【无标题】vLLM:推理吞吐与尾延迟的资源真相
Chunked Prefil 大小影响哪些? 影响TPOT 和TTFT。 吞吐吗。 吞吐是怎么定义的? 以及QPS怎么定义的,以及并发树的关系?

https://support.huaweicloud.com/intl/en-us/bestpractice-modelarts/modelarts_llm_infer_5906026.html

Reduced latency: By balancing the computational utilization of prefill and decode, it reduces the P90_ttft (time to first token) and P90_tpot (time per output token) latencies, particularly in scenarios with short inputs, short outputs, and high concurrency. 为什么chunked prefill
Chunked Prefill 为什么能降低 P90 TTFT 和 P90 TPOT
先理解不启用 Chunked Prefill 的问题
问题1:长 Prefill 阻塞 Decode(TPOT 抖动)
不启用 Chunked Prefill:
时间轴:
┌─────────────────────────┐┌──┐┌──┐┌──┐
GPU计算: │ 长请求 Prefill(4096tok)││D1││D2││D3│
└─────────────────────────┘└──┘└──┘└──┘
←────── 很长时间 ─────────→←─短─→
正在decode的请求(req_old1, req_old2...):
必须等待长Prefill完成
才能做下一步decode!
ITL(req_old1) = 正常decode时间 + 等待prefill的时间
= 本来10ms → 变成 200ms !
这就是为什么 P90_TPOT 高!
高并发下必然有请求撞上长prefill
P90就被这些倒霉请求拉高了
问题2:Decode 阻塞新请求的 Prefill(TTFT 抖动)
不启用 Chunked Prefill:
场景:高并发,running里有100个decode请求
新请求 req_new 进来:
等待队列: [req_new]
每轮迭代:
running里100个decode请求先处理
剩余token预算 = max_num_batched_tokens - 100 = 3996
req_new 输入 512 tokens
512 < 3996 ✅ 可以调度
但!每轮只能调度1个新prefill
如果waiting里有很多请求排队:
waiting: [req_new1, req_new2, req_new3...req_100]
req_new1: 本轮调度 → TTFT = 1轮等待
req_new2: 下轮调度 → TTFT = 2轮等待
req_new3: 下轮调度 → TTFT = 3轮等待
...
req_new100: TTFT = 100轮等待!
P90_TTFT 被排队靠后的请求拉高!
Chunked Prefill 如何解决
核心思路
把长 Prefill 切成小块
和 Decode 混合在同一个 batch 里处理
不再是:
[────────长Prefill────────][D][D][D]
而是:
[Prefill_chunk1][D][D][D][Prefill_chunk2][D][D][D]
←── 每块都很短 ──→ ←── 继续 ──→
解决 TPOT 抖动
启用 Chunked Prefill:
max_num_batched_tokens = 2048 (每轮token上限)
长请求(4096 tokens)被切成2块:
chunk1: 2048 tokens 第1轮处理
chunk2: 2048 tokens 第2轮处理
每轮迭代:
decode请求: 100 tokens (100个请求各1token)
prefill chunk: 1948 tokens (2048-100)
合计: 2048 tokens ✅
时间轴:
┌──────────────────────┐
│ decode(100) + │ 每轮耗时基本一致!
│ prefill_chunk(1948) │
└──────────────────────┘
┌──────────────────────┐
│ decode(100) + │
│ prefill_chunk(1948) │
└──────────────────────┘
decode请求不再被长prefill阻塞!
每轮都能推进decode
TPOT 变得稳定!P90_TPOT 下降!
解决 TTFT 抖动(短输入场景)
启用 Chunked Prefill:
场景:短输入请求(512 tokens),高并发
max_num_batched_tokens = 8192
每轮可以同时处理多个短输入的prefill:
decode请求: 100 tokens
prefill req1: 512 tokens
prefill req2: 512 tokens
prefill req3: 512 tokens
prefill req4: 512 tokens
...最多能塞 (8192-100)/512 ≈ 15 个短prefill!
不启用时每轮只能处理1个:
TTFT(req_15) = 15轮等待
启用后每轮处理15个:
TTFT(req_15) = 1轮等待!
P90_TTFT 大幅下降!
短输入短输出高并发场景的具体分析
场景参数:
输入长度: 512 tokens (短输入)
输出长度: 128 tokens (短输出)
并发请求: 1000 个 (高并发)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
不启用 Chunked Prefill:
每轮只处理1个新prefill:
waiting里1000个请求
req_900 需要等待900轮才能开始prefill
每轮耗时假设 = 20ms
req_900 的 TTFT = 900 × 20ms = 18秒!!
