解码大语言模型:深入理解 LLM “温度”参数及其核心控制参数
温度不只是一个数字旋钮——它是你与模型"世界观"之间的协议。理解它,才能真正驾驭大语言模型。
01 从预测下一个词开始
大语言模型(LLM)生成文本的方式,本质上是一个不断重复的"下一词预测"过程。每走一步,模型都会对词汇表中的每一个词(更准确地说是每一个"词元 token")给出一个原始评分,这个评分叫做 logit。
光有 logit 还不够——它们可以是任意正负数,无法直接作为概率使用。所以需要一个转换函数,把这堆数字归一化为 0 到 1 之间的概率,且所有词元的概率之和为 1。这个函数就是 softmax。
核心概念 · Softmax 函数
Softmax 将一组任意实数向量 z 映射为概率分布。
对每个元素取指数后,再除以所有元素指数之和:
P(i) = exp(zᵢ) / Σ exp(zⱼ)。
结果天然满足"非负且求和为 1"的概率条件。
这是 Transformer 架构中注意力机制的核心运算之一。
得到 softmax 概率分布之后,
模型按照这个概率进行采样——概率越高的词元,
被选中的可能性越大,但并非总是选最高的那个。
如此循环,一个词一个词地生成完整文本。02温度如何介入这个过程
温度参数 T 在 softmax 之前作用于 logit:每个 logit 除以 T,再送入 softmax。这个操作看似微小,却从根本上改变了概率分布的"形状"。
当 T < 1 时,除以一个小于 1 的数相当于放大了 logit 之间的差距。原本概率领先的词元会获得更高的相对优势,分布变得更加"尖锐"——最高概率词元几乎垄断了选择空间,模型行为趋向确定性。
当 T > 1 时,logit 差距被压缩,分布变得更加"平坦"。那些原本概率偏低的词元获得了更大的被选中机会,输出随机性和多样性随之增加。
