众智FlagOS 2.0正式发布:32款AI芯片、497算子、Skills专业技能库首发
2026年3月27日,在2026中关村论坛上,北京智源人工智能研究院副院长兼总工程师林咏华代表众智 FlagOS 社区正式发布众智 FlagOS 2.0,这是面向多种 AI 芯片的统一开源系统软件栈的重大版本升级。FlagOS 2.0 全面拥抱智能体时代,将支持范围从大模型训推扩展到具身智能与科学计算,并为大模型性能提升正式发布 Triton-TLE 编程语言、AI 算子自动生成平台 KernelGen 2.0、FlagOS Skills 1.0 智能体技能库等多项创新成果。FlagOS 2.0 版本由北京智源研究院、中科加禾、中科院计算所、澎峰科技、清程极智、清华大学、北京大学、中科院软件所、硅基流动、先进编译实验室、华为、清微智能、海光信息、中电信人工智能公司、北京邮电大学、摩尔线程、沐曦股份、天数智芯、燧原科技、基流科技、苦芽科技、晶隆智算等23家核心机构共同完成。
从大模型到智能体:AI 基础设施的新命题
大模型开启了 AI 时代,而智能体正在重构现实世界。当 AI 从“生成回答”走向“持续感知、规划、执行任务”,对底层计算基础设施提出了全新挑战:
-
没有普适计算,智能体难以跨芯片、跨场景、跨平台运行;
-
没有高效计算,智能体难以进入政府、工业、金融、机器人等关键领域;
-
没有开放计算,AI 生态将被单一路径锁定,难以形成真正繁荣的产业体系。
FlagOS 要解决的问题始终如一——以更全面、更高效、更智能为核心目标,为智能体时代提供坚实的计算底座。

八大核心升级:FlagOS 2.0 成为智能体时代的核心智算基座
1.全球支持芯片种类最多的 AI 系统软件栈:18家厂商、32款芯片
