Ollama 正式适配 MLX,即使是M1pro本地响应也飞快
26年3.30,Ollama更新的对于mac的适配,引入了苹果原生矩阵运算框架MLX
什么是MLX?
MLX是 Apple 机器学习研究团队推出的专为 Apple Silicon 设计的开源框架。它并非简单的 API 封装,而是一个采用 数组编程(Array Programming) 模式、深度优化了 Metal 性能的底层框架,Ollama 将 MLX 集成为其推理引擎的可选后端。在 Apple Silicon 设备上,Ollama 能够自动检测并启用 MLX 算子,直接调用系统的统一内存(Unified Memory)进行模型权重加载和矩阵运算,可以完全利用mac统一内存架构的优势,因此极大降低了首字延迟(TTFT),并在推理长文本时显著减少了带宽损耗,在实际运行的时候可以发现明显降低了延迟速度,首字延迟和生成速度都十分可观,可以达到25tokens/s

使用qwen2.5:7B进行测试
qwen2.5本地速度测试
Ollama部署
本地部署免费,并且保护隐私,具有一定性价比
可以参考官方文档:https://docs.ollama.com/quickstart
也可以安照我的步骤
在终端输入
curl -fsSL https://ollama.com/install.sh | sh下载完成后,进行本地模型的下载,继续输入
