深度学习第四版
⚪非线性激活函数它在深度学习里到底具体干什么,线性层负责混合特征,激活函数负责让这种混合变成有条件的、非线性的处理。
你前面问“具体功能是什么”,可以归纳成这几个。
第一,打破线性限制
这是最核心的。
没有它,多层网络等于单层线性模型。
第二,做特征筛选
ReLU 会把负值直接压成 0。
这相当于在说:
-
这个特征当前不重要,关掉
-
那个特征当前有响应,保留
所以它像一个简单的门控器。
第三,让网络能表达“条件关系”
比如你可以粗略理解成:
-
某些边缘特征够强,才继续往后传
-
某些纹理特征不够强,就被压掉
所以不是所有特征都一视同仁,而是看输入决定谁激活。
第四,形成复杂决策边界
分类问题很多不是一条直线能分开的。
有了激活函数,网络可以拼出弯曲、折线状、更复杂的边界。

⚪XOR 异或问题;XOR 是 exclusive OR,中文叫 异或。
规则是:
- 两个输入 不同 → 输出 1
- 两个输入 相同 → 输出 0
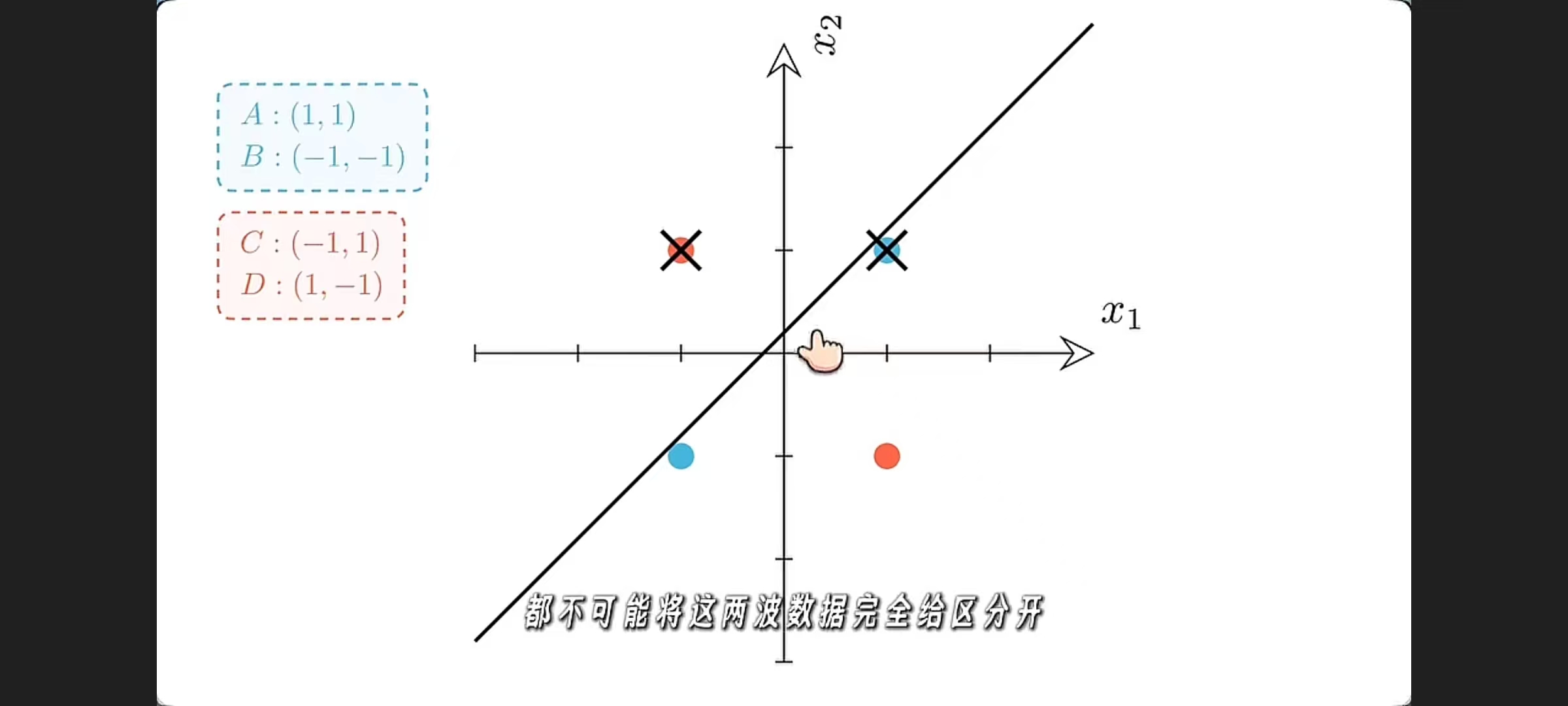
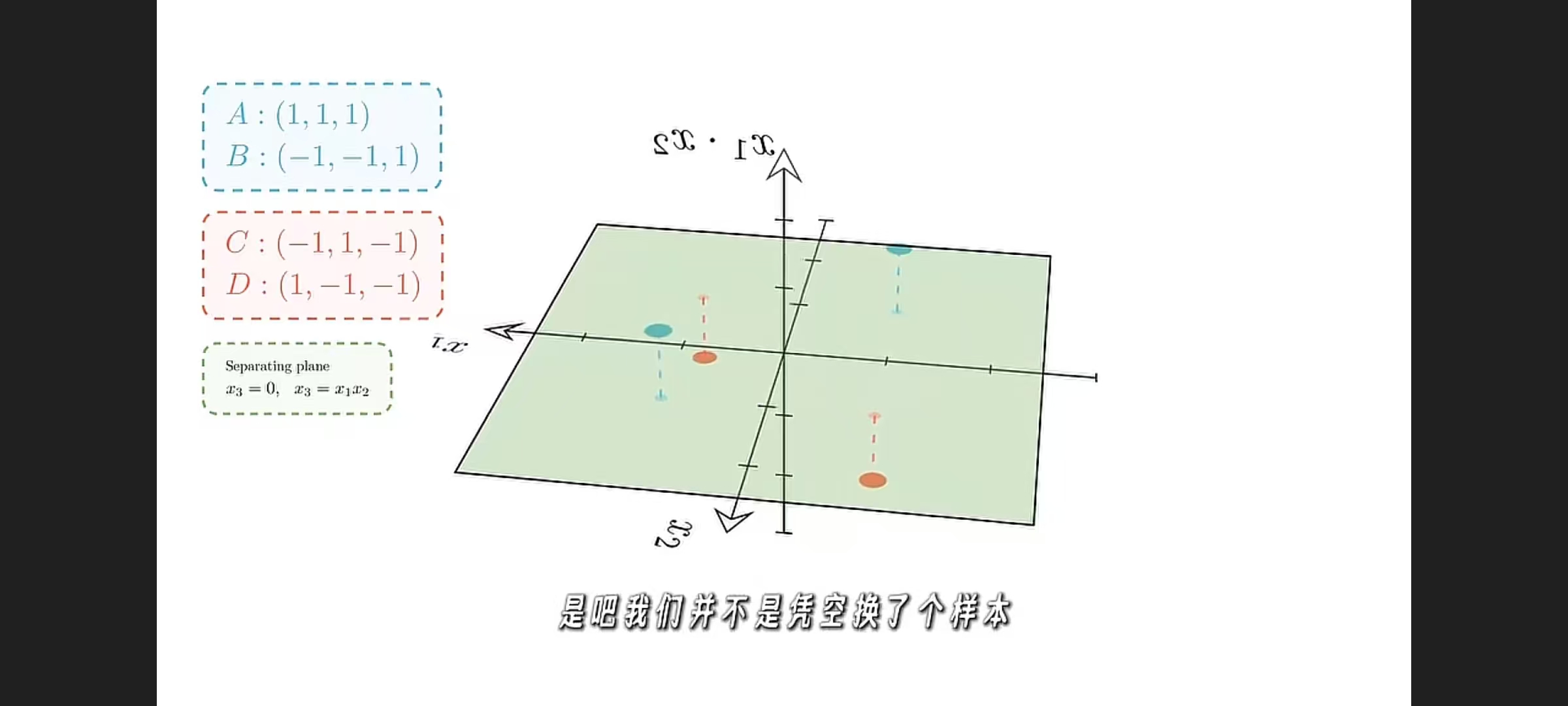
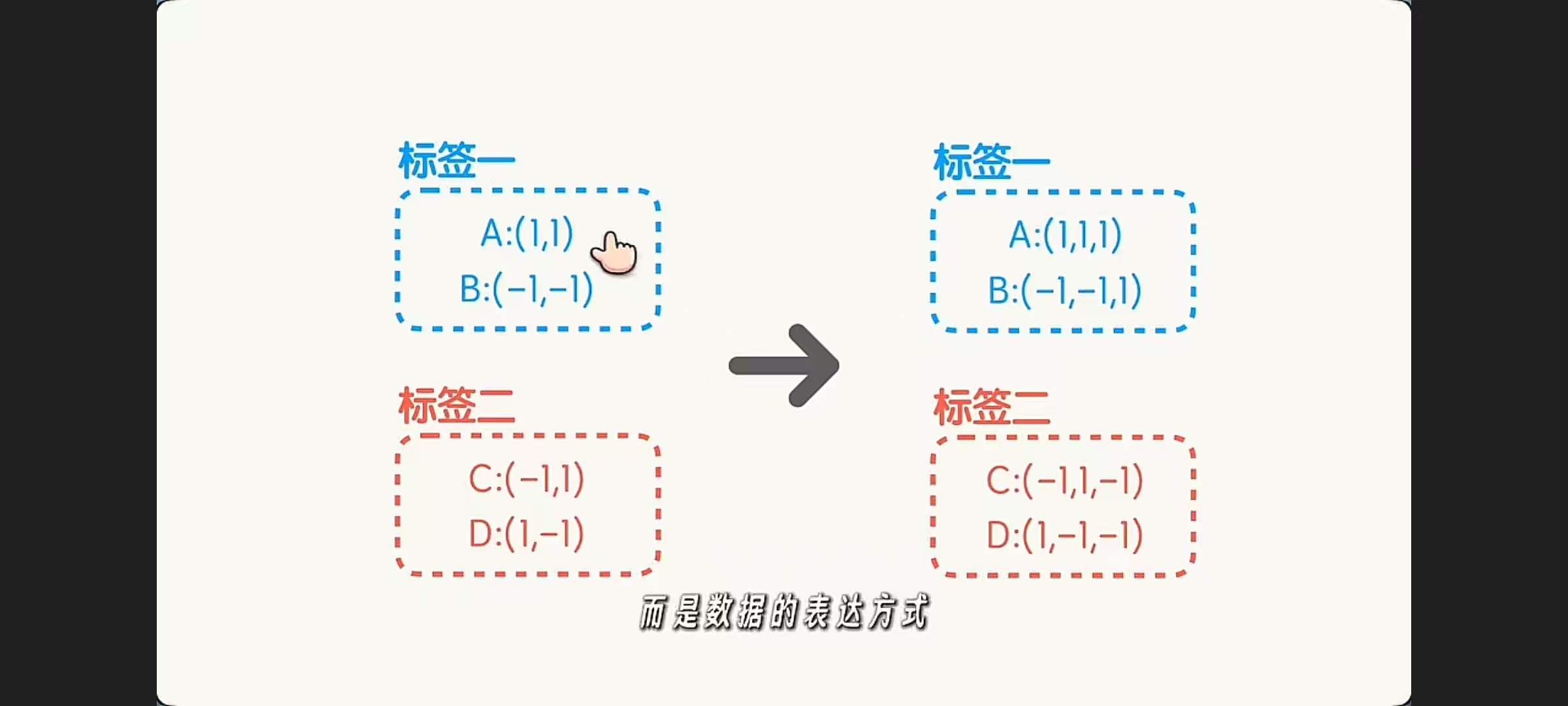
XOR 例子说明的不是“样本变了”,而是“样本的表示方式变了”。
升维后的向量虽然不等于原向量,但仍然对应同一个样本。
真正让数据更容易分类的,不是单纯维度变多,而是新表示中包含了更符合任务规律的特征。
在深度学习中,这种高维特征通常不是人工设计,而是通过非线性网络从数据中自动学习得到的。
⚪线性确实可以组合特征,但它只能做固定的全局加权组合;非线性让网络能够根据输入不同,选择不同的激活模式和组合方式,从而表达复杂的特征交互和非线性决策边界。没有非线性,多层网络最终仍然只是一个线性模型。
你可以把线性想成做菜时的:
固定配方搅拌
比如永远是:
- 盐 2 克
- 糖 1 克
- 醋 3 克
不管什么菜,都这么拌。
而非线性更像:
先判断菜是什么,再决定要不要放某个调料、放多少、是否跳过某一步
⚪RGB 图像本质上是二维空间数据,每个空间位置附带 3 个颜色通道值。因此,在深度学习中说“升维”,很多时候并不是增加新的空间坐标轴,而是增加每个位置上的特征维度或通道数。
- XYZ 轴:告诉你“在哪里”
- RGB / feature channels:告诉你“是什么样”
- 加空间维度:像从平面变成立体
- 加特征维度:像在同一个位置上记录更多属性
因为网络希望在同一个空间位置上,提取越来越丰富的特征。
比如一个像素位置原来只有:
- 红、绿、蓝
经过卷积后,这个位置可能变成:
- 是否像边缘
- 是否像纹理
- 是否像角点
- 是否像毛发
- 是否像狗耳朵区域
- 是否像背景
这些都不是空间位置,而是这个位置上的“特征响应”。
所以通道越来越多,本质上是:
每个位置的特征描述越来越丰富
深度学习里很多“加维度”,本质上是加特征轴,不是加空间坐标系。
⚪升维到底是在干什么?为什么升维后还要加非线性?