FlagOS 2.0 将芯片支持从上一版本的16家厂商25款芯片,扩展到18家厂商32款AI芯片,应用场景从数据中心延伸到边缘推理和机器人云边协同——实现了从云到端的全场景覆盖。
2.“1+6”算子库体系:497个算子,从大模型走向科学计算全域覆盖
FlagOS 2.0 在原有 FlagGems 大模型算子库基础上,新增6大领域算子库,算子总数达到497个,构建起全球最大的多芯片算子库。
-
最大单一 Triton 算子库
FlagGems 作为全球最大的 Triton 单一算子库,已有超过407个算子,并正式进入 PyTorch 基金会生态合作项目,同时已支持18个 vLLM 的重要融合算子。在40个主流模型上,推理任务算子覆盖度达到90%~100%。
-
新增六大领域算子库
AI芯片不仅仅加速大模型计算,也对更多领域起到计算加速的重要作用。这次6大领域 FlagDNN(深度神经网络)、FlagBLAS(基础线性代数)、FlagFFT(快速傅里叶变换)、FlagSparse(稀疏矩阵)、FlagTensor(张量运算)、FlagAudio(语音处理)等算子库的发布,标志着 FlagOS 从“大模型专用”正式迈向科学计算全领域覆盖。目前共计90个算子,后续将不断扩充。
-
多厂商全面支持 C++ Wrapper
天数智芯、摩尔线程、华为、寒武纪等多个芯片厂商全面支持 FlagGems C++ Wrapper 关键能力,并对 30 个重点算子的 C++ Wrapper 替换。作为连接 Triton 高性能内核与 PyTorch 推理框架运行时的关键桥梁,C++ Wrapper 将算子封装、注册机制和运行时管理下沉到 C++ 层,在复用底层 Triton Kernel 的同时,有效降低 Python 运行时开销、提升端到端性能,并为多芯片环境下的统一分发、稳定调度和工程化落地提供核心支撑。
