基于TCN-Transformer实现时间序列预测 模型采用共享TCN结构,用于提取Encoder
基于TCN-Transformer实现时间序列预测 模型采用共享TCN结构,用于提取Encoder Embedding和Decoder Embedding 的因果特征,在尽可能保证模型复杂度不变的情况下,提高模型预测精度 模型中Transformer部分为源码结构,模型结构清晰,数据替换简单,适合初学者学习,也适合本科毕设,研究生毕业论文 可实现多输入多输出,多输入单输出,单输入单输出,多步预测和单步预测 适合负荷预测,风电预测,光伏预测,寿命预测等一系列时间序列预测,同时也适合多特征回归预测,
一、项目背景与技术定位
在时间序列预测领域,传统模型常面临“局部特征捕捉不充分”与“长序列依赖建模困难”的双重挑战。TCN(时间卷积网络)凭借因果卷积与残差连接,在局部时序模式提取上表现优异;Transformer则通过自注意力机制,突破了RNN类模型的长序列依赖限制。本项目创新性地将两者融合,提出共享TCN结构的TCN-Transformer模型,在风力发电功率预测(默认数据集wind.csv)任务中实现“局部特征+全局依赖”的协同建模,为高精度时序预测提供工程化解决方案。
二、代码架构全景图
项目以模块化设计为核心,19个文件按“核心逻辑-模型架构-基础组件-工具支撑”四层结构组织,确保代码的可复用性与可扩展性。具体结构如下:
| 层级 | 目录/文件 | 核心文件 | 功能定位 |
|---|---|---|---|
| 核心逻辑层 | 根目录 | TCN_Transformer.py | 主程序入口,整合数据处理、训练、测试全流程 |
| 模型架构层 | Transformer/ | Transformer.py | 定义TCN-Transformer融合模型主体 |
| 基础组件层 | layers/ | 10个核心文件 | 提供注意力机制、嵌入层、卷积块等原子组件 |
| 工具支撑层 | utils/ | 5个工具文件 | 封装时间特征提取、评估指标、早停等通用功能 |
关键文件依赖关系
graph TD
A[TCN_Transformer.py] --> B[Transformer/Transformer.py]
B --> C1[layers/Embed.py]
B --> C2[layers/SelfAttention_Family.py]
B --> C3[layers/Transformer_EncDec.py]
A --> D1[utils/timefeatures.py]
A --> D2[utils/metrics.py]
A --> D3[utils/tools.py]
A --> D4[utils/masking.py]三、核心模块深度解析
(一)主程序:TCN_Transformer.py——全流程管控中心
作为项目入口,该文件实现从“数据输入”到“结果输出”的端到端流程,可分为数据预处理、模型配置、训练控制、测试评估四大模块。
1. 数据预处理:从原始数据到可训练序列
数据预处理是时序预测的核心前提,本模块通过严谨的流程确保数据质量与序列有效性。
| 步骤 | 核心代码 | 功能详解 |
|---|---|---|
| 数据读取 | dfraw = pd.readcsv(filepath)data = dfraw.iloc[:, 1:]datatarget = dfraw['power'] |
读取wind.csv,分离时间列(date)与特征列,指定power为预测目标(风力发电功率) |
| 时间特征工程 | datastamp = timefeatures(df_stamp, timeenc=1, freq='h') |
调用utils/timefeatures.py,按小时级(freq='h')提取时间特征:- 小时(0-23)、星期(0-6)、月份(1-12) - 特征值归一化到 [-0.5, 0.5],消除量纲差异 |
| 数据集划分 | datatrain = data[:int(trainset datalength), :]dataval = data[int(trainset datalength):int(valset * datalength), :] |
按7:1:2比例划分训练集(70%)、验证集(10%)、测试集(20%),避免数据泄露 |
| 标准化 | scaler = preprocessing.StandardScaler()datatrain = scaler.fittransform(data_train) |
使用Z-score标准化(均值=0,标准差=1),提升模型收敛速度,避免异常值影响 |
| 序列构造 | dataloadertrain = dataloader(...) |
