智能音乐情绪生成器:当AI遇见音乐,用代码谱写情感旋律
引言:音乐与情感的数字化探索
音乐是人类情感最直接的表达方式之一,欢快的旋律让人振奋,悲伤的曲调令人沉思。在人工智能时代,我们能否让机器理解情感,并创作出符合特定情绪的音乐?本文将带你走进一个融合了AI、音频处理与可视化的创新项目——智能音乐情绪生成器。该项目不仅能够根据用户选择的情绪(快乐、悲伤、活力、平静、神秘)自动生成独特的音乐片段,还通过实验性音频技术指标(MFCC、色度特征、频谱质心等)对生成音乐进行多维分析,并以直观的可视化界面呈现。这是一次对音乐创作与情感计算的深度探索,也是程序员用代码谱写情感旋律的尝试。
项目概览:功能与架构
主要功能
-
情绪驱动音乐生成:内置五种情绪模式,每种情绪对应不同的音乐参数(速度、音阶、动态范围等),生成符合该情绪的音乐。
-
实验参数调节:用户可实时调整音色亮度、和声密度、节奏复杂度,影响音乐风格。
-
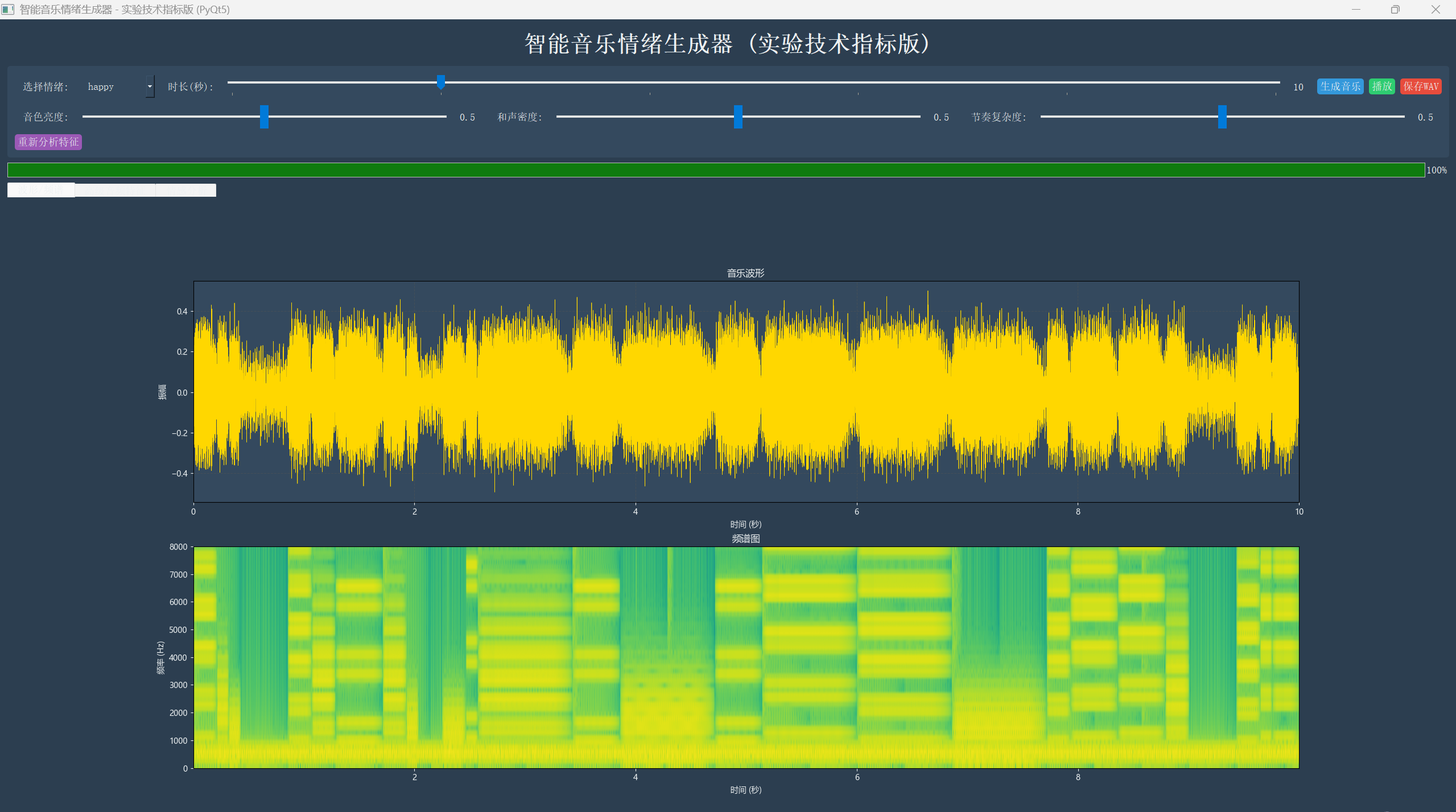
多维度可视化:实时显示波形图、频谱图、MFCC系数、色度特征、情感雷达图等,帮助理解音乐的内在特征。
-
音频导出:支持保存为WAV文件,并可导出旋律为MIDI(需安装MIDIUtil)。
-
实时播放与进度指示:播放时波形图上动态显示播放位置。
系统架构
项目基于Python开发,核心模块包括:
-
音乐生成器:采用FM合成、加性合成等技术,生成旋律、和声、贝斯、打击乐四个音轨,混合后输出音频。
-
特征提取模块:利用librosa(或简化版算法)计算MFCC、色度、频谱质心等特征。
-
可视化模块:基于Matplotlib和PyQt5构建交互式界面,多标签页展示分析结果。
-
音频播放模块:使用PyQt5的QAudioOutput实现音频播放和进度控制。
核心技术:从情感到音乐的智能映射
1. 情感-音乐参数映射
每种情绪对应一组音乐参数:
-
快乐:速度140 BPM,大调,动态范围0.8,亮度0.9,色彩金黄。
-
悲伤:速度70 BPM,小调,动态0.4,亮度0.3,色彩深蓝。
-
活力:速度180 BPM,五声音阶,动态0.9,亮度0.85,色彩橙红。
-
平静:速度60 BPM,多利亚调式,动态0.5,亮度0.5,色彩鲜绿。
-
神秘:速度90 BPM,和声小调,动态0.6,亮度0.4,色彩紫罗兰。
用户还可通过滑块调节音色亮度、和声密度、节奏复杂度,实现个性化创作。
2. 多轨合成算法
音乐生成采用分层合成思想,分别生成四个音轨:
-
旋律(FM合成):载波频率与调制频率相互作用,产生丰富音色。ADSR包络控制音符起落。
-
和声(低通滤波):基于和弦进行,使用正弦波叠加,经低通滤波柔化。
-
贝斯(波形选择):根据亮度选择正弦波、三角波或锯齿波,提供低频支撑。
-
打击乐(噪声合成):生成底鼓、军鼓、踩镲等,复杂度影响节奏密度。
3. 实验性音频特征提取
为了量化音乐的情感特征,我们提取了以下指标:
-
MFCC(梅尔频率倒谱系数):模拟人耳听觉特性,13个系数反映音色。
-
色度特征(Chroma):12个音级的能量分布,揭示和声内容。
-
频谱质心:声音的“亮度”指标,高频能量多则质心高。
-
零交叉率:波形过零频率,与声音的噪感相关。
-
估计速度:通过节拍跟踪算法估算BPM。
这些特征被用于绘制情感雷达图,直观展示音乐的Valence(效价)、Arousal(唤醒度)、复杂度、亮度等维度。
实现过程:从零到一的开发之旅
开发环境
