用户购买行为分析
数据集:Customer Purchase Behavior Dataset (E-Commerce)
一、数据加载与预处理
1、加载数据集
import pandas as pd
data = pd.read_csv('D:\Kaggle\电商客户购买行为数据集\customerData_500k.csv')2、查看数据表头和基本信息
data.head()| Age | AnnualIncome | NumberOfPurchases | TimeSpentOnWebsite | CustomerTenureYears | LastPurchaseDaysAgo | Gender | ProductCategory | PreferredDevice | Region | ReferralSource | CustomerSegment | LoyaltyProgram | DiscountsAvailed | SessionCount | CustomerSatisfaction | PurchaseStatus | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 37 | 57722.572411 | 19 | 5.908826 | 1.093430 | 11 | Male | Furniture | Desktop | South | Paid Ads | Regular | 1 | 5 | 3 | 2 | 1 |
| 1 | 63 | 21328.925876 | 10 | 6.970749 | 0.649246 | 20 | Female | Furniture | Mobile | East | Organic | VIP | 0 | 4 | 2 | 3 | 0 |
| 2 | 60 | 150537.742465 | 19 | 35.004954 | 3.858211 | 25 | Male | Electronics | Desktop | South | Organic | VIP | 1 | 2 | 5 | 2 | 0 |
| 3 | 19 | 63508.762549 | 10 | 14.818000 | 7.554374 | 20 | Male | Furniture | Desktop | West | Paid Ads | Premium | 0 | 0 | 1 | 3 | 0 |
| 4 | 54 | 100399.558368 | 19 | 55.925462 | 0.197411 | 92 | Male | Electronics | Mobile | South | Referral | Regular | 1 | 4 | 1 | 2 | 0 |
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 500000 entries, 0 to 499999
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 500000 non-null int64
1 AnnualIncome 500000 non-null float64
2 NumberOfPurchases 500000 non-null int64
3 TimeSpentOnWebsite 500000 non-null float64
4 CustomerTenureYears 500000 non-null float64
5 LastPurchaseDaysAgo 500000 non-null int64
6 Gender 500000 non-null object
7 ProductCategory 500000 non-null object
8 PreferredDevice 500000 non-null object
9 Region 500000 non-null object
10 ReferralSource 500000 non-null object
11 CustomerSegment 500000 non-null object
12 LoyaltyProgram 500000 non-null int64
13 DiscountsAvailed 500000 non-null int64
14 SessionCount 500000 non-null int64
15 CustomerSatisfaction 500000 non-null int64
16 PurchaseStatus 500000 non-null int64
dtypes: float64(3), int64(8), object(6)
memory usage: 64.8+ MB属性解释
年龄(int):客户的年龄(单位:年)。范围:15–81岁。
年收入(浮动收入):客户的年收入(美元计)。范围:11,966 – 204,178。
购买数量(int):客户的总购买次数。可以表示参与度。
网站停留时间(浮动):每次访问网站的平均时间(分钟)。
客户持有年数(浮动时间):客户加入平台以来的持续时间(以年计)。
最后一次购买天数(整数天):自客户最近一次购买以来的天数。
性别(分类:男性/女性):顾客的性别。
产品类别(分类:时尚、电子产品、家具、杂货、体育等):最常购买的产品类别。
首选设备(分类:移动/桌面/平板):客户最常用的设备。
地区(分类:北部、南部、东部、西部):客户的地理区域。
推荐源(分类:自然广告、付费广告、推荐、社交媒体、电子邮件):客户是如何发现该平台的。
客户细分(分类:常规、高级、VIP):业务定义的客户分类。
忠诚计划(二元:0/1):客户是否注册了忠诚度计划。
可使用折扣(int):客户兑换的折扣/优惠券数量。
会话计数(int):为客户记录的会话/访问数量。
客户满意度(int: 1–5):客户满意度评分(1 = 非常不满意,5 = 非常满意)。
购买状态(目标变量,二进制:0/1):购买成功与否3、英文列名转换为中文列名
# 定义列名映射关系
column_mapping = {
'Age': '年龄',
'AnnualIncome': '年收入',
'NumberOfPurchases': '购买次数',
'TimeSpentOnWebsite': '网站停留时间',
'CustomerTenureYears': '客户年限',
'LastPurchaseDaysAgo': '上次购买天数',
'Gender': '性别',
'ProductCategory': '产品类别',
'PreferredDevice': '偏好设备',
'Region': '地区',
'ReferralSource': '推荐来源',
'CustomerSegment': '客户细分',
'LoyaltyProgram': '忠诚度计划',
'DiscountsAvailed': '使用折扣次数',
'SessionCount': '访问次数',
'CustomerSatisfaction': '客户满意度',
'PurchaseStatus': '购买状态'
}
# 批量修改列名
data = data.rename(columns=column_mapping)
# 查看修改后的列名
print(data.columns)4、缺失值查看
data.isnull().sum()年龄 0
年收入 0
购买次数 0
网站停留时间 0
客户年限 0
上次购买天数 0
性别 0
产品类别 0
偏好设备 0
地区 0
推荐来源 0
客户细分 0
忠诚度计划 0
使用折扣次数 0
访问次数 0
客户满意度 0
购买状态 0
dtype: int645、重复值查看
data.duplicated().sum()0二、数据探索性分析
1、数值型数据统计分析
data.select_dtypes(include=['int64','float64']).describe()| 年龄 | 年收入 | 购买次数 | 网站停留时间 | 客户年限 | 上次购买天数 | 忠诚度计划 | 使用折扣次数 | 访问次数 | 客户满意度 | 购买状态 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 | 500000.000000 |
| mean | 43.941044 | 85071.804966 | 11.387584 | 30.594395 | 2.163483 | 60.191362 | 0.501110 | 3.154496 | 2.351750 | 3.219764 | 0.418354 |
| std | 15.756232 | 39586.271859 | 6.000702 | 17.585290 | 2.197354 | 54.886826 | 0.499999 | 1.879333 | 1.485597 | 0.826482 | 0.493289 |
| min | 15.000000 | 11966.385655 | -1.000000 | -3.804161 | -0.418429 | -11.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 0.000000 |
| 25% | 30.000000 | 51998.815726 | 6.000000 | 15.843041 | 0.592285 | 16.000000 | 0.000000 | 2.000000 | 1.000000 | 3.000000 | 0.000000 |
