MiniMind学习笔记(一)
MiniMind学习笔记(一)
前言
MiniMind学习记录
MiniMind项目仓库:https://github.com/jingyaogong/minimind/tree/master
学习参考b站up主:木乔_Mokio
【【2025/Minimind】Only三小时!Pytorch从零手敲大模型,架构到训练全教程】 https://www.bilibili.com/video/BV1T2k6BaEeC/?p=20&share_source=copy_web&vd_source=02d019664ac8c19be7713615e12a7bdc
视频对应参考代码,即本文对应学习代码:https://github.com/Wood-Q/MokioMind
一、模型架构
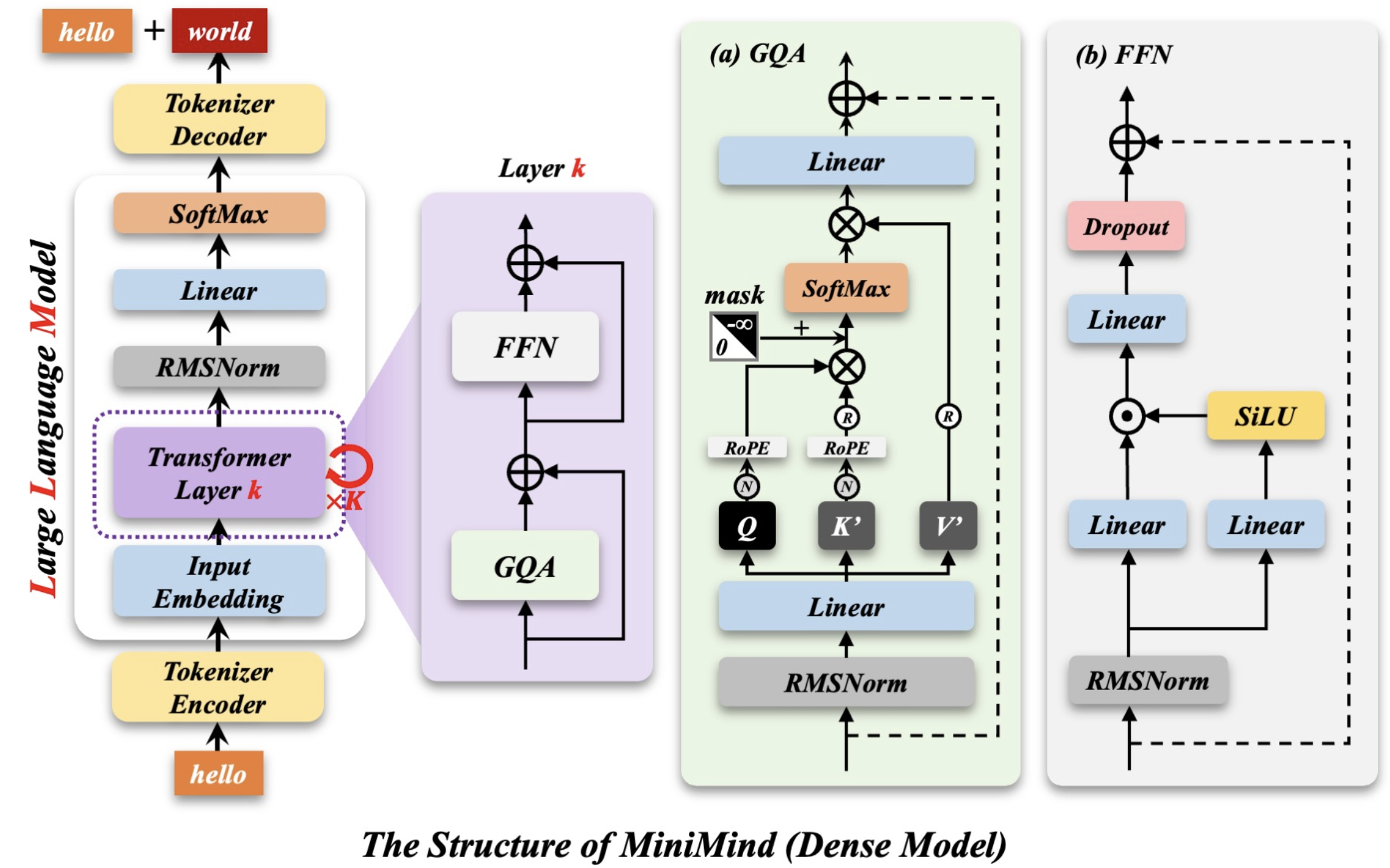
整体视角
- 输入文本
“hello”,在大模型中会经过分词器Tokenizer转为Token_ID - 输入的一串Token_ID经过
Embedding层转为高维向量 - 下一步进入
Transformer_Layer,num_hidden_layers的数量即表示k Transformer_Layer内部先经过GQA(Grouped-Query Attention),其内部先通过RMSNorm归一化,防止梯度消失或爆炸的问题发生- 在
Linear层进行QKV矩阵计算,获得对应向量,让多个Q共享一组K,V。工程验证中4个Q共享一组KV效果最好 - 对Q和K进行
RoPE位置编码,再进行点积,上三角掩码处理后输入进softmax,得到相关性矩阵,再与V点积,得到注意力分数 - 最后送入
Linear层进行拼接,投影回原维度;同时与最初的输入相加完成残差 GQA输出之后也与最初的向量相加完成残差,送入FFNFFN内部也先进行归一化,然后进行两路升维,右侧支路经过SwiGLU门控升维后经SiLU激活,与左侧升维后的结果进行相乘。再经过新的Linear进行降维,最后通过Dropout防止过拟合,该部分也有残差处理FFN之后也应用残差Transformer_Layer之后进入RMSNorm归一化再进入Linear层,将之前计算出的隐藏态映射到词表大小维度,得到每个位置上每个词的得分- 最后
softmax变为概率,进入分词器输出为具体的词“world”
二、核心模块
此部分解释模型架构中的核心模块并附相关代码理解
1.RMSNorm
归一化指让数据平均值为0,标准差为1,公式如下:
RMSNorm ( x ) = x 1 d ∑ i = 1 d x i 2 + ϵ ⋅ w \text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d} x_i^2 + \epsilon}} \cdot w RMSNorm(x)=d1∑i=1dxi2+ϵx⋅w
传统的Transformer的LayerNorm计算时需求均值和方差,而大模型为了追求极致速度,使用RMSNorm(均方根归一化),它假设输入的均值为 0,直接省去了求均值 x ‾ \overline{x} x和 x − x ‾ x-\overline{x} x−x的步骤,计算量更小但效果几乎一样。
代码如下(示例):
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
#初始化
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
#函数定义,核心计算
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
#前向传播,乘上权重,返回tensor[bs,seq_len,dim]
def forward(self, x):
return self.weight * self._norm(x.float()).type_as(x)
2.RoPE
文字的顺序极其重要(“我爱你”和“你爱我”意思完全相反)。RoPE 不像传统模型那样把位置信息直接加到词向量里,而是通过复数旋转的方式,在计算 Attention 时动态注入相对位置信息(上下文信息)。
数学方法很巧妙(积化和差公式)
c o s ( ( m − n ) θ ) cos((m-n)\theta) cos((m−n)θ) s i n ( ( m − n ) θ ) sin((m-n)\theta) sin((m−n)θ)
但RoPE也存在局限性,即在长度外推时会出现错误。
因此MiniMind引入YaRN技术,如果模型原本只训练了 2048 长度,通过 YaRN 算法调整旋转的频率(频率缩放),可以让模型在不重新训练的情况下,直接处理 32768 长度的文本。
RoPE原始频率计算公式 f r e q s i = 1 r o p e _ b a s e ( 2 i / d i m ) freqs_i = \frac{1}{rope\_base^{(2i/dim)}} freqsi=rope_base(2i/dim)1
对高低频使用不同的处理方法,对于高频,不处理保持原样;对于中频,使用线性插值,平滑过渡;对于低频,使用线性缩放
通过计算波长 λ i = 2 π / f r e q s = 2 π ∗ b a s e 2 i / d \lambda_i=2\pi/freqs=2\pi*base^{2i/d} λi=2π/freqs=2π∗base2i/d
