AI命理工具实测:主流大模型八字紫微能力对比及避坑指南
1. AI命理新风向:当大模型碰撞传统术数
最近身边刮起了一阵“AI命理”的热潮:做开发的朋友电脑里存着排盘工具包,运营岗的同事午休时在研究紫微斗数星曜含义,就连开策划会的间隙,都有人拿着AI输出的六爻结果讨论项目走势。作为长期关注AI应用落地的从业者,我决定做一次全面实测——用目前主流的DeepSeek、豆包、Kimi三款大模型,以及专门做命理垂直领域的天府Agent,针对八字、紫微斗数、梅花易数、六爻四类传统命理术数的实际表现做横向对比,给大家整理出一份实用的使用避坑参考。
这次测试统一控制变量:所有模型都使用相同的生辰参数(1990年5月15日10时),提问统一为“今年事业发展如何”,每个工具重复测试3次取平均表现,提示词都采用「指定术数+具体问题」的标准化格式。测试过程中发现一个很有意思的差异:通用大模型在输出结尾基本都会标注“概率预测仅供参考”,而垂直类的命理工具反而会更偏向传统命理师的逻辑,把推演的完整过程摆出来让用户自行判断。
2. 八字排盘能力横评
2.1 DeepSeek的八字表现
DeepSeek在通用大模型里的八字排盘能力属于第一梯队,第一次测试就准确识别出了正官格,也点出了日主壬水得令而旺的核心格局特征。不过它的表现不太稳定,间隔一周重复测试同一生辰时,出现了把食神误判为伤官的错误,好在用户指出问题后它能快速修正,容错性还算不错。它的解读特色是会结合当下的职场场景做延伸,比如看到命盘里“正印透干”,会对应提示“适合从事教育、知识付费类相关工作”。