3.Triton-TLE:面向多架构的新一代编程语言
FlagOS 2.0 的多芯片统一编译器 FlagTree v0.5 正式发布 Triton-TLE(Triton Language Extension)——这是对原有 Triton 语言的全面扩展,让算子开发从单一 GPU 架构拓展到一个兼顾高性能、高开发效率的更广阔空间。
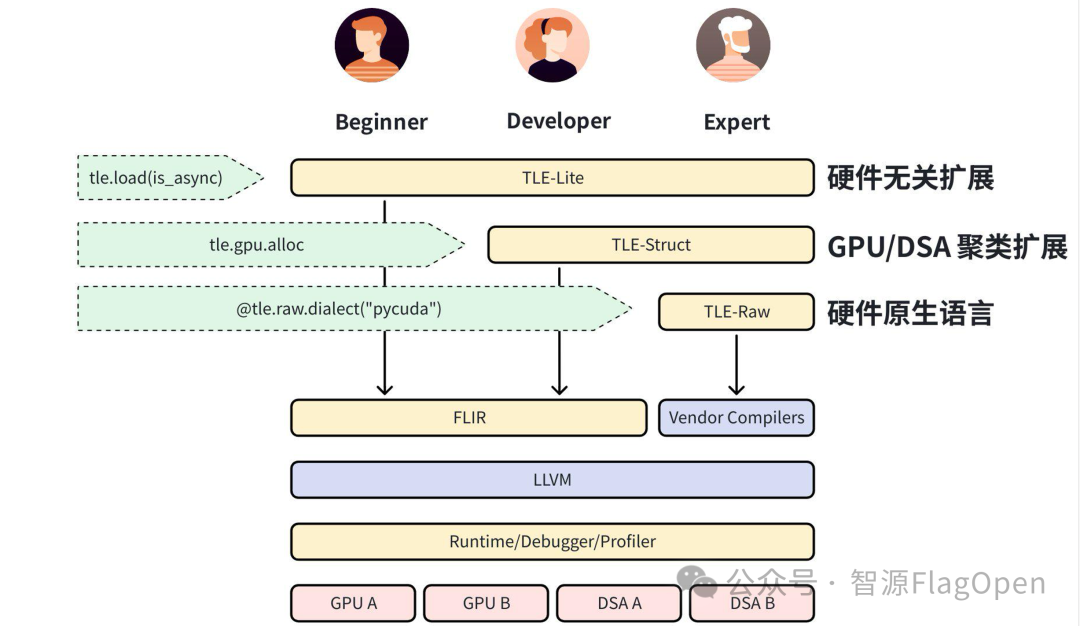
Triton-TLE 多层抽象架构图
Triton-TLE 目前支持31种原语,与华为昇腾、清微智能深度合作,分别在 GPU、DSA、可重构计算三大代表性架构上进行验证。实测性能显著优于原生 Triton,接近甚至超过各芯片原厂 C 语言实现:
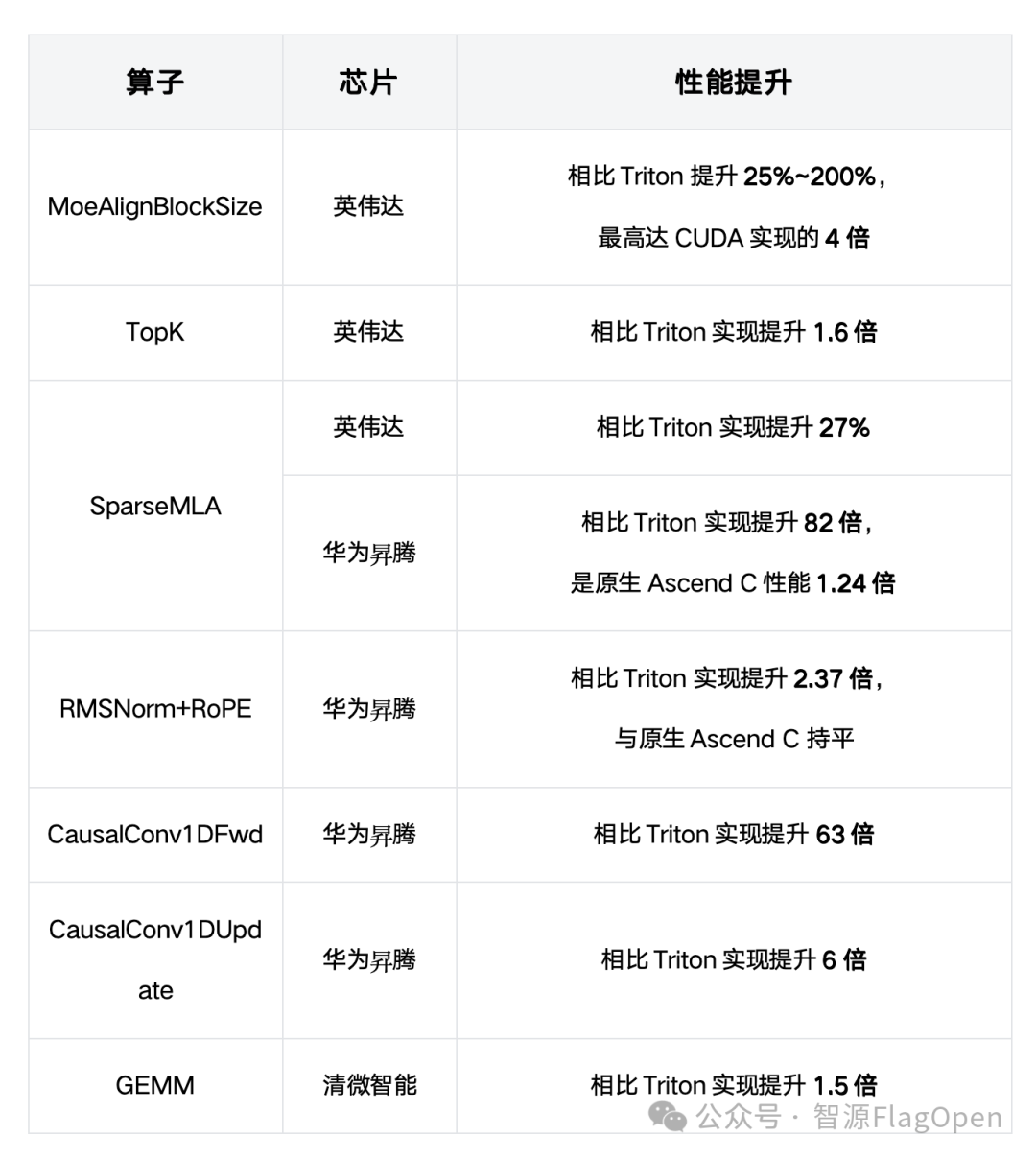
Triton-TLE 在多芯片上的典型算子性能提升
Triton-TLE 的发布意味着:开发者可以用统一的语言编写算子,在多种架构上获得接近原生的性能——这是解决“一种芯片一套开发工具”困境关键一步。
4.FLIR(FlagIR):支持多架构的统一中间表示层
通过与华为昇腾、清微智能、ARM AIPU 团队深入合作,FlagOS 2.0 的多芯片统一编译器 FlagTree v0.5 首次发布 FLIR (FlagIR) 的预览版,探索建立支持多芯片架构的统一中间表示层,让不同芯片可以共享统一编译优化、更容易适配。目前,FLIR 已经支持了76个 Triton 语言的原语,103个 FlagGems 算子,首批支持芯片包括华为昇腾、清微智能、ARM AIPU。