i i i指哪一个维度
得到维度大小 d d d后,用训练长度 L L L和 λ \lambda λ与的比例 b b b来区分边界, b = l λ i b=\frac{l}{\lambda_i} b=λil
因此 b a s e 2 i / d = L b ∗ 2 π base^{2i/d}=\frac{L}{b*2\pi} base2i/d=b∗2πL
最后求 i = d ∗ l n ( L b ∗ 2 π ) 2 l n ( b a s e ) i = \frac{d*ln(\frac{L}{b*2\pi})}{2ln(base)} i=2ln(base)d∗ln(b∗2πL)
找到对应维度后再找对应高中低频,分别处理
代码如下(示例):
def precompute_freqs_cis(dim:int,end:int=int(32*1024),rope_base:float=1e6,rope_scaling:Optional[dict]=None):
#初始化RoPE频率,即公式
freqs,attn_factor = (1.0/(rope_base**(torch.arange(0,dim,2)[:dim//2].float()/dim)),1.0)
if rope_scaling is not None:
orig_max,factor,beta_fast,beta_slow=(
rope_scaling["original_max_position_embeddings"],
rope_scaling["factor"],
rope_scaling["beta_fast"],#高频边界
rope_scaling["beta_slow"],#低频边界
)
#推断的长度大于训练长度,需要外推技术,使用缩放
if end>orig_max:
#波长b到i的映射
inv_dim = lambda b:(dim*math.log(orig_max/(b*2*math.pi))/(2*math.log(rope_base)))
#划分高低维度
#low:开始缩放的起点
#high:需要完全缩放的起点
#i(维度)越小,频率越高
low,high = (max(math.floor(inv_dim(beta_fast)),0),
min(math.ceil(inv_dim(beta_slow)),dim // 2-1))
#计算缩放因子ramp(一个从0-1的平滑权重)
#low之前,ramp为0,high之后,ramp为1,在low和high之间,先行过度
ramp = torch.clamp(
(torch.arange(dim//2,device=freqs.device).float()-low)
/max(high-low,0.001),
0,
1
)
#freqs的缩放,低频部分不变,高频部分根据ramp线性过度到factor倍
#ramp为0时(高频),freqs不变;ramp为1时(低频),freqs缩放为原来的1/factor;在0和1之间,freqs线性过度到1/factor
freqs = freqs*(1-ramp+ramp/factor)
#根据end,生成位置索引t
t = torch.arange(end,device=freqs.device).float()
#计算外积,将t和频率部分相乘,得到每个位置的旋转角度
freqs = torch.outer(t,freqs).float()
#计算cos和sin,并用注意力补偿系数
freq_cos = (
torch.cat([torch.cos(freqs),torch.cos(freqs)],dim=-1)*attn_factor
)
freq_sin = (
torch.cat([torch.sin(freqs),torch.sin(freqs)],dim=-1)*attn_factor
)
return freq_cos,fre q_sin
def apply_rotary_pos_emb(q,k,cos,sin,position_ids=None,unsqueeze_dim=1):
#旋转[a,b]->[-b,a]
def rotate_half(x):
#x.shape[-1]取最后一个维度的重点
# x[...,x.shape[-1]//2:]取后半部分
#对向量作半旋转
return torch.cat(
(-x[...,x.shape[-1]//2:],x[...,:x.shape[-1]//2]),dim=-1
)
#实现x_rotated=x*cos+x_rotated*sin
#cos,sin维度扩展一维,[seq_len,1,head_dim]还会结合braodcast再扩展
#因为qkv维度为(bs,seq_len,num_attention_heads,head_dim]
q_embed = (q*cos.unsqueeze(unsqueeze_dim))+(rotate_half(q)*sin.unsqueeze(unsqueeze_dim))
k_embed = (k*cos.unsqueeze(unsqueeze_dim))+(rotate_half(k)*sin.unsqueeze(unsqueeze_dim))
return q_embed,k_embed
3.GQA
标准的注意力机制中,Q(查询)、K(键)、V(值)的头数是一样的。但为了节省显存,现在的模型会让多个 Q 共享一组 K 和 V。代码中的 repeat_kv 就是在做这件事。