在深度学习中,升维并不等于线性分离本身,而是把输入映射到更高维、更丰富的特征空间,使不同模式更容易被表示和区分。
如果只有线性升维而没有非线性激活,那么多层网络仍然等价于单层线性变换,表达能力有限。
因此,升维之后通常需要加入激活函数,通过非线性变换来学习复杂的特征关系和非线性决策边界。
升维是“把特征展开”,激活函数是“把特征掰弯”。
只有展开,没有掰弯,模型还是线性的;
只有升维和非线性一起作用,网络才有能力把复杂数据逐步变得更可分。
⚪一、为什么要"分配"?——CPU 和 GPU 是两台机器
虽然 GPU 插在主板上,但从内存系统看,CPU 和 GPU 是两个独立的处理器,各自有独立的物理内存:
|
处理器 |
内存 |
物理介质 |
|---|---|---|
|
CPU |
主存(Host Memory) |
DDR4/DDR5 |
|
GPU |
显存(Device Memory) |
GDDR6/HBM |
它们通过 PCIe 总线(或 NVLink)通信。这就像两台电脑通过网线连着——A 机器不能直接读 B 机器的内存。
所以当你写 cudaMalloc(&ptr, size),做的事情是:
-
向 GPU 的内存管理器(driver 驱动里的一个组件)申请一块连续的显存区域;
-
管理器返回一个"设备指针"(device pointer),这个指针在 CPU 上不能解引用,只有 GPU 上的 kernel 能用它读写。
你可以把 GPU 内存管理器想象成一个"房东":cudaMalloc 是签租约拿房间,cudaFree 是退房。不签约就住,房东会赶你走(段错误 / illegal memory access)。
⚪二、"为什么不能直接把内存放在 GPU 里"——其实可以,但"分配"这一步躲不掉
你的问题其实可以拆成两件事:
(a) 数据从哪来? 如果数据一开始在 CPU(从硬盘读、从 DataLoader 来),那必须做 H2D 传输(cudaMemcpy)。如果数据已经在 GPU 上(比如前一个 kernel 的输出、前一层的 feature map),那下一个 kernel 直接用那块显存就行,不需要再传。
(b) "分配"能不能省? 不能。只要你要在 GPU 上存一块新数据,就得先告诉管理器"这块地归我"。这是内存管理的本质要求——任何需要持久存在的数据都需要有一块被登记过的地址空间。
举个例子,DCN 的 forward 里:
-
输入
input、offset:上游传下来的 tensor,已经在 GPU,不用重新分配; -
输出
output:这是一块新的数据,需要cudaMalloc一块空间来存结果; -
中间的
columnsbuffer(DCN 用 im2col 思路时需要的临时矩阵):也是新数据,也要分配。
⚪三、那为什么写 PyTorch 时从没调过 cudaMalloc?
因为 PyTorch 帮你做了两件事:
1. 框架代劳。 你写 y = conv(x),PyTorch 内部:
-
根据
x.shape和 conv 参数算出y的 shape; -
调
cudaMalloc(或 caching allocator)给y分配显存; -
调 cuDNN/自定义 kernel 往
y里写结果; -
返回 tensor 对象给你。
2. Caching Allocator(显存池)。 PyTorch 不是每次都向 OS 申请、释放,而是:
-
第一次需要显存时,一次性向 driver 要一大块;
-
内部自己切分、复用;
-
你
del tensor时,显存不还给 driver,只还给 PyTorch 自己的池。
这就是为什么你 del 完 tensor,nvidia-smi 看到的显存占用不降——因为 PyTorch 把它"留着备用"了。torch.cuda.memory_allocated() 反映的是池内已用,torch.cuda.memory_reserved() 反映的是池总大小。
所以写自定义 CUDA kernel 之所以要手动 malloc/free,不是因为 CUDA 设计繁琐,而是因为你在"框架之下"的那一层工作——平时都是 PyTorch 替你做的。
┌─────────────────────────────────────┐
│ 你的代码(Python / PyTorch) │ ← 你写的
├─────────────────────────────────────┤
│ PyTorch / TensorFlow / TensorRT │ ← 深度学习框架
├─────────────────────────────────────┤
│ cuDNN / cuBLAS / NCCL │ ← 库(算子、通信)
