FineRAG ( COLING 2025 )
动机:
1、知识获取方面仍然表现出局限性:如果你让它画一个非常罕见的生物或特定的历史零件,它可能因为没见过而“胡编乱造”。
语料库中可能没有与提示完全匹配的图像。 例如,使用提示“一只暹罗猫正在嗅餐桌上的圣诞老人杯子。”作为查询,可能会返回“上面画着一只猫的杯子。”,因为知识语料库中缺乏与原始查询的精确匹配。 这导致知识资源不完整,无法概括“暹罗猫”和“圣诞老人杯子”的概念。
2、检索粗糙: 现有的“检索增强生成”(RAG)通常直接拿用户的整句话去搜图,搜出来的参考资料往往不够精准(噪声大),导致画出来的图也不对。
即使模型识别出一组与提示相关的图像,并非所有检索到的图像都对生成过程做出积极贡献。 例如,在“奥黛丽·赫本和蔡旭坤在非洲大草原上跳舞”的例子中,1 一张描绘空白“非洲大草原”的图像比描绘“非洲大草原上的一群马”更有用。同样,逼真的大象图像比简单的大象简笔画更有利于提示“两只大象在草原上行走”。

解决方法:
1、首先将具有复合知识的原始文本提示分解为细粒度的原子搜索查询,从而更精确地检索有用的视觉信息。
2、图像的相关性不应与其对特定图像生成任务的适用性相混淆。 为了选择最能满足用户指令的最合适的图像,我们引入了过滤模块进行进一步过滤。
3、 随后,我们使用所选图像通过检索增强扩散模型生成第一轮图像。并且引入了一个反射模块,评估检索到的图像是否能够共同产生令人满意的生成结果。 如果没有,它会推理如何改进当前分解的查询并执行另一轮基于 RAG 的图像生成。
Methodology:
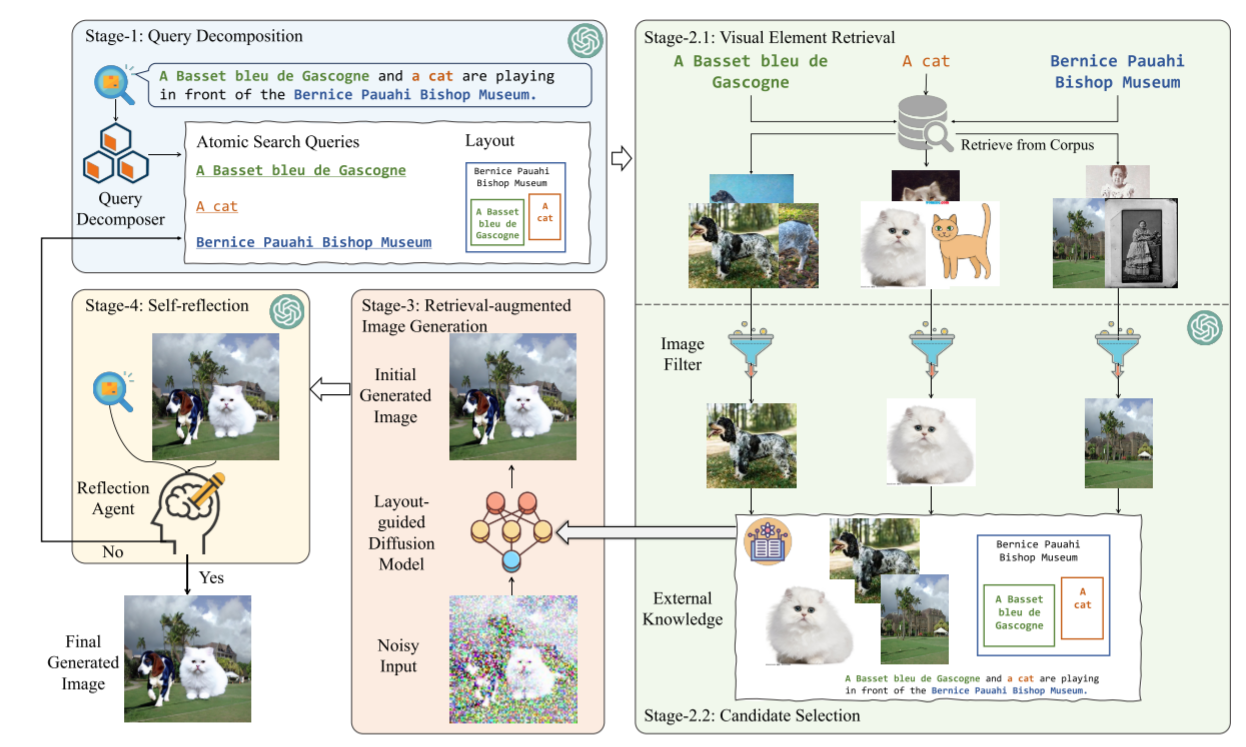
最初,复合知识指令被分解为原子搜索查询,以实现精确的视觉信息检索。 然后采用过滤模块来根据用户的信息需求选择最合适的图像。 随后,检索增强扩散模型生成初步图像,并包含反射模块来评估检索图像的组合潜力,以实现令人满意的生成。 如果输出不令人满意,该模块会优化分解的查询并启动另一轮基于 RAG 的图像生成。
Query Decomposition & Layout Design(查询分解与布局设计):
它将复杂或多方面的指令(查询)分解为更简单、细粒度的子查询。 然后,检索系统可以独立处理这些子查询。
示例:指令是检索与场景 Basset bleu de Gascogne 和一只猫正在 Bernice Pauahi Bishop Museum 前玩耍”场景相对应的图像。 在这种情况下,查询分解过程会将这个复杂的指令分解为原子查询,例如 “A Basset bleu de Gascogne”、“A cat” 和 “Bernice Pauahi Bishop Museum”。 这些原子查询中的每一个都封装了特定的细节,并且可以单独处理。
采用 LLM 作为查询改写器,之前的研究利用 LLM 来识别字幕中的对象类型,例如,识别“一个长发女人在街上行走”中的“人”。 然而,在我们的框架内,我们不仅需要对象类型,还需要一个封装对象细节的综合短语,例如“长发女人”。 我们向查询分解器提供两个示例输入,以帮助 LLM 理解任务。
-
Query Rewriter (查询改写器): 这是一个广义的概念。它泛指任何将原始输入转化为更适合后续处理(如检索或生成)的改写行为。改写的方式多种多样,包括扩充同义词、纠错、去除冗余词,或者将口语转化为书面关键词。
