从环境搭建到参数调优:大语言模型开发必知的 5 个核心技巧
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码获取 + 调试运行 + 问题答疑)🔥🔥🔥 有兴趣可以联系我
🔥🔥🔥 文末有往期免费源码,直接领取获取(无删减,无套路)
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
同样一句话,为什么每次生成的结果都不同?温度参数调高调低分别适合什么场景?
前言
上一篇文章我们认识了什么是大语言模型,了解了它的核心能力和发展趋势。但纸上得来终觉浅,真正的学习一定是从动手开始的。当你第一次成功加载一个模型,看到它根据你的输入生成出一段连贯的文字时,那种“我和AI连接上了”的成就感,是任何理论都无法替代的。
然而,很多初学者在入门阶段会遇到这样的困惑:
-
代码环境怎么配?依赖包装不上怎么办?
-
模型文件太大,下载总是失败?
-
同样的输入,为什么每次生成的结果都不一样?
-
temperature、top_k、top_p 这些参数到底是什么?怎么调才能得到我想要的效果?
本文将手把手带你完成大语言模型的本地调用,深入讲解生成参数背后的原理,并教你如何评估模型输出的质量。读完这篇文章,你不仅能跑通第一个模型,还能理解如何控制模型的“创造力”与“稳定性”,为后续的微调和应用打下坚实基础。
目标
通过本文的实践,你将能够:
-
独立搭建 Python 大模型开发环境
-
使用 Hugging Face 加载预训练模型与分词器
-
深入理解 temperature、top_k、top_p 等生成参数的作用
-
根据业务场景合理调整参数,控制生成效果
-
掌握简单的模型输出质量评估方法
第一部分:环境搭建——从零开始准备开发环境
1.1 Python 环境准备
大语言模型开发通常使用 Python 3.8 及以上版本。推荐使用 Anaconda 管理环境,避免包冲突。
# 创建新环境(命名为 llm)
conda create -n llm python=3.10
# 激活环境
conda activate llm1.2 安装核心依赖
我们需要安装的主要库有:
-
torch:PyTorch 深度学习框架 -
transformers:Hugging Face 提供的模型库,封装了数千个预训练模型 -
accelerate:加速训练和推理(可选,但推荐)
# 安装 PyTorch(CPU 版本,适合入门;如果有 GPU 可安装对应版本)
pip install torch --index-url https://download.pytorch.org/whl/cpu
# 安装 transformers 和 accelerate
pip install transformers accelerate小贴士:如果下载速度慢,可配置国内镜像源,如:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple transformers
第二部分:加载预训练模型——与模型“握手”
我们以 Qwen2.5-0.5B 为例(参数量小,适合本地 CPU 运行),展示如何加载模型和分词器。
from transformers import AutoTokenizer, AutoModelForCausalLM
# 模型名称(可在 Hugging Face 官网搜索)
model_name = "Qwen/Qwen2.5-0.5B"
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(model_name)核心概念:
-
分词器(Tokenizer):将文本转换成模型可理解的 token 序列,同时负责将生成的 token 序列解码回文本。
-
模型(Model):实际执行计算的神经网络,加载后即可用于推理。
第一次运行时会自动下载模型文件(约 1GB),请保持网络通畅。如果下载失败,可尝试设置 Hugging Face 镜像:
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'第三部分:文本生成——让模型开口说话
3.1 基础生成流程
# 构造用户输入
prompt = "请介绍一下人工智能的发展历程。"
# 对话模板处理(不同模型可能有不同格式)
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 编码为模型输入
inputs = tokenizer(text, return_tensors="pt")
# 生成回答
outputs = model.generate(**inputs, max_new_tokens=200)
# 解码输出
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
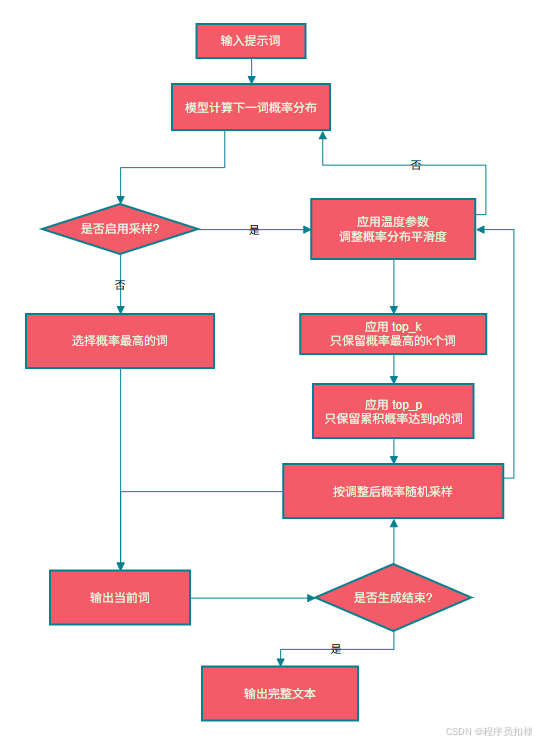
print(answer)3.2 生成参数详解
生成参数是控制模型输出的关键。它们在 model.generate() 中通过 do_sample、temperature、top_k、top_p 等参数设置。
(1)temperature(温度)
作用:控制输出分布的平滑程度。值越小,模型越倾向于选择高概率的词(更确定性);值越大,低概率词被选中的机会增加(更多样性)。
-
温度 = 0:贪婪解码,每次都选概率最高的词 → 输出固定,缺乏创造性
-
温度 = 0.7:平衡,适合大多数对话场景
-
温度 > 1.0:增加随机性,可能产生意想不到的内容
代码示例:
outputs = model.generate(
