RAG 工作机制详解——一个高质量知识库背后的技术全流程
你是否想做一个靠谱的客服或者是搭建一个能回答问题的知识库?那就一定绕不开一个技术: RAG,它的全称是 Retrieval Augmented Generation,翻译过来就是检索增强生成。听起来挺高大上,但说白了也就这么两件事:先从资料库里检索相关的内容;再基于这些内容来生成答案。也就是说它先检索再生成,所以叫做检索增强生成。RAG 是目前最常用的 AI 问答方案之一,很多企业内的知识助手、智能客服用的都是这项技术。”

“在本篇文章里,我将会为你介绍 RAG 的实现原理,主要包括以下三个部分:首先,我们将总体看一下 RAG 的使用场景和大致链路,让你对这门技术有个感性的了解;然后,我们会逐步拆解这链路里面的每一个环节,深入理解它的原理;最后,我们会从提问前和提问后两个角度出发,复习一下整个链路的运行过程,加深你的理解。在这个过程里面,我还会解释一下 RAG 用到的各种专业名词,比如说是向量、Embedding 模型、向量数据库、向量相似度等等。相信在看完这个视频之后,你就会明白一个高质量的智能客服或者是知识库是如何构建的。”
“假设你想做一个智能客服,这个智能客服可以回答各种关于你们公司产品的问题,应该怎么实现它?首先,这个客服的内部一定要有个模型,比如说是 GPT、Davinci、DeepSeek 这种的。不过光有个模型可不够,因为模型可不知道你们公司的产品信息。你想这个问题好办,在给模型发送问题的时候,把产品手册一起发给模型不就好了?没错,这确实是一个解决方案。不过如果产品手册的字数特别多,比如有个上百页乃至上千页,这就会带来很多问题。”
画面切换:深灰色背景列出 “产品手册太长所带来的问题”:
- 模型无法读取所有内容(因上下文窗口大小限制,读了后面忘了前面);
- 模型推理成本高(输入越多成本越高);
- 模型推理慢(输入越多消化越久)
“看来直接把文档丢给模型是行不通的,那我们是不是可以考虑只把文档中相关的内容发给模型?可以的,这就需要 RAG 登场了。我们一起来看看 RAG 是如何解决这个问题的。”
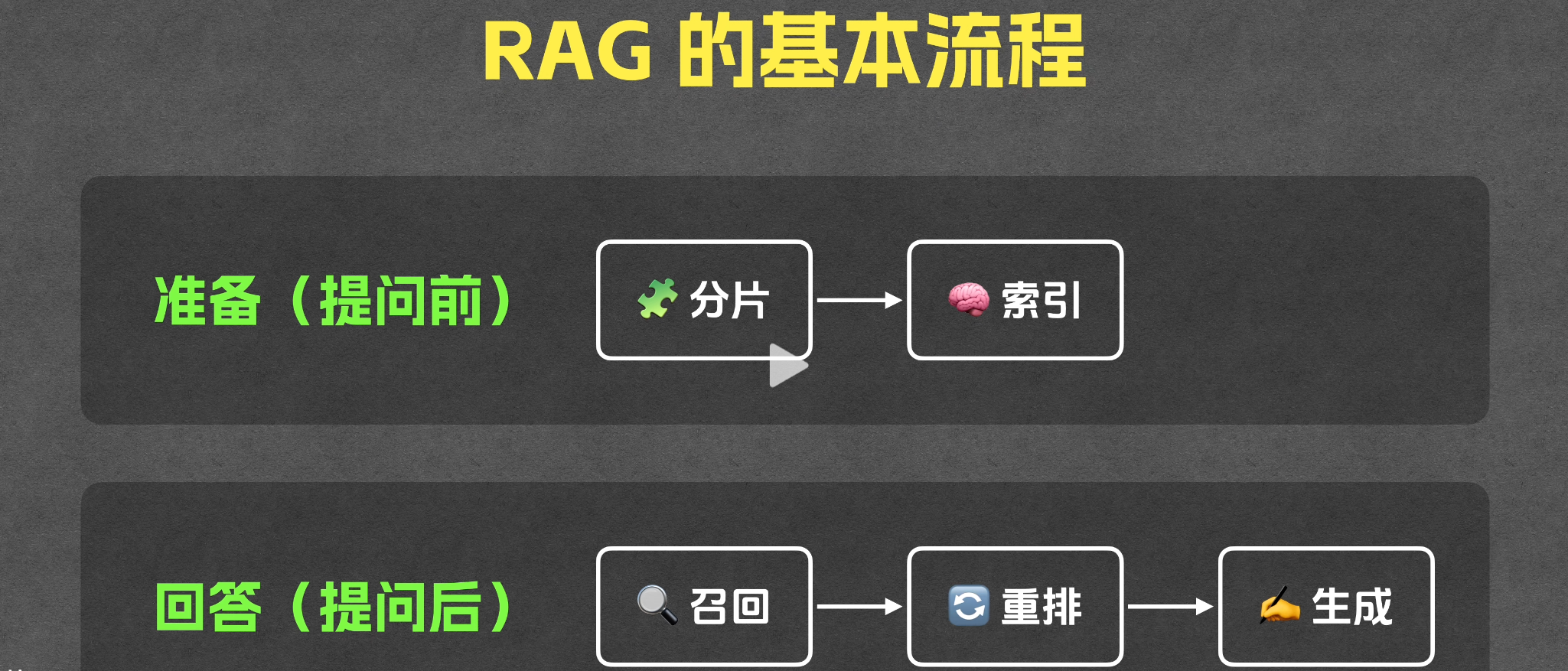
“通常来说,RAG 的整体流程包含两个部分,一个是数据准备部分,这个发生在用户提问前,我们要在这一部分里把相关的文档都给准备好,并完成相应的预处理,它一共是包含分片和索引两个环节。另外一个是回答部分,这一部分当然是发生在用户提问之后了。在用户问完问题之后,我们便会触发回答问题的各个环节,分别是召回、重排和生成。接下来我们就逐步拆解分片、索引、召回、重排和生成这五个环节,看看它们分别是如何工作的。”
