【AI】Explaining AI with AI:Language models can explain neurons in language models

1、用 AI 来解释 AI


https://openai.com/index/language-models-can-explain-neurons-in-language-models/

目标不同,可解释的东西不同,会采用各式各样的技术来解释
Language models can explain neurons in language models 想做的事情是知道一个神经元的作用

多数神经元,不知道自己在干什么

预测接下来会不会出现 an 的神经元
有时候人不知道神经元的作用是什么
可以让 LLM 告诉你
有些神经元的行为比较复杂,交给 GPT4 解释

把 GPT2 中某些 neuron 激活比较高的 token 丢给 GPT4 让其解释
如何向 GPT4 说明 neuron 激活比较高呢?

打分,十分制

特定神经元(Neuron 1)对每个词(Token)的反应强度

把非零得分的 token 去掉,
为了更清晰,系统过滤掉了所有零值。
可以看到,神经元 neuron1 对“团结”、“整体性”、“城镇”相关的词缀有反应。


检测文本中关于社区或团结相关概念的实例


侦测比喻的神经元


neuron 的功能:找一句话中重复或相似的 word

GPT4 觉得它什么都能干,人类的答案是:侦测前面有错字,or 侦测前面有罕见字



人类答案:规律被破坏时,该 neuron 启动
怎么知道 GPT4,解释的好不好呢?

叫 GPT4 根据自己的解释扮演神经元

-
生成解释 (Explanations): 给 GPT-4 提供大量激活样本,让它用自然语言描述这个神经元在寻找什么。
-
模拟实验 (Simulation): 让 GPT-4 充当这个神经元。给它一段新文本,让它预测:“根据你刚才生成的解释,你认为这个神经元在遇到这些词时会产生多大的激活值?”
-
对比打分 (Scoring): 将 GPT-4 模拟生成的激活值与真实神经元(eg GPT2)的激活值进行对比。如果两者高度吻合,说明 GPT-4 给出的解释是准确的。
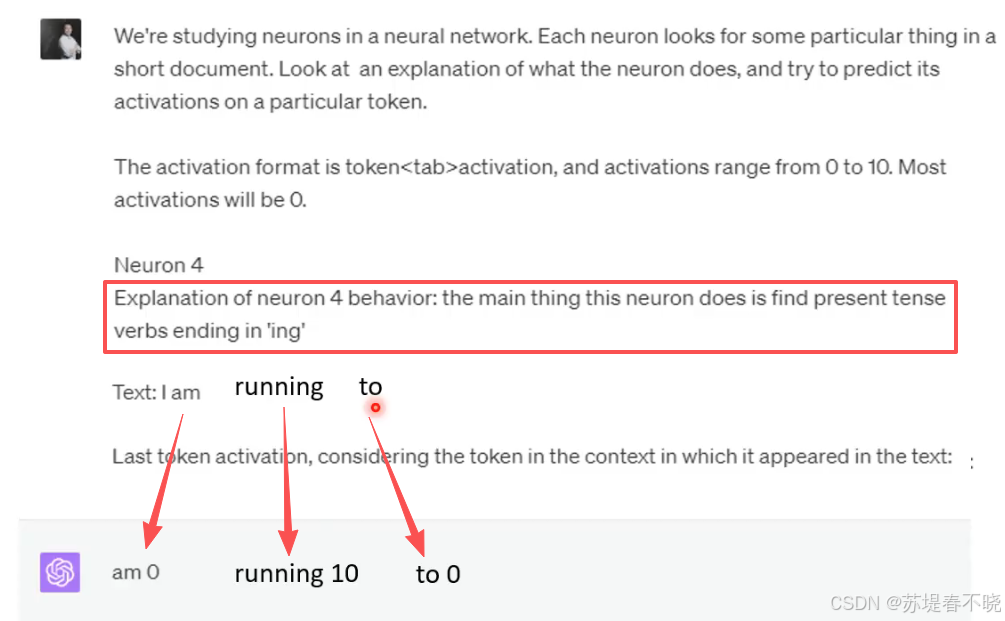
让 GPT4 扮演神经元 4,作用是出现 ing 时候启动,
am 时候 0,running 时 10,to 时 0
扮演的很成功
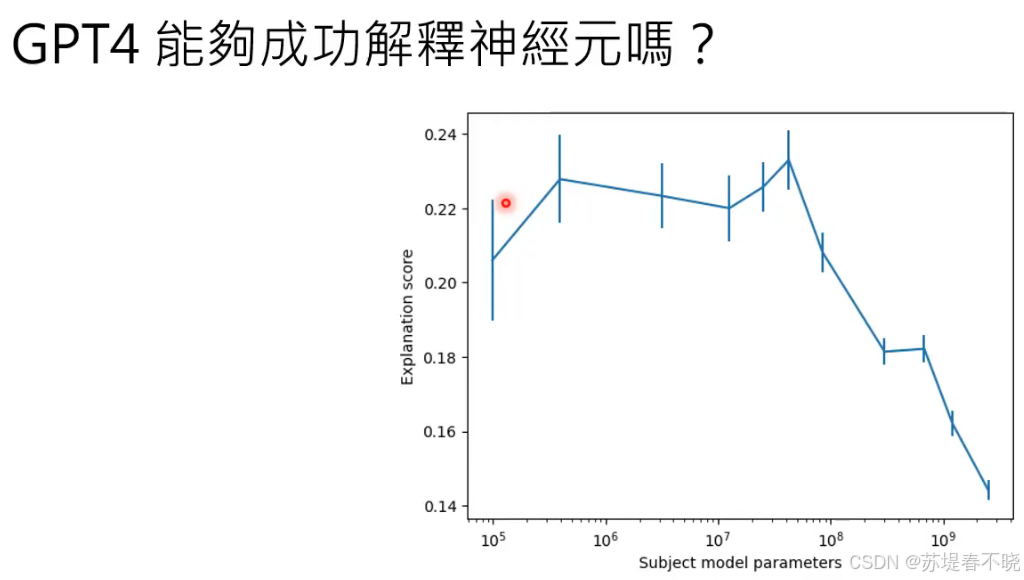
比较小的网络,比较好解释神经元在干什么,太大的网络,可能很多神经元合起来在做一件事,单独看某一个神经元不太好辨别其在干什么