当 T → 0 时,这等价于 贪心解码(greedy decoding):每次都选概率最高的词元,输出完全确定。当 T → ∞ 时,所有词元概率趋于均等,模型退化为随机乱输出。
03温度 ≠ 创造力,但两者有联系
把温度直接等同于创造力,是工程实践中最常见的误解之一。这个说法既有道理,又有相当程度的误导性。
我们发现温度与新颖性呈弱相关,不出所料,与不连贯性呈中等相关,但与内聚性或典型性均无关系。然而,温度对创造性的影响远比"创造性参数"的说法所暗示的要微妙和微弱得多。
— Max Peeperkorn 等,《不同温度下 LLM 输出的实证分析》更精准的理解是:温度控制的是模型对训练数据的依赖程度。低温下,模型高度依赖训练中最频繁出现的模式,输出安全、可预测;高温下,模型更容易选到训练数据中相对罕见的词汇和句式,输出看起来"更新颖",但这种新颖并非源于真正的创造性推理,而是统计上的偏离。
这意味着:盲目调高温度并不能让模型"更聪明",只会让它更容易偏离语义轨道,生成在表面上多样、但逻辑上断裂的内容。

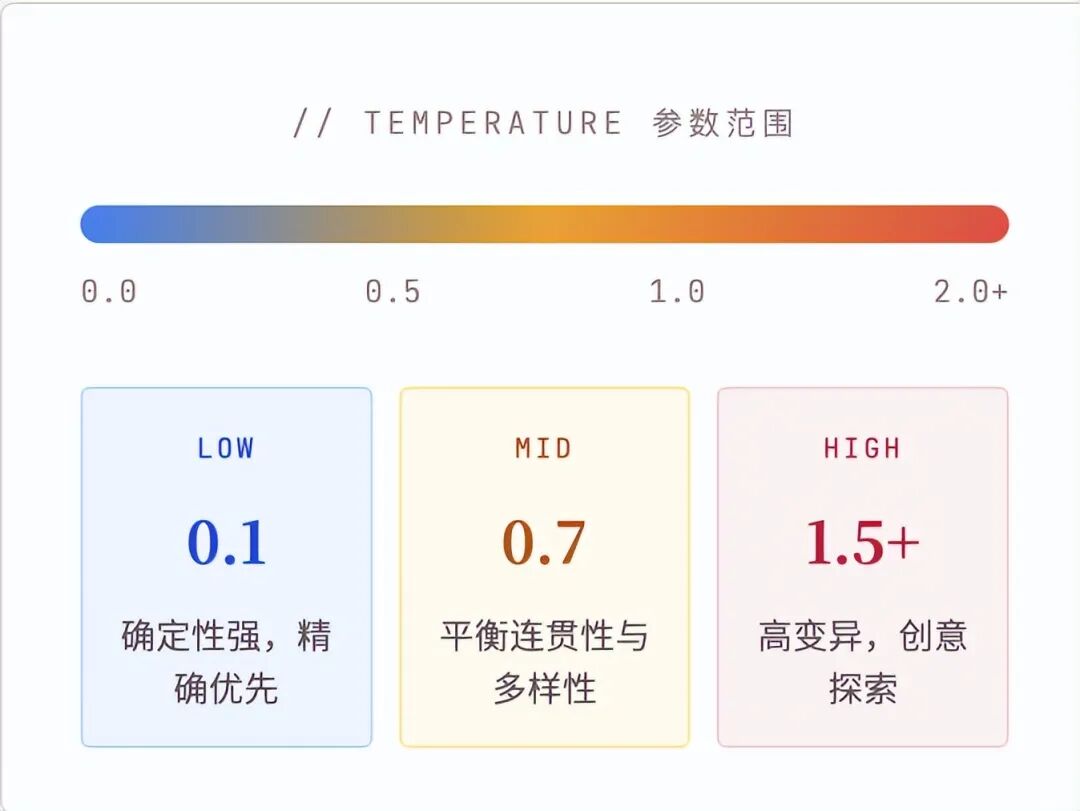
确定性优先场景 低温 0.1–0.4
-
技术文档生成
-
代码补全与审查
-
数据抽取与信息检索
-
FAQ 聊天机器人回复
-
合同 / 法律文本摘要
创意发散场景 高温 0.8–1.5
-
创意写作 / 故事生成
-
广告文案与品牌口号
-
概念头脑风暴
-
剧本与角色对话
-
产品创意探索
04与温度协同工作的三个采样参数
温度是采样策略的核心,但不是全部。实际使用中,它通常与以下三个参数配合,共同塑造输出质量。
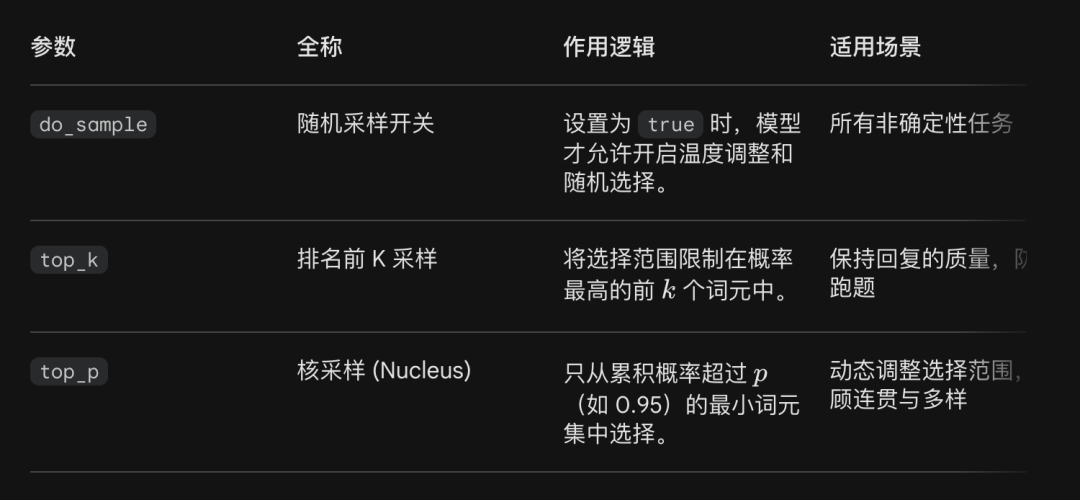
do_sample Boolean · 采样开关
控制模型是否启用随机采样。设为 true 时,模型按概率分布随机选取词元;设为 false 时退化为贪心解码,每次选最高概率词元。温度调整生效的前提是将此参数设为 true——否则温度参数形同虚设。这是初学者最常踩到的配置陷阱。
