BERT与GPT:Transformer架构下的理解与创造双雄,带你深入NLP核心技术!
BERT和GPT作为Transformer架构的杰出代表,分别擅长双向编码和单向生成任务。BERT通过同时关注上下文信息,实现全面的语言理解,适用于分类、问答等任务;GPT则依据单向生成机制,逐词预测生成文本,更适用于对话生成、文本续写等场景。本文深入剖析了BERT和GPT的架构特点、训练方法及实际应用,并通过代码示例展示了它们在自然语言处理领域的强大能力,为读者提供了理解与创造的双子星技术解析。
BERT(Bidirectional Encoder Representations from Transformers)和 GPT(Generative Pre-trained Transformer)作为 Transformer 架构的两大代表性模型,分别在双向编码和单向生成任务中展现了独特优势。BERT 采用双向编码器结构,能够同时关注上下文信息,适用于分类、问答等需要全面理解输入文本的任务;GPT 则基于单向生成器结构,按照从左到右的顺序生成文本,更擅长对话生成、文本续写等任务。
两者在任务适用性和信息处理方式上各有千秋,共同丰富了 Transformer 架构在自然语言处理领域的应用场景。
一、BERT 架构:双向理解的语言高手
BERT 架构基于双向编码器设计,通过同时关注上下文的前后信息,实现了全面的信息编码。其架构由多个 Transformer 编码层堆叠而成,每层包含自注意力机制和前馈神经网络(Feed-Forward Network),使模型能够捕获深层的语义信息。BERT 结构如图 1 所示。
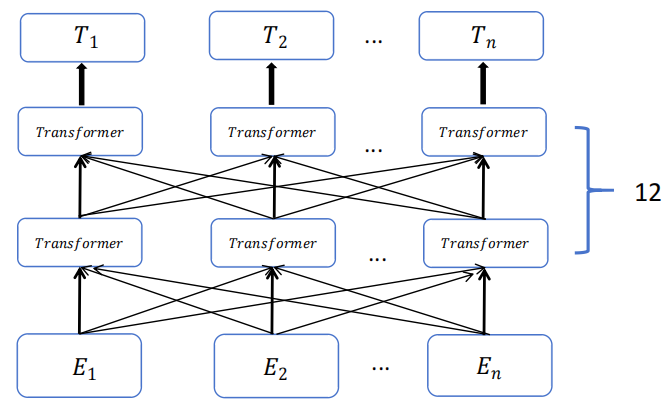
图1 BERT 语言模型结构图
BERT 通过掩码语言模型(Masked Language Model,MLM)任务进行预训练:在输入序列中随机掩盖部分词,然后根据上下文预测被掩盖的词。这种训练方式让模型学会了真正“理解”语言。
如果把 BERT 比作一位优秀的“语言理解高手”,它的任务就是通过阅读上下文,全面把握句子的含义。名字中的“Bidirectional”(双向)表明,它在理解句子时会同时考虑单词前后的信息,而非单向处理。
想象你正在玩一个拼图游戏,每一块拼图代表句子中的一个单词,只有正确组合才能完整表达句子的含义。BERT 就像一个“聪明的拼图助手”,它会仔细观察每一块拼图,分析它跟周围拼图的关系,最终帮你把句子拼完整。具体来说:
- Transformer 编码器:BERT 完全由一组 Transformer 编码器组成,每个编码器就像一个“拼图分析师”,关注每个单词与其他单词的关系。
- 自注意力机制:通过自注意力机制,BERT 可以为每个单词生成“权重分布”,告诉模型哪些单词对当前单词更重要。例如,在句子“我喜欢吃苹果”中,“喜欢”会特别关注“吃”和“苹果”,而对“我”的关注相对较少。
- 多层编码:BERT 有多层编码器(如12层或24层),每一层都会对单词和上下文关系进行更深层次的分析,就像“拼图助手”一遍遍检查拼图的组合方式。
此外,BERT 在句子对任务中引入了下一句预测(Next Sentence Prediction)任务,使其更适用于分类、问答等自然语言理解场景。以下代码展示了 BERT 架构的基本应用,包括模型加载、文本嵌入和双向信息编码。
import torchimport torch.nn as nnimport os# 设置 Hugging Face 镜像源,解决国内网络访问问题os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'from transformers import BertModel, BertTokenizer# 定义 BERT 分类模型class BERTClassifier(nn.Module): """ BERT 分类器模型 在预训练的 BERT 基础上添加一个分类头,用于文本分类任务 """ def __init__(self, bert_model_name, num_classes): """ 初始化 BERT 分类器 参数: bert_model_name: str, 预训练 BERT 模型名称,如 'bert-base-uncased' num_classes: int, 分类的类别数量 """ super(BERTClassifier, self).__init__() # 加载预训练的 BERT 模型 # from_pretrained 会从 Hugging Face 下载模型权重(如果本地没有缓存) self.bert = BertModel.from_pretrained(bert_model_name) # 全连接分类层 # bert.config.hidden_size 是 BERT 隐藏层维度,对于 bert-base-uncased 是 768 # 将 768 维的 BERT 输出映射到 num_classes 维,得到每个类别的分数 self.fc = nn.Linear(self.bert.config.hidden_size, num_classes) # Dropout 层,防止过拟合 # 以 0.3 的概率随机丢弃神经元,增强模型的泛化能力 self.dropout = nn.Dropout(0.3) def forward(self, input_ids, attention_mask): """ 前向传播函数 参数: input_ids: tensor, 形状 [batch_size, seq_len],文本的 token ID 序列 attention_mask: tensor, 形状 [batch_size, seq_len],注意力掩码,1 表示真实 token,0 表示 padding 返回: out: tensor, 形状 [batch_size, num_classes],每个类别的分数(logits) """ # 1. 