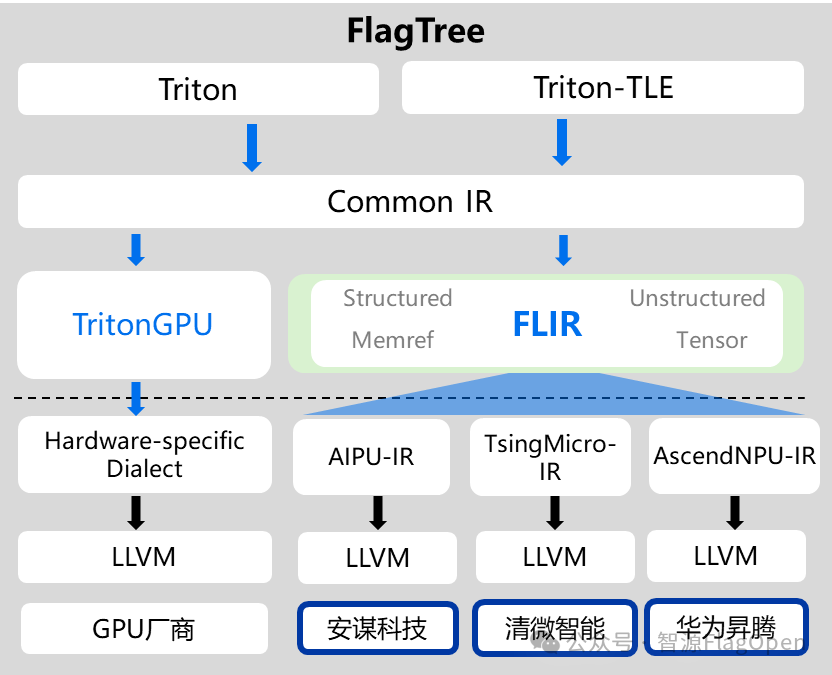
FLIR 在FlagTree的架构支持
FLIR 不但是 FlagTree 在 Triton 编译体系上的关键技术,也成为与生态协同的技术桥梁,本次预览版发布,也标志着众智 FlagOS 与华为昇腾 CANN 两大开源生态的打通。
5.FlagScale 统一插件体系:从推理到训练到强化学习
AI 芯片生态的另一个痛点是框架碎片化——各芯片厂商接入 PyTorch、vLLM、Megatron 等框架时,往往以不同方式“魔改”,导致版本不一致、接入方式不一致、优化策略不一致。
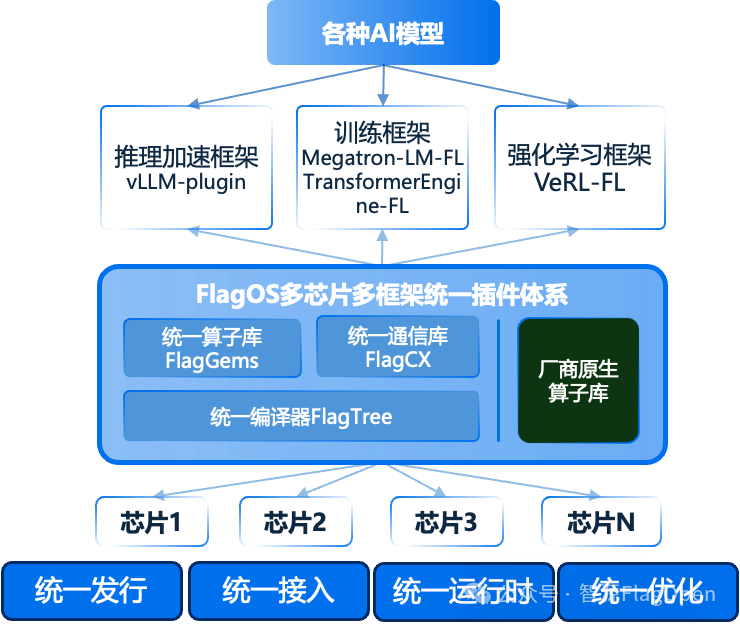
FlagScale统一多芯片插件体系
FlagOS 2.0 通过 FlagScale 统一多芯片插件体系,向上连接多种主流 AI 框架,向下连接 FlagOS 核心能力与厂商原生能力,形成面向多元 AI 芯片的统一插件中枢:
-
推理:vLLM-plugin-FL(支持英伟达、华为、摩尔线程、沐曦、海光、清微智能、天数、平头哥等)
-
训练:Megatron-LM-FL + TransformerEngine-FL(支持英伟达、摩尔线程、沐曦、海光、昆仑芯、天数、清微智能等)
-
强化学习:VeRL-FL
FlagOS 正从解决“N种芯片”的统一,迈向解决“M种框架与算法包接入”的统一。
6.FlagOS-Robo:面向具身智能的训练、推理、评测一体化多芯片框架
FlagOS 2.0 本次发布的 FlagOS-Robo 更新版本,支持了更多模型的具身智能大模型的训练和推理,打通了具身智能领域的训练-推理-仿真评测全流程覆盖:
训练:支持 RoboBrain2.0/2.5、PI0、PI0.5、GROOT N1.5 等具身 VLA 模型,及具身大脑模型的微调训练
推理部署:支持云端多芯片(英伟达/华为昇腾/摩尔线程)和端侧多种硬件模组的推理部署(天数 TY1200 /英伟达 THOR )
仿真评测:集成 MuJoCo、SAPIEN/PhysX,支持 LIBERO、RoboCasa、VLA-Arena、ManiSkill 等评测集
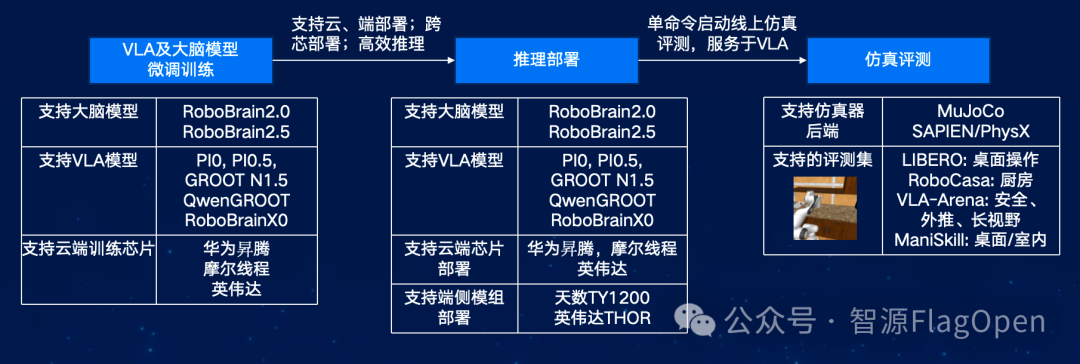
FlagOS-Robo “训练-推理-仿真评测”全流程平台
7.KernelGen 2.0:全面升级支持6种AI芯片的算子自动生成
KernelGen 2.0 是面向多种 AI 芯片的算子生成自动化平台,覆盖算子生成、基线构建、验证测试的完整生命周期,支持 Triton 和 Triton-TLE 两种语言,已适配6款 AI 芯片(英伟达、海光、摩尔线程、华为昇腾、天数智芯、沐曦)。在 KernelGen-Bench (110个算子)上的测试结果显示:
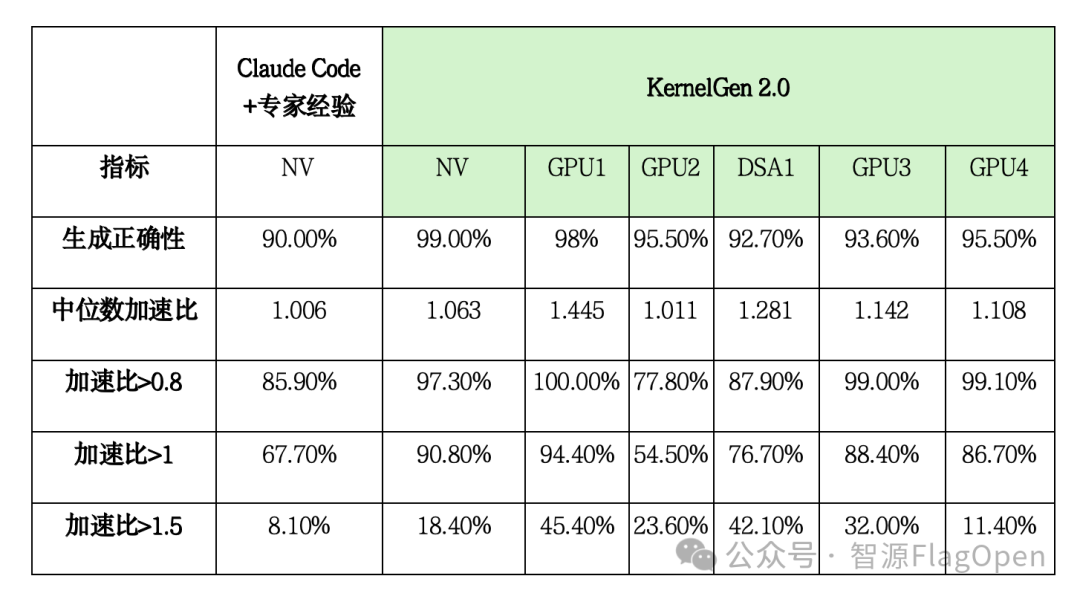
KernelGen 2.0 vs Claude Code,及其在多芯片上的性能指标对比
KernelGen 在英伟达上的算子生成正确性和加速比均显著超过 Claude Code,在5种国产AI芯片上均获得高于92%的生成正确性,超过50%的算子性能优于芯片原生实现。KernelGen 2.0 提供 Web 平台、智能体 Skill 和 MCP 等多种产品形态,支持 VSCode、Claude Code 和 OpenClaw 等开发工具接入。
