单模态视觉识别模型:从应用到原理的初步解析
在人工智能技术飞速迭代的今天,计算机视觉识别作为AI的核心分支,正深刻改变着各行业的运作模式。其中,单模态视觉识别模型凭借架构简洁、部署高效的特性,成为工业落地的焦点。
人们都说模型像个黑盒子,训练完的模型在物理上是什么样的?
训练完的模型在电脑文件夹内是一堆文件,文件内有一大堆数字(参数),小的模型一般有10几个文件,每个文件都有几个G内存。把这些文件(包含参数)通过代码在服务器的内存、显卡上运行起来,就叫做模型部署。
应用场景
图像分类场景
说个简单点的模型,输入的参数是“猫”、“狗”图片,经过模型的一系列特征提取、信息聚合等操作,输出标签/ID:“Cat”/“Dog”。
业务流程图:
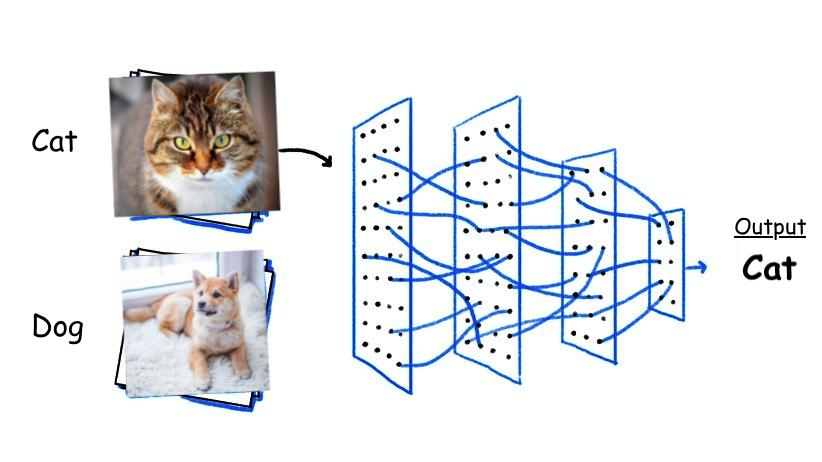
业务流程图:
目标检测场景
案例1:从图中找到里面有什么物体。
输入一张图片,找到图片内的人、狗、马、车等物体,并且用矩形框住,上方有类型标识与相似度数值。

图像分割场景
图像分割分割有2种类型:
- 语义分割;
- 实体分割。
输入一张图片,把图片内的物体描绘出来,不同类型的物体使用不同的颜色。
比如图片是300 * 500 像素,总共15万像素,每个像素点都需要给一个标签,它是一个独特的物体,比如:马路、红绿灯、广告牌、人、车等。
下面图片是进行语义分割:

第一个图片在进行语义分割,只需要分割出桌子、人;
第二张图在进行实体分割,要分清桌子,人也要分出6种不同的人,并且标记成不同的颜色。
![![[Pasted image 20260401150710.png]]](https://i-blog.csdnimg.cn/direct/887e38d3c2bd4e77a1ebb8110ec74560.png)
人脸识别场景
如下图,人脸上有很多关键点,也叫人脸特征值:

也可以识别N张人脸:

姿态识别场景
通过人体的骨骼(人的肩膀、手腕、手肘、手指等),来识别当前人的姿势,就能知道他在做什么动作,可以进行预判当前人类在做什么,或者接下来可能会做什么动作等。
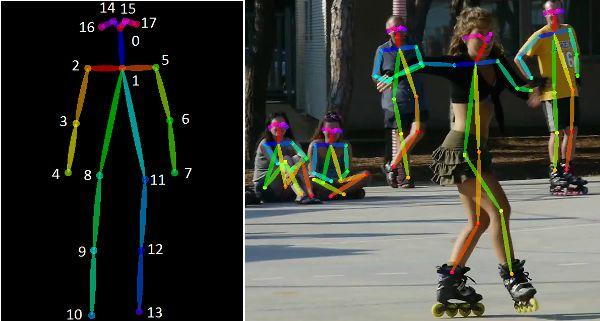
姿态识别任务常用于安防领域,如下图:

视觉问答场景
通过一张图片以及对应的文字,可以知道当前图片内在干什么,或者图片内有什么东西。
比如这张图里的披萨被切成多少块?它就可以回答你多少块

比如,图片内有一对情侣在手牵手,并且在路上逛街:

卷积神经网络(CNN)
CNN(卷积神经网络),全称为Convolutional Neural Network,是一种专门用于处理具有网格结构数据(特别是图像)的前馈神经网络。它通过卷积操作自动提取空间层次的特征。
主要特点:
- 局部连接:每个卷积核只关注局部输入区域,捕捉局部特征。
- 参数共享:同一个卷积核的参数被重复使用,大幅减少参数数量。
- 层级结构:多层卷积层和池化层逐步提取从简单到复杂的特征。
- 空间不变性:对图像中的平移、缩放等变换具有较强鲁棒性。
卷积核
卷积神经网络的核心:卷积核。
你给我一张图片为原始图片,我通过一个卷积核(3 * 3) 进行处理,得到一个新的特征图。
卷积核对原图进行特征提取的工作,得到的新图叫做特征图。
如下图所示:
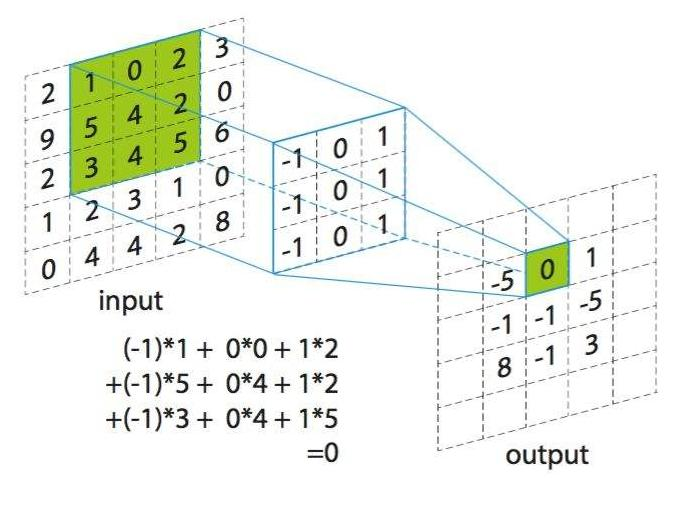
output特征图上的第三列、第二行的数值 “0” 是怎么得到的?
通过input原图 + 3 * 3 的卷积核,进行加权求和得到特征图上的一个点的向量。
步骤如下:
1、在input原图上找到第三列、第二行的数值 “4”,以 “4” 为中心,画一个3 * 3的正方形,圈住的数值集 [1,0,2,5,4,2,3,4,5];
2、把圈住的数值集 [1,0,2,5,4,2,3,4,5]与卷积核的参数 [-1, 0, 1, -1, 0, 1, -1, 0 ,1]进行加权求和 :-1 * 1 + 0 * 0 + 1 * 2 + -1 * 5 + 0 * 4 + 1 * 2 + -1 * 3 + 0 * 4 + 1 * 5 = 0;
3、最后在output特征图上第三列、第二行的数值就等于 “0”。
卷积神经网络(CNN) 内的卷积核内部都是参数,这里的参数跟其他类型的神经网络内部参数一样,最开始都不知道参数需要设置成什么样,才能到达要求,所以都是设置成随机数,然后通过模型训练调整出合适参数,让卷积核能提取到有用、有价值的特征。
卷积神经网络的参数都是在卷积核内部。
如图上所示,在input原图上,绿色的框在原图上进行滑动,每次滑动,并且通过卷积核计算,可以在output特征图内生成对应的特征值,一直滑动,最后到特征图越来越完整,就结束一轮特征提取。
这轮特征提取会有一个问题,在input原图的边缘上,数值没办法提取到。
处理的方式有2种:
- 绿框可以滑到原图外,原图外的值是复制就近的参数,然后再通过卷积核的参数进行加权求和计算,把值填充到新图内,这样input原图是多大,output特征图也有多大,比如原图是 28 * 28像素,特征图就是 28 * 28像素。
- input原图边缘上的值放弃掉,都不计算,再output特征图上就是空,最后的output特征图会比input原图小,比如原图是 28 * 28像素,新图就是 24 * 24像素。这种处理方式也叫做边缘检测,一般视觉处理都是用该方式。
卷积核还有一种模糊处理的方式:在卷积核的参数上 * 1/16,每次卷积层都进行做平均,可以让图片变得越来越模糊。
卷积核的参数,如下所示:
![[Pasted image 20260331113701.png]]
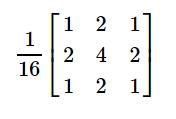
如果用1 / 16的卷积核,对原图进行处理,效果如下:

简而言之,每次用1 / 16 的卷积核,每次卷积核一次都会模糊一点,以下是3次样式:
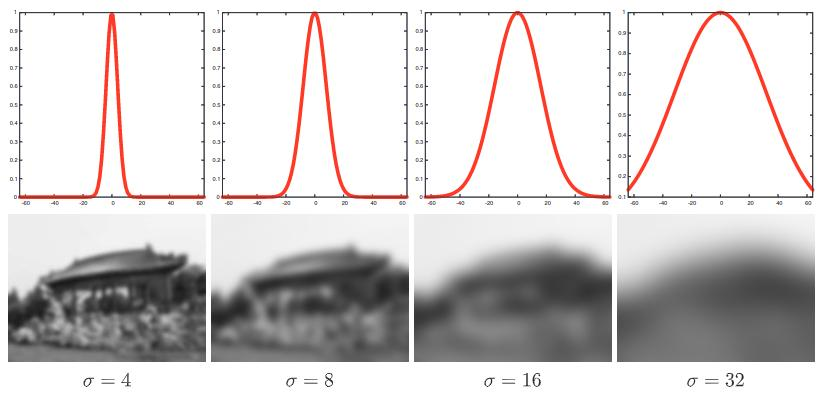
综上所说,不同的卷积核可以起到不同的特征提取作用,那么我们不知道我们要什么样的卷积核,那么前期就把卷积核的参数进行随机,然后通过模型训练方式,通过总误差进行调整参数,卷积核内是什么的数值,比较适合做当下的任务,得到整个数值之后,卷积核就训练完了。
模型训练请看我之前写的文章 # 初遇Open AI,深入了解大语言模型训练范式
卷积核总结:
- 卷积核在图片上滑动的时候,每一次计算,就是在对图片中的一个小“区域”提取特征;
- 卷积核滑动处理完一张图片后,得到的新的矩阵,叫做特征图(类似LLM中的向量概念);
- 对一张图片,同时使用多个卷积核,即可得到多组特征图;
- 不同的卷积核,类似于 Transformer - Decoder(解码器) 的多头自注意力机制内的“多头”概念 ,从不同角度提取图片中的特征。比如 Transformer - Decoder(解码器) 的多头自注意机制,它内部是从96个角度对这段文字提取特征,这个概念在单模态模型内,等同于一张原图进行多个、不同的卷积核,进行提取不同的特征。
Transformer - Decoder(解码器) 是从卷积神经网络(CNN) 这里学习过去的,1989年卷积神经网络进行应用,2017年Google才提出Transformer架构。
尺度
视觉图片 与 语言文字 相比,还有一个重要的概念:“尺度”。
比如这张图,当前视觉尺度比较近时,你能看清发动机里面的东西,上面还有小图案,机翼下面有什么东西,草地上草的纹理等,树还可以看到树杈,在当前尺度下,你可以看到很多细节和纹理。

但是你把照片缩小,你能看到的视觉是:
![![[Pasted image 20260331134458.png]]](https://i-blog.csdnimg.cn/direct/1718e7e2726f47caa3e567ce0bdea226.png)
再缩小一半,你看的细节就比较少:

再缩小一半,你只能看到飞机的轮廓:

如果拿到最后缩小的图片,你还能看清图片里面的细节和纹理吗?
答案是,肯定是不行的。
不同尺度下,提取的特征是不一样的,有些尺度在提取细节特征,有些尺度在提取形状特征。
比如 使用3 * 3 的卷积核,在不同照片上提取的特征肯定是不一样的,所以在不同“尺度”概念的图片上,它的“感受野”也是不一样的。
比如在最开始的原图,尺度比较近,在3 * 3 的卷积核可以圈到飞机的轮子:

到尺度比较远的照片上,3 * 3 的卷积核圈到的范围是 1 / 3的飞机:

甚至尺度更远的照片 , 3 * 3 的卷积核圈到的范围近乎是整个飞机轮廓:

以上3张图片,通过使用相同的卷积核,在尺度不一样的情况下提取的特征是不一样的,尺度近的提取细节特征,尺度远的提取形状特征。
卷积核的原理
用之前文章内的一个案例(MNIST数据库的图像识别案例)来讲解下卷积核的内部原理。
想了解MNIST数据库的图像识别案例的,可以看下 # 初识神经网络与机器学习。
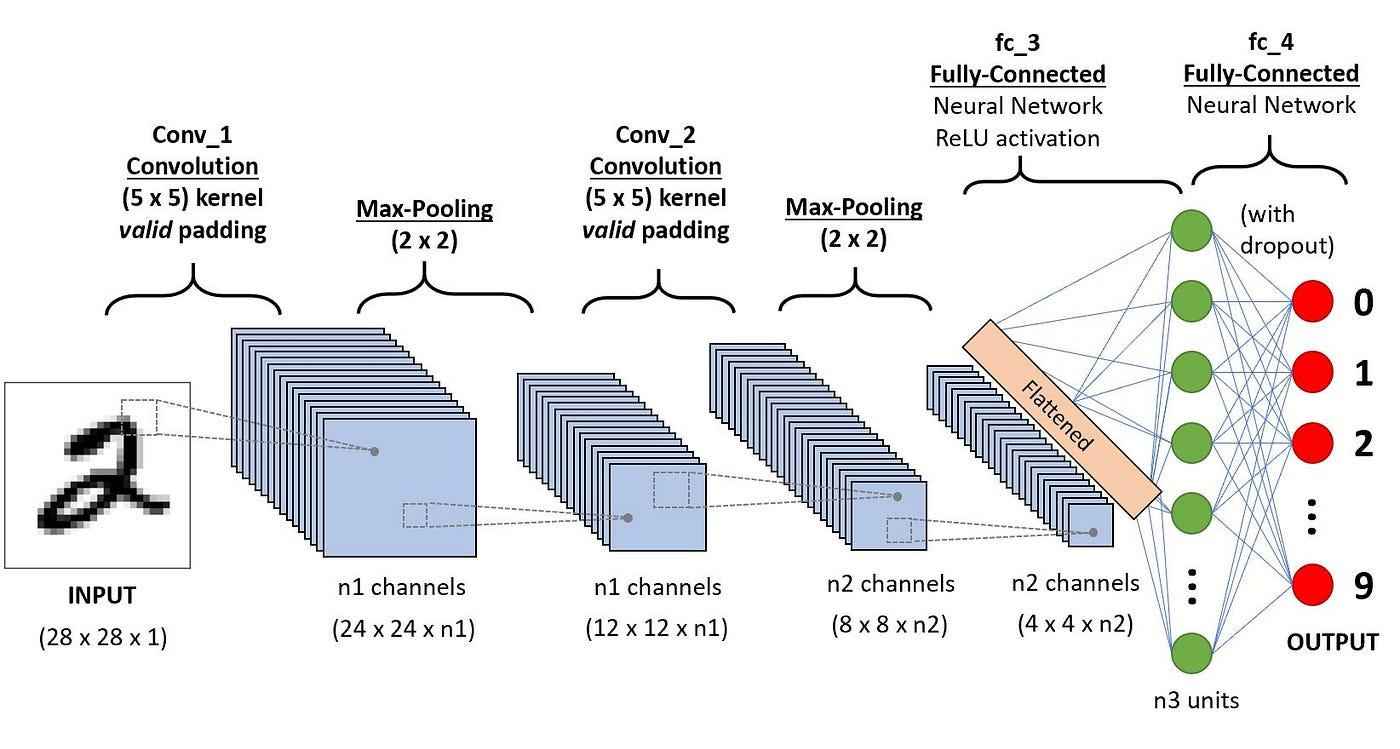
把手写 “2” 的图片输入到卷积神经网络内,它是一个 28 * 28 像素 * 1 单通道图片(单通道:图片里只有黑白灰),如果是彩色 就是三通道 (这个图片内是RGB)。
三通道的意思是一个像素点上有3个 0 ~ 255个数字,单通道的意思是一个像素点只有一个 0 ~ 255个数字。
28 * 28 * 1的图片经过 n1 个 5 * 5的卷积核的特征提取,然后输出 n1 个 24 * 24 像素的特征图,或者可以理解输出一张特征图,这个特征图上的一个像素位置就是n1维的数学向量,算法工程师在该神经网络上进行设定n1 = 32,那么当前特征图上的一个像素点的信息为32维的数学向量。
5 * 5的卷积核 在做边缘检测,特征图要小于原图,因为原图的外圈有2行/2列没办法进行计算,通过卷积核进行提取特征后,从 28 * 28像素的原图生成为 24 * 24像素的特征图。
Max-Pooling池化操作: 把24 * 24像素 进行长宽各缩小一半,变为12 * 12像素,缩小的方式:把24 * 24像素分成N个小方格,每个小方格都有2个像素,然后在2个像素内取最大像素值,其实就是选一个特征比较突出的向量,概念类似于 # 揭秘Transformer架构设计 2(补全版) 的前馈神经网络,都是把特征突出的提取出来,用人话来说就是有菱有角的信息提出出来,他们更具备代表性,比如[0,1,0,2,0.5]与[8,16,2,-34]这2组数据相比,第二组的特征值更明显。
卷积和池化操作一般来说都是绑定在一起的,在卷积神经网络(CNN)里,一般都要做一次卷积和池化计算。
第二轮,重复上面的卷积与池化步骤,本轮的“多头”是n2,是第一轮“多头”n1的2倍,n1是32,n2就是64 ,12 * 12 * n1的特征图 经过卷积+池化计算,最后输出 4 * 4 * 64 的特征图。