| 50% | 44.000000 | 83748.351846 | 12.000000 | 30.763164 | 1.466097 | 31.000000 | 1.000000 | 3.000000 | 2.000000 | 3.000000 | 0.000000 |
| 75% | 57.000000 | 116554.694607 | 16.000000 | 45.012866 | 3.009516 | 105.000000 | 1.000000 | 5.000000 | 3.000000 | 4.000000 | 1.000000 |
| max | 81.000000 | 204178.294436 | 28.000000 | 78.364251 | 15.346356 | 189.000000 | 1.000000 | 10.000000 | 12.000000 | 5.000000 | 1.000000 |
2、数值型数据直方图分布
import matplotlib.pyplot as plt
import matplotlib
import math
plt.rcParams['figure.dpi'] = 600
# 配置中文字体适配(兼容不同操作系统)
# 按优先级尝试加载常见中文字体
font_candidates = [
'SimHei', # Windows: 黑体
'Microsoft YaHei', # Windows: 微软雅黑
'PingFang SC', # macOS: 苹方
'Heiti TC', # macOS: 黑体
'WenQuanYi Micro Hei' # Linux: 文泉驿
]
matplotlib.rcParams['font.sans-serif'] = font_candidates
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示乱码问题
palette = [
'#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FECA57',
'#FF9FF3', '#54A0FF', '#5F27CD', '#00D2D3', '#FF7F50', '#98D8C8'
]
df_numeric = data.select_dtypes(include=['int64', 'float64'])
feature_count = len(df_numeric.columns)
# math.ceil向上取整每行3个图
rows = math.ceil(feature_count / 3)
fig, ax_array = plt.subplots(rows, 3, figsize=(15, 3 * rows))
# 将多维的坐标轴数组展平为一维,方便通过索引访问
ax_array = ax_array.flatten()
for idx, col_name in enumerate(df_numeric.columns):
current_color = palette[idx % len(palette)]
ax_array[idx].hist(df_numeric[col_name].dropna(),
bins=20,
color=current_color,
alpha=0.7,
edgecolor='black')
ax_array[idx].set_title(f'{col_name}分布', fontsize=12)
ax_array[idx].set_xlabel(col_name, fontsize=10)
ax_array[idx].set_ylabel('频数', fontsize=10)
# 如果特征数量不足以填满最后一行,隐藏剩余的坐标轴
for j in range(feature_count, len(ax_array)):
ax_array[j].set_visible(False)
# 自动调整子图间距,防止重叠
plt.tight_layout()
plt.show()
用户画像类特征:年龄、年收入、客户年限。年龄呈现出一种多峰分布,平台的用户群体覆盖了主要的劳动力人口。营销策略需要针对不同年龄段推送不同品类的商品。年收入呈现右偏分布,中低收入段集中,高收入段长尾很长,绝大部分用户属于工薪阶层,高收入用户极少,平台主流商品定价应当匹配工薪阶层消费水平,针对高收入长尾用户可以设立高端精选的内容频道。客户年限极度右偏,绝大部分用户是0-2年新客户,平台可能还处于快速扩张器,不断有新用户涌入,但老用户(5年以上)留存少,重点在于提高新课的转存率,对于新用户要有新手引导、首单优惠等活动。行为参与度特征:网站停留时长、访问次数、购买次数、上次购买天数、使用折扣次数。网站停留时长接近正态分布,中心在30-40分钟,说明大部分用户有实质性的浏览行为,这个长度的停留时间意味着用户在深度对比产品或阅读内容,用户停留意愿较高,可以再页面中增加猜你喜欢、相关推荐来提高转化率。访问次数极度右偏,大部分用户访问次数集中在1-2次,说明平台面临严重的留存问题,多数用户为低频访客,极少数用户会高频访问,这是业务痛点,可以通过邮件营销、推送通知、会员积分体系等激励用户在一个月内多次访问。访问次数呈现多峰分布,说明用户分层很明显,需要分析将中间低谷的用户购买次数拉升。用户上次购买天数在0-50天有集中趋势,这部分用户很活跃,但仍有大部分用户上次购买天数在50-180天,他们处于沉睡或流失边缘,针对50天以上未购买的用户需要启动会召回机制,开展回归活动。使用折扣次数集中在2-5次,大部分用户会使用折扣,但次数没有特别高,说明平台的折扣策略相对健康,用户既享受了优惠,有没完全依赖折扣。
关键指标:客户满意度、购买状态。客户满意度3分中立最多,4分次之,1分和5分很少,大多数用户对平台感觉“一般般”,没有极度的爱也没有极度的恨,需要平台提升服务体验,争取把“3分”用户转化为满意的用户,中立用户最容易被竞争对手抢走。购买状态分布不平衡,未购买的接近30万,已购买接近20万,未购买的用户远远多余购买用户,在模型训练中,如果只看准确率,模型可能会倾向于预测未购买。必须使用F1-score、AUC 或召回率来评估模型,并考虑使用过采样或调整类别权重。
3、数值型特征相关性热力图
import seaborn as sns
import matplotlib.pyplot as plt
# 1. 数据预处理
numeric_data = data.select_dtypes(include=['int64', 'float64'])
corr_matrix = numeric_data.corr().round(2)
# 2. 画布设置
plt.figure(figsize=(12, 10))
# 3. 绘制热力图
sns.heatmap(
corr_matrix,
annot=True,
cmap='RdYlGn',
vmin=-1, vmax=1,
center=0,
fmt='.2f',
linewidths=0.5,
linecolor='lightgray'
)
# 4. 样式调整
plt.title('数值型特征相关性热力图', fontsize=14, pad=20)
plt.tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()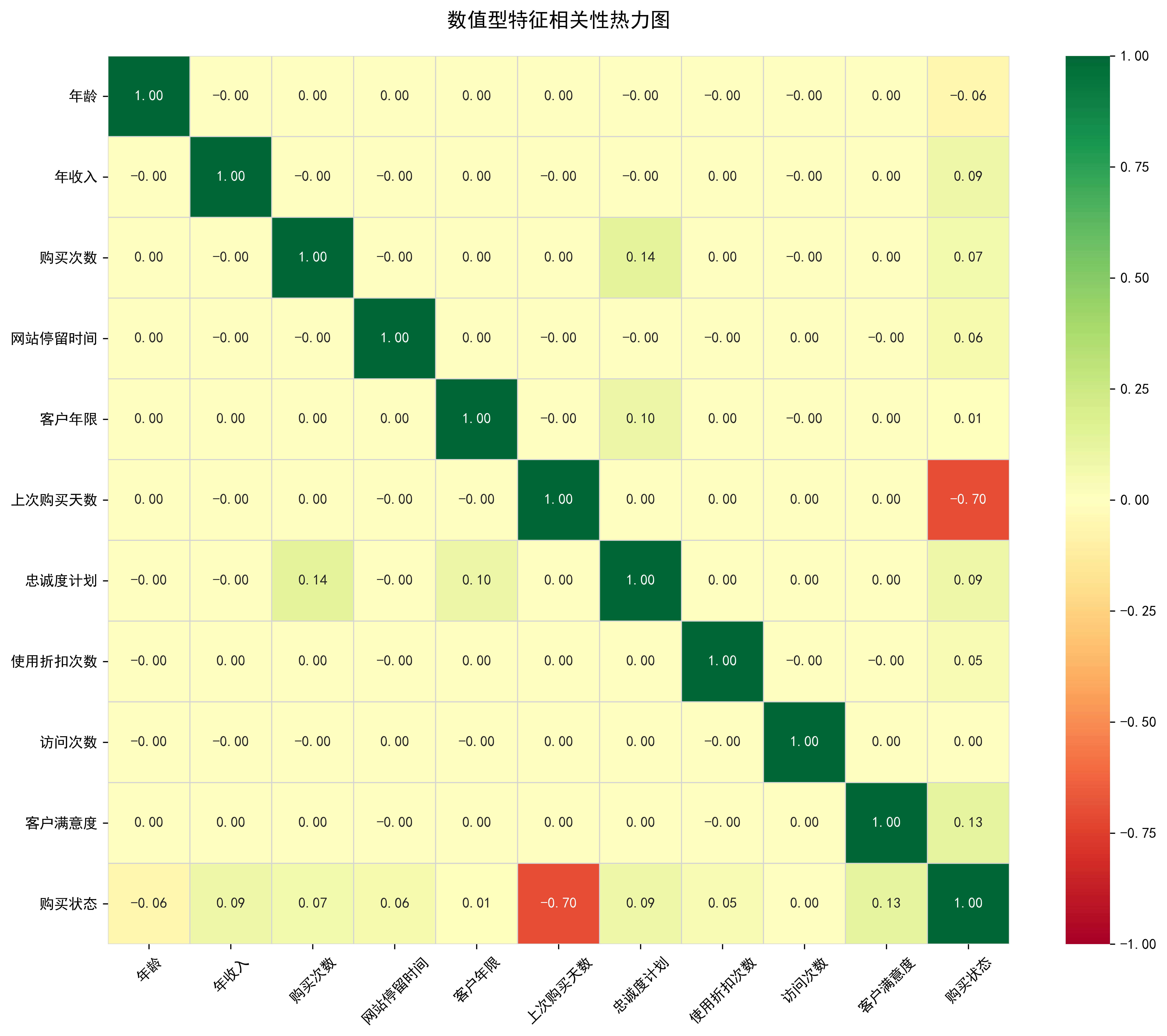
上次购买天数与购买状态是最强的负相关,如果上次购买天数很大那么当前购买状态很可能是未购买0。在建模时要注意,如果预测的是现在是否购买,这个特征可能涉及数据泄露,但预测未来几天是否购买可能不影响。
购买次数与忠诚度计划相关性为0.14,虽然数值不大,但在业务上是合理的。参与了忠诚度计划的用户,历史购买次数倾向于更多。这说明会员体系是有效的,或者高频购买者更愿意加入会员。
年收入、年龄与购买状态的相关性极低,意味着有钱人并不比穷人更容易购买,年轻人也不比老年人更容易购买。传统的针对高收入人群推销策略在这里可能失效。用户的购买决策更多取决于行为特征(如停留时间、访问次数),而不是人口统计学特征。
客户满意度与其他特征的相关的较低,满意度是一个独立的维度。满意的客户不一定买得多也不一定收入高。提升满意度并不直接等同于提升短期销量,它更多是品牌资产。
4、数值型特征的小提琴分布
单纯看数值分布不够,必须结合目标变量——购买状态来看。找出“购买者”和“未购买者”在数值特征上的显著差异,可以使用分面直方图或小提琴图。将数据分为“已购买”和“未购买”两组,对比两组的各数值特征的均值差异。
import matplotlib.pyplot as plt
import seaborn as sns
# 设置绘图风格
sns.set_theme(style="whitegrid")
# 设置字体为 SimHei(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
continuous_features = ['年龄', '年收入', '购买次数', '网站停留时间',
'客户年限', '上次购买天数', '使用折扣次数', '访问次数']
n_rows = (len(continuous_features) + 1) // 2
plt.figure(figsize=(20, 5 * n_rows))
for i, feature in enumerate(continuous_features):
plt.subplot(n_rows, 2, i + 1)
