【论文学习】SCTS: Instance Segmentation of Single Cells Using a Transformer-Based Semantic-Aware Model a
SCTS: Instance Segmentation of Single Cells Using a Transformer-Based Semantic-Aware Model and Space-Filling Augmentation
2023年IEEE
SCTS:基于 Transformer 的语义感知模型与空间填充增强的单细胞实例分割
题目
单细胞实例分割
分类:
- 语义分割:给图像里的每个像素分类,只区分「细胞(前景)」和「背景」,不区分不同的细胞个体;
- 实例分割:在语义分类的基础上,给每个独立的单细胞分配唯一 ID,精准区分挨在一起的不同细胞,哪怕它们粘连、边界模糊
显微镜下的细胞图像,给实例分割带来了三大传统方法难以解决的难题
- 细胞密度高、紧密接触、边界模糊,极易把多个细胞合并成一个,出现粘连分割错误;
- 细胞信号弱、亮度不均,极易出现漏检、分割不完整的问题;
- 细胞大小、形状差异极大(从圆形的肿瘤细胞到细长的神经元细胞),传统模型适配性差;
- 额外痛点:单细胞标注成本极高,一张高密度图像可能有上千个细胞,人工标注需数小时,可用的标注训练数据极少
基于 Transformer
此前主流的细胞分割模型(如 Mask R-CNN、U-Net)都以 CNN(卷积神经网络)为核心,而 CNN 的卷积核尺寸有限,只能捕捉图像的局部特征,无法建模长距离的全局依赖。例如:面对细长的神经元细胞,CNN 看不到整个细胞的完整轮廓,极易出现分割断裂、形状识别错误,也很难适配不同大小、形态的细胞
论文采用Swin-Tiny Transformer作为模型的骨干网络,替代了传统的 ResNet 等 CNN 骨架:
- Transformer 的自注意力机制,能同时捕捉细胞的局部纹理细节和整张图像的全局上下文信息,完美适配不同大小、形状、纹理的细胞,解决了 CNN 的核心短板;
- 选用轻量的 Swin-Tiny 版本,在保证全局建模能力的同时,控制了模型参数量(仅 29M),远低于同期的 SOTA 模型,兼顾了精度与推理效率。
语义感知模型
面临困境:
- 没有给细胞边界单独建模,面对紧密接触的细胞,无法精准区分两个细胞的边界,极易把多个细胞合并成一个实例;
- 面对弱信号、低亮度的细胞,很容易把细胞的一部分误判为背景,出现分割残缺、漏检。
论文设计了一个背景 / 细胞内部 / 细胞边界的三分类语义分割分支,嵌入到 Transformer 主干中,给模型赋予了「语义感知能力」:
- 专门给「细胞边界」设置了独立的语义类别,并且在损失函数中给了 3 倍的权重,强制模型重点学习细胞边界的特征,哪怕边界模糊、细胞紧密接触,也能精准区分不同细胞的边界,解决粘连分割问题;
- 通过「细胞内部 / 背景」的语义区分,强化模型对弱信号细胞的识别能力,哪怕细胞亮度和背景接近,也能识别出完整的细胞轮廓,解决分割残缺、漏检问题;
- 分支输出的语义特征,会直接馈入下游的检测和分割头,给实例分割提供全局语义引导,进一步提升分割精度。
空间填充增强
传统的数据增强(旋转、翻转、亮度调整)都是对整张图像做变换,能增加的数据多样性非常有限,无法从根本上解决小数据集训练模型的过拟合问题。
论文设计了一套专门针对单细胞场景的、无需额外标注的在线数据增强方法,分为两步:
- 构建单细胞实例库:从已标注的训练图像中,把单个细胞连同它的标注掩码一起裁剪出来,背景像素置零,形成一个可复用的单细胞库;
- 在线空间填充:每一轮训练时,随机从库中挑选细胞,做旋转、随机亮度变换等处理后,把细胞填充到训练图像的空白背景区域(确保和原图已有细胞无重叠),在线生成全新的训练样本。
摘要
从显微镜图像中实现单细胞实例分割,对疾病诊断、药物筛选等诸多重要生物医学应用中,细胞空间与形态学特征的定量分析至关重要。然而,细胞密度高、接触紧密、边界模糊的特点,给这项任务带来了巨大的技术挑战。为攻克上述难题,我们开发了一种全新的实例分割模型,命名为单细胞 Transformer 分割器(Single-cell Transformer Segmenter,SCTS)。
该模型以 Swin Transformer 为骨干网络,融合了 Transformer 的全局建模能力与卷积神经网络(CNN)的局部建模能力,确保模型能够适配不同尺寸、形状与纹理特征的细胞。模型还嵌入了一个三分类(背景、细胞内部、细胞边界)语义分割分支,用于实现像素分类,并为下游任务提供语义特征。其中,边界语义的预测提升了模型的边界感知能力,前景与背景的语义区分则增强了模型在弱信号区域的分割完整性。