├─────────────────────────────────────┤
│ CUDA Runtime API(libcudart.so) │ ← cudaMalloc、cudaMemcpy 在这层
├─────────────────────────────────────┤
│ CUDA Driver API(libcuda.so) │ ← 更底层,cuMemAlloc、cuLaunchKernel
├─────────────────────────────────────┤
│ NVIDIA Kernel Driver(nvidia.ko) │ ← 内核态驱动,真正操作硬件
├─────────────────────────────────────┤
│ GPU 硬件 │ ← 物理芯片
└─────────────────────────────────────┘
⚪Python 中 print() 的所有常见用法,按类型和场景分类
| 场景 | 括号内容 | 特点 / 注意点 |
|---|---|---|
| 固定文本 | "Hello" 或 'Hello' | 输出字符串,必须用引号 |
| 变量 | x, y, my_list | 输出变量当前值,不用引号 |
| 表达式 | 2+3, 3*4 | 先计算再输出结果 |
| 函数返回值 | torch.cuda.is_available() | 输出函数返回值 |
| 多元素 | "名字:", name | 用逗号分隔,自动加空格 |
| 格式化输出 | f"{name}的分数是{score}" | 可嵌入变量和表达式 |
| 多行文本 | """line1\nline2""" | 支持换行显示 |
| 自定义结尾/分隔 | end=" ", sep="-" | 控制换行或分隔符 |
| 调试 | print(var) | 查看程序运行状态 |
⚪torch.cuda.is_available() . 和 _ 的用法
. (点号)
-
用于 访问对象的属性或方法,或者 模块中的子模块/函数。
-
在
torch.cuda.is_available()中:-
torch→ PyTorch 的顶级模块。 -
cuda→torch模块里的一个子模块,管理 GPU 相关功能。 -
is_available()→cuda子模块下的一个函数方法。
-
理解方式:
“层层访问,从大模块 → 子模块 → 函数/方法”,每一层用
.连接。
_ (下划线)
-
用于 Python 命名规则中,例如函数名、变量名、类属性等。
-
在
is_available()中的_:-
只是函数名的一部分,不能用点号代替。
-
Python 的命名习惯:
-
单词间用
_连接(snake_case),比如is_available,my_variable_name。 -
类名一般用大写开头的驼峰命名(CamelCase),比如
MyClassName。
-
-
⚪反向传播,填充所有 .grad什么意思,是不是在nn.Parameter列表里填充梯度
.grad 是挂在每个 Parameter 张量上的属性
model 里所有 requires_grad=True 的参数,本质上是一个个 torch.Tensor,每个张量对象上有一个 .grad 槽位:
model.layer1.weight # Parameter 张量本身,存权重值
model.layer1.weight.grad # 同形状的张量,存梯度值,初始为 None
loss.backward() 做的事就是:按链式法则从后往前,把梯度的数值写进每个参数的 .grad 里。
不是"列表",而是图上的节点
PyTorch 在前向传播时会构建一张计算图,每个参与计算的张量都是图上的节点。backward() 沿这张图反向遍历,遇到 requires_grad=True 的叶子节点(即 Parameter)就把梯度累积到它的 .grad 上。
计算图(前向): x → Linear → ReLU → Linear → loss
↑ ↑
weight1 weight2 ← 叶子节点
backward() 方向: loss → Linear ← ReLU ← Linear
↓ ↓
weight1.grad weight2.grad ← 被填充
optimizer 持有的 param_groups 里存的就是这些 Parameter 的引用,step() 时直接去读它们的 .grad 来更新权重值。
一句话总结
backward()遍历计算图的所有叶子 Parameter,把对应梯度数值写入各自的.grad属性;optimizer.step()再拿着这些.grad去修改权重本身的数值。