越底层的神经元越好解释,越高层的神经元越不好解释

三步走
-
生成解释 (Explanations): GPT-4 观察神经元激活样本,写下文字描述。
-
模拟实验 (Simulation): GPT-4 根据自己的描述,预测该神经元在遇到新词时的激活强度。
-
打分评估 (Scoring): 对比预测值与真实值。如果解释完美,得分应接近 1.0。
高分案例 (0.42): 当解释为“寻找与正确或妥当执行动作相关的词和短语”时,得分较高。这意味着 GPT-4 预测的激活模式与实际神经元的表现比较接近。
低分案例 (0.14): 当解释为“寻找一般概念、标题和部分术语”时,得分很低。这说明解释太笼统,无法准确预测神经元的具体行为。
人类提供解释,GPT4 用人类解释的内容扮演神经元再计算与 GPT2 的 explanation score,得分也只有 0.18 分,并没有比 GPT4 提供的解释好太多
也就是说其实多数的神经元都没有好的解释
explaining AI with AI
为什么这项技术很重要?
-
规模化 (Scalability): 大语言模型有数千亿个参数和神经元。靠人类专家去一个一个分析是不可能的。用 AI 解释 AI 是唯一能够跟上模型增长规模的方法。
-
发现模式: 这种方法发现了一些有趣的神经元,比如专门负责“漫威电影”的神经元、负责“代码缩进”的神经元,甚至是负责“这种说法很阴阳怪气”的神经元。
-
模型对齐 (Alignment): 如果我们知道模型内部哪些神经元在负责有害内容或欺骗性逻辑,我们就可以更有针对性地引导和修正模型
局限性:
-
复杂神经元: 许多神经元是“多义性”的(Polysemantic),即一个神经元可能同时负责多个互不相关的概念,GPT-4 很难给出简洁的解释。
-
分层深度: 随着网络加深,神经元捕捉的概念越来越抽象,目前的解释能力还处于初级阶段。