为降低模型对标注训练数据的依赖,我们还开发了一种数据增强策略,可将单细胞实例随机填充至训练图像的空白区域。实验结果表明,在 LIVECell 数据集与自研数据集上,我们的模型性能均优于多款当前主流的最优(SOTA)模型。本研究的代码与数据集已开源,可通过以下链接获取:https://github.com/cbmi-group/SCTS。
引言
通过实例分割从显微镜图像中提取单细胞,对于疾病诊断、药物筛选等重要应用场景下,生物医学样本的单细胞水平分析至关重要 [2,26,34]。在实例分割任务中,不仅需要将图像像素划分至不同的语义类别,还需将像素归类到各个独立的实例中。这是一项极具挑战的任务,因为组织或培养体系中的细胞往往存在密度高、接触紧密、边界模糊的问题。
U-Net [31] 等早期模型在细胞图像的语义分割任务中取得了优异的性能,但无法区分单个细胞。为解决这一问题,学界已将语义分割与各类后处理策略相结合,开发出多种实例分割方法 [33,4,36]。这些方法原理直观,对不同尺寸、形状的细胞具备良好的适配性,但并非完全端到端的训练模式,其性能也受限于后处理操作;同时,由于每个像素只能分配一个实例标签,这类方法无法处理存在重叠的细胞。
Mask R-CNN [15] 是一种两阶段实例分割网络,它首先通过区域候选网络(Region Proposal Network, RPN)[29] 生成一系列候选框,再对候选框执行分类与坐标回归。该模型能够处理图像中存在目标重叠的分割场景,但如图 1 所示,在细胞紧密接触的区域,它往往会出现边界预测错误的问题,在弱信号区域则易生成不完整的分割掩码。混合任务级联网络(Hybrid Task Cascade, HTC)[6] 是基于 Mask R-CNN 的改进模型,它引入了语义分割分支来区分真实前景与杂乱背景,有助于补全弱信号区域的漏检目标,但也带来了副作用 —— 易将紧密接触的不同细胞合并为同一个实例。
总体而言,U-Net、Mask R-CNN 等卷积神经网络(Convolutional Neural Networks, CNNs)被广泛应用于视觉任务,并取得了出色的效果。但受限于卷积核尺寸,这类网络难以捕捉长距离依赖关系,这一缺陷进而导致下游任务难以适配细胞形状、尺寸与纹理的变化。而 Transformer 架构为解决上述不足提供了有效方案 [24]。本研究受上述模型启发,提出了一种基于 Transformer 的语义感知架构,用于实现全端到端的单细胞实例分割,解决了单细胞实例分割中的多个核心问题。第一,细胞的尺寸、形状存在极大差异,CNNs 难以应对这种变化,为此我们引入 Swin Transformer [24] 作为骨干网络,它能有效捕捉全局信息与长距离依赖关系,更好地适配细胞形状与尺寸的变化。第二,在细胞高密度场景下,现有方法难以精准识别细胞边界,为此我们嵌入了一个三分类语义分支,区分背景、细胞边界与细胞内部,更好地对紧密接触的细胞进行分割。第三,显微镜图像的人工标注始终存在耗时长、工作量大的问题,为此我们提出了一种新的策略,实现小规模数据集的增强。综上,本研究的核心贡献如下:
- 我们开发了一种全新的单细胞实例分割模型。为保证模型对细胞尺寸、形状、纹理变化的适配性,该模型采用 Swin Transformer 作为骨干网络,同时对全局特征与局部特征进行建模。
- 我们提出在 Transformer 骨干网络中嵌入三分类语义分支,以有效捕捉语义信息。其中,边界语义的预测提升了模型对细胞边界的区分能力,前景与背景的语义预测则增强了模型在弱信号区域的分割完整性。
- 我们开发了一种名为 “空间填充(space-filling)” 的新型数据增强策略,通过将细胞实例随机填充至图像的无目标背景区域,有效且大幅扩充了训练图像的数量。
图一
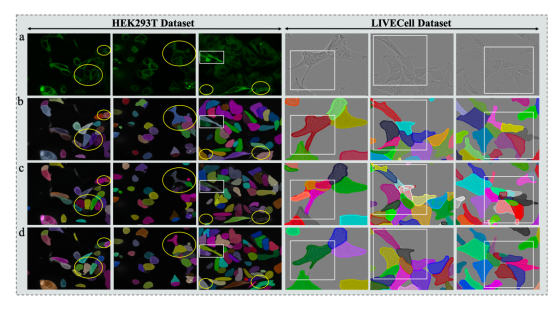
图 1 Mask R-CNN 与本研究开发的 SCTS 模型的性能对比
(a) 原始图像;(b) 金标准标注;(c) Mask R-CNN 的预测结果;(d) SCTS 的预测结果。
椭圆圈注处突出显示了弱信号区域的预测结果,白色矩形框则标注了细胞紧密接触、边界弥散场景下的边界预测效果。
相关工作
单细胞实例分割
单通道显微镜图像的语义分割,是将图像像素划分为前景、背景两个语义类别。全卷积网络(Fully Convolutional Networks, FCN)[25] 是早期的语义分割模型之一,它采用全卷积神经网络架构,大幅提升了语义分割的精度。但由于未考虑上下文信息,其分割结果往往存在细节表现力不足的问题。Ronneberger 等人在 FCN 的基础上提出了 U-Net,该模型采用 U 型编码器 - 解码器架构,通过跳跃连接融合低分辨率与高分辨率信息。U-Net 在医学图像分割任务中取得了优异的性能,现已成为被广泛使用的基线模型。尽管如此,其架构设计并非面向单细胞实例分割任务。