通过 BERT 模型获取上下文表示 # outputs 包含多个元素:last_hidden_state, pooler_output, hidden_states 等 outputs = self.bert( input_ids=input_ids, attention_mask=attention_mask ) # 2. 提取 [CLS] 标记的隐藏状态 # BERT 的第一个 token 是 [CLS],它的输出被设计用于分类任务 # outputs.last_hidden_state 形状: [batch_size, seq_len, hidden_size] # [:, 0, :] 表示取所有样本的第一个 token([CLS])的所有隐藏维度 cls_output = outputs.last_hidden_state[:, 0, :] # 形状: [batch_size, hidden_size] # 3. 应用 Dropout 防止过拟合 cls_output = self.dropout(cls_output) # 4. 通过全连接层得到分类分数(logits) out = self.fc(cls_output) # 形状: [batch_size, num_classes] return out# ==================== 模型加载和推理部分 ====================# 加载 BERT 分词器和模型bert_model_name = 'bert-base-uncased'# BERT base 模型,uncased 表示不区分大小写print("正在加载模型和分词器...")# 加载分词器:将文本转换为 BERT 可接受的输入格式tokenizer = BertTokenizer.from_pretrained(bert_model_name)# 创建 BERT 分类器实例# num_classes=2 表示二分类任务(正面/负面情感分类)model = BERTClassifier(bert_model_name, num_classes=2)# 输入文本示例texts = [ "This is a positive example.", # 正面情感示例 "This is a negative example."# 负面情感示例]# 对文本进行编码,转换为模型输入格式encodings = tokenizer( texts, # 待编码的文本列表 return_tensors="pt", # 返回 PyTorch 张量格式 padding=True, # 对较短的序列进行填充,使所有序列长度一致 truncation=True, # 对过长的序列进行截断 max_length=32# 设置最大序列长度为 32)# 设置模型为评估模式# eval() 会关闭 dropout 和 batch normalization 的训练模式,使用固定的参数# 这对于推理非常重要,确保每次推理结果一致model.eval()# 模型推理(不计算梯度,节省内存和计算资源)# torch.no_grad() 上下文管理器会禁用梯度计算,大幅减少内存占用with torch.no_grad(): input_ids = encodings["input_ids"] # 获取 token IDs attention_mask = encodings["attention_mask"] # 获取注意力掩码 output = model(input_ids, attention_mask) # 前向传播,得到 logits# ==================== 输出结果解释 ====================print("\n" + "=" * 50)print("BERT模型输出详解")print("=" * 50)print("\nBERT模型输出形状:", output.shape)print("输出形状解释:")print(f" - 第0维({output.shape[0]}):批次大小(batch size),表示同时处理了 {output.shape[0]} 个样本")print(f" - 第1维({output.shape[1]}):类别数量,表示模型为每个样本预测 {output.shape[1]} 个类别的分数")print("\nBERT模型输出(logits):")print(output)print("\nLogits 解释:")print(" - Logits 是模型最后一层全连接层的原始输出,取值范围是 (-∞, +∞)")print(" - 数值越大表示模型认为该样本属于对应类别的可能性越大")print(f" - 第一个样本(正面示例):类别0分数={output[0][0]:.4f},类别1分数={output[0][1]:.4f}")print(f" - 第二个样本(负面示例):类别0分数={output[1][0]:.4f},类别1分数={output[1][1]:.4f}")# 应用 softmax 获取概率分布# Softmax 将 logits 转换为概率分布,确保所有类别的概率和为 1probabilities = torch.softmax(output, dim=-1)print("\n" + "=" * 50)print("概率分布详解")print("=" * 50)print("\n概率分布:", probabilities)print("\n概率分布解释:")print(" - Softmax 