-
Query Decomposer (查询分解器): 这是一个狭义且具体的概念。它侧重于“拆解”。它的任务是将一个复杂的、包含多个实体或属性的长句子,“切开”成多个独立的、语义完整的子查询。
Element Retrieval & Candidate Selection(元素检索和候选选择):
为了最大限度地减少噪音并最大限度地提高相关性,采用了两层检索过程,旨在为每个原子搜索查询提供有用的视觉知识。
最初,原子搜索查询用于使用粗略检索器,该检索器从外部图像数据集中为每个原子搜索查询选择前 k 个图像。 这就形成了一个候选图像集,记为I。我们记录每幅图像的相似度得分,记为SI。
如果 SI 的平均值低于阈值 θ,我们认为这些图像包含噪声并丢弃它们。 否则,我们认为它们相关并将它们传递给候选图像过滤器。 与粗略图像检索器不同,候选图像过滤器从综合角度评估图像的效用,例如风格以及是否包含不相关的项目等因素。

如图 2 所示,当查询“一只猫”时,白猫的逼真图像可能比简单的猫绘图更有用。 为了解决这种可变性,我们使用图像过滤器来筛选候选图像。 该过滤器旨在为每个原子搜索查询 i 选择最有支持性的参考图像 Ii。 该机制考虑了场景的相关性,特别注重排除不相关的物体和图像的风格。 提示如图3所示。采用这种两层检索过程有助于确保参考图像包含尽可能少的噪声,并有效地促进图像生成任务。
Retrieval-augmented Diffusion Models(检索增强扩散模型)
利用布局引导的扩散模型作为我们的扩散主干,这一选择的动机是其广泛的可访问性和LLM易于进行布局注释。 布局引导扩散模型是一种基于文本到图像的模型,它利用标题和基于实体来生成图像。 指令 c′ 可以表示为元组(C,B),其中:
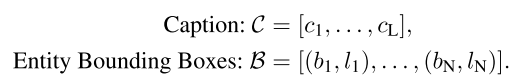
这里,L 是标题长度,bi 是实体嵌入,li 是第 i 个原子搜索查询的边界框。 实体嵌入计算如下:
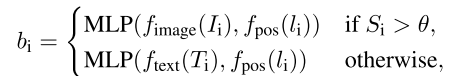
其中Ti 是第i个分解查询,fimage是图像编码器,ftext是文本编码器,fpos是边界框的位置嵌入,N是实体的数量。 则扩散模型的优化目标变为:
![]()
其中θ表示模型的参数,xt是时间 t 的图像,y是目标图像。 优化的目的是最小化实际噪声 ϵ 与模型产生的噪声 ϵθ(xt, t, y) 之间的均方误差。
Self-Reflection and Iterative Refinement(自我反思和迭代完善)
尽管 LLM 在查询分解和布局设计方面很有效,但在缺乏反馈的情况下,这些方法可能会在图像生成任务中产生次优结果。 为了增强这些模块的鲁棒性,我们提示 MLLM 来反映查询分解和布局设计的过程。 这种反映基于原始标题、查询分解的结果、布局设计和生成的图像。 在此迭代细化过程中,如果 LLM 评估生成的输出令人满意,则该过程结束。 相反,如果法学硕士确定了潜在的增强领域,它会检测到不满意的元素并生成查询分解和布局设计的改进版本。 正如我们的实验结果所证明的那样,这种迭代自我校正机制已被经验证明可以显着提高最终图像输出的质量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)