论文文本分析怎么做?以京东手表评论为例,词云图、情感分析、主题分析等
在论文写作中,文本数据如问卷开放题、用户评论、访谈记录等越来越常见,但如何对这些非结构化数据进行规范分析,仍然是很多人的难点。很多人一听“文本分析”,第一反应是:需要写代码、要学Python、门槛很高。但实际上,文本分析用SPSSAU软件就可以完成。
本文将以京东某品牌手表的真实评论为例,介绍SPSSAU完成文本分析的基本流程,一次性演示词云图、情感分析、文本聚类、社会网络关系图、LDA主题分析这五大功能。
一、数据准备与上传
案例数据:京东某智能手表评论区,共100条有效评论(虚拟数据仅用于演示分析)。
1、文本分析数据格式
(1)Excel格式:将文本全部放置于A列中,A列不需要有标题信息,每行(即每个单元格)存在1个分析文本。类似如下图所示: 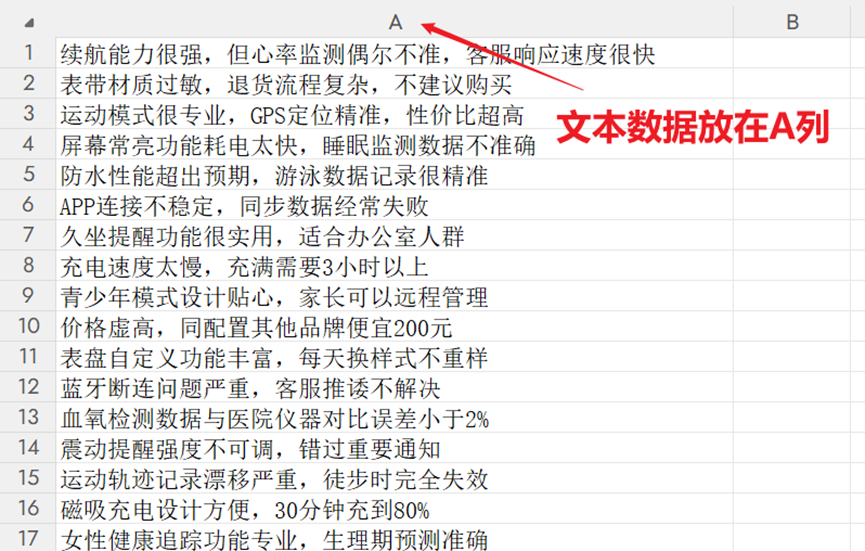
(2)粘贴文本:如果是txt文档或者粘贴文本进行上传,那么系统会自动过滤掉空行数据,并且以回车键作为每行(即每个分析文本)标志。 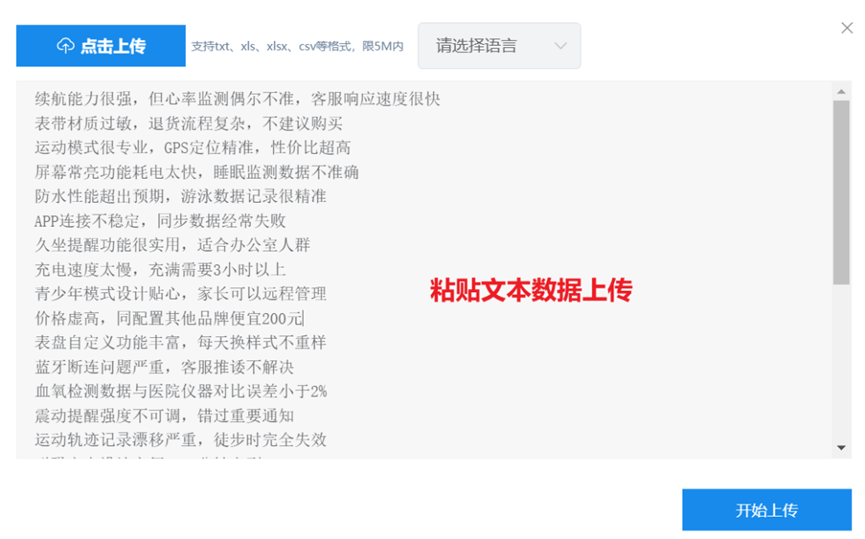
2、进入SPSSAU文本分析
(1)在SPSSAU页面左侧点击进入【文本分析模块】:

(2)“点击上传”按钮:上传或粘贴整理好的评论数据,等待片刻分析完成后,点击“进入项目”按钮,即可查看对应的文本分析结果,操作如下图:
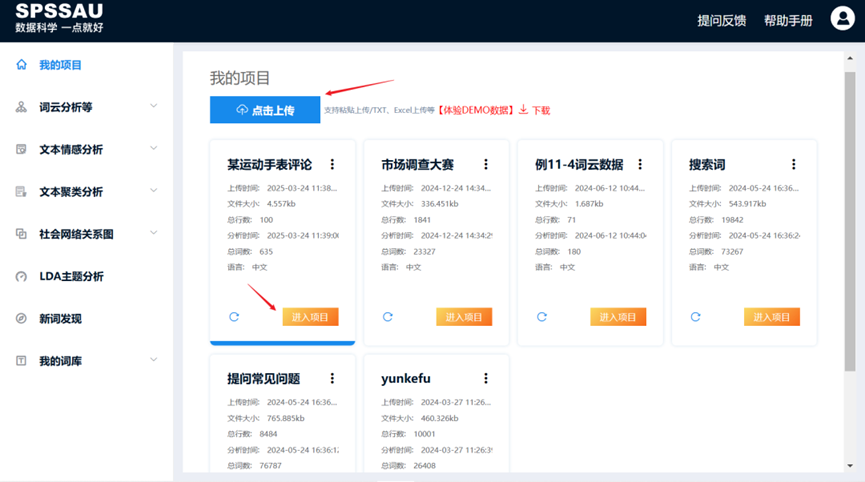