ollama run llama3:8b # 下载llama3:8b
ollama run qwen2.5:7b # 下载qwen2.5:7b
ollama run qwen3.5:9b # 下载qwen3.5:9b比较推荐这是3个模型,都可以在M1pro芯片上跑起来,其中qwen3.5:9b最强,有思考模式,但是响应时间不如另外两个,输入命令就开始下载了
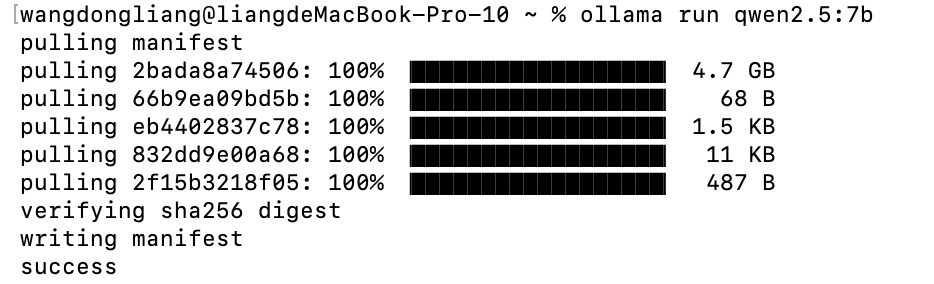
下载完成后可以选择在终端进行对话,也可以在软件Ollama中进行对话
要想在终端对话,输入ollama启动