环节 1:分片(准备部分)
- 旁白:“分片,顾名思义,就是把文档切分成多个片段。分片的方式有很多种,我们可以按照字数来分,比如说一千个字一个片段。按照段落来分,比如说是一个段落一个片段。或者是按照章节分,按照页码分。除此之外,还有很多的切分方式,但不管怎么做,我们最后都需要把一篇文档切分为多份。切好后这个环节就结束了,然后我们就要进入到下一个环节。”

环节 2:索引(准备部分)
- 旁白:“索引,就是通过 Embedding 将每一个片段文本转化为向量,然后再将片段文本和对应向量都存储在向量数据库的一个过程。没错,它一共就只有这两步,但这两个步骤所包含的信息量其实是巨大的。比如什么是 Embedding?什么是向量?可能什么是向量你也记不清楚了。别急,我们先把这三个概念解释清楚,然后再回来看看索引这个流程,相信你就会清楚很多。”
- 子概念 1:向量
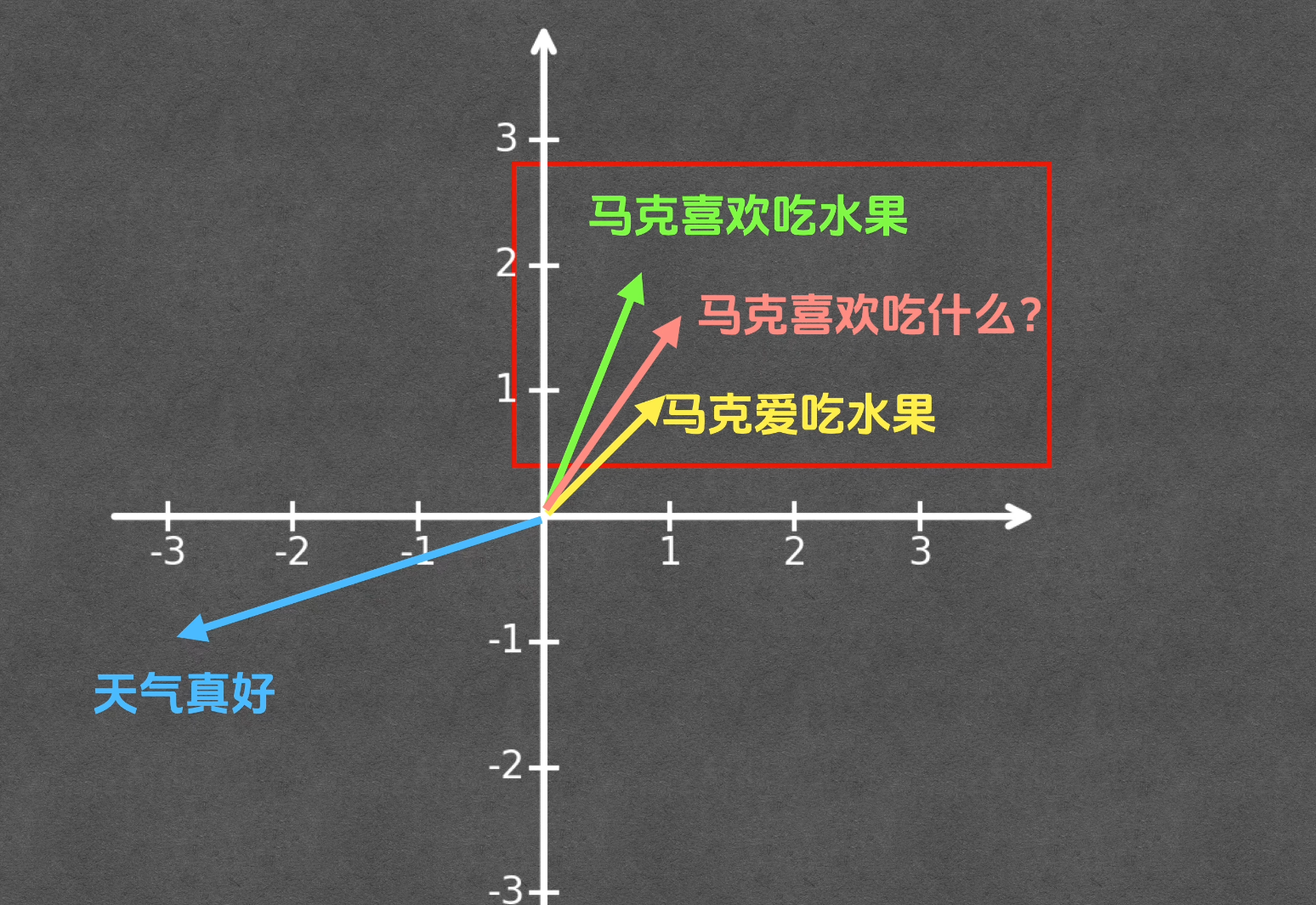
“首先,我们来讲讲这其中最基础的向量。向量是数学里面的一个概念,相信大家多多少少都学过。从概念上来讲,它代表一个有大小、有方向的量。在通常情况下,我们可以用一个数组来表示它,每个向量都有维度,维度的大小就等于数组中数字的个数。比如这些都是一维向量,这些都是二维向量,而这些都是三维向量等等。对于低维度的向量,我们可以直接把它们在坐标轴里面画出来。比如最简单的一维向量,我们可以把它放置在一个一维坐标轴上,[1] 这个向量可以这么画,它的大小是 1,方向朝右。[-3] 这个向量可以这么画,它的大小是 3,方向朝左。要表示二维向量,我们就必须使用一个二维坐标轴,比如说 [2, 2] 可以放在这个地方,[-1, 2] 可以放在这里。同理,三维向量需要放在一个三维的坐标轴里。当然维度再大一点,我就没办法给你演示它在坐标轴里面的位置了,毕竟我们生活在一个三维世界里。但无法可视化并不代表就不存在,实际上我们在 RAG 里面用到的向量维度通常情况下都会比较大,比如是几百甚至几千。一般来说,维度越大,每个向量所包含的信息也就会越丰富,用这些向量做各种工作的可靠性也就越强。”
子概念 2:Embedding
讲完了向量,再来看看 Embedding。Embedding 就是把文本转换为向量的一个过程。比如我们以二维向量为例,假设‘马克喜欢吃水果’对应的向量是 [1, 2],‘,马克爱吃水果’对应的向量是 [1, 1],‘天气真好’对应的向量是 [-3, -1]。你会发现前两个句子的向量非常接近,而‘天气真好’则距离比较远,这说明前两个句子的语义是相近的,而后者则完全不相关。