HNU2026-计算机系统-笔记2.1 计算机简化模型
2.1 计算机简化模型
基础知识:位、字节与字
计算机中所有信息的最小单位是 位(bit),即一个 0 或 1。由位向上构建出更大的存储单元:
| 单位 | 定义 | 典型用途 |
|---|---|---|
| 位 (bit) | 0 或 1,信息最小单位 | 单个开关状态 |
| 字节 (Byte) | 8 bit | 表示一个 ASCII 字符、最小可寻址内存单元 |
| 字 (Word) | 机器字长决定(常见 16/32/64 bit) | CPU 一次处理的数据宽度 |
内存(Memory)
- 内存可视为一系列按地址编号的字节单元
- 在简化模型中,使用 4 位地址,可编址 24=162^4 = 1624=16 个字节(地址范围
0000~1111) - 每个存储单元存放 1 个字节(8 bit) 的数据
示例:4 位地址的内存布局
地址(4 bit) 存储内容(8 bit) 000000000001000100000010… … 1111xxxxxxxx
寄存器(Register)
- 寄存器是 CPU 内部的超高速小容量存储单元
- 根据 CPU 架构,寄存器宽度不同:
- 8 位 CPU → 8 bit 寄存器
- 16 位 CPU → 16 bit 寄存器
- 32 位 CPU → 32 bit 寄存器(如 x86 的
EAX、EBX等)
- 寄存器数量极少(通常几个到几十个),但速度极快
01 一个最简模型
简化模型结构
课件中提出一个极简计算机模型,由两大核心部件构成: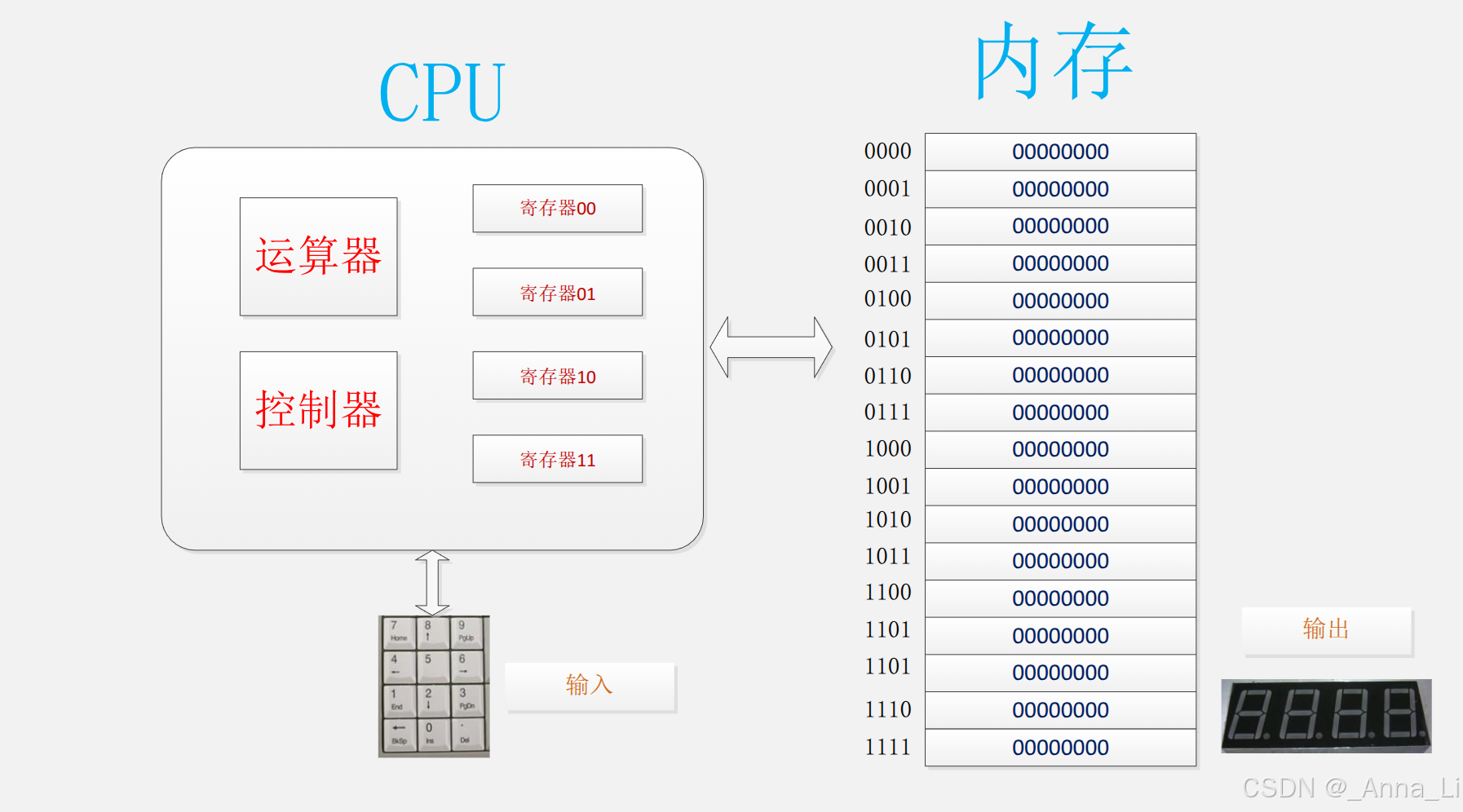
模型规格:
| 部件 | 规格 | 说明 |
|---|---|---|
| 寄存器 | 4 个,编号 00、01、10、11 |
每个 8 bit 宽 |
| 内存 | 16 字节 | 4 位地址(0000 ~ 1111) |
| 数据总线 | 8 bit | CPU 与内存间传输数据的通道 |
用简化模型理解 C 程序执行
考虑如下 C 代码:
int i = 1;
int j = 2;
int k;
k = i + j;
在简化模型中,编译器会将变量分配到内存,CPU 通过寄存器完成运算。下面逐步追踪执行过程。
阶段一:变量声明与初始化(内存分配)
Step 1 — int i = 1;