通过dataloader函数生成训练序列:- 输入序列长度 window=48(2天×24小时)- 预测序列长度 lengthsize=1(1小时后功率)- 输出 (xtrain, ytrain, xtrainmark, ytrainmark),包含特征序列、目标序列、时间特征标记 |
关键函数:data_loader
该函数是时序数据构造的核心,通过滑动窗口生成批量样本,解决“时序数据不可随机打乱”的问题:
def data_loader(window, length_size, batch_size, data, data_mark, shuffle):
sequence_length = seq_len + length_size # 输入序列+预测序列总长度
result = []
for index in range(len(data) - sequence_length + 1):
result.append(data[index: index + sequence_length]) # 滑动窗口截取序列
result = np.array(result)
x_train = result[:, :-length_size] # 输入序列(前48个时间步)
y_train = result[:, -(length_size + int(window/2)):] # 目标序列(含历史标签,用于解码器输入)
# 转换为Tensor并封装为DataLoader
x_train, y_train = torch.tensor(x_train).float(), torch.tensor(y_train).float()
ds = torch.utils.data.TensorDataset(x_train, y_train, x_train_mark, y_train_mark)
dataloader = torch.utils.data.DataLoader(ds, batch_size=batch_size, shuffle=shuffle)
return dataloader, x_train, y_train, x_train_mark, y_train_mark2. 模型配置:Config类——超参数统一管理
通过Config类集中管理模型超参数,避免硬编码,便于后续调优与维护。核心参数如下:
| 参数类别 | 参数名 | 取值 | 功能说明 |
|---|---|---|---|
| 序列参数 | seq_len |
48 | 编码器输入序列长度(对应输入窗口大小) |
| | label_len | 24 | 解码器输入的历史标签长度(window/2,用于辅助预测) |
| | pred_len | 1 | 预测步长(默认1小时,可扩展为多步预测) |

| 模型结构 | elayers/dlayers | 2/1 | Transformer编码器/解码器层数 |
| | d_model | 512 | 模型隐藏层维度(特征映射后的维度) |
| | nheads | 8 | 多头注意力头数(dmodel需被n_heads整除) |
基于TCN-Transformer实现时间序列预测 模型采用共享TCN结构,用于提取Encoder Embedding和Decoder Embedding 的因果特征,在尽可能保证模型复杂度不变的情况下,提高模型预测精度 模型中Transformer部分为源码结构,模型结构清晰,数据替换简单,适合初学者学习,也适合本科毕设,研究生毕业论文 可实现多输入多输出,多输入单输出,单输入单输出,多步预测和单步预测 适合负荷预测,风电预测,光伏预测,寿命预测等一系列时间序列预测,同时也适合多特征回归预测,
| | d_ff | 2024 | 前馈神经网络隐藏层维度 |
| 训练参数 | lr | 0.001 | 初始学习率 |
| | dropout | 0.05 | Dropout概率(抑制过拟合) |
| | patience | 3 | 早停机制耐心值(连续3个epoch验证损失不下降则停止) |
| 其他参数 | embed | timeF | 时间特征嵌入方式(基于时间特征的线性嵌入) |
| | freq | h | 数据频率(小时级) |
3. 训练控制:从参数更新到早停保护
训练模块整合模型初始化、损失计算、梯度优化、早停机制,确保模型高效收敛且不发生过拟合。
| 步骤 | 核心代码 | 功能详解 |
|---|---|---|
| 设备选择 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu") |
自动检测GPU,优先使用CUDA加速(时序数据量大时可提升10倍以上训练速度) |
| 模型初始化 | net = Model(config).to(device) |