已有多项研究通过引入后处理操作,将语义分割拓展至实例分割 [1,4,14,30,33,36]。例如,Greenwald 等人提出了名为 Mesmer [14] 的方法,将实例分割拆解为两个像素级预测任务:第一个任务预测像素属于细胞内部、细胞边界还是图像背景;第二个任务预测细胞内每个像素到细胞质心的距离;最终对预测结果执行分水岭分割算法,以分离不同的细胞实例。这类方法原理直观、可解释性强,但其分割精度受限于后处理策略,且无法处理存在重叠的细胞。
受益于 R-CNN [13] 及其变体 [3,12,29]、YOLO [28]、SSD [23] 等检测模型的发展,另一类主流的实例分割策略是结合检测与分割的两阶段方法,代表方法包括 FCIS [19]、Mask R-CNN、MaskLab [8]、Mask Scoring RCNN [17]、HTC [6] 与 PointRend [18]。这类方法首先通过卷积层提取感兴趣区域(Region of Interest, ROI),再对每个 ROI 执行分割与分类。它们能够处理存在目标重叠的场景,但对于细胞图像中常见的紧密接触、边界弥散、弱信号区域,分割效果较差。
也有研究将像素级分类任务转化为像素级回归任务,以实现实例分割 [27,32,35,38,39,40]。例如,Stardist 方法 [32] 将实例分割任务,转化为对图像目标轮廓上固定数量点的预测问题。该方法为每个像素预测其所属的目标类别概率,以及通过径向距离参数化的星形凸多边形,以此实现细胞实例的捕捉。MultiStar [35] 与 SplineDist [27] 均是基于 Stardist 方法的扩展模型。但受限于模型表征能力,这类方法对非凸目标的分割性能较差。
视觉 Transformer
尽管基于 CNN 的细胞实例分割方法已取得诸多成果,但受限于卷积核尺寸,CNN 难以捕捉长距离依赖关系与全局上下文信息。近年来,基于 Transformer 的方法在分类、检测、分割等众多视觉任务中均取得了优异的性能。检测 Transformer(DEtection Transformer, DETR)[5] 是首个基于 Transformer 的端到端目标检测模型,它将目标检测任务视为一个集合预测问题,省去了非极大值抑制、锚框生成等诸多人工设计的操作,取得了与 Faster R-CNN 相当的精度与推理速度。
视觉 Transformer(Vision Transformer, ViT)[10] 将纯 Transformer 架构应用于图像块序列,在图像分类任务中取得了极具潜力的效果。Swin Transformer 解决了 Transformer 从文本领域迁移至图像领域时,面临的图像分辨率高、尺度变化大的问题,它通过构建分层特征,将 Transformer 拓展至像素级密集预测任务。Swin Transformer 在多项视觉任务中的优异表现,证明了其作为视觉任务通用骨干网络的潜力。在本研究开发的实例分割模型中,我们采用 Swin Transformer 作为骨干网络,以捕捉长距离依赖关系与全局上下文信息,这对于模型适配不同尺寸、形状与纹理的细胞至关重要。
方法
图二
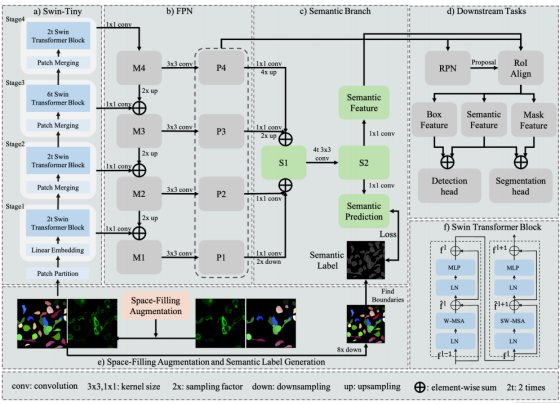
图 2:所提模型的整体架构
(a) Swin-Tiny 主干网络(b) 特征金字塔网络(FPN)(c) 三分类语义分割分支(d) 下游检测与分割任务(e) 空间填充增强策略及语义标签生成流程(f) Swin Transformer 模块的详细结构
数据输入→特征提取→语义增强→实例分割输出
数据预处理(e 区):做数据扩充 + 生成语义标签
特征提取(a+b 区):用 Swin Transformer+FPN 提取多尺度特征
语义增强(c 区):额外学习边界 / 细胞 / 背景的语义信息
最终分割(d 区):用两阶段流程输出单细胞实例分割结果
模块细节(f 区):Swin Transformer 核心组件的内部结构
模块 e(空间填充增强 + 语义标签生成)是模型的数据输入与标签准备环节
输入:最左侧两张图(左:彩色细胞实例标注图,不同颜色代表不同细胞;右:原始荧光显微镜图像,绿色是细胞信号)
空间填充增强:按照论文方法,从标注中抠出单个细胞实例,随机旋转、调整亮度后,填充到原图的空白区域,在线扩充训练数据,解决生物医学图像标注成本高、数据少的问题,输出增强后的图像(中间两张)
语义标签生成:把增强后的实例标注图8 倍下采样,匹配语义分支的输出尺寸;用边界检测算法,把标注图分成三类:背景(黑色)、细胞内部(彩色区域)、细胞边界(单像素白色边缘),生成三分类语义标签(最右侧黑白图)
