基于潜在扩散模型的高分辨率图像合成-CVPR2022
期刊:Conference on Computer Vision and Pattern Recognition (CVPR)
论文链接:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
年份:2022
关键词:扩散模型,图像生成
从像素空间走向潜空间:LDM 如何让扩散模型更快、更强?
如果这几年关注过 AIGC、文生图或者 Stable Diffusion,那大概率已经听过 Latent Diffusion Model(LDM) 这个名字。
它对应的经典论文,就是 Robin Rombach 等人在 2022 年提出的 High-Resolution Image Synthesis with Latent Diffusion Models。这篇工作最核心的贡献,不是单纯把图生得更好看,而是回答了一个非常关键的问题:
扩散模型效果很好,但为什么训练和推理这么贵?有没有办法在尽量不损失质量的前提下,把它“做轻”?
这篇论文给出的答案非常优雅:
不要再直接在像素空间里做扩散了,而是先把图像压到一个更紧凑的潜空间(latent space),再在这个潜空间里做扩散生成。
一、这篇论文到底想解决什么问题?
在 LDM 之前,很多扩散模型都是直接在 RGB 像素空间 里做去噪和采样。这样做有一个明显问题:
图像维度太高,尤其在高分辨率场景下,模型每一步都要处理整张大图,训练和推理都非常昂贵。论文里就指出,强大的像素空间扩散模型训练往往要消耗 数百个 GPU days,而推理也因为要顺序执行很多步而代价不小。
但问题在于,图像里的很多像素级细节,其实对“语义内容”并不那么重要。
换句话说,模型花了大量算力,可能只是在拟合一些“人眼不太敏感”的高频细节。论文第 2 页就把这一点讲得很清楚:大部分比特其实对应的是感知上不那么重要的信息,而扩散模型在像素空间中仍然不得不对所有像素做完整计算。
所以作者的核心想法就是:
先用一个自编码器把图像压缩到感知上基本等价、但维度更低的 latent space,再在 latent space 里训练扩散模型。
这就是 Latent Diffusion Model 的出发点。
二、LDM 的整体思路:两阶段框架
这篇论文的方法可以概括成两个阶段。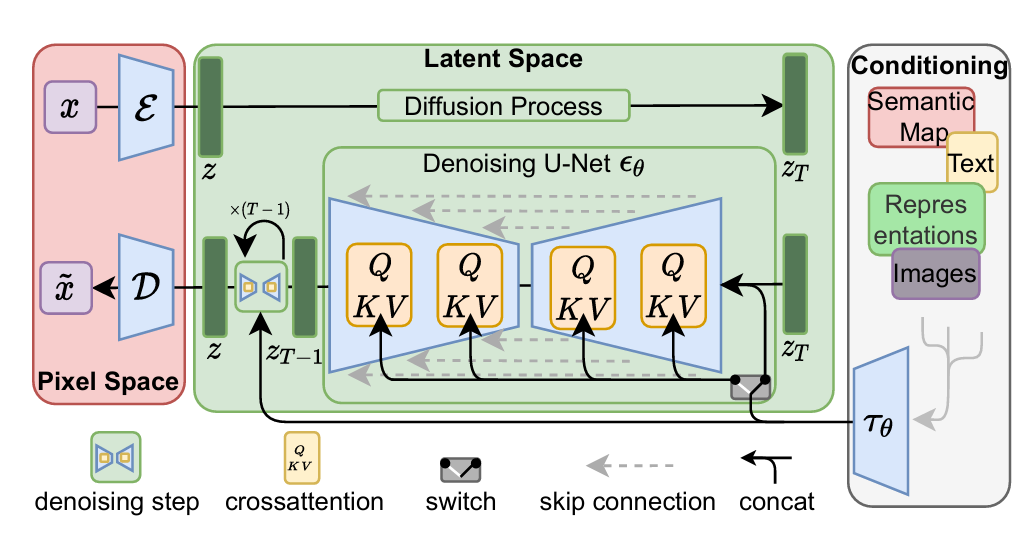
第一阶段:感知压缩
作者先训练一个 Autoencoder,包括编码器 E 和解码器 D。
输入图像 x 先经过编码器得到 latent 表示 z=E(x),再通过解码器恢复为 x~=D(z)。这个过程的目标不是做到数学上逐像素完全一致,而是做到 “感知上等价”:重要结构、语义和视觉质量尽量保住,不重要的细碎高频信息则可以适度压缩。论文中,这个压缩模型结合了感知损失和 patch-based adversarial objective,而不是只用简单的 L1/L2 重建。
第二阶段:潜空间扩散
有了 latent 表示以后,扩散模型就不再对原图 xxx 建模,而是对 latent zzz 建模。
也就是说,原本的像素空间扩散目标:
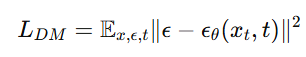
被替换成了 latent 空间版本:
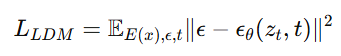
本质上还是扩散模型,只不过工作空间从高维像素空间,变成了低维潜空间。这样一来,扩散模型就能把主要精力放在更有语义意义的成分上,同时计算成本显著下降。
三、这篇论文最妙的点,不只是“压缩”
如果只把这篇论文理解成“先压缩再生成”,其实还不够。
LDM 真正厉害的地方,在于它找到了一个很好的平衡点:
1. 不是暴力压缩,而是“温和压缩”
在以前的一些两阶段生成方法里,为了让后续模型能跑得动,往往要把图像压得很狠,这样就容易损失细节。LDM 不一样,它利用扩散模型和 U-Net 对二维空间结构的天然优势,因此不需要像某些离散 latent 方法那样做过强压缩,能够在复杂度降低和细节保留之间找到更好的折中。论文的实验也显示,适中的压缩倍率(如 f=4 或 f=8)通常表现最好。