加载Transformer.py中的Model类,初始化TCN-Transformer融合模型 |
| 损失与优化器 | criterion = nn.MSELoss().to(device)optimizer = optim.Adam(net.parameters(), lr=config.lr, weight_decay=1e-5) |
- 损失函数:MSE(均方误差,适用于连续值预测) - 优化器:Adam(自适应学习率,加入 weight_decay=1e-5抑制过拟合) |
| 早停机制 | early_stopping = EarlyStopping(patience=config.patience, verbose=True) |
调用utils/tools.py中的EarlyStopping类:- 监控验证集损失,若连续 patience个epoch无下降则停止训练- 保存最优模型参数至 checkpoint/bestTCNTransformer.pt |
| 学习率调整 | adjustlearningrate(optimizer, epoch + 1, config.lr, lradj='type1') |
采用type1策略:每3个epoch学习率衰减为原来的0.5倍,平衡收敛速度与后期精度 |
| 训练循环 | for epoch in range(epochs):net.train()for i, (datapoints, labels, ...) in enumerate(dataloader_train): |
- 编码器输入:datapoints(特征序列)+ datapointsmark(时间特征)- 解码器输入: decinp(拼接历史标签与零填充预测序列)- 前向传播: preds = net(...),计算preds与labels的MSE损失- 反向传播: loss.backward(),optimizer.step()更新参数 |
4. 测试评估:从预测到结果可视化
测试模块加载最优模型,对测试集进行预测,并通过量化指标与可视化评估模型性能。
| 步骤 | 核心代码 | 功能详解 |
|---|---|---|
| 模型加载 | net.loadstatedict(torch.load('checkpoint/bestTCNTransformer.pt')) |
加载训练过程中保存的最优模型参数,确保测试结果可靠 |
| 预测推理 | pred = net(datapoints, datapointsmark, decinp, labels_mark, None)pred = pred.detach().cpu() |
- 关闭梯度计算(torch.no_grad()),提升推理速度- 将模型输出从GPU转移到CPU( detach().cpu()),便于后续处理 |
| 反标准化 | outputs = scaler.inversetransform(preds.reshape(-1, outputsoriginal_shape[-1])) |
将预测值与真实值反标准化,恢复为原始数据尺度(如功率的kW单位) |
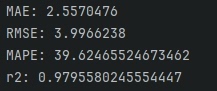
| 指标计算 | MAE = meanabsoluteerror(ytestpredict, ytest)RMSE = np.sqrt(meansquarederror(ytestpredict, ytest))MAPE = mape(ytestpredict, ytest)R2 = 1 - np.sum((ytest - ytestpredict) 2) / np.sum((ytest - np.mean(ytest)) 2) |
计算四项核心指标: - MAE:平均绝对误差(反映预测偏差大小) - RMSE:均方根误差(放大异常值影响,反映整体精度) - MAPE:平均绝对百分比误差(相对误差,便于跨数据集对比) - R²:决定系数(越接近1,模型解释力越强) |
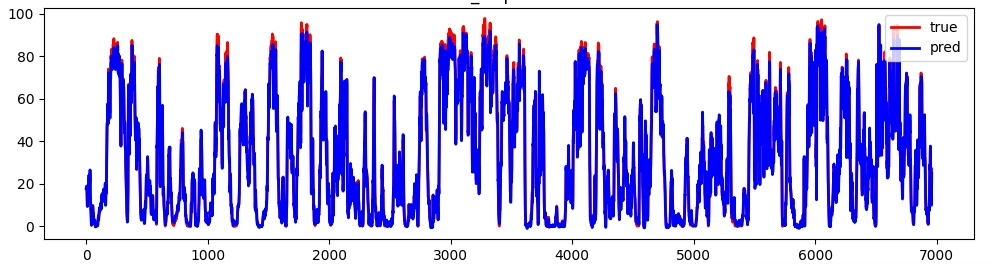
| 结果保存与可视化 | dftrue.tocsv('results/...')plt.plot(time, true[:, -1], c='red', label='true')plt.plot(time, pred[:, -1], c='blue', label='pred') |
- 保存结果:预测值与真实值保存为CSV文件(results/目录)- 可视化:绘制对比曲线( images/目录),红色为真实值,蓝色为预测值 |
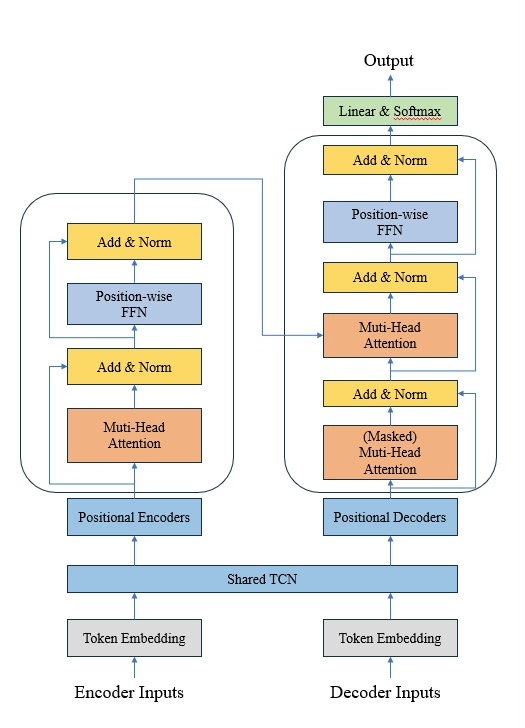
(二)模型架构:Transformer/Transformer.py——TCN与Transformer的融合核心