top_k Integer · 候选词元截断
将采样范围限定为概率最高的前 k 个词元。例如 top_k=50 意味着模型只从概率排名前 50 的词元中选择,彻底排除长尾低概率词元的干扰。这在保留一定随机性的同时,有效防止模型生成词不达意的内容——是输出质量的"安全阀"。
top_p(核采样)Float · 累积概率截断
又称 nucleus sampling。不限定固定数量的词元,而是动态选取累积概率超过 p 的最小词元集合。例如 top_p=0.95 意味着选取概率之和达到 95% 的那些词元参与采样。相比 top_k 的固定截断,top_p 在高概率时段更保守、低概率时段更开放,自适应性更强。
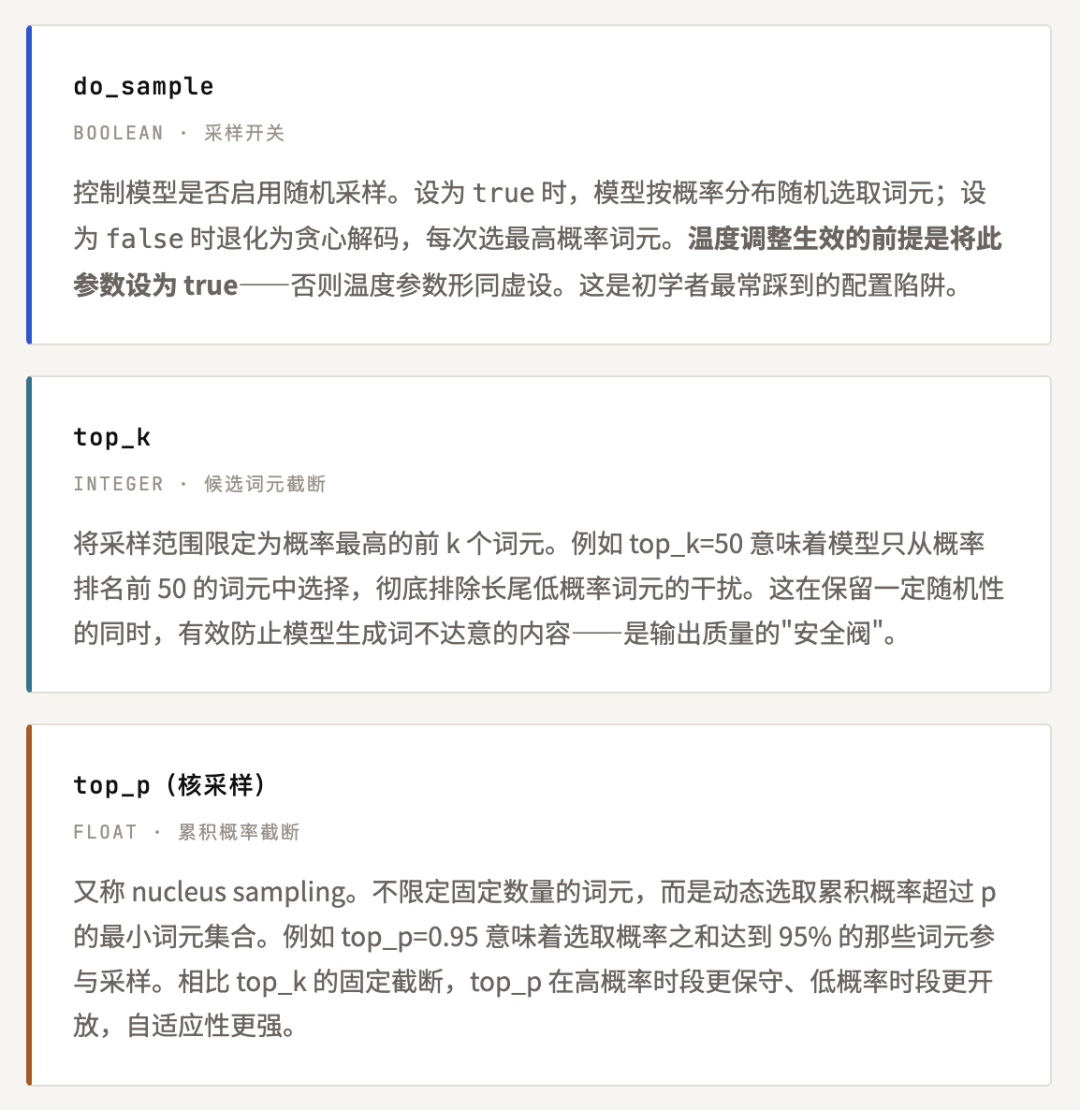
三者的组合逻辑是:temperature 调整分布形状 → top_k / top_p 截断候选范围 → 最终从筛选后的分布中采样。三者共同决定了模型输出的"随机性边界"。
05精确控制输出:四个关键参数
除采样策略外,还有一类参数直接作用于输出的结构与长度控制,是生产级部署中不可忽视的工程细节。
最大长度(max_length)
设定模型在单次生成中允许输出的最大词元数。防止模型无限生成或产生冗余内容,同时可管控 API 调用成本。对于实时对话场景,通常需要权衡响应速度与信息完整度来设定合理上限。
停止序列(stop_sequences)
指定特定字符串作为生成终止信号。例如在邮件生成任务中,可将"此致"设为停止序列,模型一旦生成该词即停止,无需等待 max_length 触发。对结构化格式输出(列表、对话、代码块)尤为有用。
频率惩罚(frequency_penalty)
按词元在当前输出中已出现的次数成比例降低其被再次选择的概率。词元出现越频繁,受到的抑制越强。有效减少"复读机"式重复,适合长文本生成场景。