# inner='quartile' 会在图中显示四分位数
sns.violinplot(x='购买状态', y=feature, data=data, palette='Set2', inner='quartile')
plt.title(f'不同购买状态下的{feature}分布', fontsize=14)
plt.xlabel('购买状态 (0:未购买, 1:已购买)', fontsize=12)
plt.ylabel(feature, fontsize=12)
plt.tight_layout()
plt.show()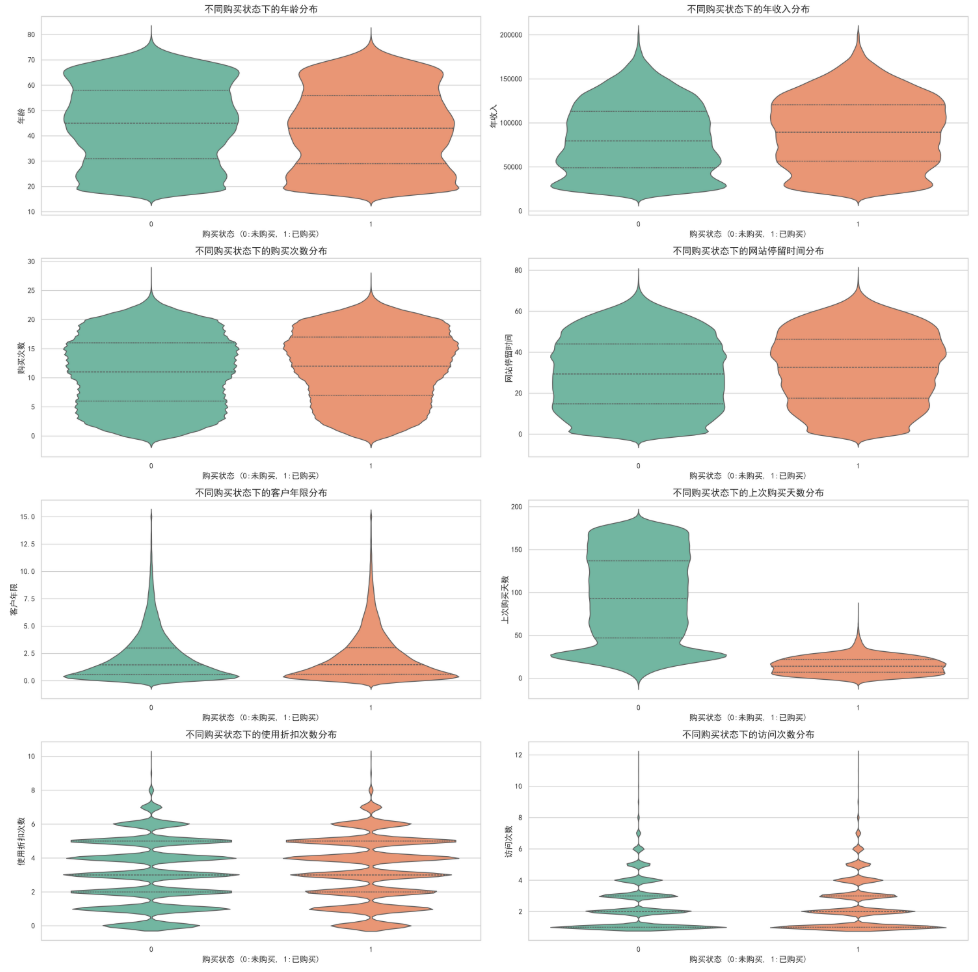
上次购买天数差异最明显,未购买分布非常宽且均匀,主要集中在25-175天之间,说明这些用户很久没买了,已购买分布集中在底部0-25天,形成尖锐三角形,说明近期有过购买行为的用户,复购概率极高,而沉睡超过100天的用户很难被唤醒。需要针对购买天数在30-60天的用户进行重点促销,防止他们陷入沉睡。
5、类别型数据统计分析
data.select_dtypes(include=['object']).describe()| 性别 | 产品类别 | 偏好设备 | 地区 | 推荐来源 | 客户细分 | |
|---|---|---|---|---|---|---|
| count | 500000 | 500000 | 500000 | 500000 | 500000 | 500000 |
| unique | 2 | 5 | 3 | 4 | 5 | 3 |
| top | Male | Fashion | Mobile | South | Organic | Premium |
| freq | 252560 | 111330 | 272131 | 177889 | 207991 | 237347 |
6、类别型数据直方图分布
import seaborn as sns
import matplotlib.pyplot as plt
# 1.数据筛选与准备
# 从数据集中提取所有对象类型(字符串/类别)的列
cat_features = data.select_dtypes(include=['object']).columns.tolist()
total_cats = len(cat_features)
# 2.画布布局设置
# 计算行数,每行固定3个图,使用整除逻辑向上取整
grid_rows = (total_cats + 2) // 3
# 初始化画布
# 宽度固定为15,高度根据行数动态计算(每行高度设为5)
fig, ax_grid = plt.subplots(grid_rows, 3, figsize=(15, 5 * grid_rows))
# 将坐标轴矩阵展平为一维列表,便于通过索引直接访问
ax_grid = ax_grid.flatten()
# 3.颜色配置
# 使用 Seaborn 内置的 'tab10' 调色板,确保不同类别的颜色区分度高
color_scheme = sns.color_palette('tab10', n_colors=10)
# 4.循环绘图
for idx, feature in enumerate(cat_features):
# 绘制计数条形图
sns.countplot(x=feature, data=data, ax=ax_grid[idx], palette=color_scheme)
# 设置图表标题
ax_grid[idx].set_title(f'{feature}分布条形图')
# 将X轴标签旋转45度,防止文字重叠
ax_grid[idx].tick_params(axis='x', rotation=45)
# 5.清理多余子图
# 如果特征数量不是3的倍数,删除最后多余的空白坐标轴
# 这里从当前索引+1开始删除,直到填满整个网格
for k in range(idx + 1, grid_rows * 3):
fig.delaxes(ax_grid[k])
# 自动调整布局,防止标签和标题遮挡
plt.tight_layout()
plt.show()
7、每个类别的平均购买状态
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 设置绘图风格
sns.set_theme(style="whitegrid")
# 设置字体为 SimHei(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
categorical_features = ['性别', '产品类别', '偏好设备', '地区', '客户细分', '忠诚度计划']
n_cols = 2
n_rows = (len(categorical_features) + 1) // n_cols
plt.figure(figsize=(20, 6 * n_rows))
for i, feature in enumerate(categorical_features):
plt.subplot(n_rows, n_cols, i + 1)
prop_df = pd.crosstab(data[feature], data['购买状态'], normalize='index')
prop_df.plot(kind='bar', stacked=True, ax=plt.gca(), legend=False, color=['#ff9999', '#66b3ff'])
plt.title(f'不同{feature}的平均购买状态分布', fontsize=14)
plt.xlabel(feature, fontsize=12)
plt.ylabel('比例', fontsize=12)
plt.xticks(rotation=45)
plt.legend(['未购买 (0)', '已购买 (1)'], title='购买状态', loc='upper right')
plt.ylim(0, 1)
plt.tight_layout()
plt.show()
for feature in categorical_features:
# 计算每个类别的平均购买状态
conversion_rate = data.groupby(feature)['购买状态'].mean().sort_values(ascending=False)
print(f"\n【{feature}】每个类别的平均购买状态:")
print(conversion_rate)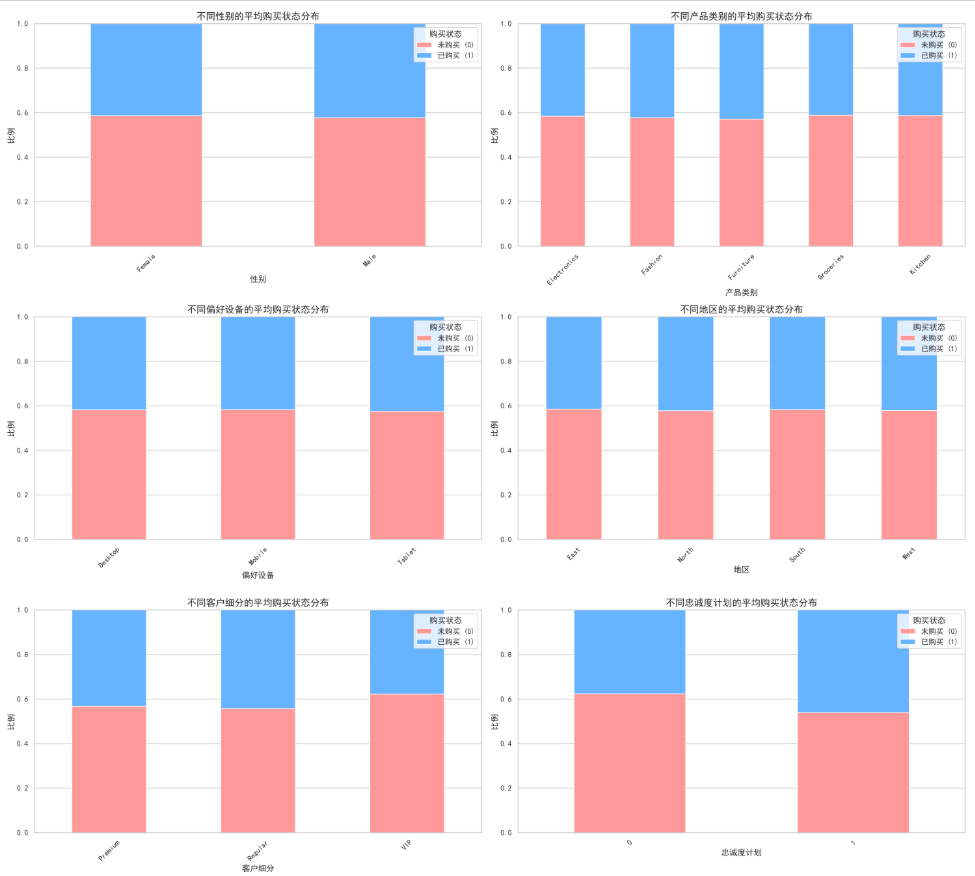
【性别】每个类别的平均购买状态:
性别
Male 0.422838
Female 0.413777
Name: 购买状态, dtype: float64
【产品类别】每个类别的平均购买状态:
产品类别
Furniture 0.428570
Fashion 0.422878
Electronics 0.416091
Kitchen 0.412730
Groceries 0.411103
Name: 购买状态, dtype: float64
【偏好设备】每个类别的平均购买状态:
偏好设备
Tablet 0.424960
Desktop 0.417795
Mobile 0.416932
Name: 购买状态, dtype: float64
【地区】每个类别的平均购买状态:
地区
North 0.421743
West 0.420440
South 0.417007
East 0.414395
Name: 购买状态, dtype: float64
【客户细分】每个类别的平均购买状态:
客户细分
Regular 0.442615
Premium 0.432295
VIP 0.377607
Name: 购买状态, dtype: float64
【忠诚度计划】每个类别的平均购买状态:
忠诚度计划
1 0.460426
0 0.376095
Name: 购买状态, dtype: float64忠诚度计划是影响最显著的特征,加入计划的购买率为46%,未加入计划的购买率为37.6%,加入忠诚度计划的用户,购买转化率比未加入的高出近8.4个百分点。证明忠诚度计划是有效的,应在结账页或浏览页强力推广计划,因为这直接关联转化。加入的人群转化高,可以进一步分析加入忠诚度计划的用户的复购率,看是否值得投入更多成本维护。
奇怪的是客户细分中,VIP客户的购买率最低,推测原因可能有三,这里的“VIP”可能指的是历史累计消费高的老客户,而不是当前活跃的客户,老客户服务可能已经饱和,需求下降。VIP 客户对服务极其挑剔,如果平台近期体验下降,他们可能正在流失。VIP 样本量可能较少,导致数据波动大,但根据直方图看,其样本量不少。这需要进一步研究,结论参照第三章第三节行为聚类与价值分层的交叉分析。
三、用户分类
1、PCA+K-Means用户聚类
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 设置绘图风格
sns.set(style="whitegrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 数据变量
data_km = data.copy()
# 特征预处理
# 区分数值型和类别型特征
numeric_features = data_km.select_dtypes(include=['int64', 'float64']).columns
categorical_features = data_km.select_dtypes(include=['object']).columns