将 logits 转换为 [0, 1] 范围内的概率值")print(" - 所有类别的概率之和为 1")print(f" - 第一个样本:类别0(负面)概率={probabilities[0][0]:.4f},类别1(正面)概率={probabilities[0][1]:.4f}")print( f" → 预测为 {'正面' if probabilities[0][1] > probabilities[0][0] else '负面'},置信度={max(probabilities[0]):.2%}")print(f" - 第二个样本:类别0(负面)概率={probabilities[1][0]:.4f},类别1(正面)概率={probabilities[1][1]:.4f}")print( f" → 预测为 {'正面' if probabilities[1][1] > probabilities[1][0] else '负面'},置信度={max(probabilities[1]):.2%}")# 获取预测类别(取概率最大的类别索引)predictions = torch.argmax(probabilities, dim=-1)print("\n" + "=" * 50)print("最终预测结果")print("=" * 50)print("\n预测类别:", predictions)print("\n预测类别解释:")print(f" - 第一个样本('This is a positive example.')预测为类别 {predictions[0].item()}")print(f" → 类别映射:0=负面,1=正面,因此预测结果为:{'正面' if predictions[0].item() == 1 else '负面'}")print(f" - 第二个样本('This is a negative example.')预测为类别 {predictions[1].item()}")print(f" → 类别映射:0=负面,1=正面,因此预测结果为:{'正面' if predictions[1].item() == 1 else '负面'}")
运行结果如下:
==================================================BERT模型输出详解==================================================BERT模型输出形状: torch.Size([2, 2])输出形状解释: - 第0维(2):批次大小(batch size),表示同时处理了 2 个样本 - 第1维(2):类别数量,表示模型为每个样本预测 2 个类别的分数BERT模型输出(logits):tensor([[0.0925, 0.6015], [0.0993, 0.5602]])Logits 解释: - Logits 是模型最后一层全连接层的原始输出,取值范围是 (-∞, +∞) - 数值越大表示模型认为该样本属于对应类别的可能性越大 - 第一个样本(正面示例):类别0分数=0.0925,类别1分数=0.6015 - 第二个样本(负面示例):类别0分数=0.0993,类别1分数=0.5602==================================================概率分布详解==================================================概率分布: tensor([[0.3754, 0.6246], [0.3868, 0.6132]])概率分布解释: - Softmax 将 logits 转换为 [0, 1] 范围内的概率值 - 所有类别的概率之和为 1 - 第一个样本:类别0(负面)概率=0.3754,类别1(正面)概率=0.6246 → 预测为 正面,置信度=62.46% - 第二个样本:类别0(负面)概率=0.3868,类别1(正面)概率=0.6132 → 预测为 正面,置信度=61.32%==================================================最终预测结果==================================================预测类别: tensor([1, 1])预测类别解释: - 第一个样本('This is a positive example.')预测为类别 1 → 类别映射:0=负面,1=正面,因此预测结果为:正面 - 第二个样本('This is a negative example.')预测为类别 1 → 类别映射:0=负面,1=正面,因此预测结果为:正面进程已结束,退出代码为 0
注意:由于分类头是随机初始化的(未经过训练),预测结果可能与预期不符。只有经过充分训练后,模型才能实现正确的分类。以上代码仅为示例演示。
二、GPT 架构:单向生成的创作大师
GPT 基于单向生成器架构,通过从左到右的顺序预测下一个词来生成文本。与 BERT 的双向注意力机制不同,GPT 采用单向注意力机制,仅依赖先前的上下文信息,这使得它天然适合自然语言生成任务,如文本续写和对话生成。GPT 架构由多个 Transformer 解码层堆叠而成,每层包含自注意力机制和前馈神经网络。
以下代码展示了 GPT 的基本应用,包括模型加载、输入编码、文本生成等,充分展现了GPT在生成任务中的强大能力。