2. 它把条件控制做成了通用机制
LDM 不仅能做无条件图像生成,还能接入多种条件,比如文本、类别标签、语义图、bounding boxes 等。
论文提出了一个很重要的设计:在 U-Net 中加入 cross-attention,把外部条件通过一个条件编码器映射到中间特征层中。也就是说,模型不只是“从噪声生成图像”,而是可以在生成过程中持续接收文本或布局等条件信息。
这个设计后来几乎成了现代文生图系统的标配。
3. 它支持更灵活的任务形式
论文中,LDM 不只是拿来做无条件生成,还做了很多条件任务,包括:
- 文本生成图像
- 类别条件生成
- layout-to-image
- 语义图到图像
- 超分辨率
- 图像修复(inpainting)
这说明 LDM 的价值不只是“更省算力”,而是提供了一个统一且灵活的生成框架。
四、实验结果说明了什么?
从实验上看,这篇论文的结论很明确:
在显著降低计算成本的同时,LDM 依然能在多个任务上取得非常强的效果。
论文在 CelebA-HQ、FFHQ、LSUN、ImageNet、MS-COCO 等数据集上进行了验证,结果显示:
- 在无条件图像生成上,LDM 在多个数据集上取得了很有竞争力的 FID;
- 在 class-conditional ImageNet 上,带 classifier-free guidance 的 LDM-4-G 达到了很强的表现;
- 在 text-to-image 任务中,1.45B 参数的文本条件 LDM 在 COCO 上已经能和当时非常强的方法同台竞争;
- 在 inpainting 和 super-resolution 上,LDM 也展示了优秀性能,同时比像素空间扩散更高效。
更重要的是,论文反复强调:
LDM 的优势不是单纯提高某一个指标,而是在“性能—算力”之间做到了更好的平衡。
五、为什么这篇论文这么重要?
如果要用一句话概括这篇论文的意义,我觉得可以这么说:
LDM 让扩散模型第一次真正从“效果很好但太贵”走向“效果强、又更可用”。
它的重要性主要体现在三个层面。
第一,它重新定义了扩散模型的工作空间
扩散模型不必死守像素空间,latent space 同样可以成为高质量生成的主战场。
第二,它为后来的大规模生成模型打下了结构基础
尤其是 latent diffusion + cross-attention 这条路线,后来直接影响了主流文生图模型的发展。Stable Diffusion 官方仓库也明确写道,它本身就是一种 latent text-to-image diffusion model。
第三,它启发了很多跨任务、跨模态扩散工作
因为它把“自编码器压缩”“潜空间生成”“条件注入”这三部分拆得很清楚,所以后来很多研究都能沿着这个框架去改造:
可以换 encoder/decoder,可以换条件输入,也可以把 latent diffusion 嵌到恢复、编辑、控制生成等更复杂任务里。
六、这篇论文也不是没有局限
当然,LDM 也不是完美无缺。
论文自己就提到一个很现实的问题:虽然 LDM 比像素空间扩散高效得多,但它依然是顺序采样的生成模型,所以在推理速度上仍然慢于 GAN。另一方面,由于最终图像仍然需要通过 decoder 从 latent 还原回像素空间,因此对于特别强调像素级精确恢复的任务,第一阶段 autoencoder 的重建能力可能会成为瓶颈。
这也说明,LDM 更擅长的是高质量生成与感知质量,而不是所有场景下的“严格像素保真”。
七、总结
High-Resolution Image Synthesis with Latent Diffusion Models 这篇论文提出了 LDM 框架,用“自编码器压缩 + 潜空间扩散 + 条件交叉注意力”三步,把高质量扩散生成从昂贵的像素空间迁移到更高效的 latent space 中,在图像生成、文生图、超分和修复等多个任务上都取得了非常强的效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)