print(f"数值特征数量: {len(numeric_features)}")
print(f"类别特征数量: {len(categorical_features)}")
# 构建预处理管道
# 数值特征标准化 (StandardScaler)
# 类别特征独热编码 (OneHotEncoder)
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(handle_unknown='ignore', sparse_output=False), categorical_features)
])
# 执行预处理,得到全数值化的矩阵
X_processed = preprocessor.fit_transform(data_km)
print(f"预处理后特征总维度: {X_processed.shape[1]}")
# 如果类别特征类别很多,这里维度会变得很高,这就是为什么要降维
# PCA降维,降低时间复杂度
pca = PCA(n_components=0.90) # 保留90%的方差信息
X_pca = pca.fit_transform(X_processed)
print(f"降维后特征维度: {X_pca.shape[1]}")
print(f"保留了90%的信息,维度从 {X_processed.shape[1]} 降至 {X_pca.shape[1]}")
# 确定最佳K值
inertias = []
K_range = range(2, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X_pca)
inertias.append(kmeans.inertia_)
plt.figure(figsize=(8, 6))
plt.plot(K_range, inertias, 'bo-')
plt.xlabel('聚类数量 K')
plt.ylabel('误差平方和 (Inertia)')
plt.title('手肘法:确定最佳 K 值 (基于PCA降维数据)')
plt.grid(True)
plt.show()数值特征数量: 11
类别特征数量: 6
预处理后特征总维度: 33
降维后特征维度: 19
保留了 90% 的信息,维度从 33 降至 19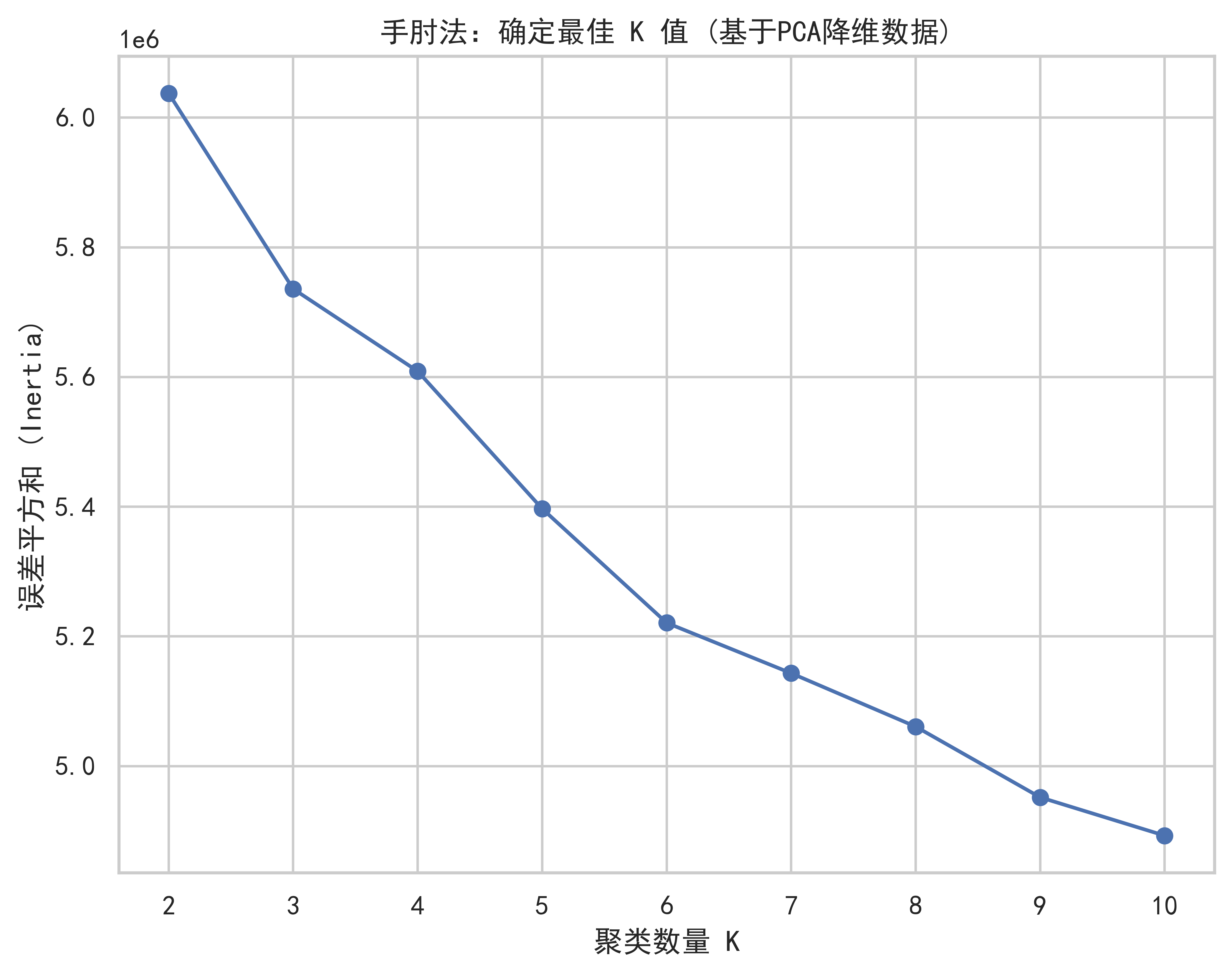
import numpy as np
# 选定 K=6
optimal_k = 6
# 5. 最终聚类
kmeans_final = KMeans(n_clusters=optimal_k, random_state=42, n_init='auto')
# 在降维后的数据上训练
cluster_labels = kmeans_final.fit_predict(X_pca)
# 将结果放回原数据
data_km['聚类簇'] = cluster_labels
# 6.结果分析与画像 (还原回原始特征进行解读)
print("\n各聚类簇数值特征均值:")
numeric_cols = data_km.select_dtypes(include=[np.number]).columns
numeric_cols = numeric_cols.drop('聚类簇', errors='ignore')
print(data_km.groupby('聚类簇')[numeric_cols].mean())
print("\n各聚类簇类别特征主要分布:")
# 对类别特征,我们看每个簇里最常见的值(众数)
categorical_cols = data_km.select_dtypes(include=['object']).columns
# agg(lambda x: x.mode().iloc[0] if not x.mode().empty else 'None')
# 上面这行代码取众数,但为了防止报错,简化为取该组第一个值示意
for col in categorical_cols:
if col != '聚类簇':
print(f"\n{col} 分布:")
print(data_km.groupby('聚类簇')[col].apply(lambda x: x.mode().dropna().tolist() if not x.mode().dropna().empty else ['无数据']))
# 可视化,利用 PCA 的前两个主成分展示聚类效果
plt.figure(figsize=(10, 8))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=data_km['聚类簇'], palette='viridis', s=80, alpha=0.6)
plt.title(f'全特征聚类分布 (PCA降维可视化, K={optimal_k})')
plt.xlabel('主成分 1')
plt.ylabel('主成分 2')
plt.legend(title='客户群体')
plt.show()各聚类簇数值特征均值:
年龄 年收入 购买次数 网站停留时间 客户年限 上次购买天数 \
聚类簇
0 42.138357 90510.498081 11.220919 32.351649 1.668834 121.224712
1 44.475348 84145.408381 11.313635 30.257319 7.872413 57.520974
2 44.160442 84056.830668 12.445599 30.160672 1.752014 104.538399
3 48.730371 69668.357296 8.690751 25.743928 1.630753 45.154379
4 42.970591 88314.507604 12.609590 31.618839 1.813336 15.665844
5 42.336107 90490.754019 11.023091 32.416700 1.682766 13.862228
忠诚度计划 使用折扣次数 访问次数 客户满意度 购买状态 Cluster
聚类簇
0 0.000000 3.322699 2.352113 3.416773 0.000000 2.000000
1 0.710809 3.128225 2.319498 3.203578 0.384039 1.351437
2 1.000000 3.131429 2.359468 3.194560 0.000000 0.000000
3 0.099996 2.694483 2.343952 2.708756 0.003732 1.796331
4 1.000000 3.248589 2.356158 3.318837 1.000000 3.000000
5 0.000000 3.304605 2.355937 3.377785 0.999945 1.000055
各聚类簇类别特征主要分布:
性别 分布:
聚类簇
0 [Male]
1 [Female]
2 [Male]
3 [Male]
4 [Male]
5 [Male]
Name: 性别, dtype: object
产品类别 分布:
聚类簇
0 [Fashion]
1 [Fashion]
2 [Fashion]
3 [Kitchen]
4 [Fashion]
5 [Fashion]
Name: 产品类别, dtype: object
偏好设备 分布:
聚类簇
0 [Mobile]
1 [Mobile]
2 [Mobile]
3 [Mobile]
4 [Mobile]
5 [Mobile]
Name: 偏好设备, dtype: object
地区 分布:
聚类簇
0 [South]
1 [South]
2 [South]
3 [South]
4 [South]
5 [South]
Name: 地区, dtype: object
推荐来源 分布:
聚类簇
0 [Organic]
1 [Organic]
2 [Organic]
3 [Organic]
4 [Organic]
5 [Organic]
Name: 推荐来源, dtype: object
客户细分 分布:
聚类簇
0 [Premium]
1 [Premium]
2 [Premium]
3 [Premium]
4 [Premium]
5 [Premium]
Name: 客户细分, dtype: object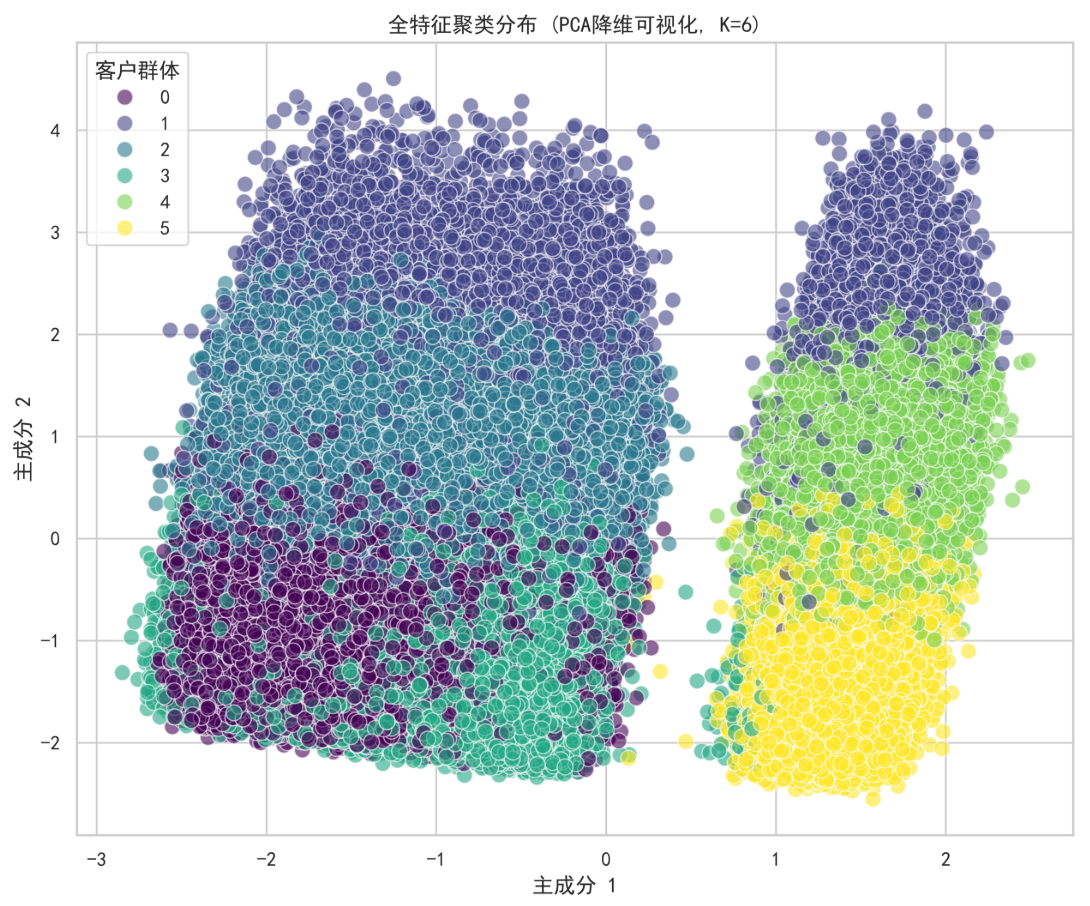
| 用户群组 | 业务标签 | 核心特征 | 策略建议 |
|---|---|---|---|
| 簇 0, 2 | 高价值流失客户 | 高收入、高忠诚度、但已超100天未购买 | 重点挽留。推送专属大额优惠券、进行电话回访,了解流失原因。 |
| 簇 1 | 高价值忠诚客户 | 高收入、高忠诚度、购买活跃(57天) | 核心维护。提供VIP服务、新品优先体验,维持其忠诚度与活跃度。 |
| 簇 3 | 低价值活跃客户 | 低收入、低满意度、但近期有购买(45天) | 潜力挖掘。推荐高性价比产品、引导参与互动提升满意度,尝试提升其客单价。 |
| 簇 4, 5 | 高价值活跃客户 | 高收入、高购买频次、最近刚购买(<16天) | 持续激励。推荐关联产品、引导分享裂变,最大化其生命周期价值。 |
2、RMF客户价值分析
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置绘图风格
sns.set(style="whitegrid")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据准备与计算
