VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models
论文:https://openreview.net/pdf?id=KZYhyilFnt
发表:2026年TMLP
github:https://github.com/Tencent/SelfEvolvingAgent/tree/main/VScan
Abstract
最近的大型视觉语言模型(LVLMs)通过引入更细粒度的视觉感知和编码,提升了多模态理解能力 。然而,由于视觉 Token 序列变长,这些方法产生了显著的计算开销,为实时部署带来了挑战 。为了缓解这一问题,先前的研究探索了在视觉编码器的输出层或语言模型的早期层剪枝不重要的视觉 Token 。在本研究中,我们重新审视了这些设计选择,并通过对视觉 Token 在视觉编码和语言解码阶段处理方式的全面实证研究,重新评估了其有效性 。在这些见解的指导下,我们提出了 VScan,这是一个两阶段的视觉 Token 削减框架,通过以下方式解决 Token 冗余:(1)在视觉编码期间,将互补的全局和局部扫描与 Token 合并相结合;(2)在语言模型的中间层引入剪枝 。在四个 LVLM 上的广泛实验结果证实了 VScan 在加速推理方面的有效性,并证明了其在 16 个基准测试中优于当前最先进方法的性能 。值得注意的是,当应用于 LLaVA-NeXT-7B 时,VScan 在预填充阶段实现了 2.91 倍的加速,并减少了 10 倍的 FLOPs,同时保留了 95.4% 的原始性能 。代码可在 https://github.com/Tencent/SelfEvolvingAgent/tree/main/VScan 获取 。
1 Introduction
大型视觉语言模型(LVLMs)已成为多模态学习中的一项变革性进展,在广泛的视觉语言任务中展现出了卓越的熟练度 。LVLMs 的最新进展进一步增强了它们处理高分辨率图像和多图像/视频输入的能力,从而在视频问答、多图像理解和指代性地基(referential grounding)等任务中实现了精细的感知 。然而,处理如此丰富的视觉输入需要大幅增加视觉 Token 的数量,这往往远超文本 Token 的数量 。例如,LLaVA-NeXT 为高分辨率图像编码多达 2,880 个视觉 Token,而 Qwen-2.5-VL 可为多图像或视频输入处理多达 16,384 个 Token——比典型的纯文本序列高出几个数量级 。由于自注意力机制的平方复杂度,这导致了更长的输入序列,并产生了巨大的计算和内存开销,从而限制了 LVLMs 在实际应用中的可扩展性和实时部署 。
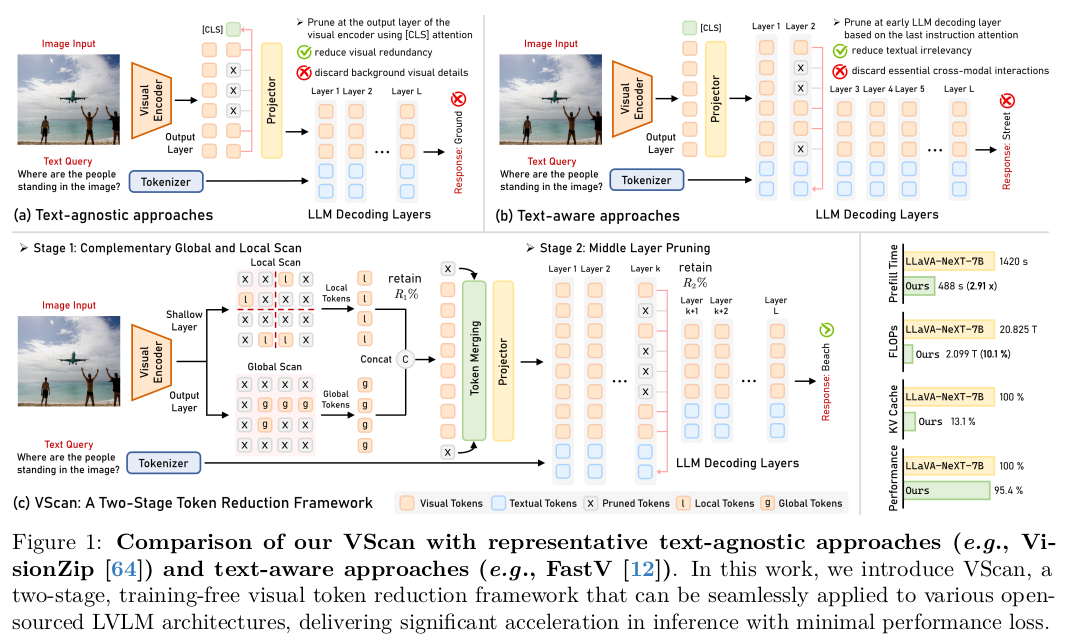