这正是 Embedding 的目的:含义相近的文本在经历了 Embedding 之后,它们对应的向量也是相近的。因为这样的话,当用户询问‘马克喜欢吃什么’的时候,我们就可以先把这个问题做个 Embedding,将其转换为向量,然后再根据向量相似度把与这个问题相关的文本也找出来,最后我们就可以把这两个相关文本以及用户的问题一起扔给大模型,大模型就可以告诉我们马克喜欢吃水果了。Embedding 这个操作是模型来完成的,不过这个模型可不是我们通常所使用的 GPT、DeepSeek 这样的模型,而是专门的 Embedding 模型。如果你想知道哪些 Embedding 模型最好用,可以看一下 MTEB 排行榜,它会对各种 Embedding 模型做评测并且把结果做个排行,方便我们挑选和使用。”
子概念 3:向量数据库
“聊完了 Embedding 的概念,我们再来看看向量数据库。向量数据库就是用来存储和查询向量的数据库,它为存储向量做了很多优化,并且还提供了计算向量相似度等相关的函数,方便我们使用。Embedding 后的向量就可以放在向量数据库里面,方便后续查询。比如我们还是以‘马克喜欢吃水果’这句话为例,在我们给这句话做了 Embedding 之后,就得到了一个向量,然后我们需要把这个向量存入到向量数据库中。不过注意,我们要存的不仅仅有向量,还有原始的文本,所以原始文本也要发给向量数据库。因为只有这样,我们才能在通过向量相似度查询出相似的向量之后,把对应的原始文本也抽取出来发给到模型,让它处理。我们最终需要的还是原始的文本,向量只是一个中间结果,所以一般的向量数据库表格里面至少都会有原始文本和向量两列内容。
回到 “索引” 环节
- 讲完了向量、Embedding 和向量数据库,我们再回头看看我们之前提到过的索引这个概念。索引就是通过 Embedding 将每个片段文本转换为向量并且把片段文本和对应的向量都存储在向量数据库的过程。这句话的意思想必大家都有个概念了,其实就是我们刚才聊的这个过程。只不过我们要把一开始的这个文本换成每一个片段的内容。比如我们一开始要处理的是片段 1,片段 1 处理完了之后,我们要处理片段 2,以此类推,直到所有的片段都处理完毕,这整个所有的流程就都结束了。不管是分片还是索引,它们都发生在用户提问之前,属于要提前准备的步骤。”
环节 3:召回(回答部分)
