5 Agent中断之如何明确用户意图
在人机交互中,用户的初始请求常常是模糊、不完整或存在歧义的。单轮"一问一答"模式无法有效处理这类情况,而多轮对话正是为了解决这一根本性问题而生。
其核心价值在于:通过与用户进行多轮、有上下文的交互,主动澄清、确认和补全信息,从而精准地理解并满足用户的真实意图。
一、多轮对话主要解决的问题
1. 信息缺失 (Missing Information)
问题描述: 用户的请求缺少完成任务所必需的关键信息(槽位/Slots)。
单轮对话的困境: 系统无法执行任务,只能返回一个笼统的错误提示,用户体验差。
多轮对话的解决方案: 系统主动发起追问,引导用户提供缺失的信息。
示例:
- 用户: “帮我订一张机票。”
- 系统 (单轮): “抱歉,我无法为您订票。” ❌
- 系统 (多轮): “好的,请问您要从哪里出发,目的地是哪里呢?” ✅
2. 意图模糊 (Ambiguous Intent)
问题描述: 用户的表述可以对应到多个不同的业务意图或操作。
单轮对话的困境: 系统可能猜错意图,执行错误的操作,导致严重后果。
多轮对话的解决方案: 系统列出可能的意图选项,让用户进行选择确认。
示例:
- 用户: “我的账户出问题了。”
- 系统 (单轮): (猜测是登录问题,发送重置密码链接) ❌ (但用户实际是想查询账单)
- 系统 (多轮): “很抱歉听到您的账户有问题。请问具体是以下哪种情况?A. 无法登录 B. 对账单有疑问 C. 其他问题” ✅
3. 信息冲突 (Conflicting Information)
问题描述: 用户在对话过程中前后提供了相互矛盾的信息。
单轮对话的困境: 系统无法处理冲突,可能导致逻辑错误或使用错误的数据。
多轮对话的解决方案: 系统识别冲突,并向用户确认应以哪条信息为准。
示例:
- 用户: “我想订明天去上海的火车票。”
- 系统: “好的,请问您希望几点出发?”
- 用户: “下午3点吧。哦对了,是后天去。”
- 系统 (多轮): “明白了。所以您是要订后天下午3点去上海的火车票,对吗?” ✅
4. 需求变更 (Evolving Needs)
问题描述: 在对话过程中,用户的需求发生了变化。
单轮对话的困境: 系统无法感知需求变化,会继续执行旧的指令。
多轮对话的解决方案: 系统能根据最新的上下文动态调整对话策略和目标。
示例:
- 用户: “给我推荐一家附近的意大利餐厅。”
- 系统: “附近有一家’罗马假日’,评分很高。”
- 用户: “算了,还是找家中餐吧,最好是川菜。”
- 系统 (多轮): “好的,已为您切换到川菜。附近有一家’巴蜀人家’…” ✅
二、多轮对话如何工作(核心机制)
多轮对话系统通常包含以下几个关键技术组件:
- 意图识别 (Intent Recognition): 判断用户当前话语想要做什么(如"订票"、“查天气”)。
- 槽位填充 (Slot Filling): 从用户话语中提取完成该意图所需的结构化信息(如"出发地"、“目的地”、“日期”)。
- 对话状态跟踪 (Dialogue State Tracking, DST): 维护一个全局的"对话状态",记录当前已识别的意图、已填充的槽位以及待澄清的问题。这是实现上下文感知的基础。
- 对话策略 (Dialogue Policy): 根据当前的对话状态,决定下一步该做什么。例如:
- 如果所有槽位都已填满,则执行任务。
- 如果有关键槽位缺失,则生成追问语句。
- 如果意图不明确,则生成澄清选项。
三、 代码以及案例
# -*- coding: utf-8 -*-
"""
ask_for_analysis
Author: user
Date: 2026/4/1
Description: 当智能体遇到模糊信息(例如,用户指令不明确、存在多种可能的解释)时,使用 LangGraph 实现“人在回路”(Human-in-the-Loop, HITL)来请求人工确认,是一个非常标准且强大的做法。
识别模糊性:在你的智能体逻辑中,需要有一个判断环节。例如,当大模型(LLM)分析用户输入后,如果发现意图不明确(比如,用户说“订票”,但没说明目的地、时间),它应该生成一个特定的状态,比如 {"needs_clarification": True, "clarification_question": "请问您要订去哪里的票?"}。
设计“澄清”节点:在 LangGraph 的状态图(StateGraph)中,创建一个专门用于处理模糊信息的节点,我们称之为 ask_for_clarification 节点。
这个节点的唯一任务就是读取状态中的 clarification_question,并将其呈现给用户。
设置中断点:这是关键一步。你可以在 ask_for_clarification 节点之后设置一个中断点 (interrupt_after=["ask_for_clarification"])。
为什么在“之后”? 因为 ask_for_clarification 节点负责“提问”,而中断点是为了“等待回答”。流程会先执行提问节点(将问题准备好),然后在下一步(等待答案)之前暂停。
恢复流程:当用户看到问题并给出答案后,将答案作为新消息再次 invoke(同一 thread_id);若使用节点内 interrupt(),则用 Command(resume=...) 恢复。interrupt_after 场景下通常只需传入 {"messages": [...]} 即可从 checkpoint 继续。
"""
from typing import Annotated, Any, Dict, Literal, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
load_dotenv(override=True)
llm = init_chat_model(model="deepseek-v3.1", #
model_provider='openai',
api_key= os.getenv("api_key"),
base_url= os.getenv("base_url"),
temperature=0.3,
max_retries=4,
#max_tokens=10
)
# --- 1. 定义状态 ---
class State(TypedDict):
messages: Annotated[list, add_messages]
needs_clarification: bool
clarification_question: str
# --- 2. 初始化模型和检查点器 ---
#llm = ChatOpenAI(model="gpt-4o-mini")
memory = MemorySaver()
# --- 3. 定义节点函数 ---
def analyze_intent(state: State):
"""分析用户意图,判断是否需要澄清"""
messages = state["messages"]
# 让LLM判断意图是否清晰
prompt = f"""
请分析以下对话,判断用户的最终意图是否足够清晰以执行任务。
如果意图模糊,请设置 needs_clarification=True 并提供一个具体的澄清问题。