⚪在一次训练迭代里,反向传播虽然是从后往前计算梯度,但是如果你用的是普通的 SGD 或 Adam,这一轮 optimizer.step() 时的基础学习率通常是同一个。请问更新参数时是反向传播算一步更新一步,还是全部算完一次更新,参数是不是存在.grad里面
两个问题分开回答
1. 是"全部算完梯度,再一次性更新"
PyTorch 的标准流程是:
loss.backward() # 反向传播:把所有参数的梯度算完,存进 .grad
optimizer.step() # 参数更新:遍历所有参数,用 .grad 里的值更新
backward() 阶段只计算梯度,不动参数。等所有参数的 .grad 都填好之后,optimizer.step() 才统一去读取并更新。
所以是:先全部算梯度 → 再全部更新参数,而不是算一个更新一个。
2. 梯度确实存在 .grad 里
每个 nn.Parameter(即 requires_grad=True 的 Tensor)都有一个 .grad 属性:
-
backward()执行后,$\frac{\partial L}{\partial \theta_i}$ 就写入param.grad -
如果连续两次
backward()中间没有optimizer.zero_grad(),梯度会累加而不是覆盖,这是个常见 bug
3. 反向传播的计算顺序 vs 参数更新顺序
|
阶段 |
顺序 |
说明 |
|---|---|---|
|
|
从输出层 → 输入层(链式法则) |
必须先有下游梯度才能算上游 |
|
|
无严格顺序,遍历 |
因为此时梯度已全部就绪,顺序无关 |
反向传播必须从后往前是因为链式法则的依赖关系,但更新阶段各参数的 .grad 已经相互独立,谁先更新都一样。
标准一次迭代的完整流程
optimizer.zero_grad() # 清空上一轮残留的 .grad
output = model(x) # 前向传播
loss = criterion(output, y)
loss.backward() # 反向传播,填充所有 .grad
optimizer.step() # 读取 .grad,更新所有参数
⚪Adam是不是每个参数都有自己学习率,为什么参数量变多,一样的学习率会产生不一样的行为具体一点
并不是有自己的学习率,而是统一的全局学习率,但是每个参数会根据自身的历史梯度平方去约束自适应调整学习率。
全局学习率 η\eta η 是统一的,但每个参数用自己的 v^i\hat{v}_i v^i 去"除"它,得到各自的有效学习率。参数量越多,各参数梯度历史差异越大,v^i\hat{v}_i v^i 分布越分散,同一个 η\eta η 对不同参数产生的实际步长差异就越悬殊,整体训练行为自然不同。
⚪loss变复杂了可不可以这样理解,参数量变多了,loss可以优化的路径也多了
参数变多以后,常见变化是:
第一,表达能力更强
模型能拟合更复杂的函数,所以更有可能把训练集拟合好。
第二,优化地形更复杂
loss 对不同参数方向的敏感度不同,可能出现:
-
有些方向很陡
-
有些方向很平
-
有些参数之间强耦合
所以不是简单“路变多了”,而是:
地图变成了更高维、更复杂的地形。参数量增加后,模型参数空间维度升高,函数表达能力增强,同时损失函数对应的高维优化地形也会改变,因此同样的学习率可能表现出不同的优化行为。
⚪为什么会出现损失值特别大,甚至 Inf / NaN?
第一步:看 loss 是一开始就 NaN,还是训练一段时间后才 NaN
第二步:如果一开始就 NaN
优先查数据、标签、loss公式、输出范围
第三步:如果训练一段时间后才 NaN
优先查学习率和梯度爆炸
第四步:如果梯度爆炸
再加梯度裁剪
NaN 可以出现在训练过程中的任何一个张量里,包括:
-
输入数据
-
中间特征(activation)
-
loss
-
梯度(gradient)
-
参数(weight)
所以“参数不稳定”和“loss 出现 NaN”不是没关系,它们往往是同一条数值崩溃链上的前后环节。
情况1:数值溢出成 Inf
例如在 float32 里,数值上限大约是:
3.4×1038
这已经超出 float32 范围了,就可能直接变成 Inf。
情况2:Inf 再参与非法运算,变成 NaN
很多运算对 Inf 很敏感,例如:
-
Inf - Inf = NaN -
0 × Inf = NaN -
Inf / Inf = NaN -
log(0)得到-Inf,后续再参与别的运算可能变成NaN -
sqrt(负数) = NaN
所以链条常常是:
学习率太大→梯度更新步长太大→参数突然变得特别大→前向输出过大→loss 变成 Inf/NaN→反向梯度也变成 NaN→参数全被污染成 NaN
⚪为什么数据归一化可以减少nan?