意识到并非所有视觉 Token 都对最终的 LVLM 响应有意义,最近的研究提出了视觉 Token 削减技术,旨在通过剪枝视觉冗余或文本无关的 Token 来提高计算效率 。这些方法通常分为两类:(1)文本无关的剪枝方法(图 1(a)),它们在视觉编码阶段根据视觉 Token 的显著性和独特性对其进行剪枝,通常利用视觉编码器输出层的自注意力或 [CLS] 注意力 ;(2)文本感知的剪枝方法(图 1(b)),它们在语言解码阶段的早期层选择性地移除与文本查询相关性较低的 Token,以在减少计算的同时保留特定任务的信息 。虽然这些方法取得了显著成果,但它们的性能往往受限于单阶段设计,且缺乏对视觉 Token 在整个 LVLM 管道中如何被处理和利用的系统性理解 。
在本研究中,我们进行了深入的实证分析,以重新评估这两种主流剪枝范式的有效性,并提取出指导设计更有效的视觉 Token 削减方法的见解 。我们的研究揭示了两个关键观察结果:(1)在视觉编码阶段,视觉编码器在浅层关注局部显著的 Token,聚焦于细粒度的局部细节;而在深层,它逐渐将注意力转移到一组高度浓缩的 Token 上,这些 Token 封装了更广泛的全局上下文 ;(2)在 LLM 解码阶段,早期层对序列后期出现的视觉 Token 表现出强烈的位置偏差,忽略了它们的语义相关性 ;随着层的加深,跨模态交互开始出现,输出 Token 概率通常在视觉信息更有效地整合进语言流的中后期层趋于收敛 。
基于这些见解,我们推出了 VScan,这是一个两阶段、无需训练的视觉 Token 削减框架。如图 1(c) 所示,它通过在视觉编码和语言解码阶段逐步剪枝无信息量的 Token 来提升 LVLMs 的效率 。在视觉编码阶段,VScan 采用互补的全局-局部扫描策略来保留语义重要且空间多样的 Token,随后进行 Token 合并以保留完整的视觉信息 。在 LLM 解码阶段,VScan 引入了中间层剪枝,以进一步消除与文本查询相关性较低的视觉 Token,同时保持必要的跨模态交互,以尽量减少对最终任务性能的影响 。值得注意的是,VScan 可以无缝集成到各种开源 LVLM 架构中,并与 FlashAttention 完全兼容,使其在实际应用中既实用又具有广泛的适用性 。
我们在 LLaVA-1.5、LLaVA-NeXT、Qwen-2.5-VL 和 Video-LLaVA 四个模型上,通过 16 个图像和视频理解基准测试全面评估了 VScan 的有效性 。广泛的实验结果证明了 VScan 在不同 LVLM 架构和 LLM 规模上的通用有效性,突显了其卓越的性能-效率权衡 。具体而言,VScan 在预填充阶段使 LLaVA-1.5-7B 实现了 1.77 倍的加速,使 LLaVA-NeXT-7B 实现了 2.91 倍的加速,同时分别保留了原始性能的 96.7% 和 95.4% 。
本工作的贡献总结如下:
-
我们进行了全面的分析,揭示了视觉知识在整个 LVLM 中的演变过程,为设计更有效的视觉 Token 削减策略提供了见解 。
-
我们推出了 VScan,这是一个两阶段、无需训练的视觉 Token 削减框架,能够逐步消除不重要的视觉 Token,以减少视觉冗余和文本无关性 。
-
跨 16 个基准测试的广泛评估证明,在受限的 Token 预算下,VScan 在维持鲁棒性能方面始终优于现有的先进方法 。