模块 a(Swin-Tiny 主干网络)是模型的特征提取器,替代了 Mask R-CNN 原本的 ResNet
输入:经过空间填充增强后的原始显微镜图像
流程:
- Patch Partition(分块):把图像切成 4×4 的无重叠小块,将图像转为序列特征
- Linear Embedding(线性嵌入):把小块特征映射到高维特征空间
- 4 个 Stage(阶段 1~4):每个 Stage 包含 Swin Transformer Block + Patch Merging(下采样),逐步提取从低维(细节纹理)到高维(全局语义)的分层特征
输出:4 个不同尺度的分层特征,输入到 b 区的 FPN
核心作用:用 Transformer 的自注意力捕捉长距离依赖,让模型更好地适配细胞的大小、形状、纹理变化
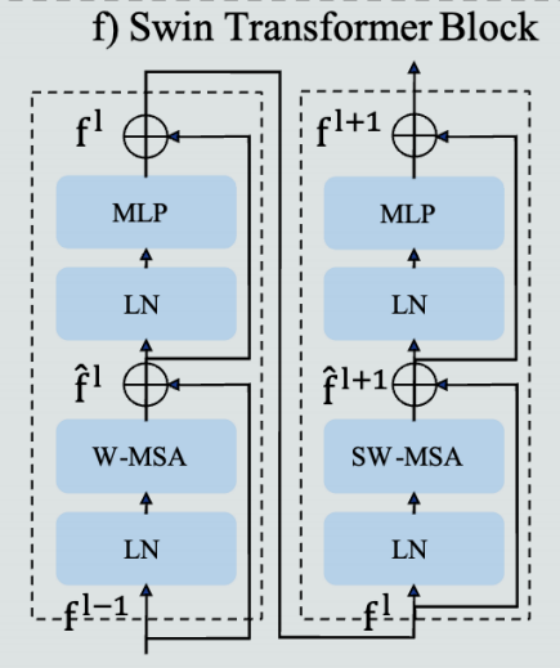
模块 f(Swin Transformer 模块细节)是 a 区 Swin-Tiny 的核心组件,展示了 Transformer Block 的内部结构
两个连续的 Block:左为W-MSA(窗口多头自注意力)Block,右为SW-MSA(滑动窗口多头自注意力)Block
每个 Block 的结构:层归一化(LN) → 自注意力 → 残差连接 → 层归一化(LN) → 多层感知机(MLP) → 残差连接
核心作用:用窗口自注意力平衡计算效率和全局建模能力,让模型能捕捉细胞的长距离上下文信息
模块 b(特征金字塔网络)是 Mask R-CNN 的经典模块,用来融合多尺度特征,兼顾细节和全局信息
输入:a 区 Swin-Tiny 输出的 4 个 Stage 的特征
流程:
- 每个 Stage 的特征先经过1×1卷积调整通道数,得到 M1~M4
- 高层特征做 2 倍上采样,和低层特征做逐元素相加,融合高低层特征
- 融合后的特征再经过3×3卷积,得到 P1~P4 四个尺度的特征金字塔
输出:P1~P4 多尺度特征,同时输入到 c 区语义分支和 d 区下游任务
模块 c(三分类语义分割分支)是 SCTS 的核心创新之一,专门解决 Mask R-CNN 边界不准、弱信号分割不全的问题
输入:b 区 FPN 输出的 P1~P4 多尺度特征
流程:
- 把不同尺度的特征(P1~P4)通过上采样 / 下采样统一到相同尺寸,逐元素相加得到 S1
- S1 经过 4 层 3×3 卷积提取特征,得到 S2
- S2 分两路:
- 一路:生成Semantic Prediction(语义预测),和 e 区的三分类标签计算加权交叉熵损失,监督语义分支训练
- 另一路:生成Semantic Feature(语义特征),输入到 d 区下游任务,给检测和分割分支补充边界、细胞内部的语义信息
核心作用:给模型额外学习「背景 / 细胞内部 / 细胞边界」的语义,强化边界感知,让紧密接触的细胞不被误合并,弱信号区域分割更完整
模块 d(下游检测与分割任务)是模型的最终预测头,输出单细胞实例分割结果
输入:b 区 FPN 的多尺度特征 + c 区语义分支的语义特征
两阶段流程:
- 第一阶段(粗找细胞位置):
- 特征输入RPN(区域提议网络),快速生成一堆「候选目标边界框」,锁定细胞的大致位置
- 用RoI Align从候选框里精准提取对应区域的特征(ROI),避免特征扭曲
- 第二阶段(精修 + 分割):
- 框特征 + 语义特征 → 输入Detection head(检测头):完成「分类(判断是不是细胞)+ 边界框回归(修正候选框,更贴合细胞边缘)」
- 掩码特征 + 语义特征 → 输入Segmentation head(分割头):完成「二值分割(抠出每个细胞的像素级轮廓)」
输出:最终的单细胞实例分割结果(每个细胞的边界框 + 分割掩码)
架构总览
本文提出的实例分割模型是对两阶段实例分割模型Mask R-CNN的改进。在第一阶段,Mask R-CNN 通过区域提议网络(RPN)生成一系列候选目标边界框;在第二阶段,Mask R-CNN 通过感兴趣区域对齐(RoIAlign)从每个候选框中提取感兴趣区域(ROI),再由检测头对 ROI 完成分类与边界框回归,由分割头对 ROI 执行二值分割(图 2d)。
- Mask R-CNN 做细胞实例分割
先粗找、再精修
RPN(区域提议网络):相当于在显微镜图片里快速扫一遍,不用精准区分每个细胞
作用:先锁定细胞的大致位置,缩小后续处理范围
RoIAlign(感兴趣区域对齐)把第一阶段找到的候选框,精准裁剪出框内的图像区域,保证细胞特征不扭曲、不偏移,提取出ROI(就是框里的细胞区域)
检测头两件事:① 判定这个区域是不是细胞(分类);② 把粗糙的候选框修得更贴合细胞边缘(边界框回归)