存在惩罚(presence_penalty)
与频率惩罚类似,但不按频次成比例,而是对所有已出现过的词元施加固定惩罚。只要某词元出现过一次,即受到同等程度的抑制,鼓励模型引入新词汇,增大输出的词汇多样性。

06工程实战:温度调参的几条原则
理论清晰之后,以下是在实际项目中调整温度参数时值得遵循的几条经验原则:
从默认值 0.7 开始,而非两端。绝大多数模型的默认温度设在 0.7 附近,这是提供者基于大量实验得出的平衡点,是一个合理的起点,而非需要第一时间修改的对象。
确认 do_sample 已启用。在调整温度之前,务必验证采样已开启。许多 SDK 默认使用贪心解码,此时设置任何温度值都没有效果。
温度不能替代 prompt 工程。如果输出质量差,首先检查提示词的质量和格式,而不是盲目调整温度。温度控制的是概率分布的形状,不能弥补指令不清晰带来的问题。
结构化任务中考虑零温度 + 少量 top_p。对于 JSON 输出、代码生成、数学推导等需要精确性的任务,temperature=0(或极低值)配合 top_p=1 通常能获得最稳定的结果。
高温配合惩罚参数。在创意写作场景中使用高温时,建议同步开启 frequency_penalty 或 presence_penalty,以防止模型陷入词汇循环,保持输出多样性的同时维护基本质量。
如何配置你的 LLM?
在实际开发中,没有万能的参数,只有最契合的场景:
代码/逻辑推理: Temp ≈ 0.2, top_p = 0.1, Penalty = 0。你需要的是确定性。
日常助手: Temp ≈ 0.7, top_p = 0.9。兼顾人性化与准确度。
剧本/创意写作: Temp ≈ 1.2, top_p = 1.0, Presence Penalty > 0。让模型放飞自我更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)