第一种方法是 GPT4 扮演神经元,第二种方法,GPT4 取代神经元


关掉真实的神经元,但换上一个由 GPT-4 解释驱动的“模拟神经元”。
用 GPT4 扮演的神经元取代 GPT2 的神经元,超大参数扮演一个神经元,哈哈哈,扮猪吃老虎


A. 消融得分 (Ablation Score)
-
定义: 衡量“功能恢复”的程度。
-
实验背景:
- 完全消融: 关掉一个神经元,模型性能会下降(此状态定义为 0)。
- 真实状态: 神经元正常工作(此状态定义为 1.0)。
- 模拟替换: 关掉真实神经元,换上 GPT-4 按照它的“解释”生成的模拟信号。
-
直观理解: “换上人工模拟器后,模型功能恢复了多少”。
B. 相关性得分 (Correlation Score)
-
含义: 这种得分衡量的是 GPT-4 预测的激活值与真实激活值在数值上的相似度。
-
差异: 有些神经元虽然预测值很准(相关性高),但它在模型逻辑链条中可能并不处于核心位置(消融得分低);反之亦然。
简单的说,横坐标是 GPT4 扮演某个神经元,纵坐标是 GPT4 替换某个神经元

只要 AI 解释得足够准,它就能用自己的话“变”出一块假积木,让坏掉的乐高机器人重新运行起来

让模型读哪些句子呢?对结果的影响也很大
直接选择待解释神经元有较大输出的句子

直觉上,以为神经元是看到 all 就会启动
让机器自己产生额外的例子,


发现是寻找 not all,而不是仅仅 all,上面的例子就是 revision
纵坐标:解释得分 (Explanation Score),就像考试成绩,分数越高(最高 1.0),说明 AI 对神经元的解释越准确。

横坐标:不同的“写纸条”方法
-
Baseline(基础版): 让 GPT-4 直接看样本写解释。
-
Reexplanation(重新解释): 让 AI 换个说法再试一次。

-
Revision(修正版): 这是一个重点!AI 先写一个草稿,然后根据它漏掉的例子或猜错的情况,自己进行 “改错”和“润色”。

-
Revision_rand(随机修正): 这是一个对比组,随便乱改一下,看看是不是只要改了就能变好。

让 AI 自己检查并修改解释,能让它更懂神经元,但要达到完全理解,还有很长的路要走!
通过这种“自我订正”的方式,AI 正在一点点抠出那些藏在模型深处、连人类都很难察觉的小细节。
用 AI 解释 AI,靠谱吗?其实人脑是一个更大的黑盒子,难道用人脑去解释 AI 就没有问题吗?