分割头对修好的区域做二值分割:用像素级标注,分出哪些是细胞(前景)、哪些是背景,画出细胞的完整轮廓掩码
图 2 展示了本文所提模型的整体架构。与 Mask R-CNN 相比,本模型的核心改进点如下:
(a) 采用Swin Transformer替代 ResNet [16] 作为主干网络,让模型能适配细胞的尺寸、形状与纹理差异(图 2a,3.3 节);
(b) 嵌入语义分割分支,区分背景、细胞内部、细胞边界三类目标,提升下游任务的边界感知能力与前景分割完整性(图 2c,3.4 节);
(c) 每批次训练前,采用下文所述的空间填充增强策略,将单细胞实例随机填充至训练图像的空白区域,完成训练图像的在线增强(图 2e,3.2 节)。
空间填充增强策略
实际应用中,带标注的生物医学图像数量有限,且标注成本高昂。为充分利用现有标注训练数据、提升训练图像的多样性,本文设计了一种全新的数据增强策略,命名为空间填充(Space-Filling)。其流程如图 3 所示,分为数据库构建与空间填充两个步骤。
图三
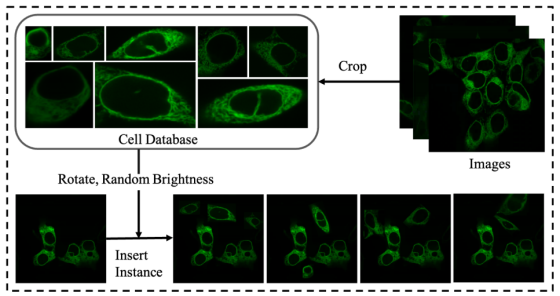
图3:使用空间填充策略的数据增强工作流程。
第一步:从原始图像中「抠出」单细胞,构建细胞库(Cell Database)
数据库构建阶段:依据实例的边界框标注与分割标注,裁剪出细胞实例区域图像,并将背景像素置零,避免实例间相互重叠,最终汇总所有实例图像构建细胞实例库。
第二步:给单细胞做「随机变形」,模拟真实多样性
第三步:把变形后的细胞「插入」到训练图中,生成全新样本
空间填充阶段:先从细胞实例库中随机选取指定数量的细胞实例,再通过旋转、随机图像亮度变换等方式对实例做形态变换;最后将单个细胞实例的前景叠加到训练图像的空白区域(确保训练图像目标与插入实例目标的二值掩码无交集)。
该增强操作在训练过程中在线执行,即便同一张训练图像,每批次的处理结果也各不相同,能有效提升训练图像多样性,降低对人工标注数据的依赖。
Swin Transformer 主干网络
Swin Transformer 包含四个版本:Swin-Tiny、Swin-Small、Swin-Base、Swin-Large,后一版本的模型规模与计算量均为前一版本的两倍。本文选用Swin-Tiny版本,其整体架构如图 2a 所示。
该主干网络包含四个阶段,阶段 1 至阶段 4 的 Swin Transformer 模块数量依次为 2、2、6、2。输入图像先通过分块操作划分为无重叠的图像块,本文设置分块尺寸为 4×4;对于 RGB 图像,每个图像块的维度为 4×4×3。随后通过线性嵌入层将原始特征映射为任意维度,再经多个 Swin Transformer 模块处理,并通过块融合层将 2×2 相邻块的特征拼接,实现下采样。阶段 2、3、4 采用相同构建方式,各阶段输出融合为分层特征表示。
Swin Transformer 模块
图 2f 展示了 Swin Transformer 模块的详细结构:MLP 为多层感知机模块,LN 为层归一化模块,W-MSA 为窗口多头自注意力模块,SW-MSA 为滑动窗口多头自注意力模块;f^l为第l个模块的(滑动)窗口多头自注意力输出特征,fl为第l个模块的多层感知机输出特征。Swin Transformer 模块的计算可由以下公式组概括:
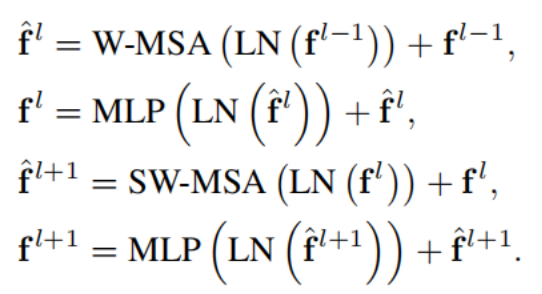
MLP 为多层感知机模块,简单的全连接神经网络,给特征做非线性变换,增强模型表达能力
LN 为层归一化模块,给每一层的特征做标准化,稳定训练过程,防止梯度消失 / 爆炸,加速收敛
W-MSA 为窗口多头自注意力模块,把特征图分成不重叠的小窗口,只在窗口内做自注意力,大幅降低计算量,提取局部特征
SW-MSA 为滑动窗口多头自注意力模块,把窗口整体平移半个窗口大小,让相邻窗口产生交互,弥补 W-MSA 的窗口隔离问题,实现全局感受野

残差连接,把输入直接加到输出上,解决深度网络梯度消失问题,让深层网络能稳定训练
Swin Transformer Block 是成对出现的:1 个 W-MSA Block + 1 个 SW-MSA Block
这个模块是模型总架构图(Figure 2a)中 Swin-Tiny 主干网络的基本单元:
- Stage1 有 2 个 Block、Stage2 有 2 个、Stage3 有 6 个、Stage4 有 2 个,所有 Block 都遵循这组公式计算,成对的 W-MSA+SW-MSA Block,最终输出分层特征,输入 FPN 做后续处理。
语义分割分支
图 1 表明,使用 Mask R-CNN 做实例分割时,弱信号区域易出现分割残缺、细胞紧密接触区域易出现边界预测偏差的问题。受混合任务级联(HTC)启发,本文设计了包含背景、细胞内部、细胞边界三类标签的语义分割分支,解决上述问题。
