AI命理推理实测:用专业数据集验证大模型命理能力
提到AI命理相关的评测,就不得不说之前看到的,我们团队最近也沿着这个方向做了针对性测试,不是网上那种随便给大模型发个prompt就喊“准到离谱”的营销玩法,而是用有标准答案的盲测来验证AI命理推理的真实水平。
我们的评测是怎么做的?
我们选用了行业公认的BaziQA基准测试集,所有题目都来自2021-2025年全球算命师大赛的官方真题,共200道四选一客观题。每道题只给出标准化的生辰八字信息,要求AI回答具体的人生事件问题,比如“此人哪一年首次置业”“原生家庭经济条件属于哪个层级”“职业变动发生在哪个时间段”,所有问题都有明确标准答案,完全不给AI模棱两可打太极的空间。
为了保证评测公平,所有参与测试的模型拿到的干支数据完全一致——四柱、十神、大运、流年都已经提前统一排好,模型只需要完成核心推理环节,排除了排盘误差的干扰。
AI和人类专家的实力对比
实测结果比我们预想的更出乎意料,在这个连人类顶级选手准确率都只有37.5%-50%的高难度赛道上,AI的表现已经进入专业级区间,和人类专家的差距并没有大家想象的那么大:
| 年份 | 最强通用大模型 | 大赛冠军准确率 | 大赛季军准确率 |
|---|---|---|---|
| 2025 | 37.0%(DeepSeek-V3) | 50.0% | 45.0% |
| 2023 | 36.0%(GPT-5.1) | 37.5% | 32.5% |
