进程的调度之schedule函数(schedule源码解读)
schedule()是调度器的核心入口函数,位于 /kernel/sched/core.c,每当需要进行调度时都会调用。具体在下面这些时候会去调用schedule()函数
一、主动调度
-
等待资源/阻塞 (sleep / wait_event )
-
用户态主动让出 CPU (sched_yield())
-
内核态耗时任务中的主动让出 cond_resched()
二、被动调度
-
从系统调用返回用户态时
-
中断返回用户空间时
-
中断返回内核空间时
-
禁用抢占区结束
-
禁用软中断临界区结束
6.8内核源码schedule()
schedule()函数执行流程为:首先提交调度请求给内核,然后禁用内核抢占以确保调度操作完整执行;随后调用核心调度函数__schedule()进行实际的进程切换;调度完成后再重新启用抢占功能,循环上述步骤直到不再需要重新调度。
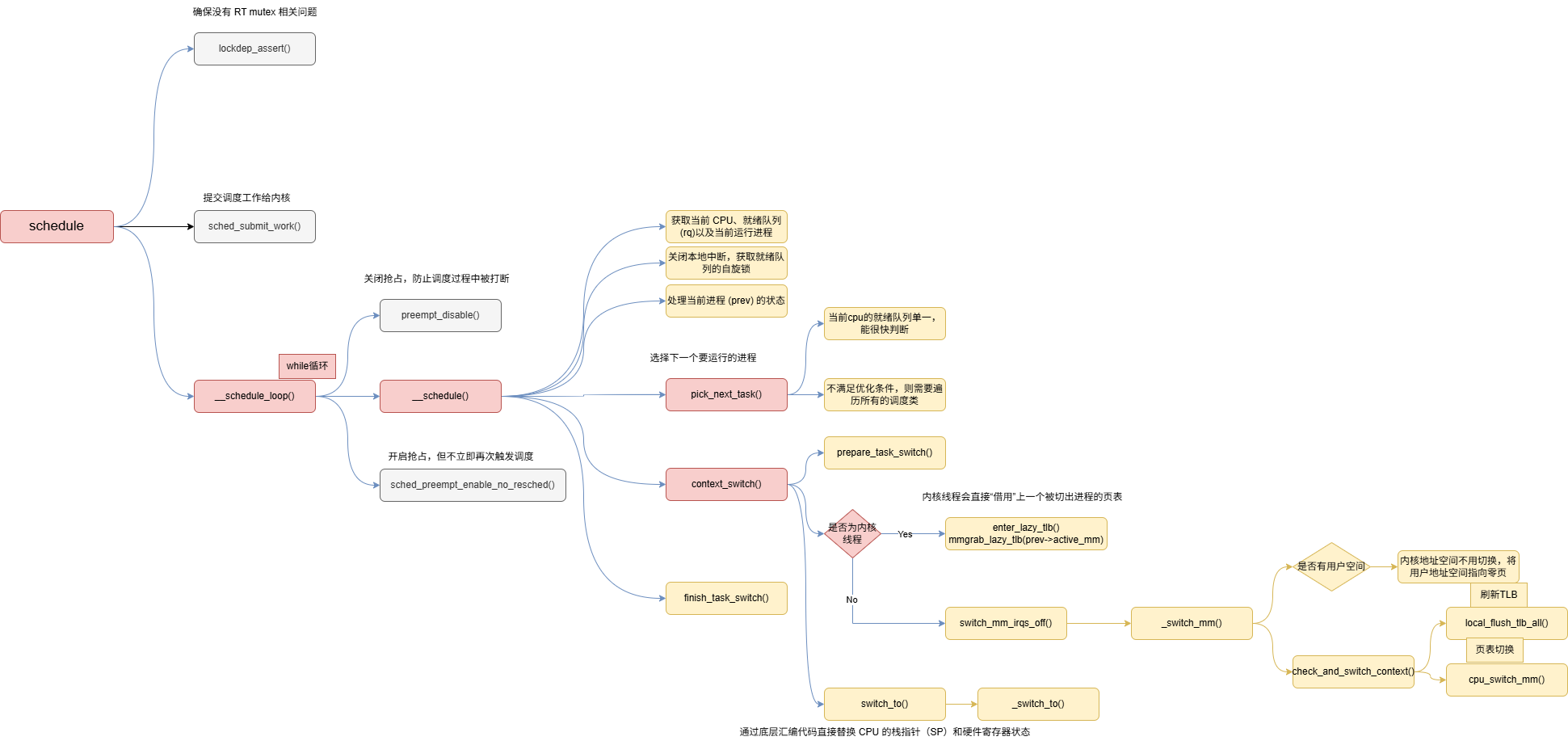
static __always_inline void __schedule_loop(unsigned int sched_mode)
{
do {
preempt_disable(); //关闭抢占,防止调度过程中被打断
__schedule(sched_mode); //schedule的核心函数
sched_preempt_enable_no_resched(); //开启抢占,但不立即再次触发调度
} while (need_resched()); //如果仍然需要调度,则继续循环
}
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current; //取当前正在运行的任务
#ifdef CONFIG_RT_MUTEXES
lockdep_assert(!tsk->sched_rt_mutex); //确保没有 RT mutex 相关问题
#endif
if (!task_is_running(tsk)) // 如果当前任务不是 RUNNING 状态
sched_submit_work(tsk); // 提交任务的收尾工
__schedule_loop(SM_NONE); // 进入调度循环(核心逻辑)
sched_update_worker(tsk); // 调度结束后更新 worker 状态(用于线程池等)
}精简流程如下:
-
关闭抢占(preempt_disable),保证调度期间不会被再次抢占
-
调用__schedule(),进入调度主循环
-
__schedule()里会遍历调度类,执行pick_next_task()选择下一个进程
-
若当前与下一个进程不同,则调用context_switch()完成上下文切换
-
恢复抢占(preempt_enable)
__schedule源码
static void __sched notrace __schedule(unsigned int sched_mode)
{
struct task_struct *prev, *next;
struct rq *rq;
int cpu;
// 1. 获取当前 CPU、就绪队列 (rq) 以及当前正在运行的进程 (prev)
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
// 2. 关闭本地中断,获取就绪队列的自旋锁 (保护 rq 数据结构)
local_irq_disable();
rq_lock(rq, &rf);
// 更新就绪队列的时钟
update_rq_clock(rq);
prev_state = READ_ONCE(prev->__state);
// 3. 处理当前进程 (prev) 的状态
// 如果这是一次主动调度 (非抢占),且进程不在 TASK_RUNNING 状态 (即准备睡眠/阻塞)
if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
// 如果有挂起的信号,就不要睡眠了,强行拉回运行状态
if (signal_pending_state(prev_state, prev)) {