HTC 是 2019 年 CVPR 提出的实例分割 SOTA 模型,全称Hybrid Task Cascade(混合任务级联)
Mask R-CNN 是单阶段检测 + 并行分割的结构:检测头和分割头是独立的,分割只依赖 RoI(候选框)内的局部特征,没有全局上下文信息,导致:边界预测不准、弱信号区域分割残缺、密集粘连目标(比如细胞)容易误合并,在细胞这种高难度场景下问题被放大。
HTC 的核心思路就是:把检测、分割、语义分割三个任务融合成一个级联式的闭环,让多任务互相辅助,同时用全局语义信息补充分割的边界感知
语义标签生成
语义标签生成流程如图 2e 所示:先对输入图像执行空间填充增强,再依据分割标注为每个实例分配不同像素值生成掩码;随后对掩码下采样,使其尺寸与语义预测结果匹配,便于损失计算;最后通过 scikit-image 库的边界检测函数,生成细胞边界、细胞内部、背景三类语义标签。
具体规则为:细胞边界为单像素宽边缘,细胞内部为除单像素边界外的前景像素,其余像素归为背景。
用 scikit-image 的函数,把这张图切成三部分:细胞边界:单像素宽边缘,用函数自动找出细胞的轮廓线,这条线必须只有 1 个像素那么细;细胞内部:除了边界的细胞区域,把刚才的单像素边界去掉,细胞掩码里,剩下的所有实心区域;剩下的所有区域,整张图里,既不是边界、也不是细胞内部的像素
语义分割损失
语义分割分支采用加权交叉熵损失函数,公式如下:
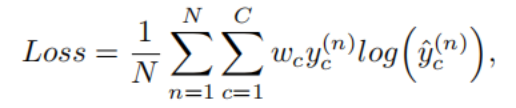
其中,N为样本数量,C为语义类别数,wc为第c类的损失权重;yc(n)为符号函数,样本n真实类别为c时取值为 1,否则为 0;y^c(n)为样本n属于第c类的预测概率。
语义分割分支使用的「加权交叉熵损失函数」:衡量模型对「背景 / 细胞内部 / 细胞边界」三分类的预测结果,和真实标签之间的差距;通过给不同类别加差异化权重,解决细胞分割中类别极度不平衡的问题,强制模型重点学习细胞边界
N为样本数量,语义分割是像素级分类,这里的「样本」就是一张图里的所有像素,N = 图像总像素数
C为语义类别数,3 类:背景、细胞内部、细胞边界,因此 C=3
wc为第c类的损失权重,给每个类别分配的「惩罚系数」: 背景、细胞内部:权重小;细胞边界:权重大,权重越大,模型预测错该类的惩罚越重
yc(n)为符号函数,样本n真实类别为c时取值为 1,否则为 0
y^c(n)为样本n属于第c类的预测概率
把所有像素的损失加总后,除以总像素数,让损失大小和图像尺寸无关,方便训练
这个损失是专门给 语义分割分支(图 2c) 设计的:用 e 区生成的三分类语义标签(背景 / 内部 / 边界)作为监督;计算损失后反向传播,优化语义分支的参数,让语义分支精准输出边界、内部、背景的特征;语义分支的特征会融合到下游的检测头、分割头(图 2d)
本文为不同语义类别分配差异化损失权重以平衡各类别损失,消融实验探究了细胞边界类不同权重的影响,详见 4.6 节。
语义分割网络结构
语义分割分支的网络结构如图 2c 所示:特征金字塔网络(FPN)的各层特征经 1×1 卷积与逐元素求和后,下采样至同一尺寸;再经四层 3×3 卷积提取特征,随后分为两个分支:一个分支计算预测结果与语义标签的交叉熵损失,另一个分支将特征融入后续的检测与分割分支。
实验
实验数据集
LIVECell 是一个大规模公开数据集,包含5239 张相差显微镜图像,涵盖8 种细胞类型,共计1686352 个细胞实例 [11]。为保证性能对比的一致性,本文按照文献 [11] 的划分方式,将数据集分为3188 张训练图、539 张验证图与1512 张测试图。
相差显微镜图像是生物实验室拍活细胞最常用的照片类型。
细胞是透明的,普通相机看不清;相差显微镜不用给细胞染色、不杀死细胞,就能拍出清晰的细胞轮廓、形态、边缘
LIVECell 数据集的图像有两个显著特点:第一,细胞密度差异极大,图像覆盖细胞从初始接种到完全融合成单层的生长全过程(图 4a);在细胞完全融合的情况下,一张尺寸为 704×520 的 LIVECell 图像可包含超过 3000 个细胞实例,即便人眼也难以精准识别细胞边界。第二,数据集中细胞的大小与形态丰富多样(图 4b),包括小而圆的 BV-2 细胞、大而扁平的 SK-OV-3 细胞,以及细长型的 SH-SY5Y 细胞。细胞的高密度与形态多样性,对算法设计提出了极大挑战。
图四
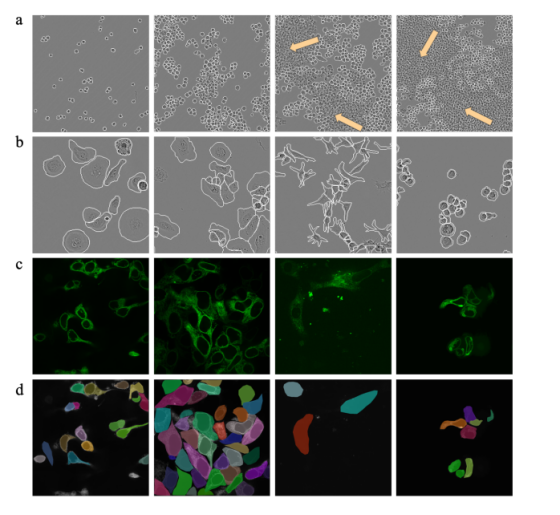
图 4:LIVECell 数据集与 HEK293T 数据集的样本示例