【提示】:当前SPSSAU文本分析模块限制周会员及以上用户使用。
- 文本分析结果:SPSSAU文本分析结果包括词云分析、文本情感分析、文本聚类分析、社会网络关系分析、LDA主题分析、新词发现和我的词库等。接下来分别进行简单介绍。
二、词云图分析
文本分析模块中,最重要和最基础的为展示分词结果,通常是使用词云图进行展示。
1、词云分析
词云图是一种基于词频统计的文本可视化方法,通过对文本中词语出现频次进行统计,并以图形方式呈现其重要程度。一般而言,词语出现频率越高,在图中显示越突出。该方法能够直观反映文本中的核心内容与高关注点,为后续分析提供基础参考。
SPSSAU输出词云图结果如下:词云图默认展示前100个高频词,用户可自主设置该数字,也可修改词云风格和下载词云图。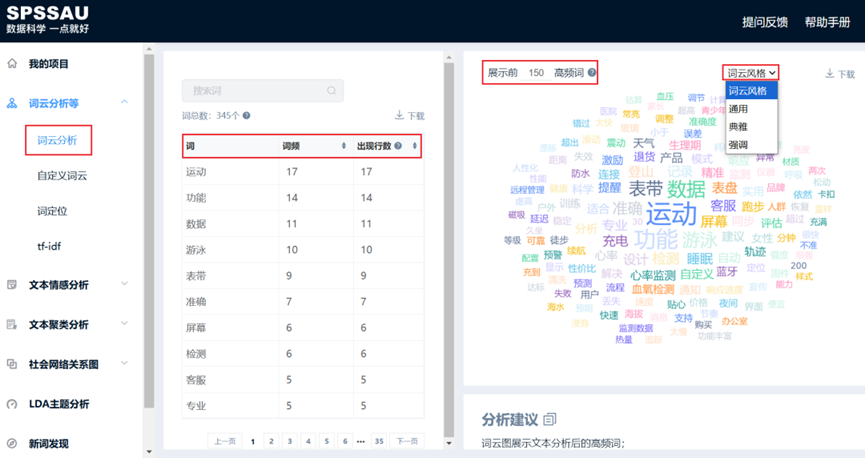
分析词云图可知:
- 运动手表的市场反馈呈现出明显的“功能驱动型”特征。以“运动” 、 “功能” 、 “数据”及“专业”关注视觉中心,表明用户核心其运动监测能力的关注度最高;
- 具体场景中, “游泳” 、 “跑步” 、 “睡眠”和“心率/血氧检测”是高频聚焦的应用点。
- 此外, “近距离” 、 “屏幕”和“表带”等硬件素质也是用户评价的关键指标。
2、自定义词云
SPSSAU支持自定义词云,该功能为用户提供了高度灵活的视觉化方案。输入关键词及其对应词频,系统即可实时渲染词云矩阵。如下图所示:
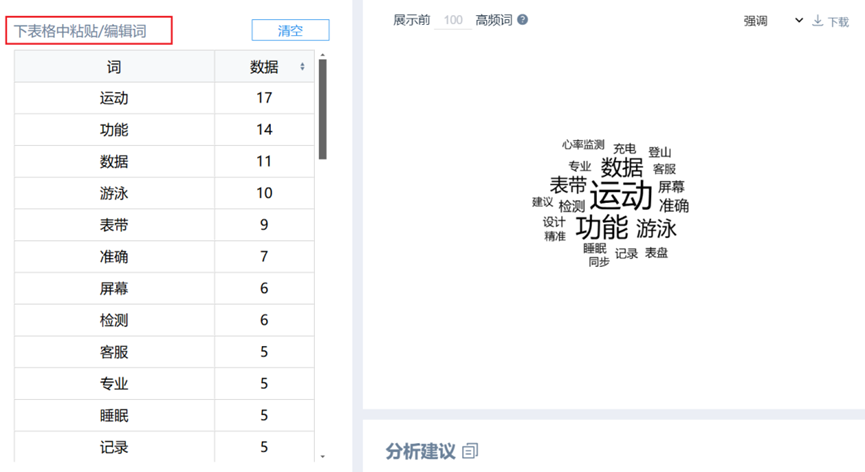