n rep = n heads n kv_heads n_{\text{rep}} = \frac{n_{\text{heads}}}{n_{\text{kv\_heads}}} nrep=nkv_headsnheads
n_heads为Q的头数,nov_heads为KV共享头数
def repeat_kv(x:torch.Tensor,n_rep:int)->torch.Tensor:
bs,slen,num_key_value_heads,head_dim=x.shape
if n_rep==1:
return x
return(
#增加一个维度
x[:,:,:,None,:]
.expand(bs,slen,num_key_value_heads,n_rep,head_dim)
#再reshape回原来的维度
.reshape(bs,slen,num_key_value_heads*n_rep,head_dim)
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
class Attention(nn.Module):
def __init__(self,args:MokioMindConfig):
super().__init__()
#是None用num_attention_heads,否则用num_key_value_heads
self.num_key_value_heads = args.num_key_value_heads if args.num_key_value_heads is not None else args.num_attention_heads
#确保query头数能被kv头数整除,GQA基本要求
assert args.num_attention_heads % self.num_key_value_heads == 0,"num_attention_heads must be divisible by num_key_value_heads"
self.n_local_heads = args.num_attention_heads#query头数
#每个local head对应的key value head数量
self.n_rep = self.n_local_heads//self.num_key_value_heads
#每个head的维度=隐藏层除注意力头数
#隐藏层512,注意力头数8,每个head维度=512/8=64
self.head_dim = args.hidden_size//args.num_attention_heads
#线性变换,输入维度为隐藏层大小,输出维度为注意力头数乘每个head的维度,即每个head的维度乘以local head数量
self.q_proj = nn.Linear(args.hidden_size,args.num_attention_heads*self.head_dim,bias=False)
self.k_proj = nn.Linear(args.hidden_size,self.num_key_value_heads*self.head_dim,bias=False)
self.v_proj = nn.Linear(args.hidden_size,self.num_key_value_heads*self.head_dim,bias=False)
#输出与qkv反过来,输入维度为local head数量乘每个head的维度,输出维度为隐藏层大小
#最后输出[bs,seq_len,hidden_size]
self.out_proj = nn.Linear(args.num_attention_heads*self.head_dim,args.hidden_size,bias=False)
self.attn.dropout = nn.Dropout(args.dropout)
self.resid_dropout = nn.Dropout(args.dropout)
self.dropout = args.dropout
#磁盘上计算更快
self.flash = hasattr(torch.nn.functional,"scaled_dot_product_attention") and args.flash_attention
def forward(self,
x:torch.Tensor,
position_embedding:Tuple[torch.Tensor,torch.Tensor],
past_key_value:Optional[Tuple[torch.Tensor,torch.Tensor]]=None,
use_cache=False,
attention_mask:Optional[torch.Tensor]=None,
)->torch.Tensor:
#投影,计算qkv
bsz,seq_len,_ = x.shape
xq,xk,xv = self.q_proj(x),self.k_proj(x),self.v_proj(x)
#把输入拆分成多个头,用view
#本来只有三维,dim=num_attention_heads*head_dim
#[bs,seq_len,num_attention_heads,head_dim]