8.FlagRelease:开源大模型的跨芯迁移与统一发布平台
FlagReleas(https://github.com/flagos-ai/FlagRelease)
解决的是一个很实际的问题:当一个新的开源大模型发布后,开发者想在多元芯片上跑起来,通常需要自己处理分布式环境配置、芯片专属依赖、模型格式转换等一系列工作。FlagRelease 把这些环节标准化了——为每个模型、每种芯片提供统一的源代码、验证过的模型文件和开箱即用的 Docker 镜像。

FlagRelease 多芯片模型迁移与发布流程图
截至目前,FlagRelease 已面向10家厂商的12款硬件适配了70+个开源模型实例,覆盖 DeepSeek-R1、Qwen3.5、GLM-5、TeleChat3 等主流模型。每个模型实例都附带在对应芯片上的评测结果,作为技术参考。
更值得关注的是生态模式的演进。FlagRelease 最初由 FlagOS 团队主导适配,现在已经进入模型厂商共建阶段——以中电信人工智能公司(TeleAI)为代表,模型方开始主动贡献适配,从“使用者”转变为“贡献者”。下一阶段的目标是模型方+芯片方的全生态共建:芯片厂商共建适配插件,模型方主动贡献模型适配,形成开放的双向生态。
全面拥抱智能体生态
FlagOS 2.0 与智能体生态深度融合,形成双向赋能:
1.FlagOS Skills 1.0发布
FlagOS Skills 1.0 发布,为首个为 AI 计算打造的专业技能库。12种 Skills 覆盖模型适配、算子生成、性能调优等核心场景。开发者通过自然语言即可调用,支持 Claude Code、Cursor、Codex、Gemini CLI 等主流 AI 编程工具。