# ==================== 导入必要的库 ====================import torch # PyTorch深度学习框架,用于张量计算和神经网络import torch.nn as nn # PyTorch的神经网络模块import os # 操作系统接口,用于设置环境变量import sys # 系统相关功能,用于程序退出控制# ==================== 配置环境 ====================# 设置 Hugging Face 镜像源,解决国内网络访问问题# HF_ENDPOINT 环境变量指定 Hugging Face 模型的下载源# 使用镜像站可以大幅提高国内用户的下载速度os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 从 transformers 库导入 GPT-2 模型和分词器# transformers 是 Hugging Face 开发的预训练模型库# GPT2LMHeadModel: GPT-2 语言模型,专门用于文本生成任务# GPT2Tokenizer: GPT-2 的分词器,负责文本和token之间的转换from transformers import GPT2LMHeadModel, GPT2Tokenizer# ==================== 模型加载部分 ====================print("开始加载 GPT-2 模型...")print("首次运行会下载模型文件(约500MB),请耐心等待...")try: # ---------- 加载分词器 ---------- # Tokenizer(分词器)的作用: # 1. 将文本字符串转换为模型可理解的数字ID序列 # 2. 处理特殊token(如开始符、结束符、填充符等) # 3. 管理词汇表(GPT-2的词汇表大小约50,000) tokenizer = GPT2Tokenizer.from_pretrained( "gpt2", # 模型名称,可选值: "gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl" # resume_download=True, # 注意:此参数在新版transformers中已移除,自动支持断点续传 # use_auth_token=False # 注意:此参数已废弃,无需指定 ) # from_pretrained() 会: # - 检查本地缓存中是否有模型 # - 如果没有,从 Hugging Face 下载 # - 自动处理断点续传 print("✓ 分词器加载完成") # ---------- 加载模型 ---------- # GPT-2 模型架构: # - 12层 Transformer 解码器(基础版) # - 768维隐藏层 # - 12个注意力头 # - 约1.24亿参数 model = GPT2LMHeadModel.from_pretrained( "gpt2", # 与分词器使用相同的模型版本 ) print("✓ 模型加载完成") except Exception as e: # 如果加载失败,打印错误信息并退出 print(f"加载失败: {e}") print("请检查网络连接或尝试其他方法") print("\n解决方案建议:") print("1. 检查网络连接是否正常") print("2. 尝试使用VPN或代理") print("3. 手动下载模型: pip install huggingface_hub && huggingface-cli download gpt2") sys.exit(1) # 使用状态码1表示异常退出# ==================== 模型配置 ====================# 设置填充token(Padding Token)# GPT-2 模型默认没有设置 pad_token,需要手动配置# 填充token的作用:# - 使同一个batch中的序列长度一致# - 在生成时用于指定停止位置if tokenizer.pad_token isNone: # 使用结束符(End Of Sentence)作为填充符 # eos_token: 表示文本结束的特殊token,通常是 "<|endoftext|>" tokenizer.pad_token = tokenizer.eos_token print(f"已设置 pad_token: {tokenizer.pad_token}")# ==================== 输入准备 ====================# 定义输入文本作为生成的起点(提示词)input_text = "Once upon a time in a distant land,"# 将输入文本转换为token ID序列# encode() 方法的工作流程:# 1. 将文本分割成tokens(使用Byte-Pair Encoding)# 2. 将每个token映射到词汇表中的数字ID# 3. 添加特殊token(如开始符)# return_tensors="pt": 指定返回PyTorch张量格式# pt = PyTorch, tf = TensorFlow, np = NumPyinput_ids = tokenizer.encode(input_text, return_tensors="pt")# 查看输入信息的形状和内容(可选调试信息)print(f"\n输入文本: {input_text}")print(f"输入token数量: {input_ids.shape[1]}") # shape: [batch_size, sequence_length]print("开始生成文本...")