- 编译器在内存中为变量
i分配地址0000 - 将值
1(二进制00000001)写入该地址
Step 2 — int j = 2;
- 编译器在内存中为变量
j分配地址0001 - 将值
2(二进制00000010)写入该地址
Step 3 — int k;
- 编译器在内存中为变量
k分配地址0010 - 仅分配空间,不赋初值(内容未定义)
此时内存状态:
| 地址 | 内容 | 变量 |
|---|---|---|
0000 |
00000001 |
i = 1 |
0001 |
00000010 |
j = 2 |
0010 |
???????? |
k(未初始化) |
0011~1111 |
— | (空闲) |
阶段二:计算 k = i + j(需要 4 步)
CPU 不能直接操作内存中的数据进行运算,必须先把数据搬到寄存器中。k = i + j 需要拆解为 4 个微操作:
Step 1 — 加载 i 到寄存器
- 将内存地址
0000的内容00000001复制到寄存器R00 - 操作:
R00 ← Memory[0000]
Step 2 — 加载 j 到寄存器
- 将内存地址
0001的内容00000010复制到寄存器R01 - 操作:
R01 ← Memory[0001]
Step 3 — 执行加法运算
- ALU 将
R00和R01的值相加,结果存回R00 - 操作:
R00 ← R00 + R01 - 结果:
R00 = 00000001 + 00000010 = 00000011(即十进制3)
Step 4 — 将结果存回内存
- 将寄存器
R00的值00000011写入内存地址0010(变量k的位置) - 操作:
Memory[0010] ← R00
最终内存状态:
| 地址 | 内容 | 变量 |
|---|---|---|
0000 |
00000001 |
i = 1 |
0001 |
00000010 |
j = 2 |
0010 |
00000011 |
k = 3 ✅ |
[!important] 核心要点
一条简单的 C 语句k = i + j在底层需要 4 个步骤:加载 → 加载 → 运算 → 存储(Load → Load → Compute → Store)。这就是 “存-算分离” 架构的基本执行模式。
存算体系:为什么不在内存中直接计算?