data_rfm = data.copy()
# 构建消费金额 (Monetary)
# 公式:估算金额 = 购买次数 * 基础客单价 * (1 + 满意度系数 + 会员系数)
base_avg_price = 1 # 假设平均每次购买贡献为系数1,这不影响计算,因为只和比例有关
data_rfm['估算消费金额'] = data_rfm['购买次数'] * base_avg_price * (
1 + (data_rfm['客户满意度'] * 0.05) + (data_rfm['忠诚度计划'] * 0.1)
)
# RFM 打分 (使用分位数法 1-5分)
def get_rfm_score(x, bins=5, labels=[1, 2, 3, 4, 5]):
# pd.qcut 是等频分箱,保证每个分数段人数大致相等
# 注意:R值(天数)是越小越好,所以 labels 需要倒序,或者在切分后反转
return pd.qcut(x, q=bins, labels=labels, duplicates='drop')
# R值打分:天数越短,分数越高 (5分最高)
# 我们通过 labels=[5,4,3,2,1] 来实现倒序
data_rfm['R_Score'] = pd.qcut(data_rfm['上次购买天数'], q=5, labels=[5, 4, 3, 2, 1], duplicates='drop').astype(int)
# F值打分:次数越多,分数越高 (5分最高)
data_rfm['F_Score'] = pd.qcut(data_rfm['购买次数'].rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop').astype(int)
# M值打分:金额越高,分数越高 (5分最高)
data_rfm['M_Score'] = pd.qcut(data_rfm['估算消费金额'].rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop').astype(int)
# 计算 RFM 总分与 8类分群
# 计算总分
data_rfm['RFM_Sum'] = data_rfm['R_Score'] + data_rfm['F_Score'] + data_rfm['M_Score']
# 定义分群规则函数
def rfm_segment(row):
r, f, m = row['R_Score'], row['F_Score'], row['M_Score']
# 这里的逻辑是:3分及以上视为“高”,3分以下视为“低”
if r >= 3 and f >= 3 and m >= 3: return '重要价值客户'
elif r >= 3 and f >= 3 and m < 3: return '一般价值客户'
elif r >= 3 and f < 3 and m >= 3: return '重要发展客户'
elif r >= 3 and f < 3 and m < 3: return '新客户'
elif r < 3 and f >= 3 and m >= 3: return '重要保持客户'
elif r < 3 and f >= 3 and m < 3: return '一般维持客户'
elif r < 3 and f < 3 and m >= 3: return '重要挽留客户'
else: return '流失客户'
data_rfm['客户群体'] = data_rfm.apply(rfm_segment, axis=1)
# 统计与绘图
# 1.统计数据
segment_counts = data_rfm['客户群体'].value_counts()
print("\n各群体人数统计")
print(segment_counts)
# 2.绘制环形图 + 外部图例
plt.figure(figsize=(12, 8))
# 配色方案
colors = sns.color_palette("Set3", len(segment_counts))
# 绘制圆环 (Donut Chart)
# wedgeprops=dict(width=0.5) 设置圆环宽度,中间留空
wedges, texts, autotexts = plt.pie(
segment_counts.values,
labels=None, # 不在饼图上直接显示标签,避免拥挤
colors=colors,
autopct='%1.1f%%', # 只显示百分比
startangle=140,
pctdistance=0.85, # 百分比文字距离圆心的距离
wedgeprops=dict(width=0.5, edgecolor='w') # 设置圆环宽度和白色描边
)
# 优化百分比文字的样式
plt.setp(autotexts, size=10, weight="bold", color="white")
# 添加中心文字
plt.text(0, 0, '客户分布', ha='center', va='center', fontsize=16, fontweight='bold')
# 添加标题
plt.title('RFM 客户群体分布 (环形图)', fontsize=18, pad=20) # pad调整标题距离
# 添加外部图例
# loc='center left', bbox_to_anchor=(1, 0, 0.5, 1) 将图例放在图表右侧外部
plt.legend(
wedges,
segment_counts.index,
title="客户群体",
loc="center left",
bbox_to_anchor=(1, 0, 0.5, 1)
)
plt.axis('equal') # 保证是正圆
plt.tight_layout() # 自动调整布局,防止图例被切掉
plt.show()各群体人数统计
客户群体
重要价值客户 176737
重要保持客户 117031
新客户 116726
流失客户 77042
一般价值客户 3795
重要发展客户 3735
重要挽留客户 2497
一般维持客户 2437
Name: count, dtype: int64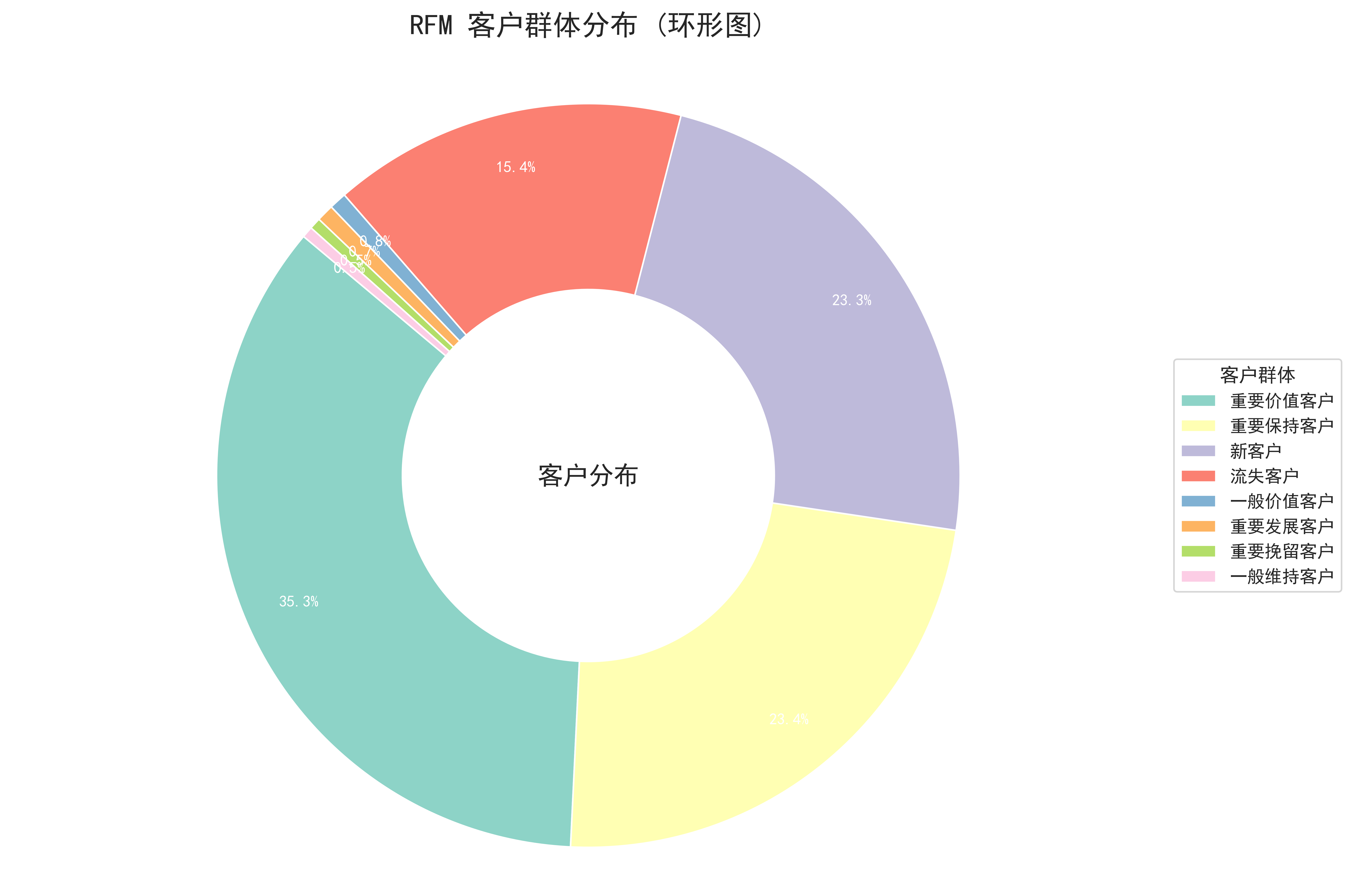
3、行为聚类与价值分层交叉分析
将聚类簇和客户群体合并到一个DataFrame,分析每个K-Means簇中,RFM各类客户的占比。利用交叉表解释为什么某些高价值簇购买率低,最后提出策略。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 两个数据集对齐合并
data_final = data_km.copy()
data_final['客户群体'] = data_rfm['客户群体'].values
data_final['R_Score'] = data_rfm['R_Score'].values
data_final['F_Score'] = data_rfm['F_Score'].values
data_final['M_Score'] = data_rfm['M_Score'].values
# 定义购买状态列
if '购买状态' not in data_final.columns:
data_final['购买状态'] = data_final['购买次数'].apply(lambda x: 1 if x > 0 else 0)
# 行是聚类簇,列是RFM群体,值是人数
cross_tab = pd.crosstab(data_final['聚类簇'], data_final['客户群体'])
# 计算每个簇内部各RFM群体的占比
cross_tab_pct = cross_tab.div(cross_tab.sum(1), axis=0)
print("###各聚类簇内的RFM客户构成占比###")
print(cross_tab_pct.round(2))
# 计算每个簇的转化率
cluster_conversion = data_final.groupby('聚类簇')['购买状态'].mean().sort_values(ascending=False)
# 计算每个簇的平均 R, F, M 分数
cluster_rfm_means = data_final.groupby('聚类簇')[['R_Score', 'F_Score', 'M_Score', '上次购买天数']].mean()
# 合并指标
cluster_analysis = pd.concat([cluster_conversion, cluster_rfm_means], axis=1)
cluster_analysis.rename(columns={'购买状态': '转化率'}, inplace=True)
print("\n###聚类簇综合诊断表###")
print(cluster_analysis)
# 策略矩阵图
plt.figure(figsize=(14, 6))
# 子图 1: 各簇转化率 vs 平均上次购买天数 (散点图)
plt.subplot(1, 2, 1)
sns.scatterplot(
x=cluster_analysis['上次购买天数'],
y=cluster_analysis['转化率'],
size=cluster_analysis['M_Score'], # 气泡大小代表金钱价值
hue=cluster_analysis.index, # 颜色区分簇