# ==================== 文本生成 ====================# generate() 方法:GPT-2的核心生成函数# 使用自回归方式生成文本,即逐个预测下一个token# 生成过程:输入 -> 预测下一个token -> 拼接到输入 -> 重复直到满足条件output_sequences = model.generate( # ----- 基础参数 ----- input_ids=input_ids, # 输入的token ID序列,形状为 [1, 输入长度] # 这是生成的起点 max_length=50, # 生成的最大总长度(包括输入文本) # 例如:输入10个token,最多生成40个新token # 当达到此长度时停止生成 num_return_sequences=1, # 返回的生成序列数量 # 可以设置为 >1 生成多个不同的续写结果 # 每个序列独立采样 # ----- 防止重复参数 ----- no_repeat_ngram_size=2, # 防止重复的n-gram # 2表示禁止任何2-gram(连续两个token)重复出现 # 例如:如果已经出现"the cat",就不能再次出现"the cat" # 这样可以提高生成文本的多样性,避免循环 # ----- 采样策略参数 ----- top_k=50, # Top-K 采样 # 原理:只从概率最高的K个token中进行采样 # 设置50:只考虑概率最高的50个候选token # 优点:过滤掉低概率的不合理token # 缺点:可能会过滤掉一些创意性的选择 # 常用范围:10-100 top_p=0.95, # Top-P(核)采样 # 原理:选择概率最高的token,直到累计概率达到p # 设置0.95:选择一组token,使其总概率达到95% # 与top_k结合使用,动态调整候选token数量 # 常用范围:0.8-1.0 temperature=0.7, # 温度参数 # 原理:控制概率分布的平滑程度 # 公式:p'(x) = exp(log(p(x))/temperature) # # 效果: # - 温度 < 1:使分布更陡峭,高概率token更高,生成更确定 # - 温度 = 1:原始概率分布 # - 温度 > 1:使分布更平滑,低概率token概率提高,生成更有创意 # # 常用值: # - 0.3-0.5:保守、确定性生成 # - 0.7-0.9:平衡创意和质量(推荐) # - 1.0-1.2:创意性生成 # ----- 其他参数 ----- pad_token_id=tokenizer.pad_token_id, # 填充token的ID # 用于确保所有序列长度一致 # 生成时遇到pad_token会停止)# ==================== 结果解码 ====================# 将生成的token ID序列解码回可读文本# output_sequences[0]: 获取第一个生成序列(因为num_return_sequences=1)# decode() 的工作流程:# 1. 将每个token ID映射回对应的文本token# 2. 将tokens拼接成完整的字符串# 3. 处理特殊tokengenerated_text = tokenizer.decode( output_sequences[0], # 要解码的token序列 skip_special_tokens=True# 跳过特殊token(如<|endoftext|>、<pad>等) # 只保留实际文本内容)# ==================== 输出结果 ====================print("\n" + "=" * 50)print("GPT 模型生成的文本:")print(generated_text)print("=" * 50)# ==================== 附加统计信息 ====================# 打印生成过程的统计信息,帮助理解生成效果input_token_count = input_ids.shape[1] # 输入token的数量output_token_count = output_sequences.shape[1] # 输出总token数量new_token_count = output_token_count - input_token_count # 新生成的token数量print(f"\n生成统计信息:")print(f"- 输入文本长度: {len(input_text)} 字符")print(f"- 输出文本长度: {len(generated_text)} 字符")print(f"- 输入token数量: {input_token_count}")print(f"- 输出总token数量: {output_token_count}")print(f"- 新生成token数量: {new_token_count}")
运行结果示例:
从运行结果可以看出,GPT 模型能够基于给定的开头,生成连贯流畅的故事文本,充分展现了其在自然语言生成任务中的卓越能力。
三、总结:理解与创造的双子星
BERT 和 GPT 代表了 Transformer 架构在自然语言处理领域的两个重要方向:
- BERT 像一位严谨的学者:通过双向理解,全面把握文本含义,在分类、问答等理解型任务中表现出色。
- GPT 像一位富有创意的作家:通过单向生成,源源不断地创造新文本,在续写、对话等生成型任务中独树一帜。
两者各有所长,相辅相成。理解它们的设计哲学和适用场景,能够帮助我们在实际应用中做出更明智的模型选择。随着大模型技术的不断发展,BERT 和 GPT 的思想也深深影响着后续模型的设计,成为现代自然语言处理不可或缺的基础。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)