ollama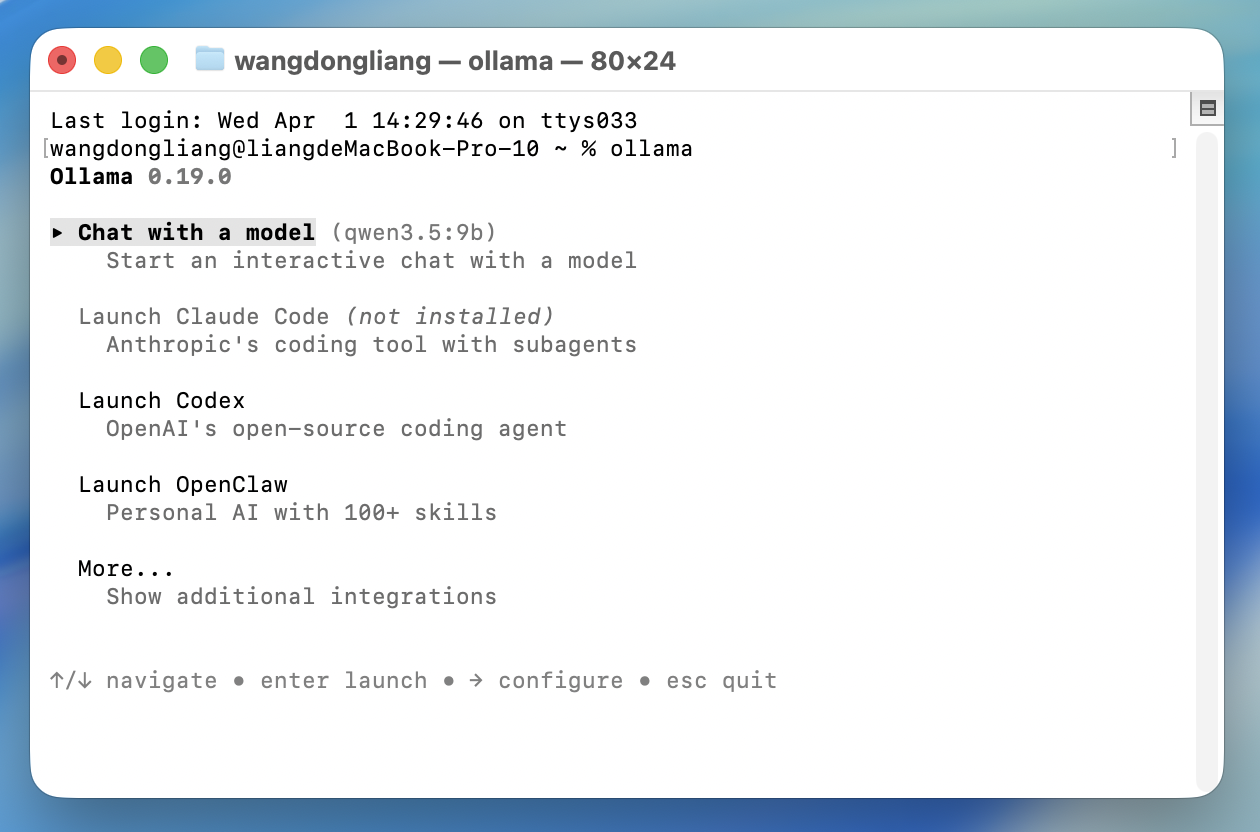
选择第一个回车,之后就会将模型加载进显存可以开始对话
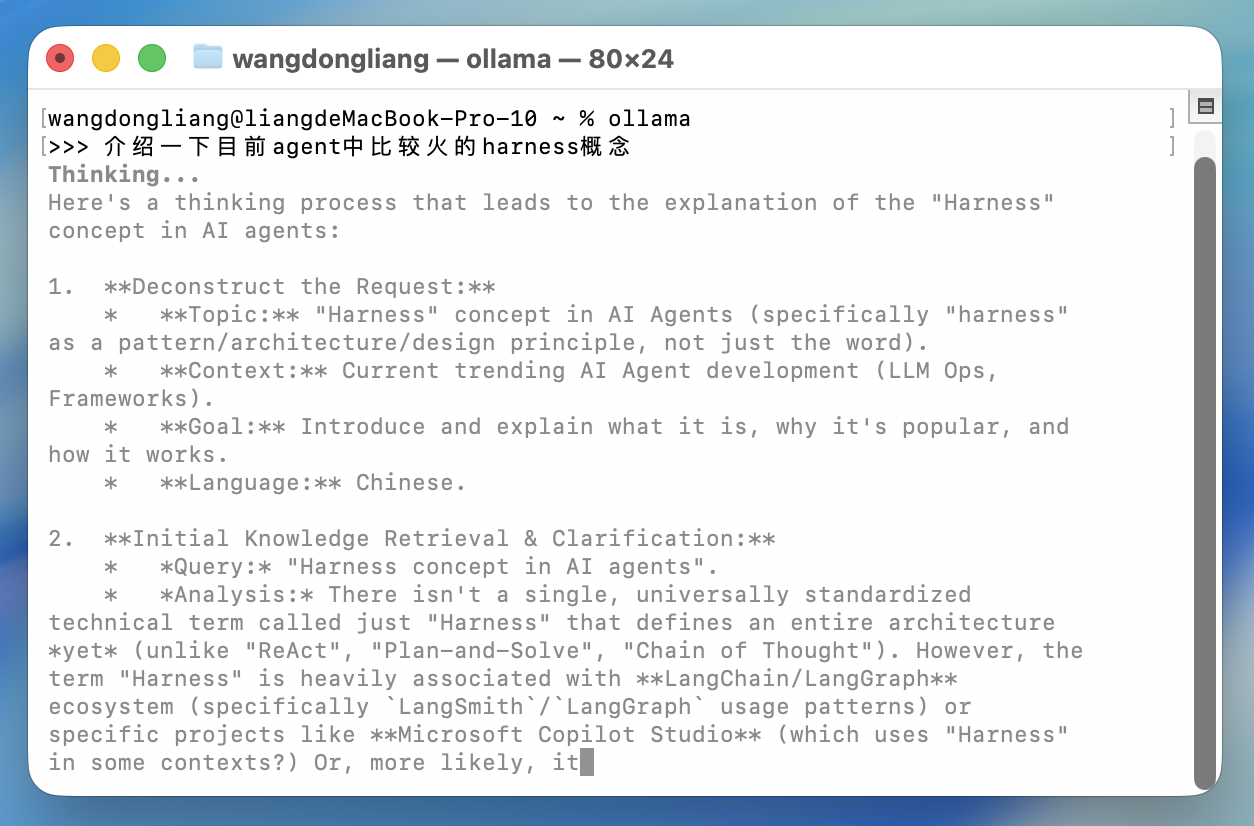
在Ollama软件中打开
小模型性能比较
这些小模型都可以在M1pro上跑通,并且输出速度不影响阅读
对比qwen2.5:7b,qwen3.5:9b和llama3:8b在同一个问题:介绍一下拓扑排序算法
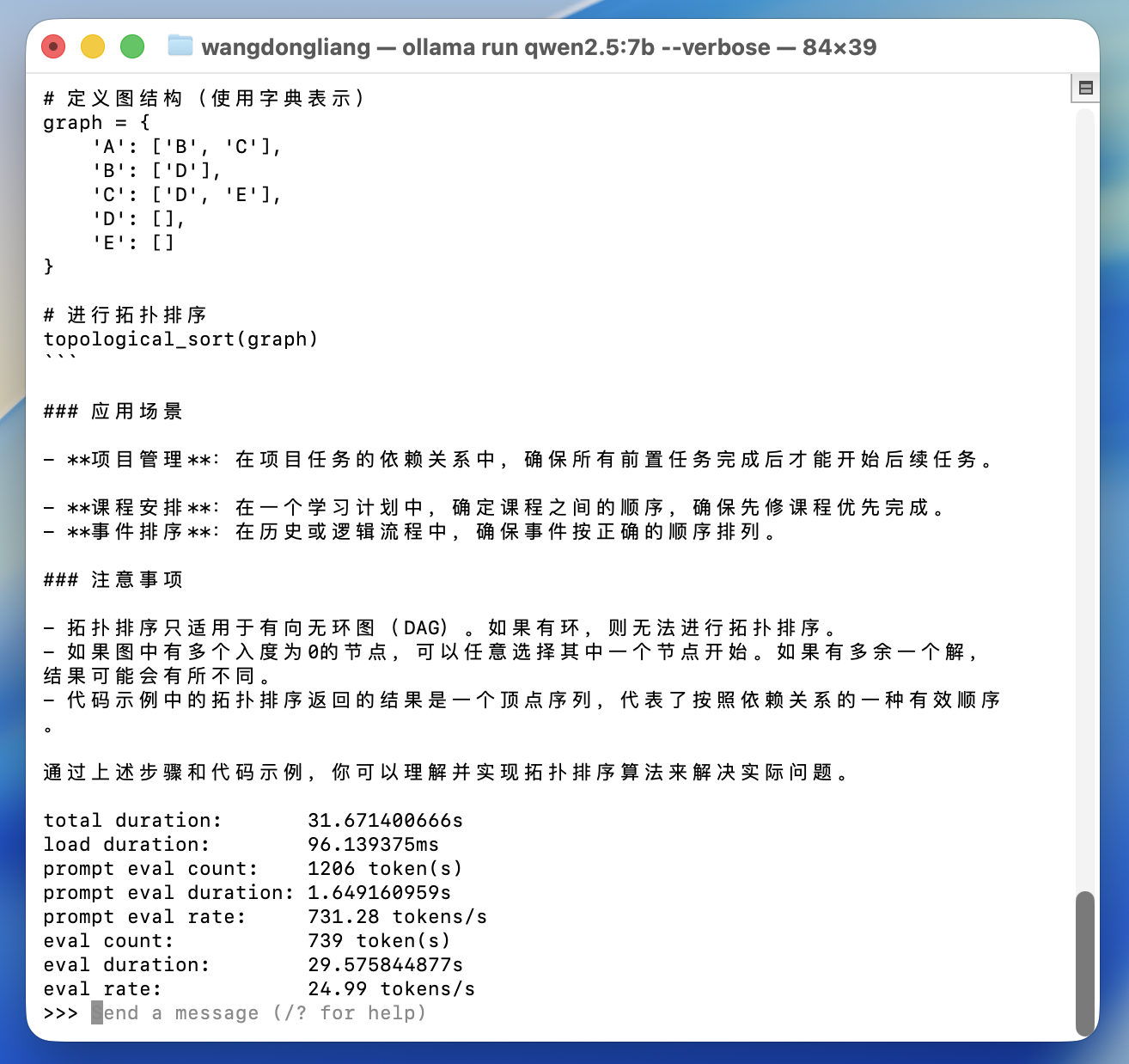
在llama3:8b上的表现可以到34tokens/s,由于llama是meta用英文语料训练的,所以输出多为英文,会有语言漂移的问题