核心矛盾在于速度差异:
| 部件 | 典型频率 | 量级 |
|---|---|---|
| CPU(运算器) | GHz(10910^9109 Hz) | 极快 |
| 内存(DRAM) | MHz(10610^6106 Hz) | 相对慢 |
- CPU 和内存之间存在巨大的速度鸿沟(约 1000 倍)
- 光在 13\frac{1}{3}31 纳秒内仅传播约 10 cm——即使是物理距离也会产生延迟
- 因此,CPU 必须配备少量超高速存储(寄存器),在本地完成计算后再与内存交互
[!tip] 存储层次的时间类比
如果把一次寄存器访问比作 1 秒钟,那么各级存储的等效时间为:
存储层级 等效时间 实际延迟量级 寄存器 < 1 秒 ~ 0.3 ns L1 缓存 ~ 3 秒 ~ 1 ns L2 缓存 ~ 14 秒 ~ 4 ns 内存(DRAM) ~ 4 分钟 ~ 100 ns 磁盘(HDD) ~ 1 年 3 个月 ~ 10 ms 这清楚地说明了为什么 CPU 需要寄存器和缓存作为"中间层"。
X86 架构寄存器概览
在真实的 X86 32 位 CPU 中,有 8 个 32 位通用寄存器(General Purpose Registers):
| 寄存器 | 全称 | 典型用途 |
|---|---|---|
EAX |
Extended Accumulator | 累加器,常用于运算结果 |
EBX |
Extended Base | 基址寄存器 |
ECX |
Extended Counter | 计数器,常用于循环 |
EDX |
Extended Data | 数据寄存器,常与 EAX 配合 |
ESI |
Extended Source Index | 源变址寄存器 |
EDI |
Extended Destination Index | 目的变址寄存器 |
EBP |
Extended Base Pointer | 栈基址指针 |
ESP |
Extended Stack Pointer | 栈顶指针 |
这些寄存器用于存放整数和指针。浮点运算使用独立的浮点寄存器(FPU / SSE / AVX)。
02 VSPM 原型机
冯诺依曼结构(Von Neumann Architecture)
现代计算机的基本架构源自 冯诺依曼(John von Neumann)在 EDVAC 报告中提出的设计思想,其核心是将计算机划分为五大功能部件:
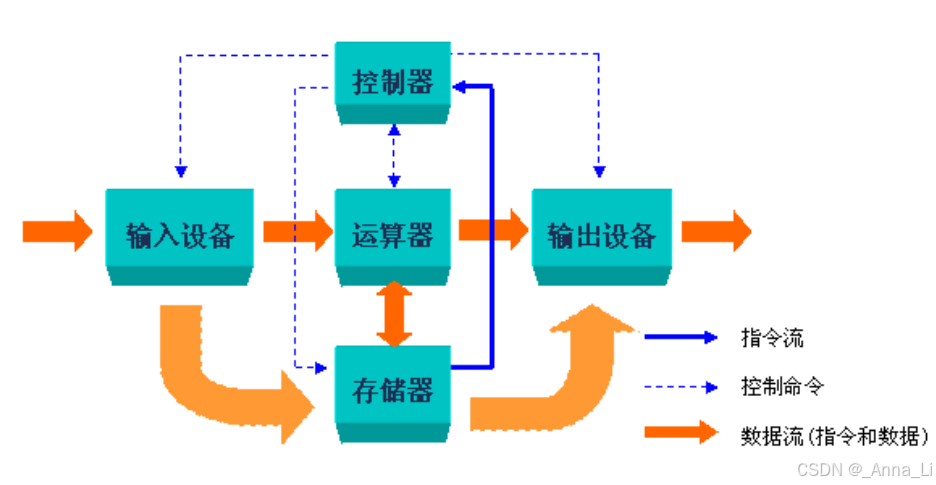
| 部件 | 功能 |
|---|---|
| 运算器(ALU) | 执行算术运算(加减乘除)和逻辑运算 |
| 控制器(Controller) | 取指令、译码、发出控制信号,协调各部件工作 |
| 存储器(Memory) | 存储程序(指令)和数据——“存储程序” 是冯诺依曼体系的核心思想 |
| 输入设备(Input) | 将外部信息输入计算机(如键盘) |
| 输出设备(Output) | 将计算结果输出给外部(如显示器) |
[!note] 其他体系结构
- 哈佛结构(Harvard Architecture):指令存储与数据存储分离,常用于 DSP 和微控制器
- 忆阻器架构(Memristor Architecture):存算一体的新兴架构,有望突破存算分离的瓶颈
VSPM 原型系统
VSPM(Very Simple Prototype Machine)是课程设计的一台教学用原型计算机,严格遵循冯诺依曼五大部件结构。
VSPM 五大组件详解:
| 组件 | 说明 |