2)让梯度尺度更平稳
反向传播里,梯度大小和前向中的激活值、参数值都有关系。
如果输入本身尺度特别乱,那么不同参数收到的梯度也会很不均匀:
-
有些参数梯度巨大
-
有些参数梯度很小
这会导致更新非常不平衡。
而归一化后,各维度输入尺度更接近,梯度通常也会更可控。
所以优化器更新时不容易出现:
-
一步跨太大
-
参数突然变得特别大
-
后面计算崩掉
-
神经元只搜x2影响

⚪残差学习的去噪网络

⚪双像素任务的本质
问题来源不是噪声,而是相机物理结构导致的散焦模糊:
左子像素 L ──→ 同一场景,同一时刻
右子像素 R ──→ 但左右视角略有差异,各自都有散焦模糊L 和 R 本身都是"干净"的图像,没有随机噪声污染,只是因为相位差导致图像模糊,无法清晰对焦。
任务目标对比
|
任务 |
退化原因 |
目标 |
|---|---|---|
|
去噪 |
传感器噪声、量化误差 |
去除随机噪声 |
|
双像素散焦去模糊 |
相机子像素视角差异 |
融合 L/R 恢复清晰对焦图 |
⚪LoRA 完整公式:h = W₀ · x + (α / r) · B · A · x A 和 B 具体是什么
r(秩)决定参数量,α(缩放系数)决定数值大小,这个增量的数值越大,对原始权重的修改幅度越大。
A 和 B 就是两个普通的线性层(nn.Linear),没有偏置项。
假设原始模型中有一个线性层,权重为 W₀ ∈ R^(4096 × 4096),r = 16:
原始结构:
x → [W₀] → h
就是一个矩阵乘法:h = W₀ · x
加入 LoRA 后的结构:
┌──── [W₀] (冻结,不更新) ────┐
│ │
x ───────┤ ├── 相加 ── h
│ │
└── [A] ── [B] ── × (α/r) ────┘
多了一条并联的旁路,由两个小线性层串联组成:
-
A 是一个 nn.Linear(4096, 16),把 4096 维压缩到 16 维
-
B 是一个 nn.Linear(16, 4096),把 16 维还原到 4096 维
前向传播时,两条路径的输出直接相加:
h = W₀ · x + (α / r) · B(A(x))
用 PyTorch 代码理解
原始线性层:
self.W0 = nn.Linear(4096, 4096) # 原始权重,冻结
LoRA 加的两个层:
self.A = nn.Linear(4096, 16) # 降维,可训练
self.B = nn.Linear(16, 4096) # 升维,可训练
前向传播:
h = self.W0(x) + (alpha / r) * self.B(self.A(x))
就这么简单。A 和 B 不是什么抽象的数学概念,就是两个实实在在的小线性层,挂在原始层旁边。
训练过程中发生了什么
冻结阶段(训练开始前):
把原始模型所有参数设为不可训练:
for param in model.parameters():
param.requires_grad = False
然后给需要微调的层(通常是 attention 的 Q/K/V/O 投影)各插入一对 A、B,设为可训练。
前向传播:
输入 x 同时经过两条路径。W₀ 路径正常计算但不记录梯度,A → B 路径计算并记录梯度。两条路径的输出相加得到 h。
反向传播:
损失函数对 h 求梯度,梯度沿着 A → B 这条旁路反传,更新 A 和 B 的参数。W₀ 因为被冻结,不接收梯度,始终不变。
参数更新的具体过程:
每一步训练中,优化器(比如 AdamW)只看 A 和 B 的梯度:
optimizer = AdamW([A的参数, B的参数], lr=1e-4)
优化器根据梯度更新 A 和 B 的权重数值,使得 B · A 这个增量逐渐逼近让损失最小的方向。
一个具体的数值例子
假设训练前 B 初始化为零矩阵,所以 B · A = 0,模型行为和原始完全一样。
训练第 1 步:损失函数产生梯度 → B 的某些位置从 0 变成了微小的非零值(比如 0.001)→ B · A 不再为零 → 模型输出开始偏离原始模型
训练第 100 步:B 和 A 的值经过多次更新,B · A 已经形成了一个有意义的增量矩阵 → 这个增量就是模型为了适应下游任务而学到的"修正量"
训练结束:B · A 收敛到最优增量,合并回原始权重 W_merged = W₀ + (α/r) · B · A
为什么要拆成两个小矩阵而不是直接加一个大矩阵
如果直接加一个可训练的 ΔW ∈ R^(4096 × 4096),参数量是 4096 × 4096 = 16,777,216。
拆成 A 和 B 后,参数量是 4096 × 16 + 16 × 4096 = 131,072,只有原来的 0.78%。
代价是 ΔW = B · A 的秩最多为 r = 16,不能表示任意的 4096 × 4096 矩阵。但实验证明下游任务适配只需要很低的秩就够了,这个代价可以接受。
⚪Adam 优化器完整总结
一、核心符号定义
|
符号 |
含义 |
|---|---|
|
θ |
模型参数 |
|
g_t |
第 t 步的梯度,即 ∂L/∂θ |
|
m_t |
一阶动量(梯度的指数加权平均) |
|
v_t |
二阶动量(梯度平方的指数加权平均) |
|
η |
学习率 |
|
β₁ |