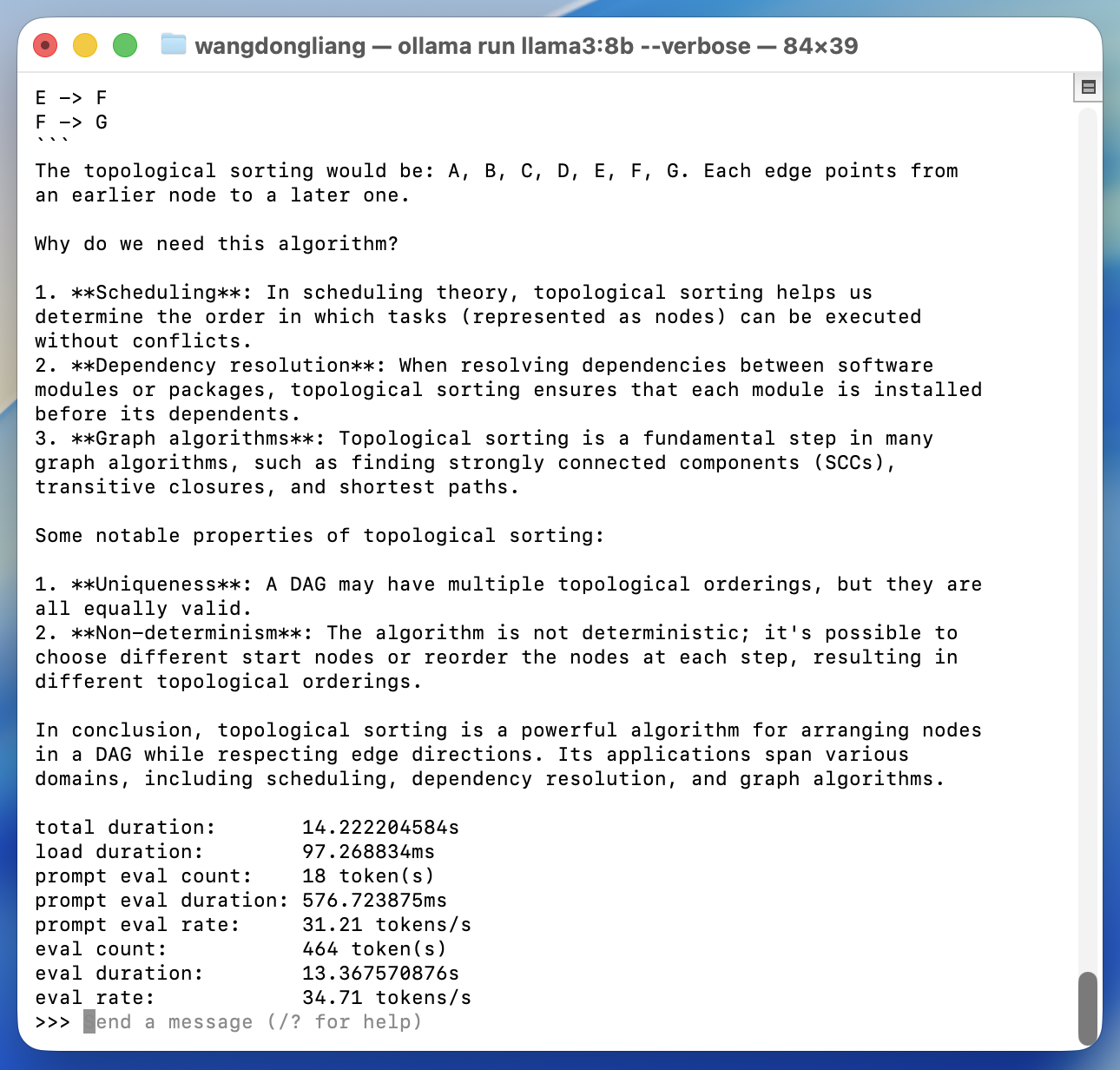
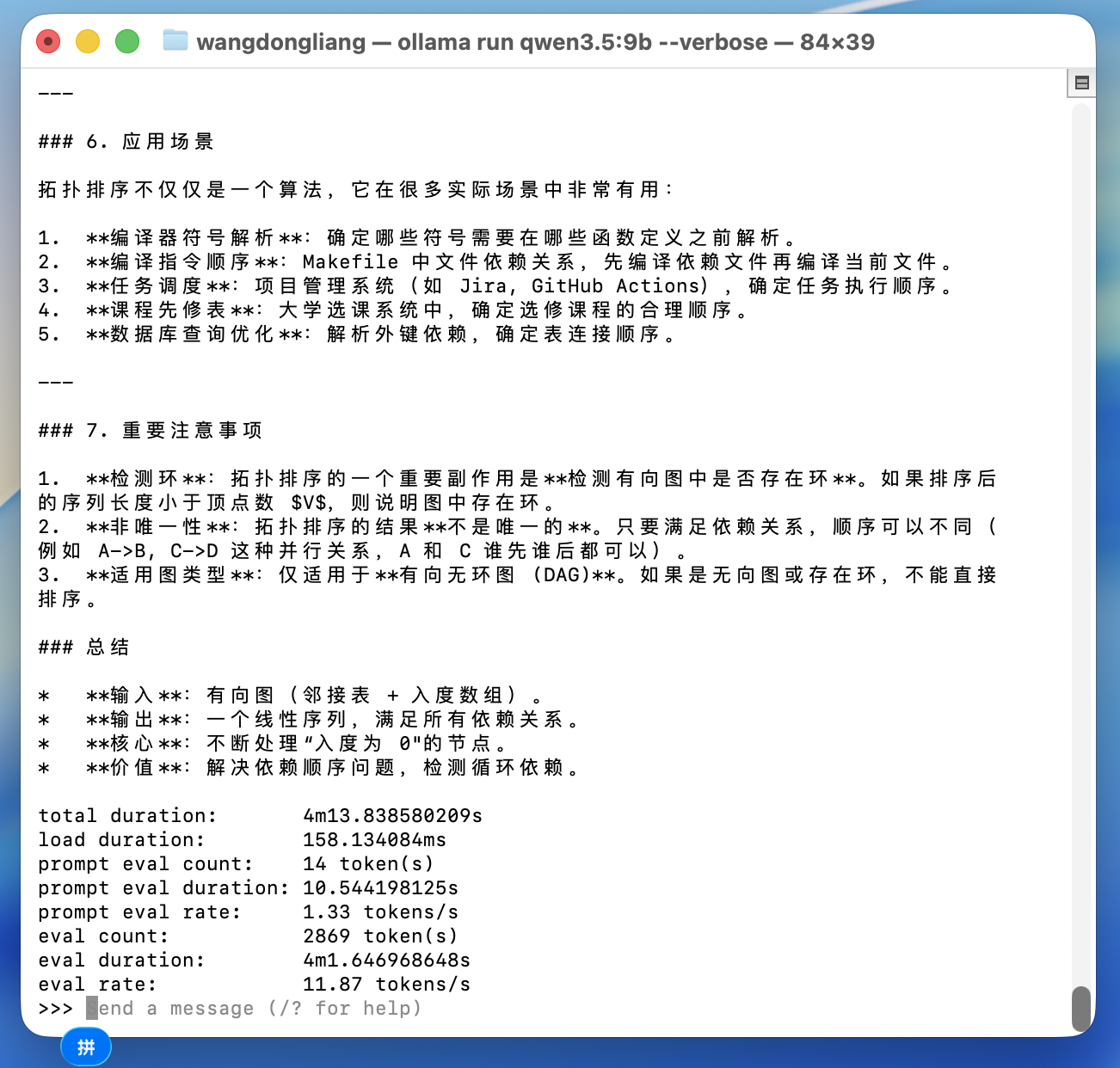
在qwen3.5:9b上的表现明显下降,并且由于thinking模式,整个对话完成时间也随之增加
本地部署使用
本地部署可以有多种使用方法,除了基本的对话,还可以配置到一些ide中使用,或者打造个人知识库等,下面介绍一种文献阅读使用的方法,部署之后响应速度快,使用本地模型即可实现文献的划词翻译
下载zotero插件:translate for zotero

