深度学习篇---全局平均池化(Global Average Pooling, GAP)
全局平均池化是深度学习中一个优雅而强大的操作,它通过极简的设计解决了全连接层参数量爆炸的问题,同时增强了模型的泛化能力。
一、什么是全局平均池化?
1. 基本定义
全局平均池化是对每个特征通道的所有空间位置取平均值,将三维特征图 (C, H, W) 压缩为一维向量 (C,)。
数学表达:
对于第 k 个通道:
GAP_k = (1/(H×W)) × Σ_{i=1}^{H} Σ_{j=1}^{W} x_{k,i,j}
示例:
输入特征图: (batch=32, channels=512, height=7, width=7) GAP 后: (batch=32, channels=512)
2. 代码实现
import torch
import torch.nn as nn
# PyTorch 中的 GAP
gap = nn.AdaptiveAvgPool2d(1) # 输出 1x1 的特征图
x = torch.randn(32, 512, 7, 7)
y = gap(x) # (32, 512, 1, 1)
y = y.view(x.size(0), -1) # (32, 512)
# 或者手动实现
def global_avg_pool(x):
return x.mean(dim=[2, 3]) # 对 H 和 W 维度求平均二、GAP 的核心思想
1. 从展平到 GAP 的演进
传统 CNN 结构(如 AlexNet):
卷积层 → 展平 → 全连接层(参数量巨大)→ 分类
GAP 结构(如 ResNet):
卷积层 → GAP → 全连接层(参数量极小)→ 分类
2. GAP 的本质:通道级特征聚合
GAP 假设:每个通道已经学习了某个特定的语义特征(如“猫耳”、“狗鼻子”),取平均值相当于问:“这个特征在整个图像中出现的平均强度是多少?”
# 通道语义示例
通道1: 检测"猫耳" → GAP值 = 0.85(整张图里猫耳特征很强)
通道2: 检测"狗鼻" → GAP值 = 0.12(几乎没有狗鼻子)
通道3: 检测"草地" → GAP值 = 0.67(有草地背景)三、GAP 的关键特点
1. 极大减少参数
| 层类型 | 输入 | 输出 | 参数量 |
|---|---|---|---|
| 展平 + 全连接 | 512×7×7=25088 | 1000类 | 25088×1000≈2500万 |
| GAP + 全连接 | 512 | 1000类 | 512×1000≈51万 |
减少约 98% 的参数!
2. 内置正则化
GAP 强制每个通道对整个图像负责,避免了局部过拟合:
-
展平后的全连接层可能只依赖少数几个位置的特征
-
GAP 迫使网络利用整张图的信息来决策
3. 输入尺寸灵活
GAP 的输出维度与输入尺寸无关,使得网络可以接受任意大小的图像:
# 同样的 GAP 层可以处理不同尺寸的输入
x1 = torch.randn(1, 512, 7, 7) # 小特征图
x2 = torch.randn(1, 512, 14, 14) # 大特征图
gap(x1).shape # (1, 512, 1, 1)
gap(x2).shape # (1, 512, 1, 1) # 输出维度相同!4. 可解释性强
GAP 天然支持类激活图(Class Activation Mapping, CAM):
-
每个通道的权重直接反映了该通道对分类的重要性
-
可以可视化哪些区域对决策贡献最大
# CAM 的简化原理
class_score = Σ(weight_k × GAP_k)
= Σ(weight_k × (1/(H×W)) × Σ_{i,j} feature_k[i,j])
= (1/(H×W)) × Σ_{i,j} (Σ weight_k × feature_k[i,j])
# 括号内就是每个位置的热力图值四、GAP 的变体
1. 全局最大池化(Global Max Pooling)
# 取每个通道的最大值
gap = nn.AdaptiveMaxPool2d(1)| 类型 | 操作 | 特点 | 适用场景 |
|---|---|---|---|
| 平均池化 | 平均值 | 平滑,鲁棒 | 一般分类任务 |
| 最大池化 | 最大值 | 关注最强响应 | 细粒度分类、异常检测 |
2. 广义平均池化(GeM Pooling)
# 可学习的池化参数 p
GeM = ( (1/(H×W)) × Σ x^p )^(1/p)当 p=1 时是平均池化,p=∞ 时是最大池化,通过学习得到最优值。
3. 空间金字塔池化(SPP)
对不同尺度进行池化,捕捉多尺度信息:
# 同时使用 1x1, 2x2, 4x4 的池化
# 输出维度 = 1 + 4 + 16 = 21 个特征五、GAP 的经典应用
1. ResNet 系列
class ResNetBlock:
# ...
def forward(self, x):
x = self.conv_layers(x)
x = self.bn(x)
x = self.relu(x)
# 最后用 GAP 替代展平
x = self.global_avg_pool(x)
x = self.fc(x)
return x2. 弱监督学习
GAP + CAM 可以只用图像级标签实现目标定位:
-
训练分类网络(使用 GAP)
-
提取类别权重
-
生成热力图定位物体
3. 多模态融合
在视频分类中,GAP 可以聚合时空特征:
# 3D CNN 输出 (batch, channels, T, H, W)
x = gap_3d(x) # (batch, channels)六、GAP vs 展平:深度对比
| 维度 | 展平 | GAP |
|---|---|---|
| 输出维度 | C × H × W | C |
| 参数量 | 巨大(全连接层) | 极小 |
| 空间信息 | 保留但打散 | 聚合为全局统计 |
| 过拟合风险 | 高 | 低 |
| 输入灵活性 | 固定尺寸 | 任意尺寸 |
| 可解释性 | 弱 | 强(支持CAM) |
| 计算开销 | 几乎为零 | 极小 |
| 细粒度识别 | 强 | 弱 |
七、mermaid 总结框图
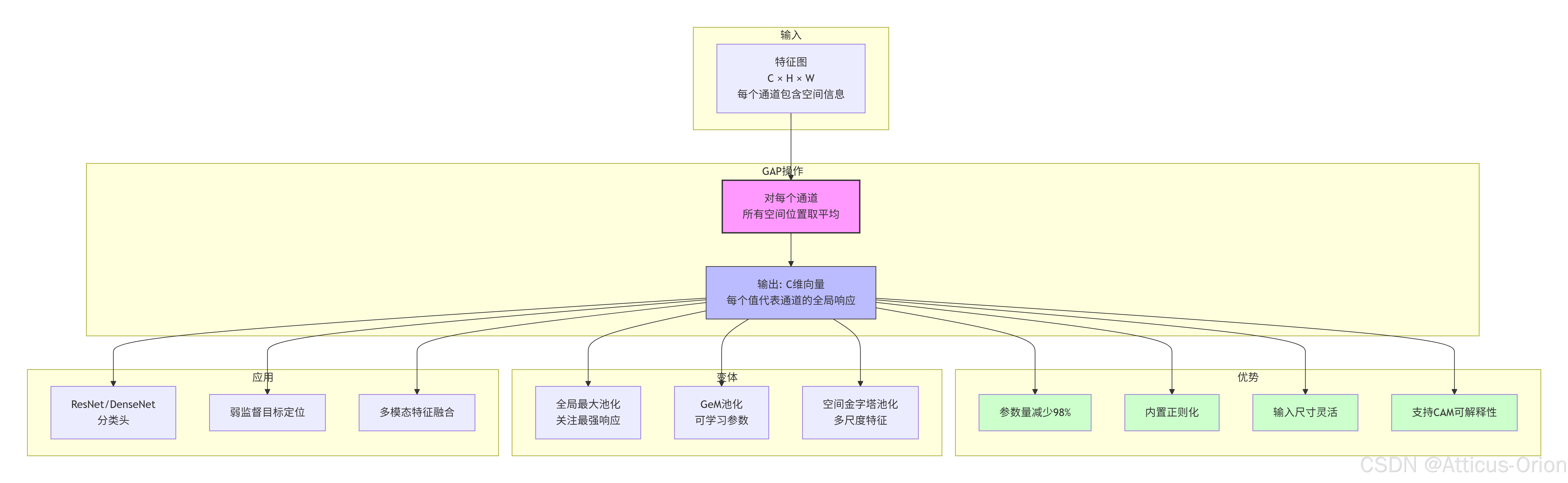
八、何时选择 GAP vs 展平?
选择 GAP 的场景
✅ 图像分类(特别是 ImageNet 等大规模分类任务)
✅ 模型需要轻量化(移动端部署)
✅ 需要可解释性(CAM 可视化)
✅ 输入图像尺寸可变
✅ 训练数据有限(防止过拟合)
选择展平的场景
✅ 需要细粒度特征(如人脸识别、OCR)
✅ 后续接 Transformer 或 RNN(需要序列信息)
✅ 目标检测中的区域提议(需要空间位置)
✅ 数据量充足,模型容量需求大
九、实践建议
1. 现代 CNN 的标准实践
# 典型 ResNet 分类头
class ResNetClassifier(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.features = nn.Sequential(
# ... 卷积层 ...
)
self.gap = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
x = self.features(x)
x = self.gap(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x2. 可学习的池化层
class GeMPooling(nn.Module):
def __init__(self, p=3, eps=1e-6):
super().__init__()
self.p = nn.Parameter(torch.ones(1) * p)
self.eps = eps
def forward(self, x):
return (x.clamp(min=self.eps).pow(self.p)
.mean(dim=[2, 3])
.pow(1.0 / self.p))全局平均池化通过极简的设计实现了参数效率、泛化能力和可解释性的完美平衡,成为现代 CNN 架构(ResNet、DenseNet、MobileNet 等)的标准组件。它不仅解决了传统全连接层的参数爆炸问题,还为深度学习模型的可解释性提供了天然支持。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)