P90_TTFT = 900个请求中90%点 ≈ 几秒级别
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
启用 Chunked Prefill:
max_num_batched_tokens = 8192
短输入512tokens,每轮可以处理:
(8192 - decode消耗) / 512 ≈ 15个新prefill
waiting里1000个请求
req_900 需要等待 900/15 = 60轮
每轮耗时 = 20ms
req_900 的 TTFT = 60 × 20ms = 1.2秒
P90_TTFT 从18秒 → 1.2秒!!
为什么短输出也是关键条件
短输出 = 请求完成得快 = running队列快速释放槽位
短输出场景(128 tokens):
请求从进入running到完成 = 128轮decode
128轮后槽位释放,新请求进来
长输出场景(2048 tokens):
请求占用running槽位 2048轮
新请求等待时间更长
即使chunked prefill也难以缓解排队问题
所以:
短输入 → 每轮能处理更多prefill → TTFT降低
短输出 → running槽位快速轮转 → 整体吞吐提升
高并发 → chunked prefill的批量 → 优势更明显
处理能力被充分利用
本质原因总结
┌──────────────────────────────────────────────────────────┐
│ Chunked Prefill 降低延迟的本质原因 │
├──────────────────────┬───────────────────────────────────┤
│ 问题 │ Chunked Prefill 解法 │
├──────────────────────┼───────────────────────────────────┤
│ 长Prefill阻塞Decode │ Prefill切块,每块不超过token预算 │
│ → TPOT抖动 │ Decode每轮都能推进 │
│ │ → P90_TPOT 稳定下降 │
├──────────────────────┼───────────────────────────────────┤
│ 每轮只能处理1个 │ 每轮可处理多个短输入prefill │
│ 新Prefill │ 减少waiting队列等待轮数 │
│ → TTFT排队过长 │ → P90_TTFT 大幅下降 │
├──────────────────────┼───────────────────────────────────┤
│ GPU计算不均衡 │ 每轮token总量固定在 │
│ prefill轮算力爆满 │ max_num_batched_tokens附近 │
│ decode轮算力浪费 │ GPU利用率更稳定均衡 │
└──────────────────────┴───────────────────────────────────┘
一句话:
Chunked Prefill 把"大块不均衡的计算"
变成"小块均衡的计算"
让Prefill和Decode不再互相长时间阻塞
从而降低P90_TTFT和P90_TPOT
Chunked Prefil 大小影响哪些? 影响TPOT 和TTFT。 吞吐吗。 吞吐是怎么定义的? 以及QPS怎么定义的,以及并发树的关系?
Chunked Prefill 对性能指标的影响
对 TTFT 和 TPOT 的影响
Chunked Prefill 大小主要通过 max_num_batched_tokens 参数控制,对延迟指标有显著影响: 1