WRITE_ONCE(prev->__state, TASK_RUNNING);
} else {
// 否则,真正让它睡眠:将其从就绪队列中移除 (Dequeue)
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
}
}
// 4. 核心调度算法:从就绪队列中挑选下一个要运行的进程 (next)
next = pick_next_task(rq, prev, &rf);
// 清除当前进程的重新调度标志位 (TIF_NEED_RESCHED)
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
// 5. 执行上下文切换 (如果挑选出的 next 不是 prev 本身)
if (likely(prev != next)) {
// 指向新进程
RCU_INIT_POINTER(rq->curr, next);
// 真正执行硬件上下文和虚拟内存空间的切换!
// 注意:这个函数内部会顺便释放掉就绪队列的锁 (rq_unlock)
rq = context_switch(rq, prev, next, &rf);
} else {
// 如果选出来的还是当前进程 (没有发生实质切换),只需解锁并开启中断即可
raw_spin_rq_unlock_irq(rq);
}
}__schedule函数的核心主要有两部分,pick_next_task()和context_switch()
选择下一个进程 pick_next_task():
pick_next_task()函数首先判断当前CPU运行队列中的进程类型,若只有普通进程则直接通过CFS或idle调度类的快速路径选取下一个进程;否则,该函数会依次遍历所有的调度类(stop、deadline、实时、完全公平、空闲),直到成功选出一个适合运行的进程。
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
/*如果前一个进程的调度类是CFS完全公平调度类,
*并且该cpu整个运行队列中的进程数量 = cfs就绪队列中的进程数量
*则说明该cpu运行队列只有普通进程,无其他调度类进程;
*/
p = fair_sched_class.pick_next_task(rq, prev, rf);//通过cfs调度类的操作集进行pick_next_task
if (unlikely(p == RETRY_TASK))
goto again;//切换失败,重新遍历整个调度类
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);//通过idle调度类的操作集进行pick_next_task
return p;
}
again:
for_each_class(class) {//遍历所有调度类,
p = class->pick_next_task(rq, prev, rf);//依次用各个调度类中的pick_next_task
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;//选到了任务,则返回该任务,没选到则继续遍历
}
}
/*所有调度类中都没有选到任务,则说明出错了,
*因为即使是空闲类别(idle class)也应该有一个可运行的任务
*/
BUG();
}pick_next_task()函数其实由两部分组成
①:优化部分,若当前cpu就绪队列全是普通进程,则直接调用cfs或idle调度类中的pick_next_task()函数,从而省去繁琐的遍历部分; ②:遍历部分,若不满足优化条件,则依次遍历所有调度类(stop_sched_class、dl_sched_class、rt_sched_class、fair_sched _class、idle_sched_class)知道找到一个要切换的进程; 如果连idle进程都没有找到,则说明出现bug。 对于cfs完全公平调度器,其会调用pick_next_task_fair()函数,选择一个合适的进程用于调度
struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
...