(a) LIVECell 数据集中不同细胞密度的图像示例。浅棕色箭头所指区域因细胞密度过高未进行标注。
(b) LIVECell 数据集中不同细胞类型的示例。从左至右依次为:SKOV3 细胞、Huh7 细胞、SHSY5Y 细胞、BT474 细胞。(a)、(b) 中的白色轮廓仅为可视化绘制。
(c) HEK293T 数据集的图像示例。
(d) HEK293T 数据集图像对应的标注结果。由图像与标注可见,HEK293T 数据集的图像亮度分布不均,存在大量弱信号区域。
HEK293T 是自研的小规模数据集,采用共聚焦显微镜拍摄 HEK293T 细胞。该数据集划分为108 张训练图与37 张测试图,包含 2012 个训练实例与 576 个测试实例。其特点是细胞亮度分布不均,且存在部分弱信号区域(图 4c–d)。训练前,先通过旋转、翻转、模糊、亮度变换将数据集扩充至 3240 张训练图;训练过程中,再通过空间填充策略进行在线数据增强。
性能评估指标
本文采用 COCO 标准评估指标AP(平均精度),该指标是交并比(IoU)从 0.5 到 0.95、以 0.05 为间隔取均值的结果 [22]。具体而言:
- APbbox:细胞检测的平均精度
- APsegm:细胞实例分割的平均精度
- AP0.5、AP0.75:分别为 IoU 阈值取 0.5、0.75 时的平均精度
实现细节
本文基于 PyTorch 框架实现网络模型,采用在 ImageNet-22K 数据集上预训练的Swin-Tiny作为主干网络。模型使用AdamW 优化器训练,学习率设为 0.0001,权重衰减系数为 0.05。
针对语义分割分支,采用预测结果与真实标签间的交叉熵损失函数,并将背景、细胞内部、细胞边界三类的损失权重分别设为1、1、3。
对于 LIVECell 数据集,本文沿用文献 [11] 的实验设置:训练时批次大小设为 16(每张 GPU 分配 2 个样本),将图像短边尺寸设为 (440, 480, 520, 580, 620),网络会随机选取一个短边尺寸,并按相同比例调整长边尺寸。由于该数据集标注量充足,未使用空间填充增强。所有模型均训练约 140 轮。
批次大小(batch size)16,一次同时喂 16 张细胞图给 AI。每张 GPU 分 2 个:用了8 张显卡一起跑
图片随机缩放(一种数据增强):不固定图片大小,每次训练随机选一个短边长度(比如 440、520),长边按相同比例跟着变,保证细胞不被压扁 / 拉变形;目的:让模型适配不同大小、不同分辨率的细胞图,不会只认固定尺寸的细胞
对于 HEK293T 数据集,保持图像分辨率为 1200×1200,通过空间填充策略在线扩充数据,模型共训练 36 轮,批次大小为 32。
HEK293T 数据集实验结果
表 1 对比了本文模型与 Mask R-CNN、级联 Mask R-CNN、PointRend [18]、MViTv2 [20]、混合任务级联(HTC)等主流实例分割模型的性能,所有结果均基于 MMDetection [7] 复现。
表一
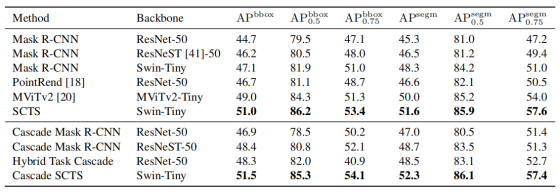
表 1:不同实例分割模型在 HEK293T 数据集上的性能对比
在无级联结构的情况下,本文方法相比性能最优的 MViTv2 模型,APbbox提升 2.0%,APsegm提升 1.6%;在 IoU=0.75 的分割精度上提升最为显著,相比基于 ResNet-50 主干的 Mask R-CNN,APsegm提升 10.4%,证明本文模型能生成高质量分割结果。
在加入级联策略后,本文方法相比性能最优的基于 ResNeST [41]-50 主干的级联 Mask R-CNN,APbbox提升 3.1%,APsegm提升 3.6%。
图 5a 为本文模型与对比模型的定性对比结果:Mask R-CNN、PointRend、MViTv2 因缺少语义信息,在弱信号区域易出现漏检与分割残缺的问题;HTC 通过融合前景与背景语义分支,缓解了弱信号区域分割残缺的问题,但会将紧密接触的细胞误合并为一个实例。本文模型充分利用上下文语义与边界信息,在弱信号区域与细胞紧密接触区域均表现优异。
图五

图 5:HEK293T 数据集与 LIVECell 数据集上的定性结果
(a) 本文方法与对比模型在 HEK293T 数据集上的定性结果
(b) 本文方法与对比模型在 LIVECell 数据集上的定性结果
MRCNN:Mask R-CNN,GT:真实标注(金标准)
椭圆标注弱信号区域的预测结果;白色矩形框标注细胞紧密接触与边界模糊区域的边界预测结果;红色矩形框标注将紧密接触的细胞误合并为同一实例的预测区域。
LIVECell 数据集实验结果