xq = xq.view(bsz,seq_len,self.n_local_heads,self.head_dim)
xk = xk.view(bsz,seq_len,self.num_key_value_heads,self.head_dim)
xv = xv.view(bsz,seq_len,self.num_key_value_heads,self.head_dim)
#q和k,使用rope
cos,sin = position_embedding
xq,xk = apply_rotary_pos_emb(xq,xk,cos[:seq_len],sin[:seq_len])
#对于k和v,使用repeat(注意kv cache)
if past_key_value is not None:
#如果有缓存,说明是推理阶段,需要把当前的k和v与缓存的k和v拼接起来
xk = torch.cat([past_key_value[0],xk],dim=1)
xv = torch.cat([past_key_value[1],xv],dim=1)
past_kv = (xk,xv) if use_cache else None
xq,xk,xv = (
#转置,准备计算attentionscore
xq.transpose(1,2),
#[bsz,n_local_heads,seq_len,head_dim]
#重复kv头数以匹配q
repeat_kv(xk,self.n_rep).transpose(1,2),
repeat_kv(xv,self.n_rep).transpose(1,2),
)
#进行attention计算,q*k^T/sqrt(d)
if self.flash and seq_len>1 and(attention_mask is None or torch.all(attention_mask==1)):
attn_mask = (
None
if attention_mask is None
else attention_mask[:,None,None,:].expand(-1,self.n_local_heads,-1,-1).expand(bsz,self.n_local_heads,
seq_len,-1).bool()
)
output = F.scaled_dot_product_attention(xq,xk,xv,attn_mask=attn_mask,
dropout_p=self.dropout if self.training else 0.0,is_causal=True)
else:
scores = (xq @ xk.transpose(-2,-1)/math.sqrt(self.head_dim))
scores = scores+torch.triu(
#相当于上三角掩码,设为负无穷
torch.full((seq_len,seq_len),float('-inf'),device = scores.device),
diagonal=1
).unsqueeze(0).unsqueeze(0)
#若attention_mask不为空,扩展后转为-1e9的mask
if attention_mask is not None:
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = (1.0 - extended_attention_mask)* -1e9
#softmax得注意力权重
scores = F.softmax(scores.float(),dim=-1).type_as(xq)
scores = self.attn_dropout(scores)
#输出
output = scores@xv
#输出投影,reshape回原形状
output = output.transpose(1,2).reshape(bsz,seq_len,-1)
#残差
output = self.resid_dropout(self.out_proj(output))
return output,past_kv
4.FFN
作用
- Attention 主要负责“寻址”和“逻辑路由”,而 FFN 则真正储存了模型预训练阶段背下来的海量事实知识
- FFN 在两层网络之间引入了激活函数(Activation Function)。正是这种非线性扭曲,赋予了大模型极强的拟合能力,让它能够理解人类语言中极其复杂的逻辑嵌套和因果关系。
- FeedForward 类参数:隐藏层维度是 512 512 512,但 FFN 内部的中间维度(intermediate_size)被放大到了 1344 1344 1344。数据进入 FFN 时,就像把光束照进了一个放大镜,特征被瞬间投射到极高的维度上。在高维空间里,模型能更清晰地把有用的信息(信号)和无用的信息(噪声)剥离开来,然后再通过降维层把提纯后的黄金特征压缩回 512 512 512 维送给下一层。
class FeedForward(nn.Module):
#初始化
def __init__(self,args:MokioMindConfig):
super().__init__()
if args.intermediate_size is None:
intermediate_size = int(args.hidden_size*8/3)
args.intermediate_size = 64*((intermediate_size+64-1)//64)