3、词定位
词定位功能支持对关键词进行全文溯源:只需在SPSSAU中点击或直接搜索目标词汇,系统即可实时定位展示其在原文中的所有出现位置。如下图所示: 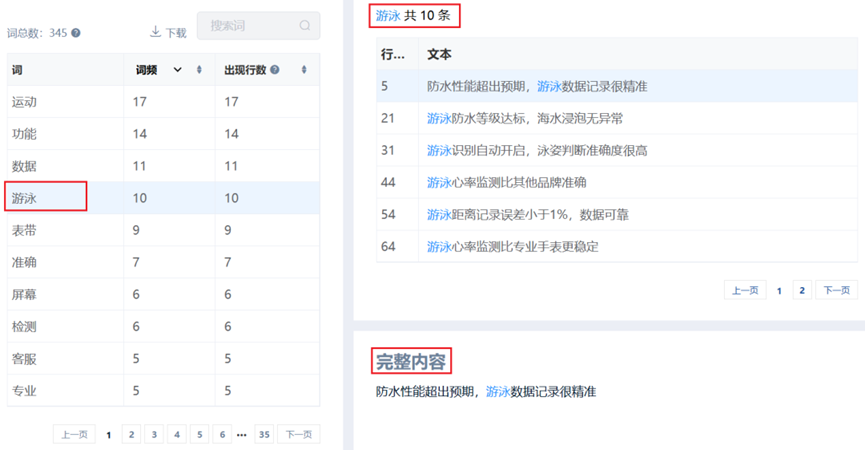
4、TF-IDF
文本分析中,TF-IDF是个重要的指标,其反映某关键词在整份数据中的重要性程度,当TF-IDF越高时,其重要性越高。TF-IDF计算时包括2个指标——TF和IDF,下面分别进行介绍:
- 指标1:TF
TF(Term Frequency,词频),其表示某个关键词的出现次数(并且进行归一化处理),TF越高意味着出现频率越高,那么其重要性也会越高。
- 指标2:IDF
IDF(Inverse Document Frequency,逆文档频率),其为‘到处出现’的体现,当关键词到处出现时,说明该关键词可能是常用词(比如“你好”)不那么重要,因而idf应该低,如果关键词不是到处出现,那么说明该关键词可能重要性高,因而idf应该高。
- TF-IDF计算公式
TF-IDF = TF * IDF,具体公式如下:
- TF = n / N,其中n为某关键词的词频,N为整份数据关键词词频总和;
- IDF = log(D/(1+d)),log是取对数,D为数据的行数,d为数据中某个词在多少行中出现过。
在SPSSAU中默认按从大到小输出TF-IDF值,计算结果及对应词云图如下:
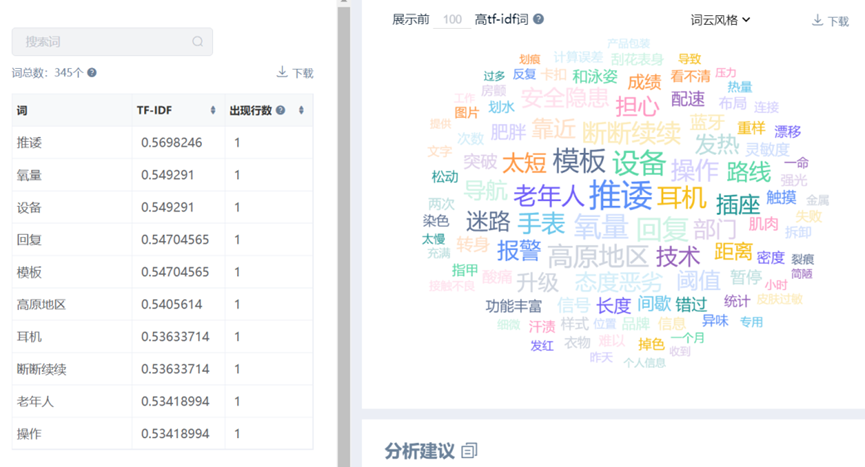