2 Related Work
高效大型视觉语言模型。 基于强大的自回归 LLMs ,近期的 LVLMs 通常采用“编码器-投影器-解码器”架构,其中视觉输入被编码为 Token,并与语言序列共同处理 。 然而,随着图像分辨率的提高或输入扩展到多图像/视频,视觉 Token 的数量会成比例增长,由于自注意力机制 的二次方复杂度,导致计算成本和运行时间急剧增加,这限制了 LVLMs 在实际应用中的可扩展性 。为了缓解这一问题,一些 LVLMs 引入了专门的模块来提升效率——例如 InstructBLIP 中的 Q-Former 和 OpenFlamingo 中的 Perceiver Resampler ——它们在 LLM 解码之前将密集的视觉输入蒸馏为一组紧凑的特征。与这些架构策略正交的是,FlashAttention 作为一种被广泛采用的硬件感知优化技术脱颖而出,它通过减少冗余内存访问来加速注意力计算,在不损害性能的情况下提供了显著的加速。
LVLMs 中的视觉 Token 削减。 另一类研究旨在提高模型在序列维度上的效率——ToMe 和 FastV 等先驱工作探索了诸如视觉 Token 合并和文本引导剪枝等策略,以提升 LVLMs 的效率。在此基础上,后续方法大致可分为两大类:(1)文本无关的剪枝方法 ,它们在视觉编码阶段识别并移除冗余或无信息的视觉 Token。例如,VisionZip 根据 [CLS] 注意力分数选择主导 Token,而 FOLDER 在视觉编码器的最后几个区块中引入了带有削减溢出(reduction overflow)的 Token 合并。(2)文本感知的剪枝方法 ,旨在 LLM 解码阶段移除与文本查询无关的视觉 Token。例如,SparseVLM 提出了一种迭代稀疏化策略,通过选择视觉相关的文本 Token 来评估视觉 Token 的重要性;PyramidDrop 则在多个解码层执行渐进式剪枝,以平衡效率与上下文保留。在本研究中,我们对 LVLMs 在视觉编码和语言解码阶段如何处理视觉 Token 进行了全面分析,并提出了相应的两阶段方法 VScan,旨在有效提高 LVLMs 的推理效率,同时保持鲁棒的性能。
3 Empirical Analysis
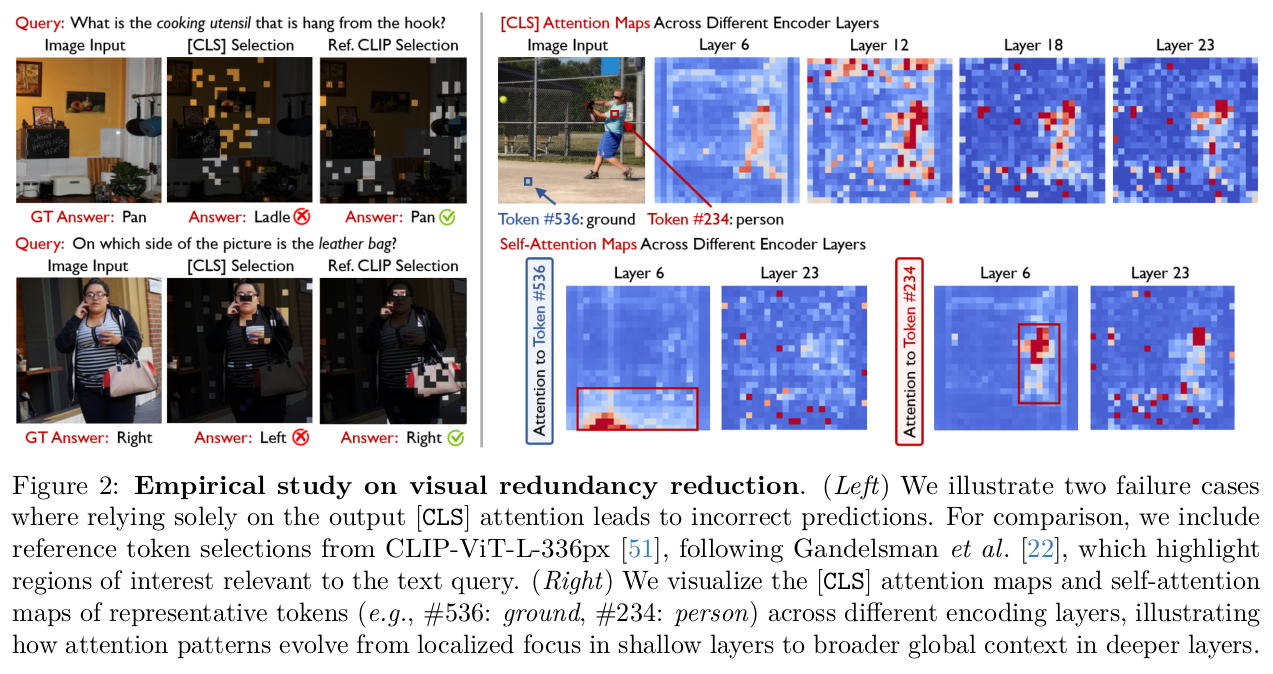


4 Method
我们引入了 VScan,这是一种无需训练的方法,它在视觉编码和 LLM 解码阶段逐步剪枝无信息量的 Token,以加速 LVLM 的推理,如图 1(c) 所示 。
4.1 Reducing Visual Redundancy via Complementary Global and Local Scans


4.2 Reducing Textual Irrelevance via Middle Layer Pruning


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)