#升维
self.up_proj = nn.Linear(args.hidden_size,args.intermediate_size,bias=False)
#降维
self.down_proj = nn.Linear(args.intermediate_size,args.hidden_size,bias=False)
#门控
self.gate_proj = nn.Linear(args.hidden_size,args.intermediate_size,bias=False)
#dropout
self.dropout = nn.Dropout(args.dropout)
#激活函数
self.act_fn = ACT2FN[args.hidden_act]
def forward(self,x):
#两路并行升维,gate分支作激活,两路相乘,最后dropout,降维
gated = self.act_fn(self.gate_proj(x))*self.up_proj(x)
return self.down_proj(self.dropout(gated))
5.Block
将GQA和FFN封装成一个Block,即Transformer_Layer
class MokioMindBlock(nn.Module):
def __init__(self,Layer_id:int,config:MokioMindConfig):
super().__init__()
self.num_attention_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.head_dim = self.hidden_size//self.num_attention_heads
self.self_attn = Attention(config)
self.layer_id = Layer_id
self.input_layernorm = RMSNorm(config.hidden_size,esp=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(config.hidden_size,esp=config.rms_norm_eps)
self.mlp = FeedForward(config)
def forward(self,hidden_states,poisition_embedding,past_key_value=None,
use_cache=False,attention_mask=None):
residual = hidden_states
#经过层归一化和注意力计算,得到新的hidden_states和缓存的key value
hidden_states,present_key_value = self.attn(
self.input_layernorm(hidden_states),
poisition_embedding,
past_key_value,
use_cache,
attention_mask
)
#残差处理
hidden_states = residual+hidden_states
hidden_states = hidden_states+self.mlp(self.post_attention_layernorm(hidden_states))
return hidden_states,present_key_value
三、组装
1.Model
#最终组装
class MokioMindModel(nn.Module):
def __init__(self,config:MokioMindConfig):
super().__init__()
self.config=config
self.vocab_size,self.num_hidden_layers=(
config.vocab_size,
config.num_hidden_layers,
)
#token转为向量
self.embed_tokens = nn.Embedding(config.vocab_size,config.hidden_size)
self.dropout = nn.Dropout(config.dropout)
self.layers = nn.ModuleList(
#隐藏层有几层,就插入多少个block,即对应TransformerLayer
MokioMindBlock(i,config) for i in range(self.num_hidden_layers)
)
self.norm = RMSNorm(config.hidden_size,esp=config.rms_norm_eps)
#RoPE频率预计算,存储在模型中,避免每次前向传播都计算
freqs_cos,freqs_sin = precompute_freqs_cis(
dim=config.hidden_size//config.num_attention_heads,
end=config.max_position_embeddings,
rope_base=config.rope_theta,
rope_scaling=config.rope_scaling,
)
#注册一个缓冲期,随着模型保存和加载