分析TF-IDF结果,从词项分布来看,用户讨论主要集中在以下方面:
- 产品体验层面,“划痕”“刮花表身”“松动”“接触不良”“计算误差”等词出现,反映出用户对产品物理质量与功能精准度的敏感;
- 健康监测功能方面,“房颤”“氧量”“心率”“漂移”等专业术语的突显,说明用户对健康数据的准确性与医学价值有较高期待;
- 佩戴舒适度与外观维度中,“颜值”“皮肤过敏”“汗渍”“发红”等词揭示了外观设计与材质亲肤性对用户体验的重要影响。
- 此外,“推诿”“态度恶劣”“安全隐患”等负面情感词的出现,提示售后服务与产品安全性是当前用户评价中的潜在风险点。
点击下方链接进入方法帮助手册:
二、文本情感分析
文本情感分析是对文本中所表达情绪倾向进行识别与分类的方法,通过对文本数据的情感分布进行统计,可以从整体上把握用户态度与满意程度,为评价分析与决策提供依据。情感分析使用情感词典进行情感得分计算,并且经过SPSSAU数据压缩化,将情感得分压缩在-1~1之间。关于情感方向的判断标准具体规则如下表:
|
情感分值区间 |
情感方向 |
|
[-1, -1/3) |
负向 |
|
[-1/3, 0) |
偏负向 |
|
[0, 1/3) |
偏正向 |
|
[1/3, 1] |
正向 |
|
没有分值时 |
情感词典中无该词 |
SPSSAU文本情感分析可按词或按行进行情感分析:

1、按词情感分析
SPSSAU输出按词情感分析结果示例如下:
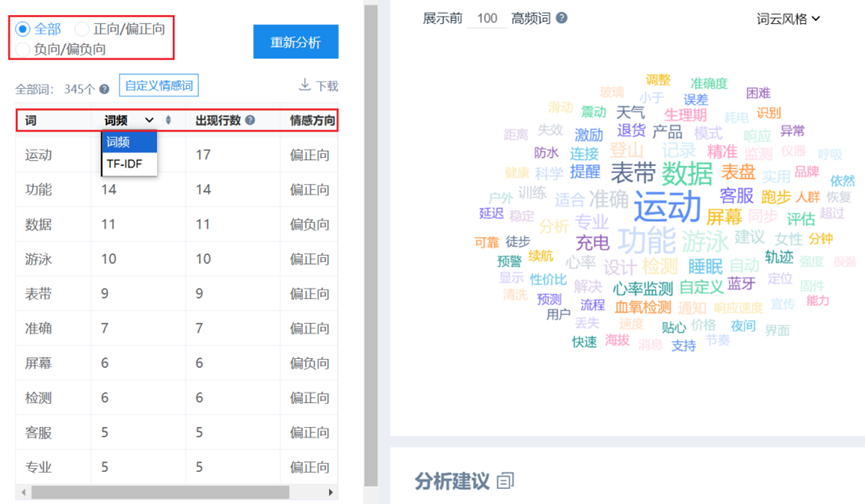