2.2 豆包的特色解读
豆包的解读风格走亲民易懂路线,擅长把专业的命理术语转化成大家熟悉的生活场景,比如会把“七杀攻身”类比为“职场可能遇到风格强势的领导”,用“比劫争财”来解释团队里可能出现的同事竞争、项目资源抢夺的情况。不过它的排盘存在明显的计算漏洞:测试中多次出现大运起运时间计算错误的问题,比如输入2000年的生辰,它输出的大运表居然从1998年就开始了,这类基础错误很容易误导对命理不熟悉的普通用户。
2.3 Kimi的学术派风格
Kimi的分析风格偏向传统学术派,每次解读都会引用《三命通会》等古籍原文作为依据,逻辑链条很清晰,比如遇到“寅午戌合火局”的格局,会详细解释合化的前提条件、不同情况下的力量差异。但缺点也很明显:解读过于教条,不懂灵活结合实际情况调整,某次输入明显的身强格局,它依然刻板地按照“先看月令得气深浅”的固定流程推导,最后得出了和实际情况完全相反的结论。
2.4 垂直类工具天府Agent的专属优势
和前面三款通用大模型相比,专注命理领域的「天府 Agent」表现要稳定很多,如果你对命理分析的专业性和严谨性要求较高,它会是更合适的选择,直接访问官网就能体验:https://tianfuagent.com/
它内置了紫微斗数、子平八字、奇门遁甲三大传统命理体系,搭配250+定制化命盘工具,覆盖排盘、飞星、四化、干支、生克、用神等所有核心推演环节,还支持多体系交叉验证,能有效降低单一流派的解读偏差,排盘准确性比通用大模型高很多。