**inputs,
max_new_tokens=200,
do_sample=True, # 启用采样(必须为True才能使用温度)
temperature=0.7
)(2)top_k
作用:只从概率最高的 k 个词中采样,忽略其他词。这能防止模型选择非常罕见的词,同时保持一定的多样性。
例如 top_k=50,表示只考虑概率排名前 50 的候选词。
(3)top_p(核采样)
作用:从累积概率超过 p 的最小词集合中采样。这是一种更动态的筛选方式。例如 top_p=0.9,表示只从概率之和达到 90% 的候选词中采样。
重要:top_k 和 top_p 可以同时使用,也可以只用其中一个。通常推荐使用 top_p 配合 temperature。
(4)其他常用参数
| 参数 | 作用 |
|---|---|
max_new_tokens |
生成的最大 token 数 |
repetition_penalty |
惩罚重复词,避免陷入循环(值 > 1 可降低重复) |
do_sample |
是否启用采样;False 时为贪婪解码(相当于 temperature=0) |
第四部分:参数调优实验——控制模型的“创造力”
让我们通过实验,直观感受不同参数对输出的影响。
实验设置
-
模型:Qwen2.5-0.5B
-
提示词:
“请讲一个关于梦想的短故事。” -
生成长度:150 token
实验结果对比
| 参数组合 | 输出特点 |
|---|---|
temperature=0(贪婪) |
输出固定、保守,多次运行结果完全一样,内容平淡 |
temperature=0.7, top_p=0.9 |
内容丰富,有细节变化,但基本围绕主题 |
temperature=1.2, top_p=0.95 |
情节多变,可能出现意想不到的转折,但有时逻辑跳跃 |
temperature=0.7, repetition_penalty=1.2 |
有效减少了重复词,流畅度提升 |
思考:为什么同样提示词,每次结果不同?
当 do_sample=True 时,模型在每一步都会根据概率分布随机采样下一个 token。即使输入完全相同,采样的随机性也会导致不同的路径。这就像同一个作家用相同素材即兴创作,每次都会有不同的发挥。
需要固定输出的场景(如生成答案、代码),可将 temperature 设为 0 或关闭采样(do_sample=False)。
第五部分:简单评估——如何判断模型输出质量
评估生成文本的质量是一个复杂课题,但我们可以从以下几个维度快速判断:
5.1 相关性
输出内容是否围绕用户输入展开?有没有跑题?
5.2 连贯性
句子之间、段落之间是否逻辑通顺?有无明显的跳跃或矛盾?
5.3 丰富度
用词是否多样?有无过多重复?
5.4 有害性
是否包含偏见、歧视、虚假或危险信息?
实用技巧
-
多次运行:对同一输入运行多次,观察输出的稳定性与多样性。
-
对比测试:固定提示词,改变参数,看效果差异。
-
人工打分:请他人对生成结果进行主观评分(1-5 分),综合评估。
思考与进阶
温度参数调高调低分别适合什么场景?
-
低温(≤ 0.5):适合需要确定性的场景,如:
-
代码生成
-
数学计算
-
事实问答(需准确)
-
格式化输出(如 JSON、表格)
-
-
中温(0.6 ~ 0.9):适合大多数对话和内容生成,平衡创造性与连贯性。
-
高温(≥ 1.0):适合需要创意和多样性的场景,如:
-
故事创作
-
头脑风暴
-
营销文案(需要新鲜感)
-
游戏角色对话(随机性带来趣味)
-
进阶调参
实际应用中,常将 temperature 与 top_p、repetition_penalty 组合使用。例如:
-
创意写作:
temperature=1.2, top_p=0.95, repetition_penalty=1.1 -
客服问答:
temperature=0.3, top_p=0.8, repetition_penalty=1.0
结语
通过本文的实践,你已经掌握了从环境搭建到模型调用的完整流程,并深入理解了生成参数如何控制模型的输出。大语言模型的魅力不仅在于它的强大能力,更在于我们可以通过参数调优,让它适配不同的应用场景。
接下来你可以尝试:
-
更换不同的模型(如 Qwen2.5-1.5B、Llama 3.2 等)感受差异
-
调整参数组合,为你的业务场景寻找最佳配置
-
尝试用模型完成一个具体任务(如总结文档、生成 SQL)
如果你在实践过程中遇到任何问题,欢迎在评论区留言。我们下篇文章将深入注意力机制与 Transformer 架构,从原理层面继续探索大语言模型的奥秘。
完整代码示例
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型
model_name = "Qwen/Qwen2.5-0.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 构造提示
prompt = "请讲一个关于梦想的短故事。"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 编码
inputs = tokenizer(text, return_tensors="pt")
# 生成(带参数)
outputs = model.generate(
**inputs,
max_new_tokens=200,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1
)
# 解码输出
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)