在调用 LLM 提供商 API 之前被调用ChatModelListener.onResponse()方法在 LLM 提供商成功接收请求之后被调用- 监听器回调方法一次调用只会被触发依次,即使出错重试调用模型也不会再次调用
监听器 Demo 示例:
1)方式一:手动添加监听器
-
Step1:创建监听器。创建一个类,实现监听器接口,并且重写监听器方法
public class MyChatModelListener implements ChatModelListener { /** * 请求前触发调用 * * @param requestContext */ @Override public void onRequest(ChatModelRequestContext requestContext) { Date requestId = new Date(); requestContext.attributes().put("requestId", requestId); System.out.println("onRequest被调用了,当前请求为:" + requestId); } /** * 响应后触发调用 * * @param responseContext */ @Override public void onResponse(ChatModelResponseContext responseContext) { Object requestId = responseContext.attributes().get("requestId"); System.out.println("onResponse被调用了,当前请求为:" + requestId); } /** * @param errorContext */ @Override public void onError(ChatModelErrorContext errorContext) { Object requestId = errorContext.attributes().get("requestId"); System.out.println("onError被调用了,当前请求为:" + requestId); } } -
Step2:添加监听器
ChatModel chatModel = OpenAiChatModel.builder() .apiKey(System.getenv("OPENAI_API_KEY")) .modelName("") .listeners(List.of(new MyChatModelListener())) .build();
2)方式二:自动添加 Bean(推荐)
直接通过 @Bean 注解将监听器加入容器,Spring 会自动将监听器进行注册
@Configuration
public class MyChatModelListener {
@Bean
public ChatModelListener buildChatModelListener() {
return new ChatModelListener() {
/**
* 请求前触发调用
*
* @param requestContext
*/
@Override
public void onRequest(ChatModelRequestContext requestContext) {
Date requestId = new Date();
requestContext.attributes().put("requestId", requestId);
System.out.println("onRequest被调用了,当前请求为:" + requestId);
}
/**
* 响应后触发调用
*
* @param responseContext
*/
@Override
public void onResponse(ChatModelResponseContext responseContext) {
Object requestId = responseContext.attributes().get("requestId");
System.out.println("onResponse被调用了,当前请求为:" + requestId);
}
/**
* @param errorContext
*/
@Override
public void onError(ChatModelErrorContext errorContext) {
Object requestId = errorContext.attributes().get("requestId");
System.out.println("onError被调用了,当前请求为:" + requestId);
}
};
}
}
工具函数
LLM 除了生成文本外,还可以触发操作,这个触发操作我们称之为工具(或函数调用),本篇文章将介绍 LangChain4j 框架是如何实现函数调用能力的。
-
工具函数是什么
在 LangChain4j 中,工具函数是大模型(LLM)用于访问和操作外部系统的能力载体,本质上就是给大模型装上 “手脚” 的业务代码,它是连接 LLM 与外部数据、接口、服务之间的桥梁。
简单来说:工具函数 = 模型能看懂的说明书(元数据) + 实际执行的 Java 方法(业务逻辑)
-
为什么需要工具函数
大模型(LLM)本身只是一个“大脑”,擅长思考和生成文本,但它无法联网、无法计算复杂数学、也无法操作你的数据库。工具函数就是为了解决这个问题而存在的——它是一段具体的 Java 代码,模型在需要时可以“触发”它来执行实际操作。
总结起来就是一下一点:
- 触发外部操作,LLM 只有大脑,没有手脚,需要工具函数来操作外部系统