palette='viridis',
s=100,
alpha=0.8
)
plt.title('簇诊断:转化率 vs 沉睡时长 (气泡大小=平均M值)', fontsize=12)
plt.xlabel('平均上次购买天数 (越小越好)')
plt.ylabel('购买转化率')
plt.legend(title='聚类簇', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True, linestyle='--', alpha=0.5)
# 子图 2: 各簇内的 RFM 结构 (堆叠柱状图)
plt.subplot(1, 2, 2)
# 只展示主要的几个群体,避免图例太乱
top_groups = ['重要价值客户', '重要保持客户', '流失客户', '新客户']
cross_tab_pct[top_groups].plot(kind='bar', stacked=True, ax=plt.gca(), colormap='Set3')
plt.title('各簇内部 RFM 客户结构分布', fontsize=12)
plt.xlabel('聚类簇')
plt.ylabel('占比')
plt.xticks(rotation=0)
plt.legend(title='RFM群体', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True, axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()
# 策略
def generate_strategy(row):
cluster_id = row.name
conversion = row['转化率']
recency = row['上次购买天数']
m_score = row['M_Score']
# 找出该簇占比最高的 RFM 群体
dominant_group = cross_tab_pct.loc[cluster_id].idxmax()
strategy = ""
if conversion > 0.45:
strategy = "核心收割区:保持现状,推高客单价关联品。"
elif recency > 100:
strategy = "重点挽留区:已沉睡,需大额券/人工回访激活。"
elif m_score > 3.5 and conversion < 0.40:
strategy = "潜力错配区:有钱但不买,检查是否服务体验差或需求饱和。"
else:
strategy = "潜力培养区:通过签到、小游戏提升活跃度。"
return f"[{dominant_group}] {strategy}"
cluster_analysis['建议策略'] = cluster_analysis.apply(generate_strategy, axis=1)
print("\n###最终行动建议表###")
print(cluster_analysis[['转化率', '上次购买天数', '建议策略']])###各聚类簇内的RFM客户构成占比###
客户群体 一般价值客户 一般维持客户 新客户 流失客户 重要价值客户 重要保持客户 重要发展客户 重要挽留客户
聚类簇
0 0.00 0.02 0.03 0.38 0.06 0.51 0.00 0.01
1 0.00 0.00 0.24 0.15 0.36 0.23 0.01 0.01
2 0.00 0.00 0.06 0.25 0.14 0.53 0.00 0.02
3 0.02 0.01 0.42 0.17 0.29 0.09 0.00 0.00
4 0.00 0.00 0.29 0.00 0.68 0.00 0.02 0.00
5 0.02 0.00 0.42 0.00 0.55 0.00 0.01 0.00
###聚类簇综合诊断表###
转化率 R_Score F_Score M_Score 上次购买天数
聚类簇
4 1.000000 4.266215 3.280925 3.387426 15.665844
5 0.999945 4.385175 2.915091 2.827597 13.862228
1 0.384039 3.028980 2.980643 3.019440 57.520974
3 0.003732 3.105430 2.384661 2.274260 45.154379
0 0.000000 1.539463 2.960911 2.872587 121.224712
2 0.000000 1.833031 3.242425 3.337694 104.538399
###最终行动建议表###
转化率 上次购买天数 建议策略
聚类簇
4 1.000000 15.665844 [重要价值客户] 核心收割区:保持现状,推高客单价关联品。
5 0.999945 13.862228 [重要价值客户] 核心收割区:保持现状,推高客单价关联品。
1 0.384039 57.520974 [重要价值客户] 潜力培养区:通过签到、小游戏提升活跃度。
3 0.003732 45.154379 [新客户] 潜力培养区:通过签到、小游戏提升活跃度。
0 0.000000 121.224712 [重要保持客户] 重点挽留区:已沉睡,需大额券/人工回访激活。
2 0.000000 104.538399 [重要保持客户] 重点挽留区:已沉睡,需大额券/人工回访激活。之前的分析显示VIP客户购买率最低,根据结果发现,低购买率VIP主要集中在簇0和簇2。这两个簇的消费金额M_score很高,证明他们是高净值客户,R_score很低,且上次购买天数超过100天,转化率为0%,是已流失的高价值VIP客户,他们拉低了整体VIP的平均转化率。
根据转化率和流失天数,我们可以将6个簇重新划分为三个战略战区。
第一是收割战区,包含簇4和簇5,转化率接近100%,刚买过(13-15天前),R值极高。簇4和5几乎包含了所有的重要价值客户,占比分别为68%和55%。
第二是挽留战区,包含簇0和簇2,转化率0%,沉睡超过 100 天。其中簇2是高M值,这部分客户已经流失,但历史贡献很高。簇0是中M值,历史贡献稍低,流失更久。可以采用分层召回的策略,对于簇2高价值流失客户,可以人工VIP客服介入,通过电话联系或者发送无门槛、高价值的回归礼包。对于簇0中等价值流失客户,可以进行大规模自动化营销,发送短信、邮件等推送,强调喜欢的新品类得到了更新快来看看。
第三是培养战区,包含簇1和簇3。簇1转化率中等,簇3转化率极低,主要是新客户和重要发展客户。簇1沉睡约57天,处于流失边缘,需要拉一把,簇3沉睡约45天,且主要是新客户,还在犹豫期。相应策略是提升活跃度,缩短复购周期。针对簇3加强新手引导。他们刚来不久就不买了,可能是因为不会用或者没找到合适的。推送新手必看、爆款榜单、首单返现等活动。针对簇1开展周期性唤醒,根据他们的购买品类设置周期购提醒。
整体来看是行动优先级是保住簇4和簇5,抢回簇2,激活簇1和簇3,如果召回成本过高放弃簇0。
四、客户满意度影响因素分析
1、相关性分析+线性回归+决策树+分组对比分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.preprocessing import LabelEncoder
import warnings
warnings.filterwarnings('ignore')
# 设置绘图风格
sns.set(style="whitegrid")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于显示中文
plt.rcParams['axes.unicode_minus'] = False
# 2.相关性分析 (数值型变量)
print("\n数值型变量与客户满意度的相关性分析")
# 选择数值型列(排除文本列)
numeric_data = data.select_dtypes(include=[np.number])
# 计算皮尔逊相关系数
correlation = numeric_data.corr()['客户满意度'].sort_values(key=abs, ascending=False)
print(correlation)
# 绘制热力图
# 修改点:增大画布尺寸,调整字体大小,设置数值格式,添加遮罩
plt.figure(figsize=(14, 12)) # 增大画布,避免拥挤
mask = np.triu(np.ones_like(numeric_data.corr(), dtype=bool)) # 生成上三角遮罩,去除冗余信息
sns.heatmap(numeric_data.corr(),
mask=mask, # 应用遮罩,只显示下三角
annot=True, # 显示数值
fmt='.6f', # 数值保留2位小数,避免过长
cmap='coolwarm',
center=0,
square=True, # 强制单元格为正方形
linewidths=.5, # 单元格之间留白线
cbar_kws={"shrink": .8}, # 调整颜色条大小
annot_kws={"size": 10}) # 调整数值字体大小
plt.title('数值变量相关性热力图', fontsize=16)
plt.show()
# 3.数据预处理 (编码分类变量)
# 复制数据进行处理
df_model = data.copy()