|---|---|
| 存储器(内存) | 16 字节,地址 0000 ~ 1111,存放程序指令和数据 |
| 运算器 | 支持加法、减法、乘法 |
| 控制器 | 逐条取指令、译码、执行 |
| 输入设备 | 键盘,通过 IN 指令读取用户输入到寄存器 |
| 输出设备 | 4 位七段数码管显示器,地址 1111 为显示存储器(写入该地址的值会直接显示) |
VSPM 指令集
VSPM 共有 12 条指令,分为数据传送、算术运算、控制转移和 I/O 四类。
数据传送指令
| 指令 | 格式 | 功能 | 说明 |
|---|---|---|---|
MOVA |
MOVA R1, R2 |
R1 ← R2 |
寄存器 → 寄存器 |
MOVB |
MOVB M, R2 |
M ← R2 |
寄存器 → 内存 |
MOVC |
MOVC R1, M |
R1 ← M |
内存 → 寄存器 |
MOVD |
MOVD R1, R2 |
R1 ← Memory[R2] |
间接寻址:以 R2 的值为地址,取内存数据到 R1 |
MOVI |
MOVI R1, IMM |
R1 ← IMM |
立即数加载,IMM 范围 −128∼127-128 \sim 127−128∼127 |
HALT |
HALT |
停机 | 程序结束 |
算术运算指令
| 指令 | 格式 | 功能 | 说明 |
|---|---|---|---|
ADD |
ADD R1, R2 |
R1 ← R1 + R2 |
加法 |
SUB |
SUB R1, R2 |
R1 ← R1 - R2 |
减法,同时设置 G 标志位(若 R1 > R2 则 G=1) |
控制转移指令
| 指令 | 格式 | 功能 | 说明 |
|---|---|---|---|
JMP |
JMP addr |
PC ← addr |
无条件跳转 |
JG |
JG addr |
若 G=1,PC ← addr |
条件跳转:上一次 SUB 结果大于 0 时跳转 |
I/O 指令
| 指令 | 格式 | 功能 | 说明 |
|---|---|---|---|
IN |
IN R1 |
R1 ← 键盘输入 |
从输入设备读一个值到寄存器 |
OUT |
OUT R2 |
显示器 ← R2 |
将寄存器的值输出到显示设备 |
VSPM 编程实例
程序 1:求和 1+2+⋯+a1 + 2 + \cdots + a1+2+⋯+a
C 语言版本:
int a;
scanf("%d", &a); // 从键盘输入 a
int sum = 0;
for (int i = 1; i <= a; i++) {
sum += i;
}
printf("%d", sum); // 输出结果
VSPM 汇编版本(10 条指令):
变量分配:sum → 0000, i → 0001, a → 0010
| 地址 | 指令 | 说明 |
|---|---|---|
| 0 | IN R00 |
读取键盘输入到 R00(即 a) |
| 1 | MOVB 0010, R00 |
将 a 存入内存地址 0010 |
| 2 | MOVI R00, 0 |
sum = 0 |
| 3 | MOVB 0000, R00 |
将 sum 存入内存 |
| 4 | MOVI R00, 1 |
i = 1 |
| 5 | MOVB 0001, R00 |
将 i 存入内存 |
| 6 | MOVC R00, 0000 |
加载 sum 到 R00 |
| 7 | MOVC R01, 0001 |