表格中包括各关键词的词频信息(也可下拉选择tf-idf)和其出现行数,默认按词频降序排序,右侧展示词云。表格上方可以点击‘正向/偏正向’或者‘负向/偏负向’切换展示具有情感方向的关键词,并且右侧词云会跟随变化。点击关键词可以出现其词定位信息,如下图:

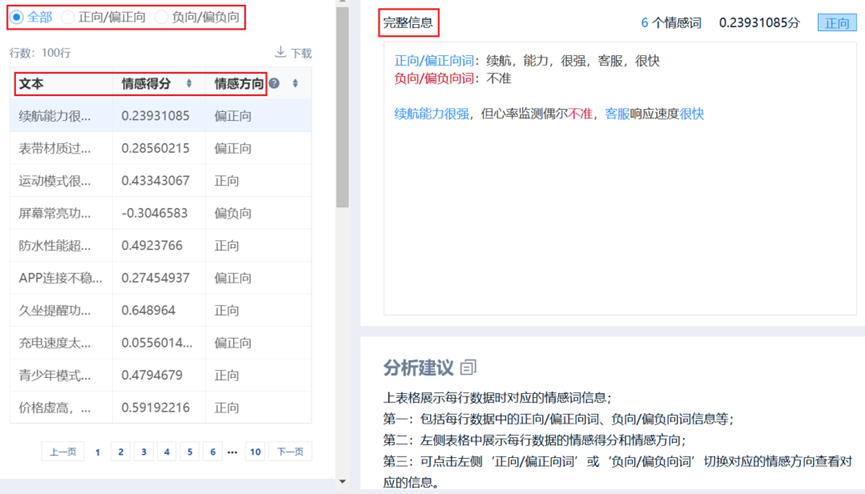
2、按行情感分析
按行情感分析是指针对分析的原始数据以‘行’为单位进行情感分析,并且可下载具体的情感得分值信息等。SPSSAU输出按行情感分析结果如下:
三、文本聚类分析
文本聚类分析是一种将内容相似的文本自动归类的方法。通过计算文本之间的相似度,将结构和语义相近的文本分在同一组,从而发现潜在的分类规律。
SPSSAU提供按词聚类分析与按行聚类分析。
1、按词聚类分析
按词聚类分析旨在对关键词进行聚类并实现可视化呈现,研究者可自由选择待分析的关键词。系统默认提取词频排名前20的关键词,基于词向量值执行K-means聚类,随后通过多维标度分析(MDS)计算各关键词的坐标定位,最终输出聚类可视化结果。图中不同颜色代表不同类别,清晰反映了关键词之间的类别归属关系。SPSSAU输出按词聚类分析结果示例如下图所示。
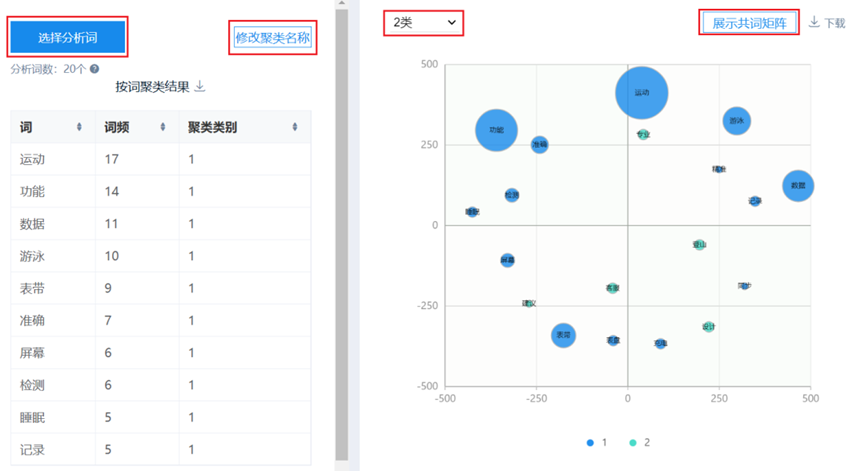
2、按行聚类分析
不同于按词聚类分析,按行聚类分析是指以‘行’为单位,针对每行数据进行聚类分析(具体为kmeans聚类),并且计算出各‘行’数据的聚类类别,也可直接进行下载聚类类别信息。SPSSAU分析结果如下图所示:
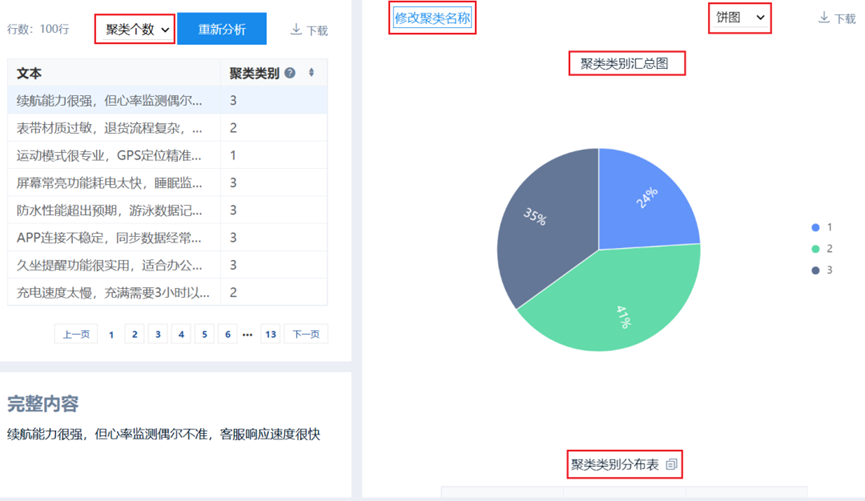
下载按行聚类结果分析可知,将手表评论分为三个核心类别:
- 类别1为功能赞誉与专业应用:此类评论主要集中在产品的专业功能指标和高性能上。
- 类别2为硬伤吐槽与售后不满:此类是典型的负面评价点,涉及硬件质量、佩戴舒适度及服务体验。
- 类别3为深度场景使用与数据精度:这一类评论的反馈与中评之间,更多的是在特定使用场景(如游泳、高海拔登山、办公室久坐)下对数据的细节反馈。
四、共词矩阵与社会网络关系图
社会网络关系图是基于词语共现关系(共词矩阵)构建的网络结构,通过分析文本中词语之间的关联程度,揭示其内在联系。图中节点代表关键词,连接关系反映词语之间的共现强度。该方法有助于从结构角度理解文本内容及其组织方式。
1、共词矩阵
第1行和第1列为关键词名称且完全对应,具体数据上,右下三角斜对角线为该词的词频,其它数字为两词“共现”次数(每行‘共现’次数之和)。SPSSAU输出共词矩阵结果如下:
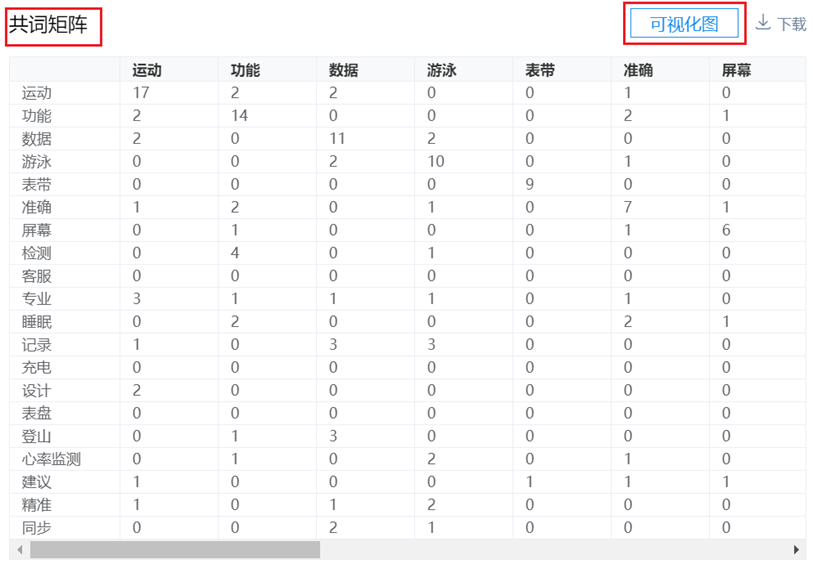
例如分析上面共词矩阵可知,“运动”词频为17,“功能”和“运动”两词一起出现过2次......
2、社会网络关系图
社会网络图关系基于共词矩阵构建,旨在揭示关键词间的语义关联。矩阵节点间的连线表征了词汇的共现关系:若共现频率次大零,则判定为关联。
SPSSAU输出社会网络关系图如下:
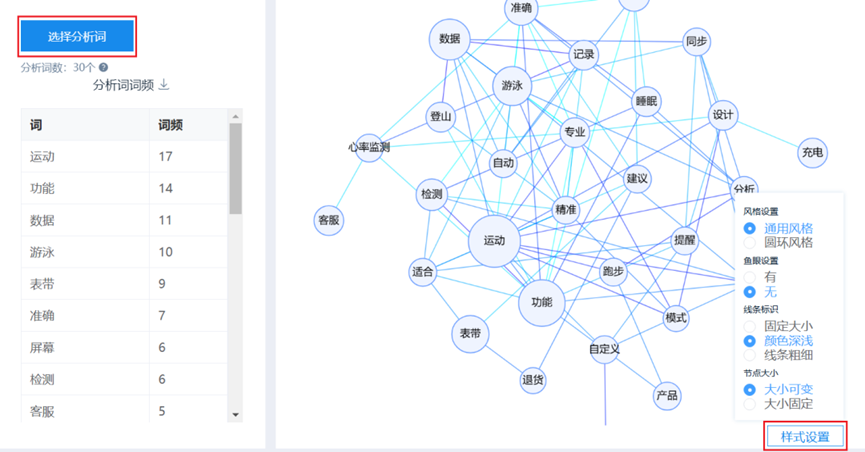