一阶动量衰减系数,通常 0.9 |
|
β₂ |
二阶动量衰减系数,通常 0.999 |
|
ε |
防止除零的极小常数,通常 1e-8 |
二、Adam 的三步计算
第一步:更新一阶动量(某个参数历史)
m_t = β₁ · m_(t-1) + (1 - β₁) · g_t。对梯度本身做指数加权平均。作用:给梯度加惯性。
-
连续多步梯度方向一致(比如一直为正)→ m_t 累积变大 → 参数更新加速
-
梯度方向来回震荡(一会正一会负)→ m_t 中正负抵消 → 参数更新变小
类比:一个球在坡上滚,方向一致就越滚越快,左右颠簸就减速。
第二步:更新二阶动量(历史)
v_t = β₂ · v_(t-1) + (1 - β₂) · g_t²,对梯度的平方做指数加权平均。
作用:衡量每个参数的梯度幅度有多大,自适应调整步长。
-
某参数历史梯度幅度大 → v_t 大 → 分母大 → 实际步长小
-
某参数历史梯度幅度小 → v_t 小 → 分母小 → 实际步长大
本质:自动给每个参数分配不同的学习率——梯度大的走小步,梯度小的走大步。
第三步:参数更新
θ_(t+1) = θ_t - η · m_t / (√v_t + ε)
三、为什么二阶动量用梯度平方而不是梯度本身
二阶动量需要衡量的是梯度的"幅度",不是"方向"。
例子: 某参数连续 4 步梯度为 +5, -5, +5, -5
-
对梯度本身求平均:(+5 - 5 + 5 - 5) / 4 = 0 → 误判为"梯度很小",给大步长 → 导致震荡
-
对梯度平方求平均:(25 + 25 + 25 + 25) / 4 = 25,√25 = 5 → 正确反映"幅度一直是5",给小步长
根本原因:梯度有正有负,直接平均会正负抵消丢失幅度信息;平方后全为正,不会抵消。
四、一阶动量与二阶动量对比
|
一阶动量 m_t |
二阶动量 v_t |
|
|---|---|---|
|
公式 |
β₁ · m_(t-1) + (1 - β₁) · g_t |
β₂ · v_(t-1) + (1 - β₂) · g_t² |
|
平均的对象 |
梯度本身 |
梯度的平方 |
|
记录什么 |
梯度方向的历史趋势 |
梯度幅度的历史大小 |
|
作用 |
加速一致方向、抑制震荡 |
自适应调整每个参数的步长 |
|
在更新公式中的位置 |
分子(决定更新方向和大小) |
分母(归一化步长) |
|
是否逐参数独立 |
是 |
是 |
六、AdamW 与 Adam 的区别
标准 Adam 的权重衰减和梯度更新是耦合的(权重衰减被加进梯度里再做自适应缩放),这会导致正则化效果被 v_t 的缩放削弱。
AdamW 将权重衰减解耦,直接在参数上减去:
θ_(t+1) = θ_t - η · m̂_t / (√v̂_t + ε) - η · λ · θ_t
其中 λ 是权重衰减系数。这样权重衰减不经过 Adam 的自适应缩放,正则化效果更稳定。
七、Adam 的显存开销
以参数量为 X 的模型为例,Adam 需要为每个参数维护:
|
存储项 |
精度 |
每参数字节数 |
总大小 |
|---|---|---|---|
|
FP32 权重主副本 |
FP32 |
4 |
4X |
|
一阶动量 m |
FP32 |
4 |
4X |
|
二阶动量 v |
FP32 |
4 |
4X |
|
合计 |
12X 字节 |
混合精度训练下的完整显存(含权重和梯度):
|
组成部分 |
精度 |
大小 |
|---|---|---|
|
模型权重(前向/反向用) |
FP16 |
2X(在训练模型前向传播中的conv值,训练结束会消失) |
|
梯度 |
FP16 |
2X(一批次前向传播结束,反向传播产生的所有模型的全部参数梯度) |
|
FP32 权重主副本 |
FP32 |
4X |
|
Adam 一阶动量 m |
FP32 |
4X |
|
Adam 二阶动量 v |
FP32 |
4X |
|
固定总计 |
16X 字节(16倍混合精度) |
|
|
激活值 |
FP16 |
视 batch size |
⚪参数更新始终在 FP32 上完成,FP16 仅用于加速计算,每一轮都会由 FP32 权重重新生成。
| 步骤 | 阶段 | 使用精度 | 涉及变量 | 做什么 | 是否保留 |
|---|---|---|---|---|---|
| 1 | 前向传播 | FP16 | W_fp16, x | 计算模型输出 y = Wx | ❌ |
| 2 | 损失计算 | FP16 | pred, label | 计算 loss | ❌ |
| 3 | 反向传播 | FP16 | grad_fp16 | 计算梯度 ∂L/∂W | ❌ |
| 4 | 梯度传递(gradscaler) | FP16 → FP32 | grad | 传给优化器 | ❌ |
| 5 | 参数更新(副本权重) | FP32 | W_fp32 | W = W - η·g(核心) | ✅ |
| 6 | 精度转换(梯度缩放回去) | FP32 → FP16 | W_fp16 | 截断用于下一轮计算 | ❌ |
| 7 | 下一轮训练 | FP16 | W_fp16 | 继续前向传播 | ❌ |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)