表 2 对比了本文模型与上述模型在 LIVECell 数据集上的性能:级联 Mask R-CNN 的分割结果沿用文献 [11] 基于 ResNeSt-200-DCN [9] 主干的设置,其余模型均基于 detectron2 [37] 复现。
表二
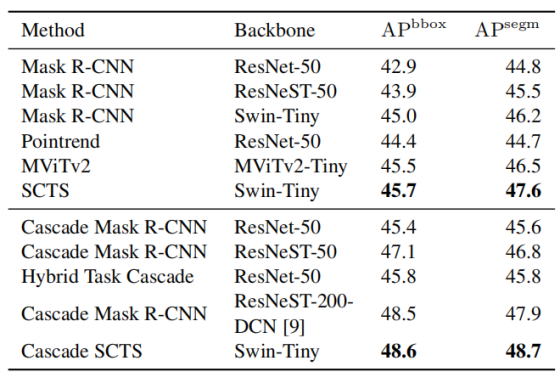
表 2:不同实例分割模型在 LIVECell 测试集上的性能对比
无级联结构时,本文方法相比性能最优的 MViTv2 模型,APsegm提升 1.1%;加入级联策略后,本文模型的检测精度 APbbox与最优模型持平,分割精度 APsegm相比基于 ResNeSt-200-DCN 主干的级联 Mask R-CNN提升 0.8%,且参数量(29M vs. 70M)与计算量(4.5G vs. 17.5G)更低。
图 5b 为定性对比结果:第 1、2 行结果显示,对于细长型细胞,Mask R-CNN、HTC、PointRend 难以捕捉长距离依赖关系,而本文模型与基于 Transformer 的 MViTv2 可精准预测,证明 Swin Transformer 主干能让模型适配不同细胞的形态与尺寸;第 3、4 行结果显示,本文模型在细胞紧密接触区域的预测效果优于对比模型,证明边界语义标签预测能帮助模型区分粘连细胞。
消融实验
网络组件有效性:首先在 HEK293T 数据集上验证各网络组件及组合的贡献,结果如表 3 所示,每个组件均能带来性能提升,组件组合后精度最优。表 4 在 LIVECell 数据集上验证了各组件的效果,提升趋势与 HEK293T 数据集一致,证明各组件及其组合的有效性。
表三
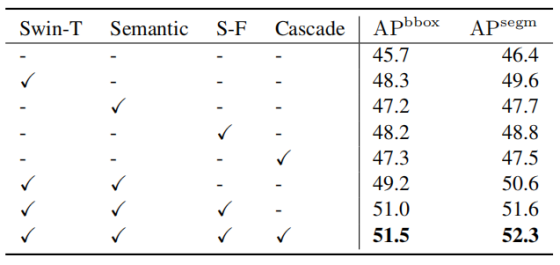
表 3:网络组件在 HEK293T 数据集上的效果消融实验
Swin-T:Swin-Tiny 主干网络;Semantic:语义分支;S-F:空间填充增强;Cascade:网络级联结构
表四
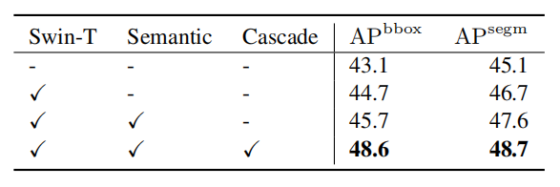
表 4:网络组件在 LIVECell 测试集上的效果消融实验
语义分割交叉熵损失权重的影响:针对加权交叉熵损失,本文探究不同语义类别权重对模型性能的影响。基于无级联结构的 SCTS,将背景与细胞内部的损失权重固定为 1,分别测试细胞边界损失权重取 1~5 时的性能(图 6a)。结果显示,边界损失权重为3时,APbbox与 APsegm均达到最优。本文在 LIVECell 验证集上开展相同实验(表 5),得到与 HEK293T 数据集一致的结果,因此将边界类的损失权重设为另外两类的 3 倍。
级联版(加了 Cascade 结构)的 d 区流程(多阶段迭代):把图 d 区的「RPN→RoIAlign→检测头→分割头」整个流程,重复 3 次(多阶段),前一次的输出作为后一次的输入,每个阶段都融合语义分支的特征,就是完整的级联结构
图六
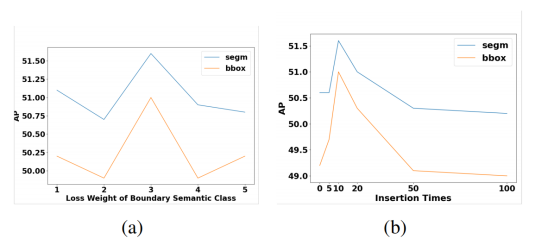
图 6:HEK293T 数据集上,语义分割交叉熵损失权重与不同实例插入数量的消融实验
(a) 语义分割损失权重的影响
(b) 不同实例插入数量的影响
表五
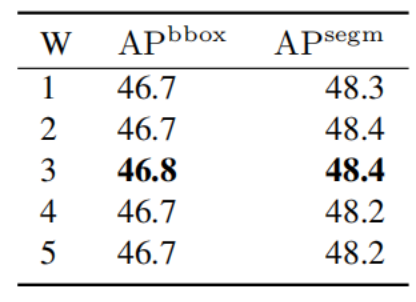
表 5:边界语义类别损失权重对 LIVECell 验证集的影响
W:边界语义类的权重
实例插入数量的影响:基于 HEK293T 数据集,探究空间填充策略中不同实例插入数量的影响。采用无级联结构的语义分支模型,分别测试插入 0、5、10、20、50、100 个实例的性能(图 6b)。结果显示,性能随插入数量增加先上升后下降,原因是插入数量过多会导致训练集与测试集的数据分布差异变大。插入数量为10时,检测与分割性能最优。
实例插入:在图像数据集中加入更多经过处理的样本,目的是让模型在训练时能适应更多情况,提高泛化能力
综上,实际应用中实例插入数量需依据训练集与测试集的分布设定;对于 HEK293T 数据集,因训练集与测试集分布相近,仅需少量插入即可。
结论
本文提出了SCTS 模型,一种以 Swin Transformer 为主干、嵌入三分类语义特征的单细胞实例分割新模型;同时提出空间填充数据增强策略,提升训练图像的多样性。实验结果表明,本文模型在 LIVECell 公开数据集与自研数据集上的性能均优于多种当前最优模型。
本文模型仍存在一定局限性,相关讨论已在补充材料中阐述;未来将针对超高密度细胞的分割问题展开进一步研究。
致谢
本研究部分得到国家自然科学基金(项目编号:31971289、91954201,负责人:G.Y.)与中国科学院战略性先导科技专项(项目编号:XDB37040402,负责人:G.Y.)的资助。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)