- 下面我们就来看看用户提问之后发生了什么。首先是召回,召回就是搜索与用户问题相关片段的过程。这个环节从用户问题开始,首先用户的问题会发给 Embedding 模型,Embedding 模型会将它转化为向量,然后我们把它发送给向量数据库,让它查询与用户问题最为相关的十个片段内容。没错,召回的结果就是十个与用户问题相关的片段。当然,10 这个数字并不是固定的,你也可以选择 15、20 等等。具体是多少,不是很重要,只要数量不是很多都可以。不管是多少,向量数据库都要返回与用户问题最相似的一批片段。那向量数据库是怎么知道哪些片段与用户问题最相关的?这就要计算向量相似度了。我来给大家模拟下整个过程,这个是向量数据库里面的数据,为了方便演示,我这里只写了三条。然后我们把用户的问题和对应的向量也放在这里。我们最后要计算下每个片段与用户问题的向量相似度,因此我们先把向量相似度的表头写在这里。然后我们剩下的任务就是把片段向量和用户问题向量分别代入到一个相似度计算公式中,得出向量相似度。这个计算公式的第一个参数永远是用户问题所对应的向量,因此我们先把第一个参数放进来。这个公式的第二个参数则是每个片段的向量了。首先我们把第一个片段向量带进来,算出一个数字,我们把这个数字放入到向量相似度这一栏中。然后我们再把第二个片段的向量带入进来,算出第二个片段与用户问题的相似度,然后同样的我们也把计算结果放入到向量相似度这一栏中。以此类推,我们再算出第三个片段与用户问题的相似度。我们需要按照这个方法把所有的片段都计算完毕,在都计算完毕了之后,我们就把这个向量相似度排个序,取前十个最大的就好了。”
向量相似度计算方
-
- 余弦相似度:计算两个向量夹角的 cos 值,夹角越小相似度越高;
- 欧氏距离:计算两个向量的距离,距离越小相似度越高;
- 点积:通过代数方式衡量相似度,考虑向量方向和长度,乘积越大相似度越高。
环节 4:重排(回答部分)
- 旁白:“重排,全称是重新排序,它做的事情其实跟召回是一样的。前面我们说过,召回是从所有的片段里面挑 10 份与用户问题最相似的,而重排则是从召回的这 10 份里面再挑 3 份与用户问题最相似的作为重排的结果。你可能会想,那直接在召回阶段挑 3 个不就好了,这样就不用重排了,同样的事情搞两遍干什么?一次挑出 3 个当然是可以的,不过这样做的效果没有召回加重排的方案好。为什么?因为召回与重排阶段使用的文本相似度计算逻辑不一样。下面我们来比较一下。首先看一下召回,召回阶段使用的是向量相似度,我们还列举了三个常见的向量相似度计算方法,但无论是使用哪一种方法,它们的特点都是成本低、耗时短、准确率低,所以适合做初步的筛选,也就是在短时间内把上千条片段的相似度数都计算出来,从中挑出十个最高的。而重排就不是了,重排阶段一般是使用一种叫做 Cross-Encoder 的模型计算每个片段与用户问题的相似度,相比之下,Cross-Encoder 的成本会比较高,耗时也会比较长。那为什么用它?