// 简单路径:若没有使用组调度,或者 prev 不满足条件,则直接释放 prev 的调度实体
if (prev)
put_prev_task(rq, prev);
// 循环调用 pick_next_entity(),从最底层的 CFS 队列中选择实体,并依次向上找出最终的实体
do {
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
// 从最终选出的 sched_entity 获取对应的任务
p = task_of(se);
...
}
我们可以看出,核心是使用pick_next_entity()函数来选择一个调度实体;
上下文切换工作 context_switch():
上下文切换详细步骤:
在进入上下文切换流程时,首先在准备阶段调用prepare_task_switch保存当前任务状态和更新调度器数据,同时通过arch_start_context_switch启动体系结构相关的初始化;接下来,对于内核线程(即目标任务mm为空),系统通过enter_lazy_tlb让它借用前一个任务的active_mm进入懒惰TLB模式,并在必要时调用mmgrab_lazy_tlb增加引用计数以确保active_mm的有效性;而对于用户线程,调用switch_mm_irqs_off完成内存上下文的实际切换,并更新页表的LRU状态,同时处理从内核线程切换过来的情况(保存prev的active_mm);最后,调用switch_to切换寄存器状态和栈,最终由finish_task_switch完成收尾工作。
/*
* context_switch - 切换到新任务的内存管理(MM)以及新线程的寄存器状态。
*
* 该函数主要完成以下工作:
* 1. 做好上下文切换前的准备工作
* 2. 根据目标任务是否为内核线程(无 mm)或用户线程(有 mm),进行不同的内存管理切换操作
* 3. 更新内存管理相关的屏障和标识,保证切换后的内存一致性
* 4. 最后调用 switch_to() 切换寄存器状态和栈,并完成任务切换后收尾工作
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
/* 1. 上下文切换前的准备工作:
* 函数 prepare_task_switch() 用于保存当前任务状态、更新调度器相关数据等,
* 为后续的上下文切换做好必要准备。
*/
prepare_task_switch(rq, prev, next);
/*2. 判断是否是内核线程
*2.1内核线程: 使用prev 进程的活跃内存描述,并进入懒惰 TLB 模式
* 懒惰TLB的意思是,让内核线程在不立即刷新 TLB 的情况下,
* 能够正确使用前一个任务的内存映射。
* 这种方式能够避免每次切换时都进行昂贵的 TLB 刷新操作。
*2.2 用户线程: 首先通过 membarrier_switch_mm() 进行内存屏障切换,
* swicth_mm_irq_off 进行进程地址空间的切换
*/
if (!next->mm) {
/*2.1.1 内核线程:进入懒惰 TLB 模式,利用当前任务(prev)的 active_mm*/ // to kernel
enter_lazy_tlb(prev->active_mm, next);
/*2.1.2 如果下一个要执行的是内核线程,需要借用 prev 进程的活跃内存描述符 active_mm*/
next->active_mm = prev->active_mm;
/*2.1.3 对于用户线程切换到内核线程的情况,
* 调用 mmgrab_lazy_tlb() 增加 active_mm 的引用计数*/
if (prev->mm)
mmgrab_lazy_tlb(prev->active_mm);
else
/*2.1.4 对于内核线程切换到内核线程的情况,清空其 active_mm */
prev->active_mm = NULL;
} else {
/*2.2 用户线程切换:
* 首先通过 membarrier_switch_mm() 进行内存屏障切换,
* 再调用 switch_mm_irqs_off() 进行进程地址空间的实际切换。
*/
membarrier_switch_mm(rq, prev->active_mm, next->mm);
switch_mm_irqs_off(prev->active_mm, next->mm, next);
lru_gen_use_mm(next->mm);
if (!prev->mm) { /* 如果 prev 为内核线程(即从内核切换到用户线程),
则保存 prev 的 active_mm 到 rq->prev_mm,并清空 prev->active_mm */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
/*3. 新旧进程的切换点,所有进程在调度时的切换都在switch_to函数
* 切换到 next 进程的内核态栈 和 硬件上下文
*/
switch_to(prev, next, prev);
barrier();
/*4. 此处由next进程来执行finish_task_switch函数;
* 会递减mm_count,
* 将prev进程的on_cpu置为0,即prev进程完全下cpu,退出执行状态;
*/
return finish_task_switch(prev);
}
context_switch函数主要执行以下几个步骤:
-
保存当前进程(prev 进程)的上下文;
-
恢复某个先前被调度出去的进程(next进程)的上下文;
-
运行下一个进程 next进程;
context_switch函数的核心实现:
-
进程地址空间的切换,switch_mm()函数进行,主要切换next进程的页表到硬件页表中;
-
进程上下文切换(包括硬件和内核态栈栈部分),switch_to()函数进行,

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)