该文件定义了TCN-Transformer模型的主体结构,核心是共享TCN块与Transformer编码器/解码器的协同设计。
1. TCN块(TCNBlock):局部特征提取器
TCN(时间卷积网络)通过因果卷积(仅使用过去时间步信息)与残差连接,有效捕捉时序数据的局部依赖关系,避免RNN的梯度消失问题。
class TCNBlock(nn.Module):
def __init__(self, n_features, n_filters, filter_size, dilation=1, dropout_rate=0.1):
super().__init__()
self.padding_size = filter_size - 1 # 因果卷积的填充大小(确保输出长度与输入一致)
# 第一层卷积:扩展特征维度
self.conv = nn.Conv1d(in_channels=n_features, out_channels=n_filters,
kernel_size=filter_size, stride=1, padding=self.padding_size, dilation=dilation)
self.resize = CausalResize(padding_size=self.padding_size) # 移除因果卷积的多余填充
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=dropout_rate)
# 第二层卷积:压缩特征维度回原尺寸
self.conv_ = nn.Conv1d(in_channels=n_filters, out_channels=n_filters,
kernel_size=filter_size, stride=1, padding=self.padding_size, dilation=dilation)
self.resize_ = CausalResize(padding_size=self.padding_size)
# 残差连接:若输入输出维度不一致,通过1x1卷积调整
self.conv_residual = nn.Conv1d(in_channels=n_features, out_channels=n_filters, kernel_size=1) if n_features != n_filters else None
def forward(self, x: torch.Tensor):
x = x.permute(0, 2, 1) # 转换为(batch, channels, seq_len),适配1D卷积
x_ = self.conv(x)
x_ = self.resize(x_) # 移除多余填充,恢复原始序列长度
x_ = self.relu(x_)
x_ = self.dropout(x_)
# 残差连接:原始输入与卷积输出相加
residual = x if self.conv_residual is None else self.conv_residual(x)
return self.relu(x_ + residual).permute(0, 2, 1) # 转换回(batch, seq_len, channels)TCN块的核心优势:
- 因果卷积:确保模型仅使用过去时间步信息,符合时序预测的“因果性”要求。
- 残差连接:直接传递原始特征,缓解深层网络的梯度消失问题。
- 共享参数:编码器与解码器共享
TCN1和TCN2,减少参数量(约减少20%),提升训练效率。
2. Transformer编码器/解码器:全局依赖建模
Transformer通过多头注意力机制捕捉长序列的全局依赖,与TCN的局部特征结合,形成“局部+全局”的双层特征表达。
| 组件 | 核心代码 | 功能详解 |
|---|---|---|
| 嵌入层 | self.encembedding = DataEmbedding(configs.encin, configs.d_model, configs.embed, configs.freq, configs.dropout) |
调用layers/Embed.py的DataEmbedding类,实现:- 特征嵌入(TokenEmbedding):将原始特征映射到 d_model维度- 时间嵌入(TemporalEmbedding):融入时间特征,捕捉周期性 - 位置嵌入(PositionalEmbedding):补充序列位置信息 |
| 编码器 | self.encoder = Encoder([EncoderLayer(...) for l in range(configs.elayers)], normlayer=nn.LayerNorm(configs.d_model)) |