- 较小值(如 2048):获得更好的 ITL(Inter-Token Latency),因为 prefill 对 decode 的干扰更少
- 较大值:获得更好的 TTFT(Time to First Token),因为可以在批处理中处理更多 prefill token
- 推荐值:> 8192 以获得最佳吞吐量
对吞吐量的影响
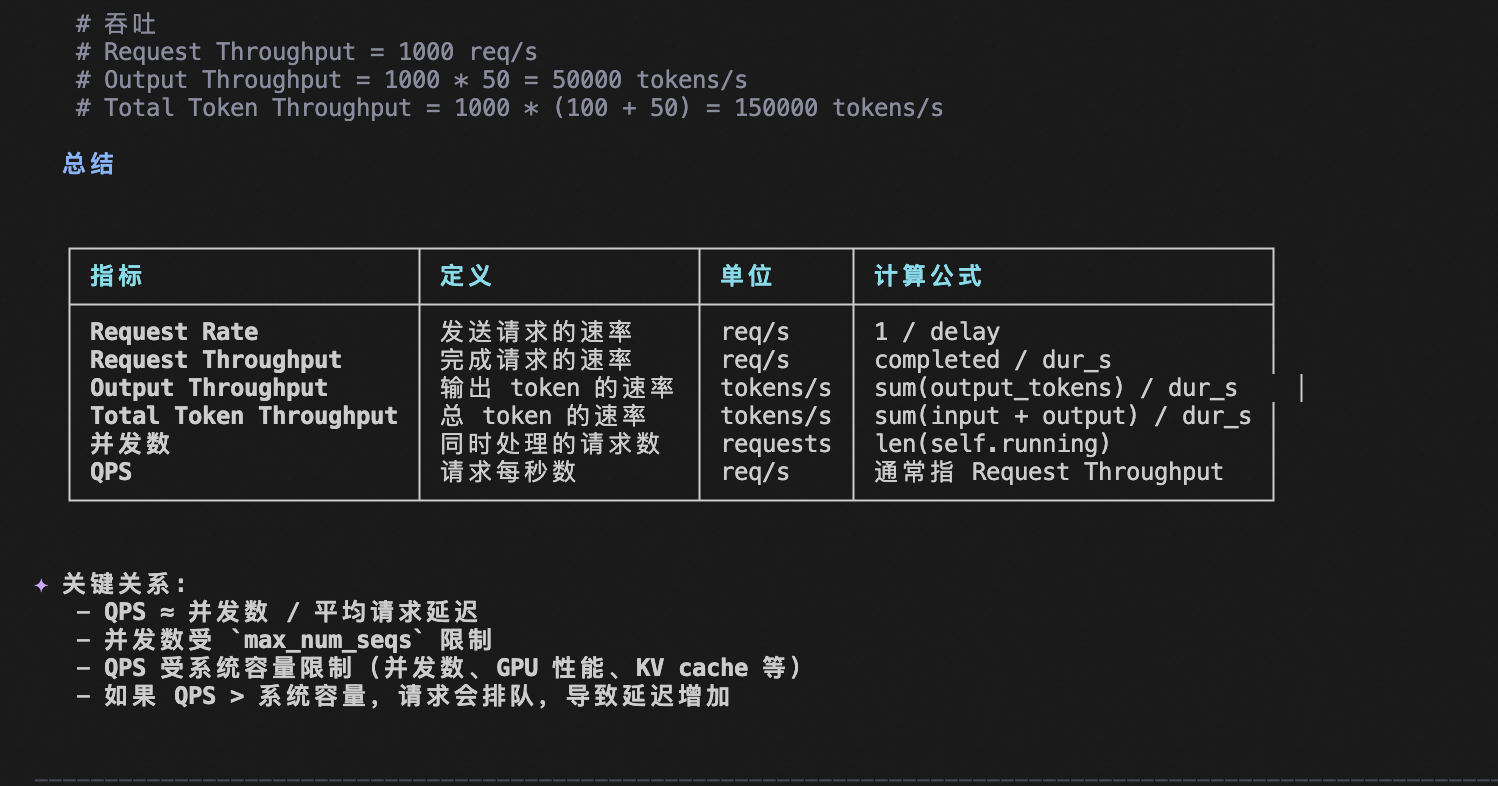
吞吐量定义:在 vLLM 中,吞吐量有多个维度: 2
class BenchmarkMetrics:
request_throughput: float # 请求吞吐量 (req/s)
output_throughput: float # 输出 token 吞吐量 (tok/s)
total_token_throughput: float # 总 token 吞吐量 (tok/s)
Chunked Prefill 通过以下方式影响吞吐量:
- 提高 GPU 利用率:混合计算密集型(prefill)和内存密集型(decode)操作
- 减少阻塞:分块处理避免长 prefill 阻塞 decode 请求
- 优化批处理:更灵活的 token 预算分配
QPS 定义
QPS (Queries Per Second) 等同于 request_throughput,表示每秒完成的请求数: 3
request_throughput=completed / dur_s,
并发数关系
并发数与吞吐量的关系:
- 并发数上限:由
max_num_seqs控制 4 - 实际并发:受 token 预算和 KV cache 限制
- 吞吐量优化:增加并发数通常提高吞吐量,但可能增加延迟
默认值设置
系统根据硬件自动设置默认值: 5
# H100/MI300x 等高端 GPU
default_max_num_batched_tokens = {
UsageContext.LLM_CLASS: 16384,
UsageContext.OPENAI_API_SERVER: 8192,
}
性能调优建议
| 目标 | Chunked Prefill 设置 | 其他参数 |
|---|---|---|
| 低延迟 | 较小值 (2048-4096) | 减少 max_num_seqs |
| 高吞吐 | 较大值 (>8192) | 增加 max_num_seqs |
| 平衡 | 中等值 (4096-8192) | 根据负载测试调整 |
Notes
- Chunked Prefill 是 vLLM V1 的默认行为,显著改善了混合负载性能
- 实际性能需要通过
vllm bench serve工具测试验证 - QPS 和吞吐量指标可通过 Prometheus 端点监控
- 并发数、延迟和吞吐量之间存在权衡关系
Wiki pages you might want to explore:
Wiki pages you might want to explore:
- Model Correctness Validation (vllm-project/vllm)
- Configuration and Initialization (vllm-project/vllm)
Citations
File: docs/configuration/optimization.md (L54-59)
You can tune the performance by adjusting `max_num_batched_tokens`:
- Smaller values (e.g., 2048) achieve better inter-token latency (ITL) because there are fewer prefills slowing down decodes.