因为 Cross-Encoder 的准确率会高很多,所以它很适合做精挑细选。你可以把它类比成公司筛选人才,众所周知,公司面试一共是分为两个环节,简历筛选加面试。召回就跟简历筛选有点像,候选人太多,公司只能用一些粗略的方法从成千上万份简历里面挑出十个看起来最优秀的,准确率可能会大打折扣,但这也是没有办法的事情。而重排就跟面试很像了,公司对这十个人进行面试,仔细挑选,尽可能的保证判断正确,从中挑出最优秀的三个人入职。”
环节 5:生成(回答部分)
- 画面:深灰色背景大字 “生成”→展示流程:用户问题 + 重排后的 3 个相关片段→发给大模型→大模型生成答案。
- 旁白:“重排就讲到这里,下面我们进入到生成阶段,生成什么?当然是生成答案了。现在我们有了用户问题,也有与用户问题相关的三个片段,我们就可以把这两部分一起发给大模型,让它根据片段内容来回答用户问题,到此整个流程就结束了。”
RAG 整体流程串
-
- 准备部分:文档→分片→各片段经 Embedding 模型转向量→向量及对应文本存入向量数据库;
- 回答部分:用户问题→Embedding 模型转向量→向量数据库召回 Top-10 片段→Cross-Encoder 模型重排选出 Top-3 片段→问题 + Top-3 片段发给大模型→大模型生成答案。“这个流程里面的所有环节我们都讲完了,下面我们把所有的流程给串联一下,整体讲一遍。整个流程分为两个部分,一个是准备部分,它发生在提问前,包括分片和索引两个环节。一个是回答部分,发生在提问后,包括召回、重排和生成三个环节。由于整个流程分为两个部分,所以我们的整体流程也会有两个。首先看提问前的准备部分,首先我们把相关的资料做个分片,然后把所有的片段都扔给 Embedding 模型,让它给每个片段都产出一个对应的向量,最后我们把向量存入到向量数据库中,到这里提问前的准备流程就结束了,这就相当于我们的知识库构建已经完毕,就等用户来用了。再来看看用户提问之后发生了什么?首先用户的问题会给到 Embedding 模型,Embedding 模型会把用户的问题转换为一个向量,然后我们会把这个向量传给向量数据库,让它给我们找到十个与用户问题最相近的片段。找到之后我们再把这十个片段送给 Cross-Encoder 模型,让它做个重排,从十个里面再筛选出三个相关程度最高的。然后我们把这三个与用户问题相关程度最高的片段外加用户的问题一起发给大模型,大模型就可以给我们产出最终答案了,到这里所有的流程就算是结束了。”
- “今天的文章就到此结束了,别忘了点赞关注,我们下次再见,拜拜!”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)