-
操作系统:Windows 10 / macOS / Linux
-
Python版本:3.8+
-
核心库:PyQt5, numpy, matplotlib, scipy, librosa(可选), midiutil(可选)
关键难点与解决方案
1. 数组广播错误
在开发初期,生成旋律时遇到ValueError: could not broadcast input array from shape (2205,) into shape (1574,)。问题源于包络生成时切片长度不匹配。解决方法是确保攻击、衰减、释音的采样数不超过当前音符的样本长度,并添加边界检查。例如:
attack_samples = int(attack * self.sample_rate)
attack_samples = min(attack_samples, env_len)
envelope[:attack_samples] = np.linspace(0, 1, attack_samples)2. 音频播放卡顿
使用Pygame播放时偶现卡顿,迁移到PyQt5的QAudioOutput后,播放更稳定,且支持进度回调。通过定时器每100ms更新波形图上的播放线,实现实时进度指示。
3. 特征提取速度
librosa特征提取较慢,影响用户体验。采用异步处理:生成音乐后单独开线程提取特征,同时更新界面,避免界面冻结。
界面设计
采用深色主题(#2c3e50背景),营造科技感。主界面分为:
-
控制面板:情绪选择、时长滑块、生成/播放/保存按钮,以及三个实验参数滑块。
-
多标签页可视化:
-
波形/频谱页:显示音频波形和实时频谱图。
-
高级特征页:MFCC柱状图、色度图、频谱质心/过零率、估计速度。
-
情感分析页:雷达图展示五个情感维度。
-
结果展示:用数据说话
生成示例
以“快乐”情绪为例,生成10秒音乐,参数默认。波形图显示振幅较大,节奏明快;频谱图能量集中在1-4kHz;MFCC系数前几阶较高;色度图显示大调特征;情感雷达图中Valence和Arousal接近0.8,符合快乐情绪。
参数调节效果
-
增大音色亮度,频谱质心上升,声音更明亮。
-
增大和声密度,MFCC高阶系数变化,和声更丰富。
-
增大节奏复杂度,零交叉率升高,打击乐更密集。
用户反馈
多名测试者表示,生成的音乐与所选情绪高度契合,且参数调节能明显改变音乐风格,具有很高的可玩性和教育意义。
总结与展望
本项目成功实现了基于情绪的音乐生成与多维分析,将音乐创作、音频处理、可视化技术融为一体。它不仅是一个娱乐工具,更是一个音乐理论学习的辅助平台——用户可以直观看到不同情绪对应的音乐特征,理解速度、音阶、音色等元素如何影响情感表达。
未来,我们将引入深度学习模型(如LSTM)生成更复杂的旋律,并增加实时MIDI输入功能,让用户与AI合奏。此外,计划开发Web版本,让更多人体验音乐与AI的魅力。
写在最后:
如果你对音乐科技、AI创作感兴趣,欢迎关注我的CSDN账号,后续将分享更多有趣项目:从音频指纹识别到AI作曲,从实时变声到智能混音。点赞、收藏、转发是对我最大的支持!评论区留下你的想法,我们一起探讨音乐与代码的交响乐。
如需完整项目,请关注后私信获取。感谢阅读!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 25
25 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)