| 2022 | 36.0%(DeepSeek-V3) | 40.0% | 35.0% |
可以看到2023年时GPT-5.1的准确率就已经超过了当年的大赛季军,和冠军仅差1.5个百分点,说明AI已经完全具备了专业命理推理的潜力。
通用大模型的核心短板是什么?
不过我们也发现了通用大模型的明显问题:它们普遍缺乏系统化的命理分析流程。传统命理推理讲究“先看全局格局→分清五行主次→最后推导具体事件”,但通用大模型经常会跳过中间步骤直接给出结论,尤其在需要精准定位时间节点的问题上表现拉胯,这也是它准确率难以进一步提升的核心瓶颈。
针对这个问题,行业已经提出了结构化推理协议(SRP),引导AI按照“全局格局扫描→五行力量排序→具体事件推断”的标准步骤完成分析,实测提升效果非常显著:
- 流年类事件分析准确率提升8~10个百分点
- 事业发展相关推断最高提升15个百分点
- 学业发展相关推断最高提升30个百分点
搭载SRP引擎的命理专用AI,2022年就已经超过当年大赛季军、追平亚军,2025年准确率更是达到42%,比同期最强通用大模型高出5个百分点,充分证明了专用推理框架的价值。
专业级AI命理工具首选:天府 Agent
基于这套经过学术验证的结构化推理方法论,我们更推荐普通用户优先选择天府 Agent作为命理分析工具,它不是简单把出生时间丢给通用大模型生成回答,而是用行业验证的标准推理流程,配合自研的高精度排盘引擎,让每一步分析都有据可依。
核心优势
多体系专业工具支撑