- 解决大模型数据滞后性问题,可以将大模型链接到外部获取相关数据。比如搜索、数据库查询等
- 解决大模型无真逻辑问题,比如复杂的数据计算问题。
工具函数的定义
对于我们人类而言,想要使用一个工具,我们需要了解工具的用途、工具的使用方法,对于 LLM 也是一样的道理。对于 LLM 而言,一个合格的工具需要满足以下三要素:
- 工具名称
- 工具说明书:描述该工具的作用以及何时应使用该工具
- 工具参数:工具需要有哪些参数,以及每个参数的说明
在 LLM 中,工具函数有三种定义方式
1)方式一:手动构建ToolSpecification。必须搭配ToolExecutor使用,ToolSpecification 是工具,ToolExecutor 是工具执行器,封装了真正干活的逻辑
- 特点:最底层、最灵活
- 适用场景:适合动态生成工具、无注解场景
// 1. 定义工具描述(告诉AI这个工具是干嘛的)
ToolSpecification addToolSpec = ToolSpecification.builder()
.name("add")
.description("计算两个数字的和")
.addParameter("a", type("integer"), "第一个数字")
.addParameter("b", type("integer"), "第二个数字")
.build();
// 2. 定义执行器(真正干活的逻辑)
ToolExecutor executor = (toolName, arguments) -> {
if ("add".equals(toolName)) {
int a = (Integer) arguments.get("a");
int b = (Integer) arguments.get("b");
return a + b;
}
return "未知工具";
};
// 3. AI 会根据 ToolSpecification 决定是否调用,由 executor 执行
2)方式二:ToolSpecifications 工具扫描。必须配合 @Tools 注解标记工具类
- 特点:能快速大量生成工具
- 适用场景:适合批量注册多个工具
// 1、定义工具
@Tools // 标记这是一个工具类
public class MathTools {
@Tool
public int add(int a, int b) {
return a + b;
}
@Tool
public int multiply(int a, int b) {
return a * b;
}
}
// 2、
// 从类扫描(推荐)
List<ToolSpecification> specs = ToolSpecifications.toolSpecificationsFrom(MathTools.class);
// 从对象扫描
// List<ToolSpecification> specs = ToolSpecifications.toolSpecificationsFrom(new MathTools());
3)方式三:@Tool + @P + @ToolMemoryId
- 特点:最简洁
- 适用场景:适用大部分场景,是开发最常用的工具函数定义方式
- 注解参数说明:
@Tool:定义工具/函数name:名称,要具体value:描述,要清晰
@P:对工具/方法的参数进行说明value:参数说明。必填项。required:参数是否为必填项,默认为true。可选字段。
@ToolMemoryId:如果 AI Service 方法中有使用@MemoryId注解的参数,那么你也可以在@Tool方法的参数上使用@ToolMemoryId。这样,AI Service 方法提供的值会自动传递给@Tool方法。这在多用户/多会话记忆的场景中非常有用,可以区分不同用户或对话
public class WeatherTool {
/**
* @Tool 标记工具
* name:工具名
* description:工具描述(给AI看)
* @P 对参数进行说明(必填)
* @ToolMemoryId 绑定记忆ID
*/
@Tool(
name = "getWeather",
description = "获取指定城市的实时天气"
)
public String getWeather(
// 参数说明
@P(value = "要查询的城市名称,例如:北京", required = true) String city,
// 记忆ID(多会话隔离)
@ToolMemoryId String memoryId
) {
return city + ":晴天,25℃";
}
}
工具函数的执行
工具函数是给 LLM 用的,不是给人用的,所以通常而言工具函数无需我们手动去调用,只需要申明给 LLM,LLM 在处理问题时,发现这个问题可能需要用到某一个工具函数,就会主动去调用。
这就好比一个人去上班,老板给他提供一个工具箱,他在干活,干活过程中遇到一个问题,比如需要拧掉十字螺丝,这时候他就会去找十字螺丝刀,而不是要老板强迫(命令)他用某一个工具
-
方式 一可手动可自动
下面我们演示一下如何手动执行
// 定义参数 Map<String, Object> params = new HashMap<>(); params.put("a", 10); params.put("b", 20); // 手动调用工具函数,需要指定工具名和参数 Object result = executor.execute("add", params); // 查看工具函数执行结果 System.out.println("手动执行结果:" + result); -
方式二、三:AI 自动执行

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)