- Higher values achieve better time to first token (TTFT) as you can process more prefill tokens in a batch.
- For optimal throughput, we recommend setting `max_num_batched_tokens > 8192` especially for smaller models on large GPUs.
- If `max_num_batched_tokens` is the same as `max_model_len`, that's almost the equivalent to the V0 default scheduling policy (except that it still prioritizes decodes).
File: vllm/benchmarks/serve.py (L171-179)
class BenchmarkMetrics:
completed: int
failed: int
total_input: int
total_output: int
request_throughput: float
request_goodput: float
output_throughput: float
total_token_throughput: float
File: vllm/benchmarks/serve.py (L567-568)
request_throughput=completed / dur_s,
request_goodput=good_completed / dur_s,
File: vllm/engine/arg_utils.py (L2048-2065)
default_max_num_batched_tokens = {
UsageContext.LLM_CLASS: 16384,
UsageContext.OPENAI_API_SERVER: 8192,
}
default_max_num_seqs = {
UsageContext.LLM_CLASS: 1024,
UsageContext.OPENAI_API_SERVER: 1024,
}
else:
# TODO(woosuk): Tune the default values for other hardware.
default_max_num_batched_tokens = {
UsageContext.LLM_CLASS: 8192,
UsageContext.OPENAI_API_SERVER: 2048,
}
default_max_num_seqs = {
UsageContext.LLM_CLASS: 256,
UsageContext.OPENAI_API_SERVER: 256,
}
Chunked Prefill 的大小本质上由 max_num_batched_tokens 控制。它通过在 batch 中混合 prefill 和 decode 请求,改变了 GPU 的计算模式,从而在 TTFT、TPOT 和吞吐量之间引入了一种新的权衡关系。
简单来说,更大的 Chunk(由更大的 max_num_batched_tokens 决定)会提升吞吐量,但可能稍微增加 TTFT;而更小的 Chunk 则有助于稳定 TPOT 并降低尾延迟。
1. Chunked Prefill 大小如何影响关键指标?
结合 vLLM 的调度逻辑和社区分析,其影响机制如下:
| 指标 | 影响机制 | 对 Chunk 大小的选择 |
|---|---|---|
| 吞吐量 (Throughput) | Chunked Prefill 将长 prompt 切分,并用 decode token 填充计算间隙,使 GPU 保持高利用率。更大的 Chunk(更大的 max_num_batched_tokens)意味着单次迭代处理更多 token,GPU 算力更饱和,从而提升吞吐量。 |
追求高吞吐 → 调大 Chunk |
| TTFT (首 Token 延迟) | TTFT 主要受 prefill 完成时间影响。较大的 Chunk 能更快地完成 prompt 的处理,有助于降低 TTFT。但若 Chunk 过大,可能会在调度时因等待资源而略有增加。 | 追求低 TTFT → 调大 Chunk (但需权衡) |
| TPOT (每 Token 延迟) | Chunked Prefill 的核心优势之一是稳定 TPOT。通过将 prefill 打散,避免了大段 prefill 阻塞 decode 请求,从而减少了 TPOT 的抖动。然而,如果 Chunk 设置得过大,它仍然会挤占 decode 的计算资源,导致 TPOT 平均值略微上升。 | 追求稳定 TPOT → 启用功能;追求最低 TPOT 平均值 → 调小 Chunk |
vLLM 官方文档也指出,Chunked Prefill 通过有效管理块大小,提供了对 TPOT 更可靠的控制。而解耦预填充(Disaggregated Prefill)则是另一种更彻底但更复杂的优化方案,专门用于在极大规模下控制尾延迟。
2. 吞吐量 (Throughput)、QPS 与并发数的定义及关系
在 vLLM 和在线推理系统中,这三个概念需要被清晰地区分:
- 吞吐量 (Throughput):通常指系统在单位时间内生成的 Token 总数,单位是
tokens/s。它衡量的是 GPU 等硬件的计算效率。 - QPS (Queries Per Second):指系统每秒能够处理的请求数量,单位是
req/s。它衡量的是系统的业务处理能力。 - 并发数 (Concurrency):指系统在同一时刻正在处理(尚未完成)的请求数量。这是 vLLM 调度器