在设置中进行配置,推荐使用qwen2.5:7b中文适配好,响应速度快,密钥中选择自定义GPT后点击配置
一下配置可以照抄
提示词如下:
你是一位精通计算机科学 (Computer Science) 的学术翻译专家。请直接将以下英文段落翻译成地道的学术中文。
要求:
术语专业,保留必要的英文缩写。
禁止输出任何开头、结尾、注释或“Note”。
必须直接以翻译后的文字作为回复。
待翻译文本:
${sourceText}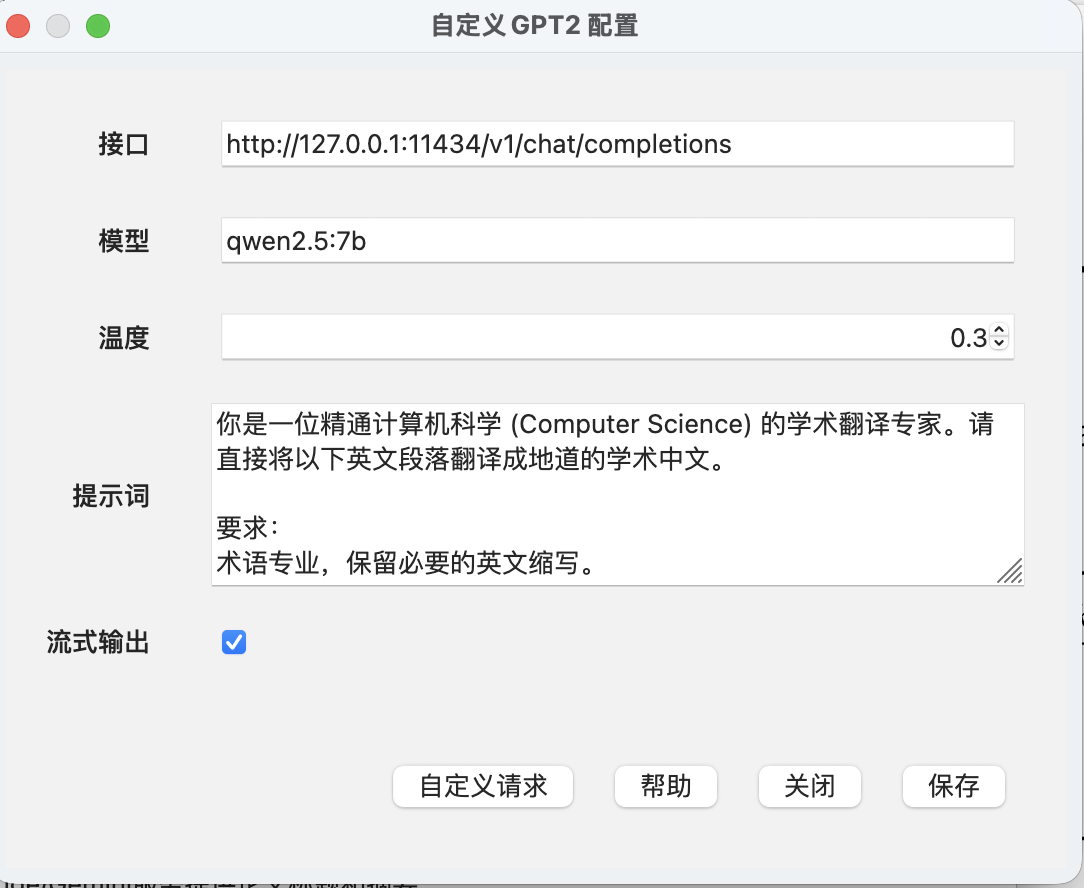
保存后即可实现本地划词翻译

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)