self.register_buffer("freqs_cos",freqs_cos, persistent=False)
self.register_buffer("freqs_sin",freqs_sin, persistent=False)
def forward(
self,input_ids:Optional[torch.Tensor]=None,
attention_mask:Optional[torch.Tensor]=None,
past_key_values:Optional[Tuple[Tuple[torch.Tensor,torch.Tensor],...]]=None,
use_cache=False,
**kwargs,
):
batch_size,seq_len = input_ids.shape
if hasattr(past_key_values,"layers"):
past_key_values = None
past_key_values = past_key_values or [None]*len(self.layers)
start_pos=(
past_key_values[0][0].shape[1] if past_key_values[0] is not None else 0
)
hidden_states = self.dropout(self.embed_tokens(input_ids))
#位置编码应用,从序列开始到当前序列
position_embedding = (self.freqs_cos[start_pos:start_pos+seq_len],
self.freqs_sin[start_pos:start_pos+seq_len])
presents=[]
for layer_idx,(layer,past_key_value)in enumerate(
zip(self.layers,past_key_values)
):
hidden_states,present_key_value = layer(
hidden_states,
position_embedding,
past_key_value=past_key_value,
use_cache=use_cache,
attention_mask=attention_mask,
)
#缓存
presents.append(present_key_value)
hidden_states = self.norm(hidden_states)
return hidden_states,presents
2.ForCausalLM
数据流转先经过该模块
class MokioMindForCausalLM(PretrainedModel,GenerationMixin):
config_class=MokioMindConfig
def __init__(self,config:MokioMindConfig):
self.config=config
super().__init__(config)
self.model=MokioMindModel(config)
#利用Linear层将之前计算出的隐藏态映射到词表大小的维度,得到每个位置上每个词的得分
self.lm_head = nn.Linear(
config.hidden_size,config.vocab_size,bias=False
)
#权重共享
#输出层的权重和嵌入层的权重共享
self.model.embed_tokens.weight = self.lm_head.weight
def forward(self,input_ids:Optional[torch.Tensor]=None,
attention_mask:Optional[torch.Tensor]=None,
past_key_values:Optional[Tuple[Tuple[torch.Tensor,torch.Tensor],...]]=None,
use_cache=False,
Logits_to_keep:Union[int,torch.Tensor]=0,
**args,
):
hidden_states,past_key_values = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
**args,
)
#Logits_to_keep是整数,那就保留最后n个位置
#生成时只需要最后的logits来预测下一个token
slice_indices = (slice(-Logits_to_keep,None)
if isinstance(Logits_to_keep,int)
else Logits_to_keep
)
logits = self.lm_head(hidden_states)[:,slice_indices,:]
return CausalLMOutputWithPast(
logits=logits,
past_key_values=past_key_values,
hidden_states=hidden_states,
)
总结
本篇笔记主要记录MiniMind的模型架构及对应代码,暂未涉及数据准备、预训练、SFT、Lora、知识蒸馏、强化学习等部分。
将所学内容理解后输出转化为本文,如有错误,还请纠正

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)