# 初始化标签编码器 (Label Encoding)
# 这里为了简单,对所有非数值列进行 Label Encoding
# 如果是树模型,其实可以直接用 OneHot,但为了回归模型维度不爆炸,这里用 LabelEncoder
label_encoders = {}
X_features = df_model.drop('客户满意度', axis=1) # 特征
y_target = df_model['客户满意度'] # 目标
# 对特征中的非数值列进行编码
for column in X_features.select_dtypes(include=['object']).columns:
le = LabelEncoder()
X_features[column] = le.fit_transform(X_features[column])
label_encoders[column] = le
print(f"\n特征形状: {X_features.shape}")
# 4.方法一:线性回归 (查看系数)
print("\n方法一:线性回归分析")
# 划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2, random_state=42)
# 训练模型
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# 获取特征重要性 (系数的绝对值越大,影响越大)
coef_df = pd.DataFrame({
'特征': X_features.columns,
'系数': lr_model.coef_,
'绝对值系数': np.abs(lr_model.coef_)
}).sort_values('绝对值系数', ascending=False)
print("线性回归系数 (正负代表影响方向):")
print(coef_df.head(10)) # 显示前10个影响最大的特征
# 5.方法二:决策树 (查看特征重要性)
print("\n方法二:决策树特征重要性分析")
# 训练决策树
dt_model = DecisionTreeRegressor(random_state=42, max_depth=10)
dt_model.fit(X_train, y_train)
# 特征重要性
importance_df = pd.DataFrame({
'特征': X_features.columns,
'重要性': dt_model.feature_importances_
}).sort_values('重要性', ascending=False)
print("决策树特征重要性:")
print(importance_df.head(10))
# 可视化特征重要性
plt.figure(figsize=(10, 6))
top_features = importance_df.head(10)
sns.barplot(data=top_features, x='重要性', y='特征')
plt.title('Top 10 特征重要性 (决策树)')
plt.show()
# 6.分组对比分析 (箱线图)
print("\n分组对比分析")
# 针对原始数据中的分类变量,画箱线图观察分布差异
categorical_cols = ['产品类别', '推荐来源', '地区']
fig, axes = plt.subplots(1, len(categorical_cols), figsize=(18, 6))
for idx, col in enumerate(categorical_cols):
sns.boxplot(data=data, x=col, y='客户满意度', ax=axes[idx])
axes[idx].set_title(f'客户满意度 vs {col}')
axes[idx].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()数值型变量与客户满意度的相关性分析
客户满意度 1.000000
购买状态 0.125145
购买次数 0.003894
忠诚度计划 0.002018
客户年限 0.001875
年收入 0.001797
年龄 0.001536
访问次数 0.001319
上次购买天数 0.001158
网站停留时间 -0.000720
使用折扣次数 -0.000212
Name: 客户满意度, dtype: float64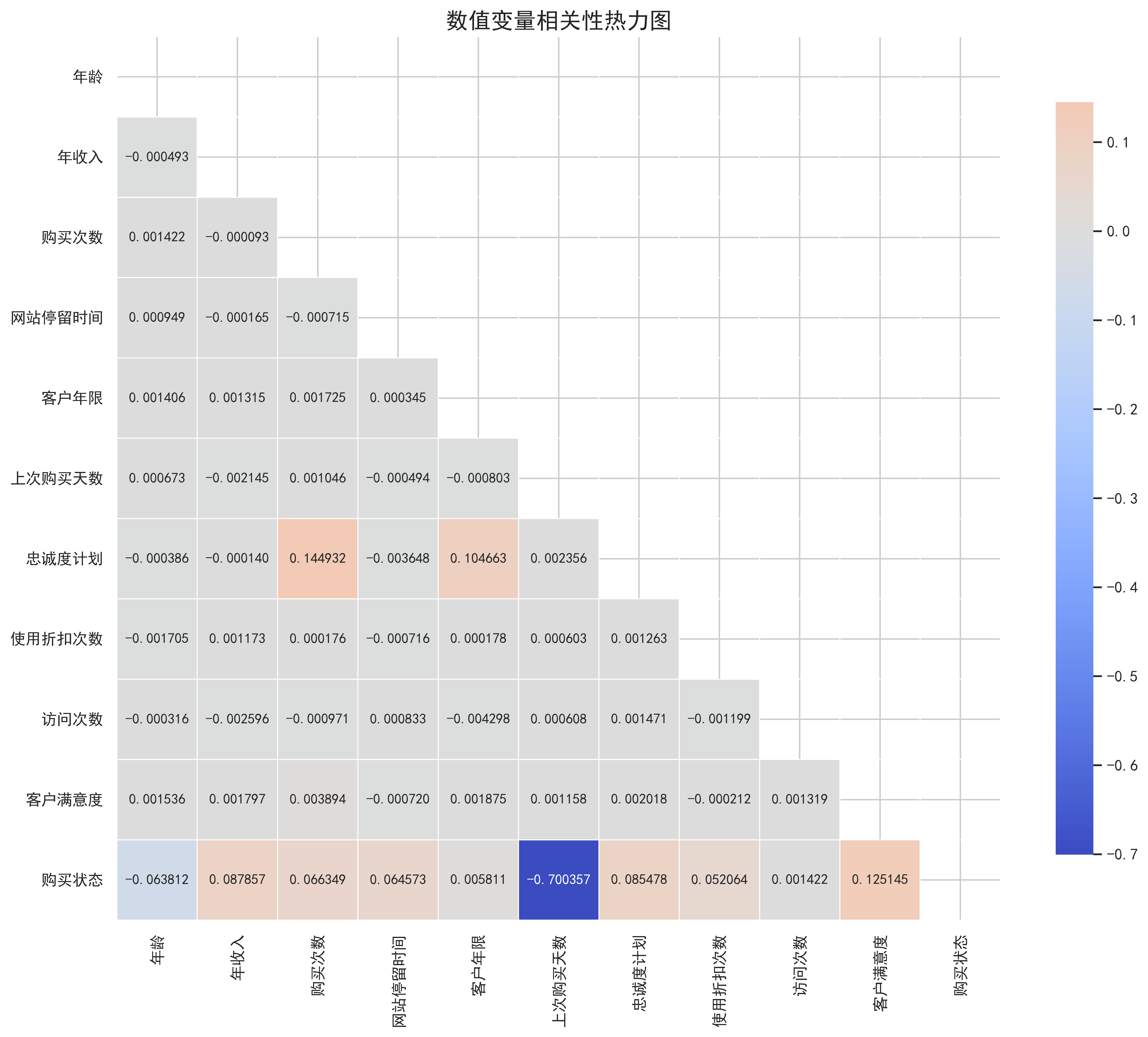
特征形状: (500000, 16)
方法一:线性回归分析
线性回归系数 (正负代表影响方向):
特征 系数 绝对值系数
15 购买状态 0.440510 0.440510
12 忠诚度计划 -0.033728 0.033728
11 客户细分 0.010239 0.010239
13 使用折扣次数 -0.006359 0.006359
6 性别 -0.005607 0.005607
5 上次购买天数 0.002802 0.002802
2 购买次数 -0.001497 0.001497
9 地区 0.001141 0.001141
8 偏好设备 0.001069 0.001069
0 年龄 0.000939 0.000939
方法二:决策树特征重要性分析
决策树特征重要性:
特征 重要性
5 上次购买天数 0.468727
15 购买状态 0.227907
1 年收入 0.063794
3 网站停留时间 0.056360
0 年龄 0.036357
2 购买次数 0.031501
4 客户年限 0.030734
12 忠诚度计划 0.029665
13 使用折扣次数 0.024092
11 客户细分 0.014207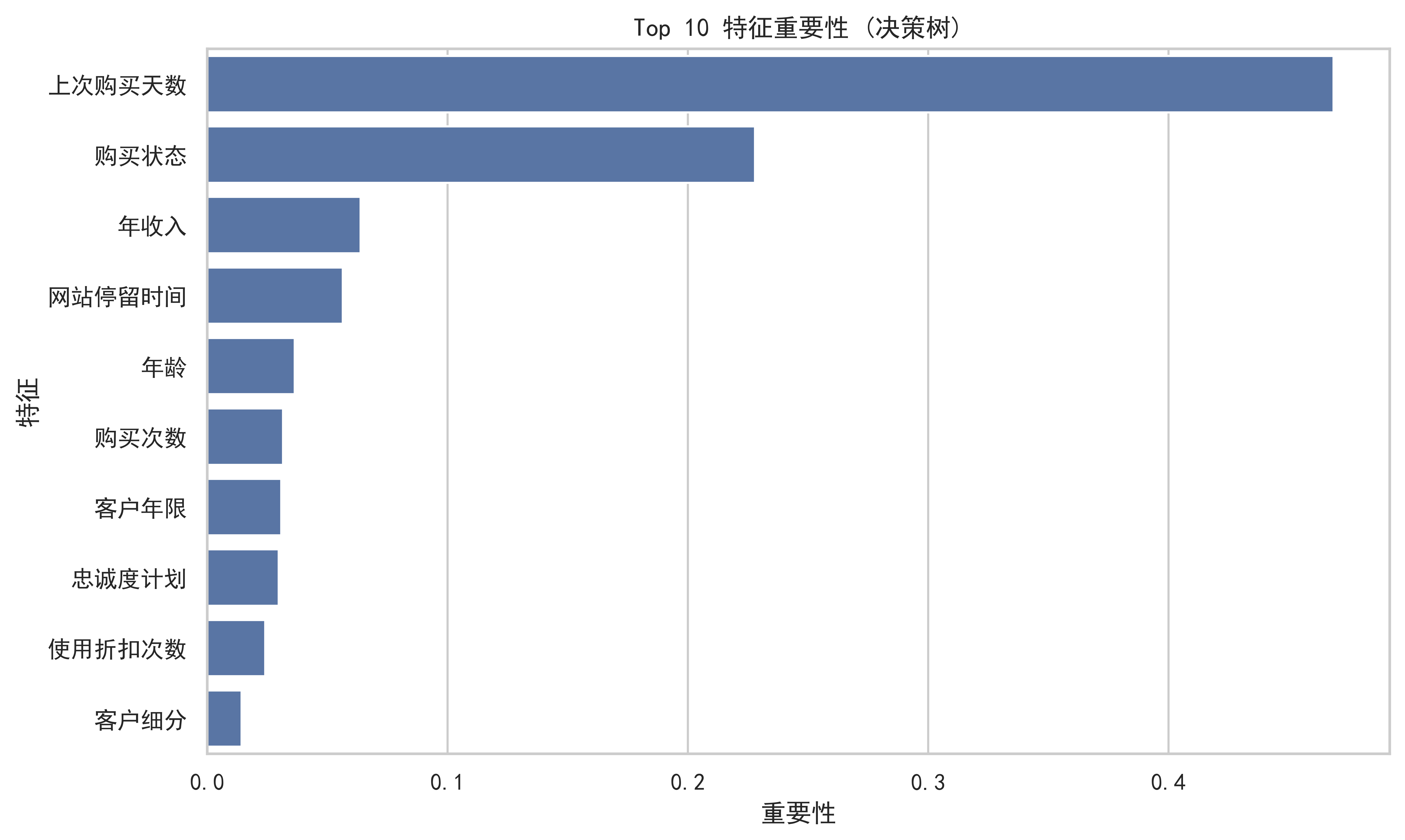
综合两种模型的结果,影响客户满意度的最关键因素主要集中在以下三个方面:
①上次购买天数(Recency)
在决策树模型中,它的重要性高达 0.47,居于最高,说明“最近是否有交互”是预测客户满意度的最重要指标。刚买过东西的客户往往处于兴奋期,满意度高;而很久没买的客户可能已经遗忘或产生了不满。说明提升满意度的最直接手段不是降价,而是增加客户的活跃度和复购频率。
②购买状态(Purchase Status)
在线性回归中,它的系数绝对值最大,且为正相关,在决策树中重要性排第二。这是一个二元变量(0或1),代表客户是否处于“活跃购买”状态,系数为0.44意味着只要客户处于购买状态,满意度平均会提升 0.44 分。说明维持客户的“在买”状态至关重要,一旦客户停止购买,满意度会断崖式下跌。
③经济实力与投入度(年收入 / 网站停留时间)
决策树显示年收入和网站停留时间是仅次于上述两者的因素。高收入群体的满意度更容易被满足,或者他们对服务有更高的容忍度/期望匹配度。停留时间越长,说明客户对内容或产品越感兴趣,这种投入感会转化为满意度。
| 特征 | 线性回归表现 | 决策树表现 | 解读 |
|---|---|---|---|
| 上次购买天数 | 系数很小 (0.002) | 极高 (0.47) | 非线性关系:满意度并不是随着天数增加线性下降的,而是存在一个“临界点”(比如超过90天)。一旦超过这个点,满意度可能瞬间崩塌。线性回归无法捕捉这种突变,但决策树捕捉到了。 |
| 购买状态 | 系数最大 (0.44) | 高 (0.23) | 强相关性:这是最直接的身份标签。它是“结果”也是“原因”,与满意度高度绑定。 |
| 忠诚度计划 |
负系数 (-0.03) |
中等 (0.03) | 反直觉:线性回归显示会员满意度反而略低。这可能是因为会员的期望值更高,所以更难取悦;或者是因为很多不满意的客户为了挽回损失而加入了会员。 |
2、客户满意度提升策略
基于以上数据驱动因素,建议采取以下策略:
①实施防流失预警
上次购买天数是重要的分裂节点,找到改危险的时间点,针对接近这个天数的客户发送回归活动、优惠券、关怀短信等,在客户满意度彻底崩塌前将其拉回。
②强化购买中的体验
购买状态对满意度有巨大的正向拉动,可以通过优化购物流程,让“购买”动作变得顺滑。在客户下单后,需要通过优质的售后服务,如发货通知、使用指南等来巩固满意度。
③差异化运营高价值人群
针对高年收入群体,提供专属客服或高端产品线。数据表明这部分人的满意度贡献潜力大,且决策树认为他们是重要细分人群。
④提升内容产品吸引力
网站停留时间对满意度影响较大,可以通过优化产品详情页、增加种草文章或视频。让客户在网站上逛得更久,他们的满意度也会随之提升。
五、客户购买行为预测
分离目标变量“购买状态”,对数值特征做标准化,分类特征独热编码。按照8:2的比例划分训练集和测试集,采用逻辑回归、随机森林、XGBoost、LightGBM四个模型训练,比较模型评估指标,找到最佳的训练模型用于预测。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score, roc_curve
import xgboost as xgb
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
# 设置绘图风格
sns.set(style="whitegrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1.数据准备
# 定义特征和目标
target_col = '购买状态'
numeric_features = ['年龄', '年收入', '购买次数', '网站停留时间', '客户年限', '上次购买天数', '忠诚度计划', '使用折扣次数', '访问次数', '客户满意度']