加载 i 到 R01 |
| 8 | ADD R00, R01 |
sum += i |
| 9 | MOVB 0000, R00 |
存回 sum |
上述为核心循环体部分。完整程序还需包含循环控制(
SUB比较 +JG跳转)、i++递增和最终OUT输出。
程序 2:求最大值 max(a,b)\max(a, b)max(a,b)
C 语言版本:
int a, b, max;
scanf("%d", &a);
scanf("%d", &b);
if (a > b)
max = a;
else
max = b;
printf("%d", max);
VSPM 汇编版本(13 条指令):
变量分配:a → 0000, b → 0001, max → 0010
| 地址 | 指令 | 说明 |
|---|---|---|
| 0 | IN R00 |
读取 a |
| 1 | MOVB 0000, R00 |
存储 a 到内存 |
| 2 | IN R00 |
读取 b |
| 3 | MOVB 0001, R00 |
存储 b 到内存 |
| 4 | MOVC R00, 0000 |
加载 a 到 R00 |
| 5 | MOVC R01, 0001 |
加载 b 到 R01 |
| 6 | SUB R00, R01 |
R00 = a - b,若 a > b 则 G=1 |
| 7 | JG 10 |
若 G=1(a>b),跳转到地址 10 |
| 8 | MOVB 0010, R01 |
max = b(else 分支) |
| 9 | JMP 11 |
跳过 if 分支 |
| 10 | MOVC R00, 0000 |
重新加载 a(因 SUB 修改了 R00) |
| 10 | MOVB 0010, R00 |
max = a(if 分支) |
| 11 | MOVC R00, 0010 |
加载 max 到 R00 |
| 12 | OUT R00 |
输出 max |
| 13 | HALT |
停机 |
[!tip] 从 C 到机器指令的编译过程
人写 C 代码 → 编译器将其翻译为 VSPM 指令 → CPU 逐条执行指令。这就是编译(Compilation)的本质:将高级语言翻译为机器可执行的低级指令序列。
本节小结
- 位、字节、字:信息的基本单位层级——bit → Byte(8 bit)→ Word(取决于 CPU 架构)
- 简化模型:CPU(4 个 8-bit 寄存器 + ALU)+ Memory(16 字节,4 位地址),构成最小可工作的计算机
- 程序执行本质:一条 C 语句
k = i + j拆解为 4 步微操作——Load → Load → Compute → Store - 存算分离:CPU 运算速度(GHz)远快于内存(MHz),因此需要寄存器作为超高速中间缓存
- 存储层次:寄存器 → L1/L2 缓存 → 内存 → 磁盘,速度依次递减、容量依次递增
- X86 寄存器:32 位 CPU 有 8 个通用寄存器(EAX ~ ESP),用于存放整数和指针
- 冯诺依曼结构:五大部件——运算器、控制器、存储器、输入设备、输出设备;核心思想是"存储程序"
- VSPM 原型机:严格遵循冯诺依曼结构的教学计算机,12 条指令涵盖数据传送、算术运算、控制转移和 I/O
- 从 C 到机器码:高级语言经编译器翻译为低级指令序列,CPU 逐条取指、译码、执行

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)