GPT-2 提供素材,Explainer 写解释,Simulator 验证解释。
我们在用一种“黑盒”去解释另一种“黑盒”,这种“以夷制夷”的方法是否存在逻辑漏洞(比如 Simulator 能力不足或两模型——Explainer 和 Simulator 串通)。
eg:
-
Explainer OK ,但是 Simulator 不行
-
Explainer 不行,Simulator 行,导致最终结果也不差
-
Explainer 和 Simulator 都不行也有可能
单一神经元->多个神经元一起
神经元的行为,完全能用人类语言来解释吗?
2、Simulator(模拟器)是如何工作的?
在 OpenAI 的框架中,Simulator 的任务是:验证 Explainer 给出的那段文字描述,是否真的能对应上神经元的数学行为。
1)它的身份是什么?
它通常也是一个强大的语言模型(比如 GPT-4)。它不直接看神经元的内部代码,它只看 Explainer 写给它的 “解释文本”。
2)具体的工作流程
我们可以把这个过程想象成一场角色扮演游戏:
-
准备阶段: 科学家给 Simulator 递过去一张小纸条(Explainer 写的解释),上面写着:“这个神经元喜欢‘天气’相关的词。”
-
模拟阶段: 科学家给 Simulator 看一段它从来没见过的句子:“今天阳光明媚,适合去公园。”
-
执行任务: 科学家问 Simulator:“如果你就是这个神经元,看到这句话里的每个词,你会兴奋到什么程度?请给每个词打分(0 到 10 分)。”
-
输出结果: Simulator 思考后给出预测:
-
“今天” -> 1分
-
“阳光明媚” -> 9分
-
“公园” -> 4分
-
3)它是如何计算“得分”的?
这是最关键的一步。科学家手里有两份打分表:
-
真实表: 真实的 GPT-2 神经元在处理这句话时产生的真实激活值(比如 8.8 分)。
-
预测表: Simulator 刚才猜的分数(比如 9 分)。
对比: 如果两张表的分数在所有句子里都很接近,说明 Simulator 成功地通过“读说明书”模拟了真实的神经元。这时,Explainer 的功劳就很大,得分(Explanation Score)也就越高。
3、扮演 vs 替换:AI 是怎么通过测试的?
扮演 vs 替换:AI 是怎么通过测试的?
用 “演戏”和“修机器” 来区分它们。
1)GPT-4 扮演神经元 (Acting/Simulation)
—— 这是一场“脑力模拟”测试。
-
做法: 科学家给 GPT-4 一张说明书(解释),问它:“如果你是这个神经元,看到‘苹果’会打几分?” GPT-4 在自己的脑子里想了想,报出了一个数字。
-
目的: 看看 GPT-4 的理论知识过不过关。
-
通俗理解: 就像是一个小演员在台下背台词。导演问:“如果你演个倒霉蛋,你会怎么哭?” 演员试着哭了一下。这时候,这个“哭声”还没影响到整场戏的进行,只是在考考演员演得像不像。
2)GPT-4 替换神经元 (Replacing/Ablation & Replacement)
—— 这是一场“实战拦截”测试。
-
做法: 科学家把 GPT-2 模型运行中的那个真实神经元给拔掉(变黑),然后把 GPT-4 刚才模拟出来的那个数字塞进去,让 GPT-2 带着这个“假信号”继续运行。
-
目的: 看看这个解释是否具备实战价值。
-
通俗理解: 这次是真上台了!主角生病了(神经元消融),我们让那个背好台词的替身演员(GPT-4 的模拟值)直接顶上去演。如果整场戏(模型输出)最后没演砸,大家还能看懂,说明这个替身(解释)是真的懂戏!
3)除了这些,还有别的测试方式吗?
科学家们非常严谨,他们还用了这些方法来“折磨” AI:
A. “找不同”挑战 (Contrastive Examples)
-
玩法: 科学家会故意找两个长得很像,但激活程度完全不同的句子给 AI 看。
-
例子: “我喜欢吃苹果”和“我恨吃苹果”。如果神经元只对“喜欢”兴奋,AI 却解释成“关于水果”,那它在“恨”这个句子里就会猜错。
-
结论: 只有能分清“相似但不同”的情况,解释才算真正过关。
B. “随机噪声”大乱斗 (Random Baselines)
-
玩法: 科学家故意让 GPT-4 乱写一个解释,或者给一个随机的数字。
-
目的: 这是一个对照组。如果乱写的结果和认真写的结果一样好,那说明这个测试方法本身就有问题。
-
结论: 实验证明,只有“认真写的解释”才能让分数提高,说明这个方法是科学的。
C. 人类专家大PK (Human vs. AI)
-
玩法: 请最厉害的人类科学家来写解释,然后跟 GPT-4 比一比。
-
结果: 就像我们之前看到的那样,人类得 0.18 分,AI 得 0.15 分。虽然 AI 输了一点点,但它几乎已经快赶上人类专家的脑子了!
总结一下
-
扮演:是看 AI 猜得准不准。
-
替换:是看 AI 能不能顶替工作。
-
其他测试:是各种各样的考试题,确保 AI 不是在“瞎猫碰上死耗子”。
4、参考
-
https://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php
-
https://www.bilibili.com/video/BV18fXbY6Eis/?spm_id_from=333.1387.homepage.video_card.click&vd_source=8e91f8e604278558ec015e749d1a3719

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)