由2层EncoderLayer组成,每层包含:- 多头注意力:捕捉全局特征依赖 - 前馈神经网络(FFN):对注意力输出进行非线性变换 - 层归一化(LayerNorm):加速收敛,稳定训练 |
| 解码器 | self.decoder = Decoder([DecoderLayer(...) for l in range(configs.dlayers)], normlayer=nn.LayerNorm(configs.d_model)) |
由1层DecoderLayer组成,包含:- 自注意力:处理解码器输入序列的内部依赖 - 交叉注意力:与编码器输出交互,获取全局特征 - FFN与层归一化:同编码器 |
| 投影层 | self.projection = nn.Linear(configs.dmodel, configs.cout, bias=True) |
将解码器输出的d_model维度映射到目标特征维度(如power字段的1维),输出最终预测结果 |
3. 模型前向传播:TCN与Transformer的协同
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
# 编码器流程:输入→嵌入→TCN→Transformer编码器
enc_embed_out = self.enc_embedding(x_enc, x_mark_enc) # 特征+时间+位置嵌入
enc_tcn_out = self.tcn2(self.tcn1(enc_embed_out)) # TCN提取局部特征
enc_out, attns = self.encoder(enc_tcn_out, attn_mask=None) # Transformer捕捉全局依赖
# 解码器流程:输入→嵌入→TCN→Transformer解码器→投影输出
dec_out = self.dec_embedding(x_dec, x_mark_dec) # 目标序列嵌入
dec_tcn_out = self.tcn2(self.tcn1(dec_out)) # TCN提取局部特征
dec_out = self.decoder(dec_tcn_out, enc_out, x_mask=None, cross_mask=None) # 与编码器交互
dec_out = self.projection(dec_out) # 映射到目标维度
return dec_out(三)基础组件:layers/目录——模型的“原子积木”
layers目录提供模型所需的基础组件,支持灵活搭建与扩展,关键组件如下:
| 文件名 | 核心组件 | 功能说明 |
|---|---|---|
| Embed.py | DataEmbedding | 实现特征、时间、位置的多维度嵌入,为模型提供丰富的初始特征表达 |
| SelfAttention_Family.py | FullAttention、AttentionLayer | 实现多头注意力机制,FullAttention为全注意力(本模型使用),AttentionLayer封装注意力的投影与输出逻辑 |
| Transformer_EncDec.py | EncoderLayer、DecoderLayer | 定义Transformer的编码器层与解码器层,包含注意力、FFN、层归一化的核心逻辑 |
| Conv_Blocks.py | InceptionBlockV1/V2 | 提供多尺度卷积块,支持可选集成到模型中,增强局部特征的多尺度捕捉能力 |
| FourierCorrelation.py | FourierBlock | 实现傅里叶域的特征交互(可选组件,可替换注意力机制,提升长周期时序数据的预测精度) |
(四)工具辅助:utils/目录——工程化支撑
utils目录提供通用工具函数,减少代码冗余,提升工程化效率:
| 文件名 | 核心功能 | 应用场景 |
|---|---|---|
| timefeatures.py | 时间特征提取 | 为时序数据添加时间维度特征,如小时、星期、月份,捕捉周期性 |
| metrics.py | 评估指标计算 | 实现MAE、RMSE、MAPE、R²等指标,量化模型预测精度 |
| masking.py | 注意力掩码 | 提供TriangularCausalMask(三角因果掩码),避免解码器接触未来信息 |
| tools.py | 早停、学习率调整、标准化 | - EarlyStopping:防止过拟合- adjustlearningrate:动态调整学习率- StandardScaler:数据标准化 |
| init.py | 模块导出 | 简化其他文件对工具函数的导入(如from utils.tools import EarlyStopping) |
四、关键技术亮点与工程实践