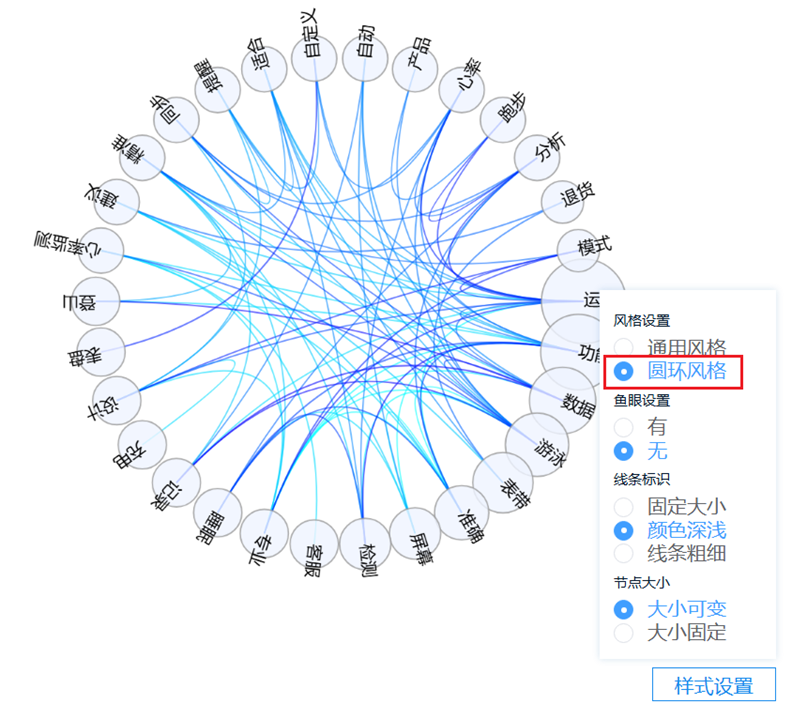 在社会网络关系图时,可通过“样式设置”切换图形风格等,例如选择是否有鱼眼,使用线条粗细展示共词次数,越粗则表示共词次数越高,当然也可选择颜色深浅或者固定线条大小。
在社会网络关系图时,可通过“样式设置”切换图形风格等,例如选择是否有鱼眼,使用线条粗细展示共词次数,越粗则表示共词次数越高,当然也可选择颜色深浅或者固定线条大小。
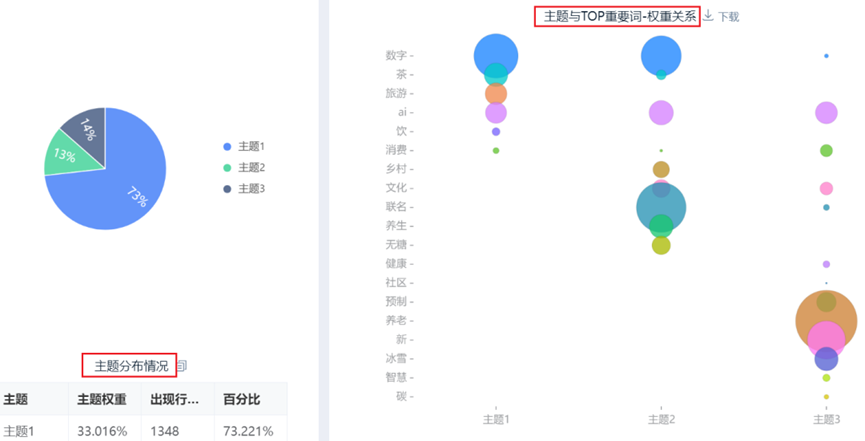
五、LDA主题分析
LDA主题分析是一种常用的文本主题挖掘方法,通过对文本中词语分布特征进行建模,将文本划分为若干潜在主题。每个主题由一组具有代表性的关键词构成,从而反映文本的主要内容结构。该方法能够从整体上揭示文本的主题分布特征。
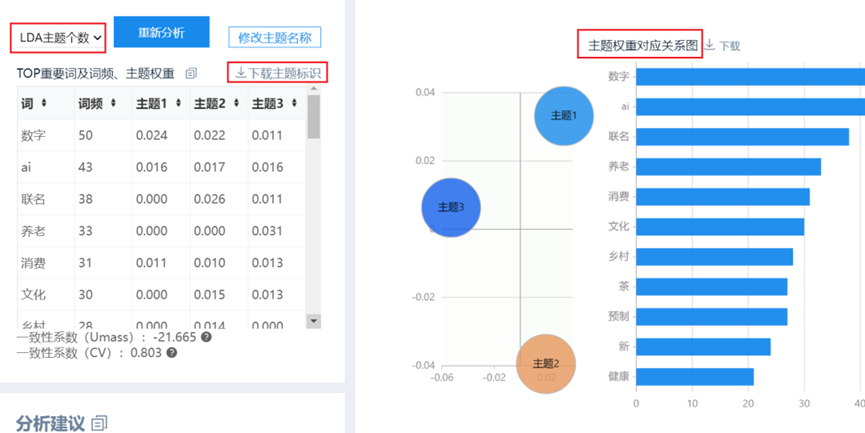
SPSSAU输出LDA主题分析包括以下结果:
|
项 |
说明 |
|
主题与关键词权重表格 |
表格化展示各主题与关键词的权重值 |
|
主题与关键词权重对应关系图 |
可视化展示各主题与关键词的权重值,点击主题气泡时可仅展示该主题时关键词的权重(且从大到小排序) |
|
主题分布表格 |
展示各行隶属的主题编号 |
|
主题与关键词权重对应气泡图 |
可视化展示各主题与关键词的权重值,气泡越大说明权重越大 |
|
修改主题名称 |
确认好主题的实际名称后,可修改主题名称,重新展示表格和图信息等 |