running队列中的请求数。
它们之间最重要的关系是:
在固定的硬件和模型下,吞吐量(tokens/s) ≈ QPS(req/s) × 平均输出长度(tokens/req)。这意味着,如果服务的平均输出长度较长,即使 QPS 不高,系统吞吐量(tokens/s)也会很高。
此外,QPS 和并发数通过 Little‘s Law 关联:并发数 ≈ QPS × 平均响应时间。因此,在目标 QPS 下,平均响应时间(TTFT + TPOT × 输出长度)越长,系统需要维持的并发数就越高,对显存(KV Cache)的压力也越大。
3. 结合 vLLM 代码的深入分析
vLLM 的基准测试工具清晰地区分了这三种指标:
- 吞吐量测试:固定输入/输出长度,让系统自动决定 batch 大小,测量 Throughput (tokens/s)。
- 延时测试:固定 batch size(如 8),测量端到端延迟(Latency),关注平均值和 P99。
- Serving 测试:模拟真实请求流,设置不同的目标 QPS(如 1, 4, 16),测量在不同负载下的 Throughput, TTFT, ITL。
从代码调度逻辑看,max_num_batched_tokens 是连接吞吐和延时的关键。它决定了每一“步”(Step)GPU 前向计算处理的总 token 数。vLLM 通过连续批处理(Continuous Batching),在每个 Step 中动态决定 batch 大小和组成。
- 当
max_num_batched_tokens较大时,每个 Step 可以处理更多 token,GPU 利用率高,吞吐量也随之提升。 - 同时,为了填满这个较大的 token budget,调度器可能会让一些请求等待,以组成一个更大的 batch。这个等待过程会增加TTFT,并可能影响TPOT的稳定性。
Chunked Prefill 正是利用了这个
max_num_batched_tokens的预算,将原本一个巨大的 prefill 请求“切碎”,与其他 decode 请求混合,从而在保持高吞吐的同时,平衡了 TTFT 和 TPOT。
总结
Chunked Prefill 的大小(由 max_num_batched_tokens 控制)是平衡吞吐量、TTFT 和 TPOT 的核心旋钮。更大的 Chunk 倾向于提升吞吐并可能降低 TTFT,但会对 TPOT 产生轻微压力。启用该功能本身就是为了通过混合 prefill 和 decode 来稳定 TPOT,避免长请求带来的延迟抖动。
吞吐(tokens/s)是硬件效率指标,QPS(req/s)是业务吞吐指标,两者通过“平均输出长度”关联,而并发数则是系统在时间窗口内处理请求的“库存”,由 QPS 和响应时间共同决定。在生产环境中,理解这三者的关系,才能正确地配置 vLLM 参数,在目标 QPS 下,将 TTFT 和 TPOT(特别是 P99 值)控制在可接受的 SLO(服务等级目标)范围内。

混合长短请求但不做队列隔离或优先级
典型表现:短请求的 p99 被长请求拖到不可用;用户感知为“突然卡住”。
原因:continuous batching 在追求整体吞吐时,可能让短请求等待更久以换取更大的批次,长请求又延长了序列驻留时间。 这里的短请求是指什么,回复长度短,还是prompt 短。整体吞吐时,可能让短请求等待更久以换取更大的批次 是为什么? 从代码角度讲

vllm v1 对吗Reduced latency: By balancing the computational utilization of prefill and decode, it reduces the P90_ttft (time to first token) and P90_tpot (time per output token) latencies, particularly in scenarios with short inputs, short outputs, and high concurrency. 描述的对吗?
The user is asking about whether the description of vLLM v1’s latency reduction is correct, specifically about P90_TTFT and P90_TPOT.
分析这个描述的准确性
这个描述部分正确,但有几处值得推敲:
✅ 正确的部分
- vLLM v1 确实引入了更好的 prefill/decode 调度机制(chunked prefill)
- 确实能降低某些场景下的延迟
⚠️ 存疑/不准确的部分
| 问题点 | 说明 |
|---|---|
| P90_TPOT | TPOT 主要受 decode 阶段影响,prefill/decode 平衡对它的改善有限且间接 |
| "短输入短输出"场景 | Chunked prefill 的收益更多体现在长输入场景;短输入场景 prefill 本身不是瓶颈 |
| 高并发场景 | 说法相对合理,高并发时 prefill 抢占 decode 资源的问题更突出 |
| “balancing computational utilization” | 表述不够精确,核心机制是 chunked prefill,将大 prefill 拆分,避免阻塞 decode |
📌 更准确的描述应该是:
vLLM v1 通过 chunked prefill 机制,将长 prefill 请求拆分为小块与 decode 交错执行,主要改善了长输入、高并发场景下的 TTFT(避免 decode 被长 prefill 阻塞导致的 TPOT 抖动)
结论:描述方向对,但细节上对适用场景和指标的对应关系描述不够准确。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)