categorical_features = ['性别', '产品类别', '偏好设备', '地区', '推荐来源', '客户细分']
X = data.drop(target_col, axis=1)
y = data[target_col]
# 2.数据预处理管道
# 数值型:标准化
# 类别型:独热编码
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(handle_unknown='ignore', sparse_output=False), categorical_features) # 修改此处
])
# 3.划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 预处理数据
X_train_processed = preprocessor.fit_transform(X_train)
X_test_processed = preprocessor.transform(X_test)
# 4.多模型训练与评估
# 定义模型字典
models = {
'逻辑回归': LogisticRegression(random_state=42, max_iter=1000),
'随机森林': RandomForestClassifier(random_state=42, n_estimators=100, max_depth=10),
'XGBoost': xgb.XGBClassifier(random_state=42, n_estimators=200, max_depth=5, eval_metric='logloss'),
'LightGBM': lgb.LGBMClassifier(random_state=42, n_estimators=200, max_depth=5)
}
results = []
print("正在训练并评估模型...\n")
for name, model in models.items():
# 训练
model.fit(X_train_processed, y_train)
# 预测
y_pred = model.predict(X_test_processed)
y_proba = model.predict_proba(X_test_processed)[:, 1]
# 评估指标
auc = roc_auc_score(y_test, y_proba)
accuracy = (y_pred == y_test).sum() / len(y_test)
results.append({
'模型': name,
'准确率': f"{accuracy:.4f}",
'AUC分数': f"{auc:.4f}"
})
print(f"{name}完成 - AUC: {auc:.4f}")
# 5.结果可视化对比
# 绘制综合 ROC 曲线
plt.figure(figsize=(10, 8))
for name, model in models.items():
# 这里为了绘图重新拟合了一次,实际应用中可以直接用上面训练好的模型
# 但因为上面是在循环里训练的,变量作用域问题,这里为了代码逻辑简单再次拟合
# 其实可以直接用上面训练好的,但为了ROC曲线代码独立性,保持现状也可以
# 为了效率,这里我们假设上面的 models 字典里的模型已经是训练好的状态(因为Python对象是引用传递)
y_proba = model.predict_proba(X_test_processed)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_proba)
auc = roc_auc_score(y_test, y_proba)
plt.plot(fpr, tpr, label=f'{name} (AUC = {auc:.4f})', lw=2)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假阳性率')
plt.ylabel('真正率')
plt.title('多模型 ROC 曲线对比')
plt.legend(loc="lower right")
plt.show()
# 打印评估值表格
results_df = pd.DataFrame(results)
print("\n=== 模型评估对比表 ===")
print(results_df.to_string(index=False))
# 6.最佳模型应用
# 选择 AUC 最高的模型
best_model_name = results_df.loc[results_df['AUC分数'].astype(float).idxmax(), '模型']
best_model = models[best_model_name]
print(f"\n最佳模型: {best_model_name}")
# 特征重要性分析
# 独热编码后特征名称会变多,这里为了展示方便,直接使用原始特征名列表
# 严格来说应该获取 preprocessor.get_feature_names_out()
plt.figure(figsize=(10, 8))
feature_names = numeric_features + categorical_features
importance = best_model.feature_importances_
# 由于独热编码,特征数量增加了,这里简单处理只画前10个最重要的
# 如果要精确对应独热编码后的特征名,可以使用下面的方式获取:
# encoded_feature_names = preprocessor.get_feature_names_out()
# 但为了图表清晰,我们暂时只用原始大类名称展示
# 这里为了准确性,使用真实的编码后特征名
try:
encoded_feature_names = preprocessor.get_feature_names_out()
feat_imp = pd.Series(importance, index=encoded_feature_names).sort_values(ascending=True)
except:
# 兼容旧版本 sklearn
encoded_feature_names = numeric_features + [f"类别_{i}" for i in range(len(categorical_features))]
feat_imp = pd.Series(importance, index=encoded_feature_names).sort_values(ascending=True)
feat_imp.tail(15).plot(kind='barh', color='skyblue')
plt.title(f'{best_model_name} - Top 15 特征重要性 (独热编码后)')
plt.xlabel('重要性')
plt.ylabel('特征')
plt.show()
# 业务应用,输出高意向客户名单
X_all_processed = preprocessor.transform(data)
data['购买意向概率'] = best_model.predict_proba(X_all_processed)[:, 1]
high_potential_customers = data[data['购买意向概率'] > 0.7]
print(f"\n基于{best_model_name}模型的营销建议")
print(f"总客户数: {len(data)}")
print(f"高意向客户数 (概率>0.7): {len(high_potential_customers)}")
print(f"高意向客户占比: {len(high_potential_customers)/len(data):.4%}")
print("\n高意向客户前5名预览:")
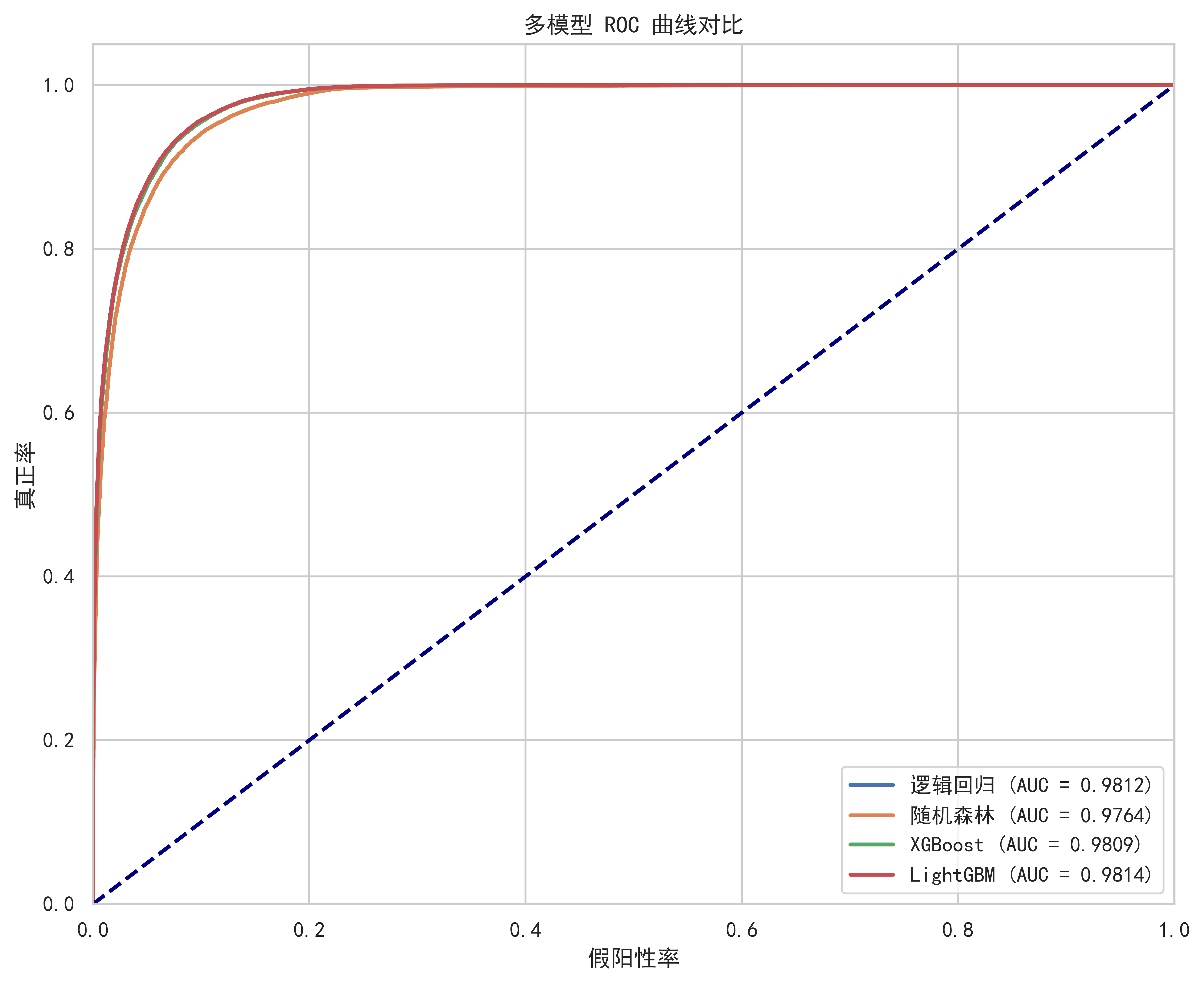
print(high_potential_customers[['年龄', '年收入', '购买次数', '上次购买天数', '购买意向概率']].head())逻辑回归完成 - AUC: 0.9812
随机森林完成 - AUC: 0.9764
XGBoost完成 - AUC: 0.9809
LightGBM完成 - AUC: 0.9814
=== 模型评估对比表 ===
模型 准确率 AUC分数
逻辑回归 0.9265 0.9812
随机森林 0.9153 0.9764
XGBoost 0.9264 0.9809
LightGBM 0.9273 0.9814
最佳模型: LightGBM
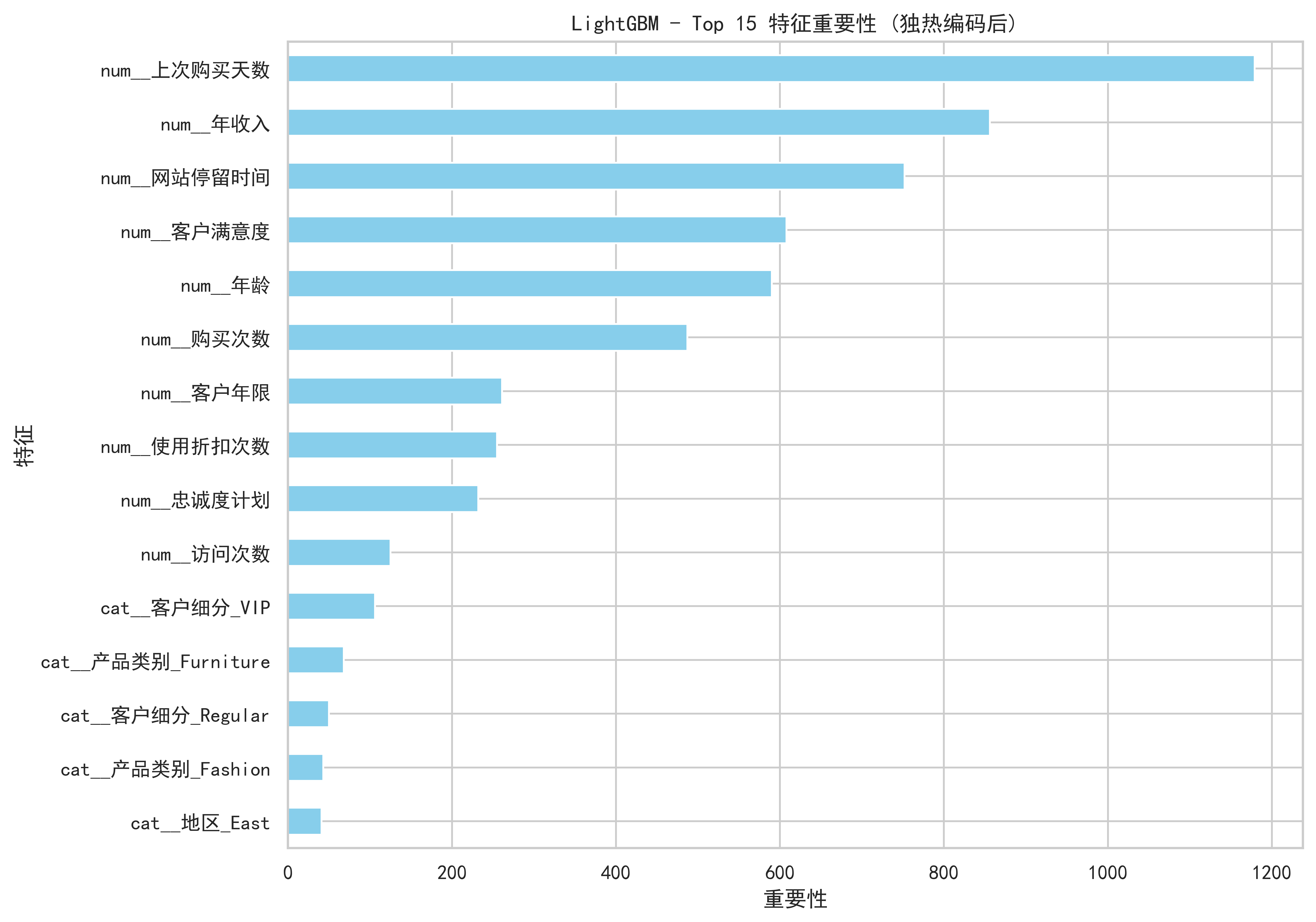
基于LightGBM模型的营销建议
总客户数: 500000
高意向客户数 (概率>0.7): 191649
高意向客户占比: 38.3298%
高意向客户前5名预览:
年龄 年收入 购买次数 上次购买天数 购买意向概率
0 37 57722.572411 19 11 0.964688
7 65 51222.012320 16 20 0.883857
9 31 32572.846759 21 23 0.818837
10 19 102417.259669 12 22 0.927685
13 65 84599.188265 16 3 0.946602
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)