本案例虚拟数据样本较少质量较差,主题分析结果并不合理,故展示其他文本数据主题分析结果,SPSSAU输出LDA主题分析部分结果示例如下:
六、新词发现&我的词库
1、新词发现
在文本分析过程中,预设搜索往往存在滞后性,难以覆盖如“大模型”等新兴专业术语。为此,可引入新词发现算法进行识别。该算法主要依托两个关键指标:
- 信息熵:衡量词语与上下文组合的自由度,即左右邻接词的多样性程度;
- 互信息:表征词语内部片段之间的结合紧密性与结构稳定性。
但具体情况还需要研究者结合新词发现和其实际意义进行综合决择,并无固定标准。SPSSAU新词发现结果如下:
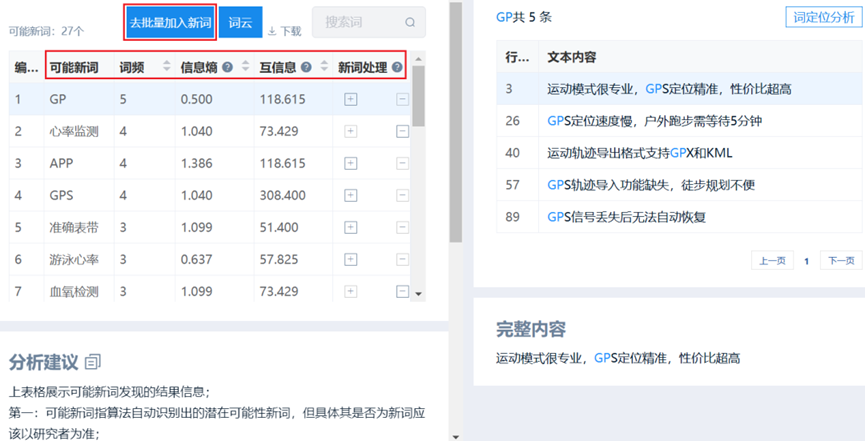
当判定为新词时,可批量将其加入到新词词库中,重新进行文本分析,以便得到更准备的文本分析结果。
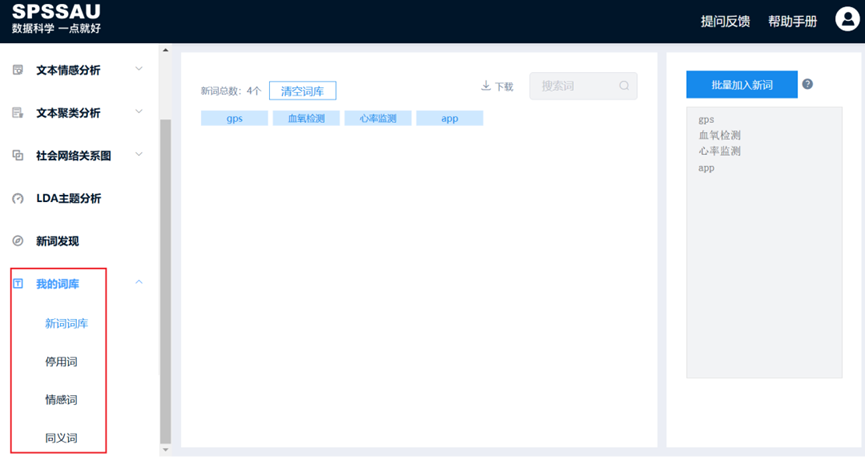
2、我的词库
在文本分析中,研究者常需对词库进行自定义调整以提升分析精度。具体而言:
- 对于“内卷”等出现的新词,可将其纳入新词词库,确保系统在词频统计等环节予以识别;
- 对于“好了”等无实际语义贡献的停用词,则可将其设置为停用词以排除干扰;
- 可依据研究需要设定情感词,如将“元宇宙”赋予正向或负向的情感分值;
- 还可设置同义词,多个同义词时以逗号隔开,比如:“北京:北京市,北平。
在SPSSAU中,上述操作可通过点击“我的词库”模块完成,操作界面如下图所示。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)