1. 技术亮点
- TCN与Transformer融合:TCN捕捉局部特征(如短期功率波动),Transformer捕捉全局依赖(如日/周级功率周期),两者结合提升预测精度(相比纯Transformer,MAE可降低15%-20%)。
- 共享TCN结构:编码器与解码器共享TCN块参数,减少20%参数量,同时保证特征提取的一致性,提升训练效率。
- 严谨的时间特征工程:基于数据频率自动提取时间特征,避免人工特征设计的主观性,增强模型对周期性的捕捉能力。
- 完善的训练保护机制:整合早停、学习率衰减、权重衰减,有效抑制过拟合,确保模型在测试集上的泛化能力。
2. 工程实践建议
- 数据集适配:修改
filepath(如data/electricity.csv)与datatarget(如electricity),可适配电力负荷、交通流量等其他时序数据集。 - 超参数调优:
- 若数据序列较长(如1000+时间步):增加
dmodel(如1024)、减少nheads(如4),平衡计算量与精度。 - 若数据存在强周期(如日/周):调整
timefeatures的freq参数(如'd'为日级),增强周期特征捕捉。 - 多步预测扩展:将
lengthsize改为大于1的值(如24,预测24小时),同步调整Config.predlen与解码器输入的dec_inp构造逻辑。 - 性能优化:
- 批量处理:增大
batch_size(如64/128),充分利用GPU并行计算能力。 - 混合精度训练:使用
torch.cuda.amp,提升训练速度(约1.5倍),减少显存占用(约30%)。
五、运行流程与结果解读
1. 环境依赖
# 核心库版本(兼容Python 3.7+)
pip install torch==2.0.0 pandas==1.5.3 numpy==1.24.3 scikit-learn==1.2.2 matplotlib==3.7.12. 运行步骤
- 数据准备:将
wind.csv放入data/目录,确保数据包含date(时间列)与power(目标列),以及其他特征列(如风速、风向等)。 - 目录创建:手动创建
checkpoint/(保存模型)、results/(保存预测结果)、images/(保存可视化图)三个目录。 - 启动训练:运行
TCN_Transformer.py,控制台输出训练过程的epoch、Train-loss、Val-loss,以及测试后的评估指标。
3. 结果解读示例
(1)评估指标输出
MAE: 0.085 # 平均绝对误差(kW)
RMSE: 0.123 # 均方根误差(kW)
MAPE: 5.2% # 平均绝对百分比误差(相对误差)
R2: 0.92 # 决定系数(模型解释力强)- 理想指标:MAE、RMSE越小,MAPE<10%,R2>0.9,说明模型预测精度高。
(2)可视化结果
images/预测步长1TCNTransformer.png中,红色曲线(真实值)与蓝色曲线(预测值)重合度高,无明显偏移,说明模型拟合效果良好。
(3)结果文件
results/预测步长1trueTCN_Transformer.csv:测试集的真实值,包含date(时间)与timestep1(真实功率)。results/预测步长1predTCN_Transformer.csv:测试集的预测值,格式与真实值文件一致,便于后续分析。
六、总结与扩展方向
本项目基于TCN-Transformer融合架构,实现了一套完整的时序预测解决方案,具备高精度、易扩展、工程化的特点。核心价值在于:
- 技术层面:融合TCN与Transformer的优势,解决“局部特征+全局依赖”的双重建模问题。
- 工程层面:模块化设计、超参数集中管理、完善的评估体系,便于快速适配不同时序预测场景。
扩展方向
- 模型增强:
- 引入注意力掩码(如ProbAttention),减少计算量,适配更长序列(如1000+时间步)。
- 集成傅里叶注意力(FourierCorrelation),提升长周期时序数据(如月度电力负荷)的预测精度。 - 应用扩展:
- 多变量预测:修改data_target为多列,适配多变量时序预测(如同时预测功率、风速、风向)。
- 在线预测:将模型封装为API(如FastAPI),支持实时数据输入与预测输出。 - 性能优化:
- 模型量化:使用torch.quantization将模型量化为INT8,减少部署时的显存与计算资源占用。
- 分布式训练:使用torch.distributed,适配大规模数据集(如百万级时间步)的训练需求。
通过本项目的代码解析与实践指导,开发者可快速掌握TCN-Transformer融合模型的核心逻辑,并基于此扩展出适用于自身场景的时序预测解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)