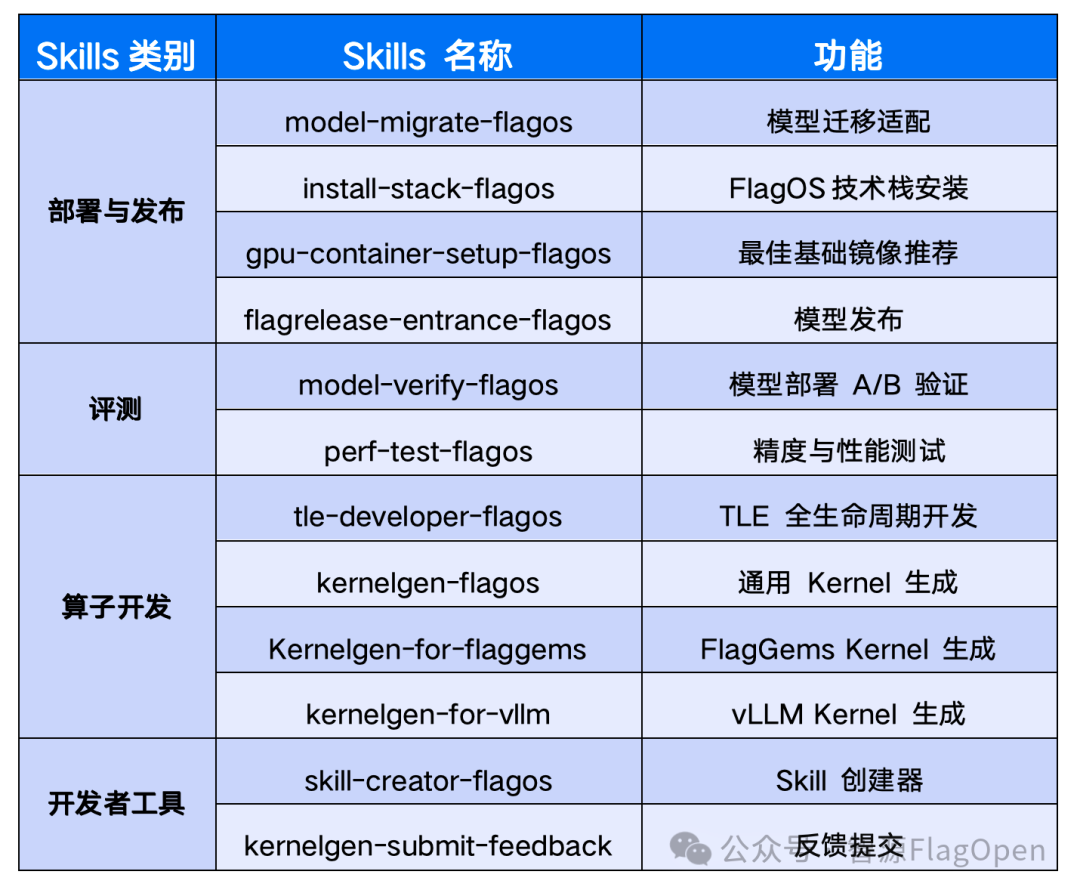
FlagOS skills 目前支持的主要skill list(https://skillhub.flagos.io)
以模型迁移为例,之前用户需要耗费几天的时间,使用 FlagOS 发布的 model-migrate-flagos 技能,即可快速、高效、智能的完成所有操作。
2.众智 FlagOS 官网 SkillHub 全新上线
众智 FlagOS 官网在本次 FlagOS 2.0 版本发布同时,也进行了全面升级。为了让全球 AI 开发者在“智能体 OpenClaw ”时代很容易使用各种 AI 芯片平台,全新上线了 SkillHub(https://skillhub.flagos.io)。旨在为 AI 开发者打造一站式、面向多种AI芯片的 “最专业 AI 计算技能中心”,开发者可以一行命令安装全部技能:
npx skills add flagos-ai/skills --allFlagOS 赋予智能体普惠的推理能力,让智能体用户轻松解决“跨芯”问题;智能体则成为 FlagOS 生态的新入口,大幅降低多芯片开发的门槛。
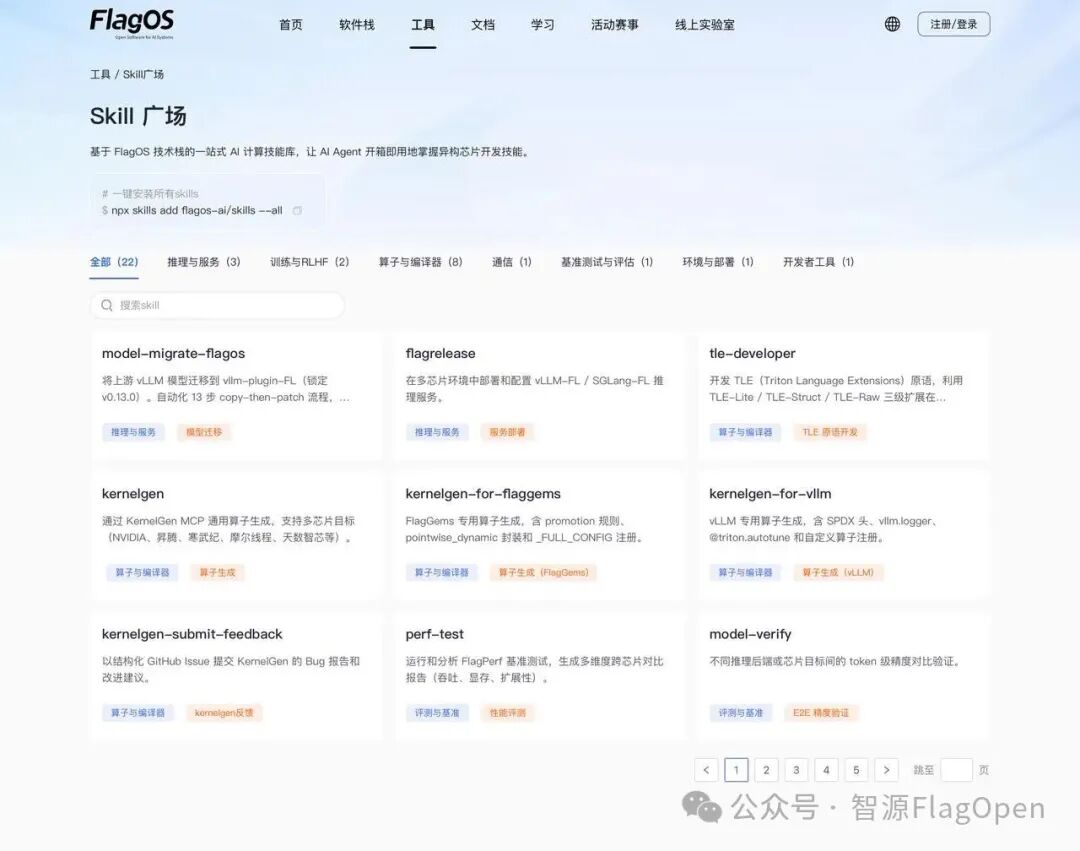
产业落地与生态共建
公有云上线:FlagOS 联合腾讯云和阿里云,将模型镜像正式上线公有云,开发者可直接拉取使用,快速部署 FlagOS + 智能体,为企业从公有云 API 转向自建本地 AI 服务提供了可落地的实践路径。
企业合作:东华软件 SmartX 智能体平台与 FlagOS 结合,以统一软件栈、广泛芯片兼容性和高效开发体验,帮助企业在多芯片上轻松构建智能体解决方案。