在 4 * 4 * n2 的特征图内拿出来一个64维的数学向量,它包含的聚合信息映射到原图上所占的区域在15 * 15 像素,甚至更大。因为64维的数学向量是经过2轮卷积层+池化层,每层的卷积核是5 * 5,它的向量空间维度大,所聚合的信息比较多,映射到原图上的面积肯定就大。
概念类似于 # 揭秘Transformer架构设计 1 里面的向量,特征信息聚合越多,就需要更大维度的空间去储存。
卷积神经网络的层数越多,它的层数越靠后,新增的特征图就会越小,但是特征图内的数学向量维度就越大,只有大维度的特征向量才能容纳多轮信息聚合所携带的信息,所以最后层次的特征图内特征向量映射到原图的区域也就越大。
当视觉任务简单时,图片不会有特别复杂的特征,卷积神经网络也不需要太多层卷积核,甚至卷积核内的数学向量维度也不会太长。
但是当视觉任务复杂时,图片就会有很多很复杂的信息,卷积神经网络就需要多层卷积核,才能更好的提取到特征,避免特征的遗漏,更好的完成任务,它最后层次的数学向量维度就会很长。
全连接层: 最后把 4 * 4 * 16的特征图转换为 16个 16维的数学向量,然后把16个16维的数学向量竖着排成一排,就得到绿色圆圈那一列,然后拿这排向量数据进行神经网络层(全连接层) 计算,输出的数据再通过Softmax归一化,得到各标签类型的概率(0 ~ 9数值的概率)。
全连接层也叫分类头,因为它在做分类任务,通过一层又一层的神经网络特征提取、信息聚合,最终拿到的特征值再进行加权求和、Softmax归一化,输出0 ~ 9数值的概率。
全连接层的计算,可以看下 # 初识神经网络与机器学习的神经网络计算逻辑。
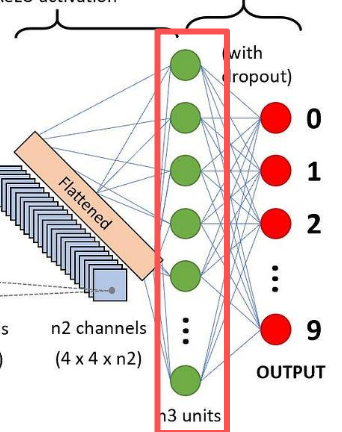
卷积神经网络是单模态模型的神经网络,它只是神经网络类型的一种而已。它也跟其他的神经网络一样,它只是在拟合,在映射关系内,它只知道在经过一系列计算,标签/ID 有多少概率,它不清楚 0 ~ 9,这10个数字是啥意思。
当前卷积神经网络的总参数:第一个卷积核 5 * 5 * 32 + 第二个卷积核 5 * 5 * 64 + 全链接神经网络 (4 * 4 * 64 + 1) 10 = 12650个参数。*
人工智能技术的快速迭代,我们也逐渐从纯视觉理解任务,慢慢到了多模态模型,本章只聊到了单模态的纯视觉模型,下一章开始给大家讲解多模态模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)