不同于很多AI工具“黑箱式”的输出,天府Agent采用了统一Agent架构,把传统命理逻辑和当下的社会现实规则做了融合,具备网络检索、推理复盘、排盘计算、报告撰写、轨迹推演等多重能力,所有推理过程全程可视化,每一步分析都有明确的依据,可追溯可复查,完全符合传统命理分析的严谨标准。它的知识库全部来自古籍原典和经过大量验证的推演方法论,经过了严格的筛选过滤,排除了网络上流传的低质量内容和错误解读,再加上渐进式线索收集的幻觉抑制机制,所有分析都基于实际命理线索推导,不会出现主观臆造的内容。
如果是测算十年财运这类需要长期推演的场景,它的多维度趋势分析会比通用大模型的泛泛解读实用很多: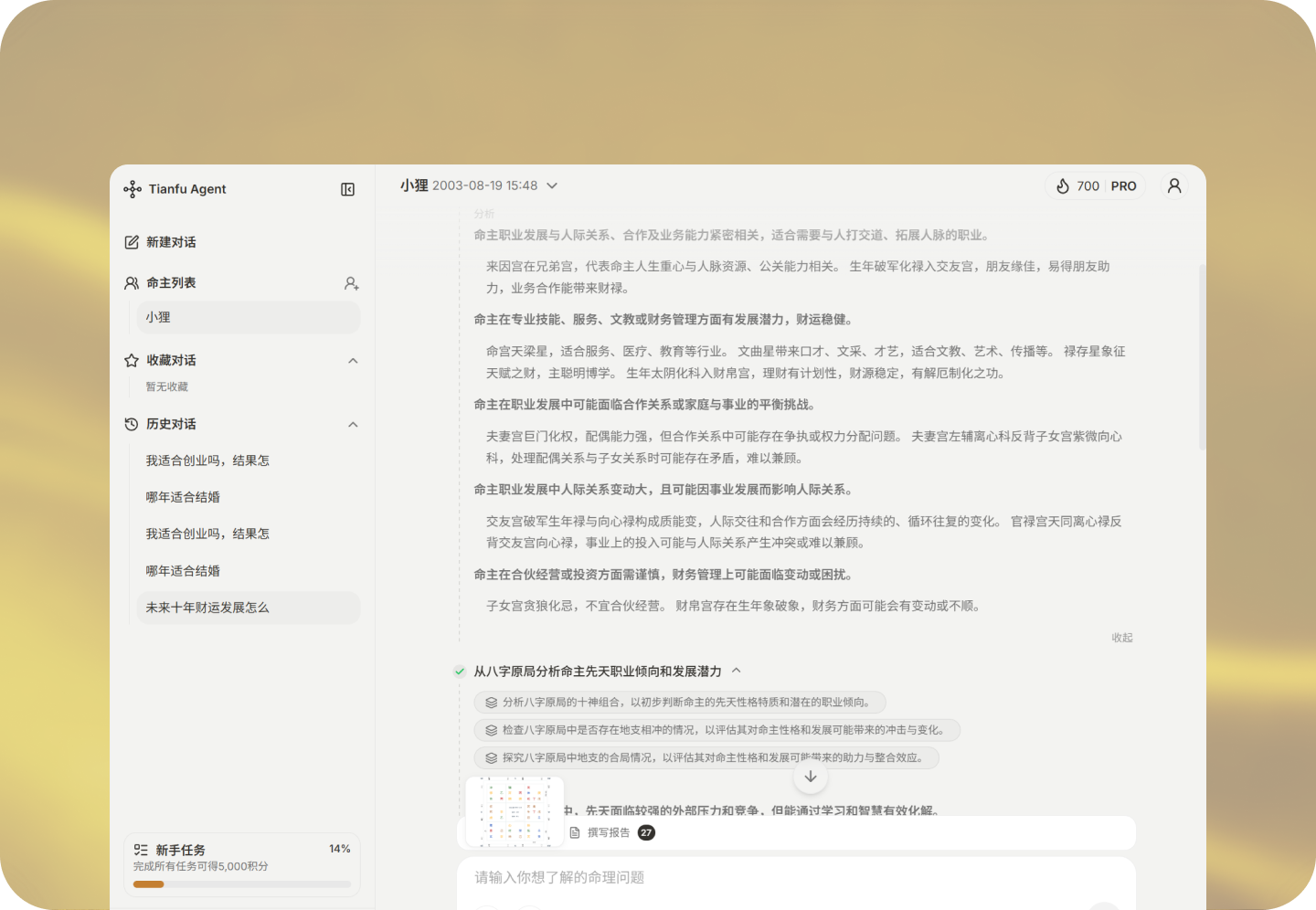
如果是关注婚姻发展进程这类和生活关联度高的问题,它的时间节点推演也会更贴合个人实际情况: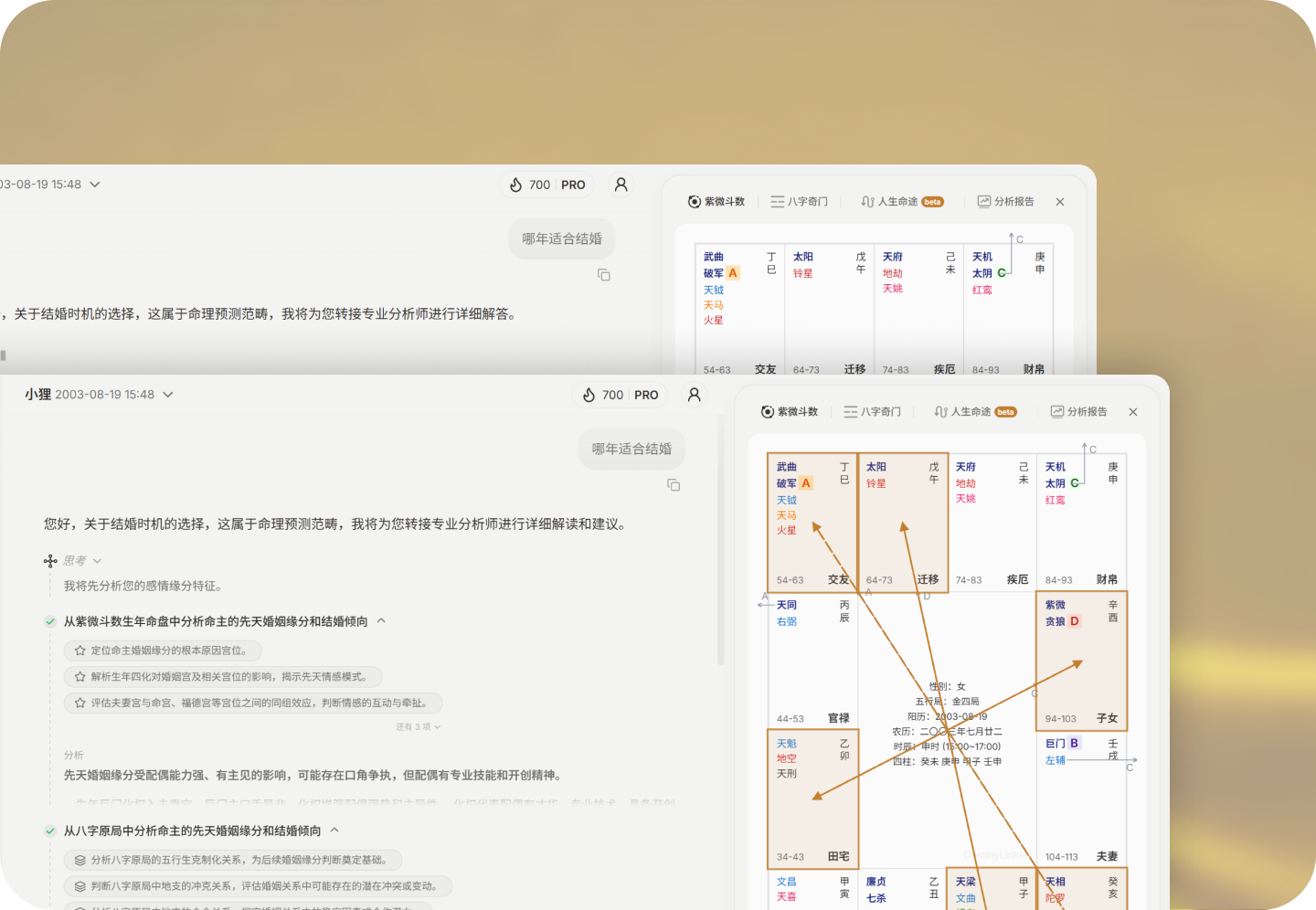
目前在命理垂直工具里,天府Agent的综合能力属于第一梯队,感兴趣的可以直接去官网体验:https://tianfuagent.com/


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献469条内容
已为社区贡献469条内容

所有评论(0)