开源共建模式升级:FlagRelease 平台已面向10家厂商12款硬件发布70+开源模型实例。以中电信人工智能公司为代表,厂商正从“使用方”成长为“贡献方”,从单向适配走向模型方+芯片方的全生态共建。
人才培养:智源研究院与北京大学计算机学院共同完成48课时《智算系统软硬件基础》课程建设(https://flagos.educoder.net),已纳入国家智慧教育平台,由北大正式开课,并通过开源方式助力更多高校进行课程打造。
FlagOS 开放计算全球挑战赛:该赛事是由众智FlagOS 社区和北京智源人工智能研究院联合主办的一项多赛季、综合性赛事。大赛鼓励开发者基于统一 AI 系统软件栈 FlagOS 的能力进行创作实战和创新探索,促进 AI 开发者能力提升。 赛事总奖金池高达200万元,诚邀 AI 算法与系统工程师、硬件与编译器开发者,以及所有致力于突破 AI 芯片编程复杂性的技术实践者与梦想家参与挑战,共同推进开放计算生态的蓬勃发展。本赛季聚焦算子开发、大模型推理优化、自动数据标注三大核心赛道,以深度优化大模型性能与运行效率,推动技术落地与行业创新。
大赛详情:https://flagos.io/RaceDetail?id=295v67vw&lang=cn
目前,众智 FlagOS 社区已汇聚79家成员单位,本次新加入18家单位,共同打造新一代开源智算软硬件技术生态。
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:
https://github.com/flagos-ai
GitCode 项目地址:
https://gitcode.com/flagos-ai

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)