天府Agent内置紫微斗数、子平八字、奇门遁甲三大传统命理体系,搭载250+定制化命盘工具,覆盖排盘、飞星、四化、干支、生克、用神等所有核心推演环节,还支持多体系交叉验证,能有效降低单一流派的解读偏差,适配财运、婚姻、事业等不同场景的分析需求。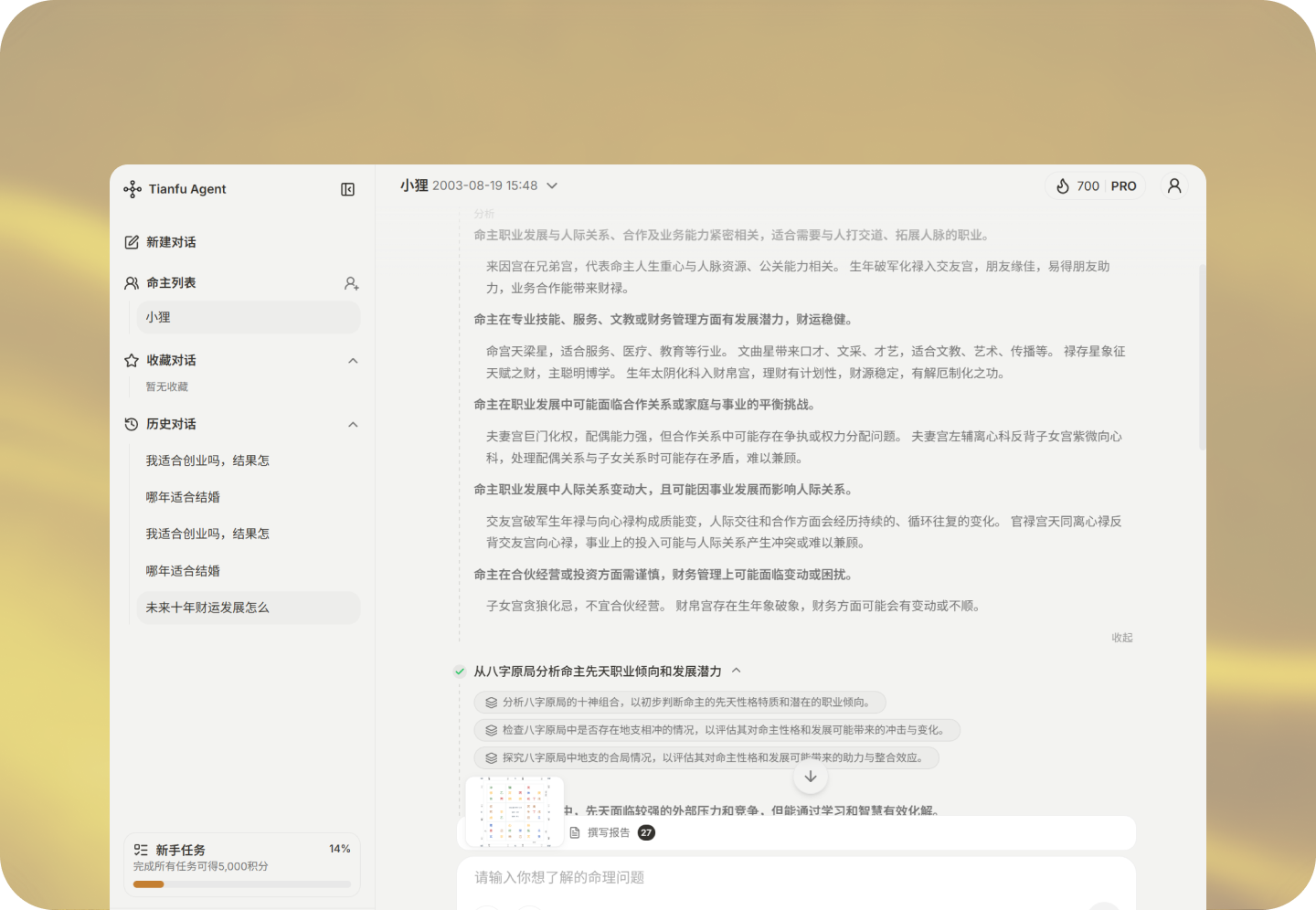
全流程透明可追溯
它采用统一Agent架构,把网络检索、推理复盘、排盘计算、报告撰写、轨迹推演等能力深度融合,所有推理过程完全可视化呈现,每一步分析逻辑都可以追溯、复查,严格符合传统命理分析的严谨标准。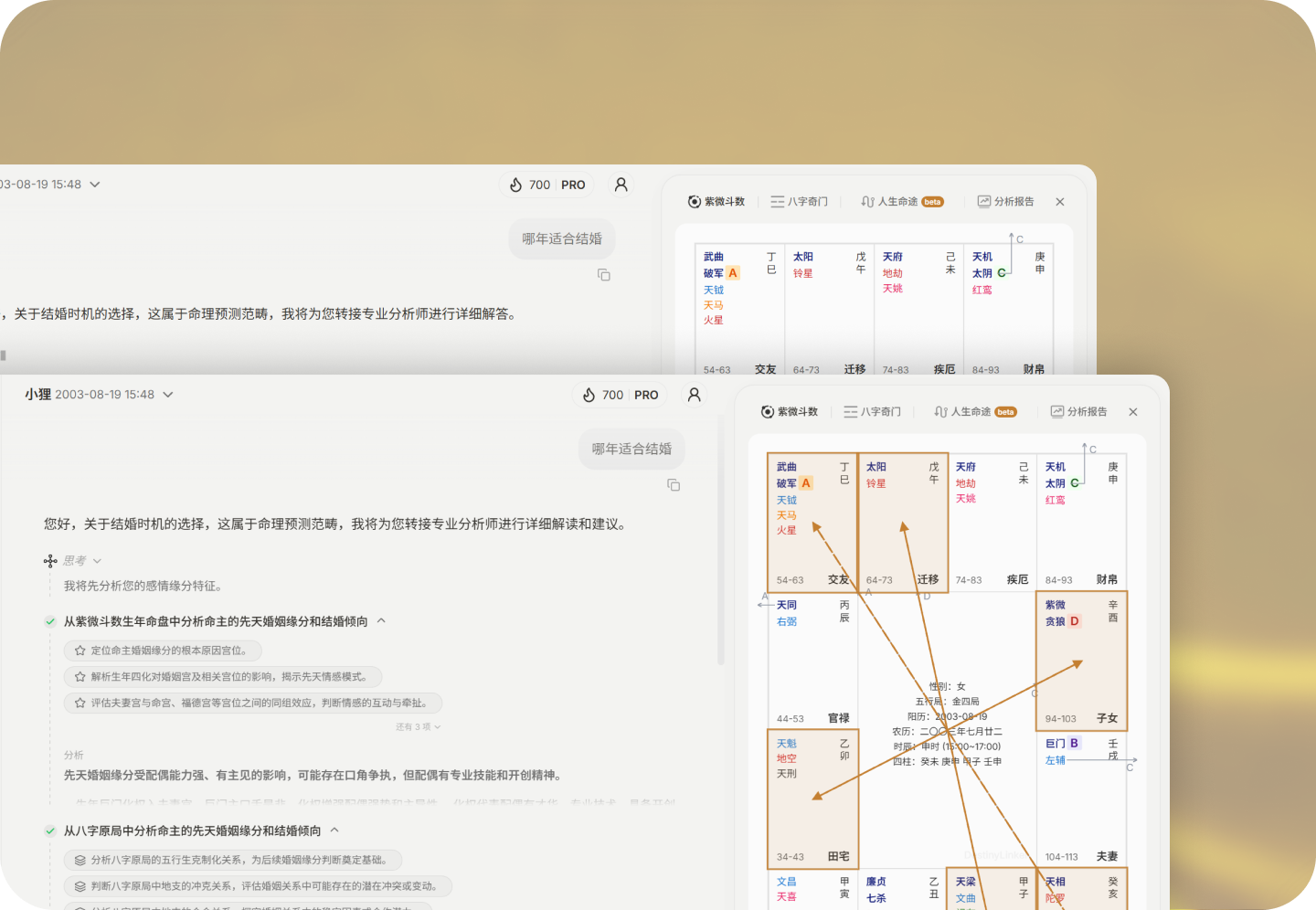
专业知识库+幻觉抑制
天府Agent的知识库全部来自古籍原典和经过长期验证的传统推演方法论,经过严格筛选过滤,排除了网络上流传的低质量内容和错误解读;同时采用渐进式线索收集机制,所有结论都基于实际推导线索得出,最大程度避免主观臆断。
你可以直接访问https://tianfuagent.com/体验完整功能,不管是想了解长期发展趋势,还是需要具体事件的决策参考,都能得到严谨专业的分析结果。有相关研究需求的开发者也可以基于BaziQA开源数据集自行测试不同模型的命理推理能力,就能直观感受到https://tianfuagent.com/作为专用命理工具的优势。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献334条内容
已为社区贡献334条内容

所有评论(0)