如果意图清晰,请设置 needs_clarification=False。
对话历史:
{messages}
请以严格的JSON格式回复,只包含以下两个字段:
{{
"needs_clarification": true/false,
"clarification_question": "如果需要澄清,请在此处写下问题;否则为空字符串"
}}
"""
response = llm.invoke([HumanMessage(content=prompt)])
try:
import json
raw = response.content
if isinstance(raw, list):
raw = "".join(
b.get("text", "") if isinstance(b, dict) else str(b) for b in raw
)
result = json.loads(raw)
return {
"needs_clarification": result["needs_clarification"],
"clarification_question": result["clarification_question"],
}
except Exception:
# 如果解析失败,默认需要澄清
return {
"needs_clarification": True,
"clarification_question": "抱歉,我没太明白您的意思,能再说一遍吗?",
}
def ask_for_clarification(state: State):
"""向用户提出澄清问题"""
question = state["clarification_question"]
print(f"[智能体提问]: {question}")
# 在真实应用中,这里会通过API/UI将问题发送给前端
return {"messages": [AIMessage(content=question)]}
def execute_task(state: State):
"""在信息明确后,执行最终任务"""
messages = state["messages"]
final_prompt = f"现在所有信息都已明确,请完成用户请求。对话历史: {messages}"
response = llm.invoke([HumanMessage(content=final_prompt)])
print(f"[智能体执行结果]: {response.content}")
return {"messages": [response]}
# --- 4. 构建状态图 ---
builder = StateGraph(State)
# 添加节点
builder.add_node("analyze", analyze_intent)
builder.add_node("ask", ask_for_clarification)
builder.add_node("execute", execute_task)
# 设置入口
builder.add_edge(START, "analyze")
# 条件路由
def route_after_analysis(state: State) -> Literal["ask", "execute"]:
if state["needs_clarification"]:
return "ask"
else:
return "execute"
builder.add_conditional_edges(
"analyze",
route_after_analysis,
{"ask": "ask", "execute": "execute"}
)
# 从 ask 节点回到 analyze,形成循环,直到信息明确
builder.add_edge("ask", "analyze")
builder.add_edge("execute", END)
# --- 5. 编译图,并设置中断点 ---
# 关键:在 'ask' 节点之后中断,等待用户回答
app = builder.compile(
checkpointer=memory,
interrupt_after=["ask"] # 在 ask 节点执行后中断
)
# # 将生成的图片保存到文件
# graph_png = app.get_graph().draw_mermaid_png()
# with open("langgraph_base.png", "wb") as f:
# f.write(graph_png)
#
def _is_paused_after_ask(app, config: dict, invoke_result: Dict[str, Any]) -> bool:
"""
判断首轮是否在 interrupt_after=['ask'] 处暂停、需要用户再输入后再 invoke。
说明:不少 LangGraph 版本里,interrupt_after 暂停时 invoke 返回的只是普通 state
(messages / needs_clarification 等),**没有** __interrupt__ 字段;是否暂停要看
get_state(config) 里是否还有待执行的下一步(next / tasks / interrupts)。
"""
if invoke_result.get("__interrupt__"):
return True
try:
snap = app.get_state(config)
except Exception:
return False
nxt = getattr(snap, "next", None)
if nxt is not None and len(tuple(nxt)) > 0:
return True
tasks = getattr(snap, "tasks", None)
if tasks and len(tasks) > 0:
return True
intr = getattr(snap, "interrupts", None)
if intr:
return True
# 兜底:少数版本里暂停后 next 可能为空,但 state 已是「刚问完澄清问题」
if invoke_result.get("needs_clarification") and invoke_result.get("messages"):
msgs = invoke_result["messages"]
q = invoke_result.get("clarification_question") or ""
last = msgs[-1]
last_text = getattr(last, "content", None) or ""
if q and last_text == q:
return True
return False
# --- 6. 模拟运行 ---
config = {"configurable": {"thread_id": "1"}}
# 用户输入(可改成模糊指令测试「提问→中断」)
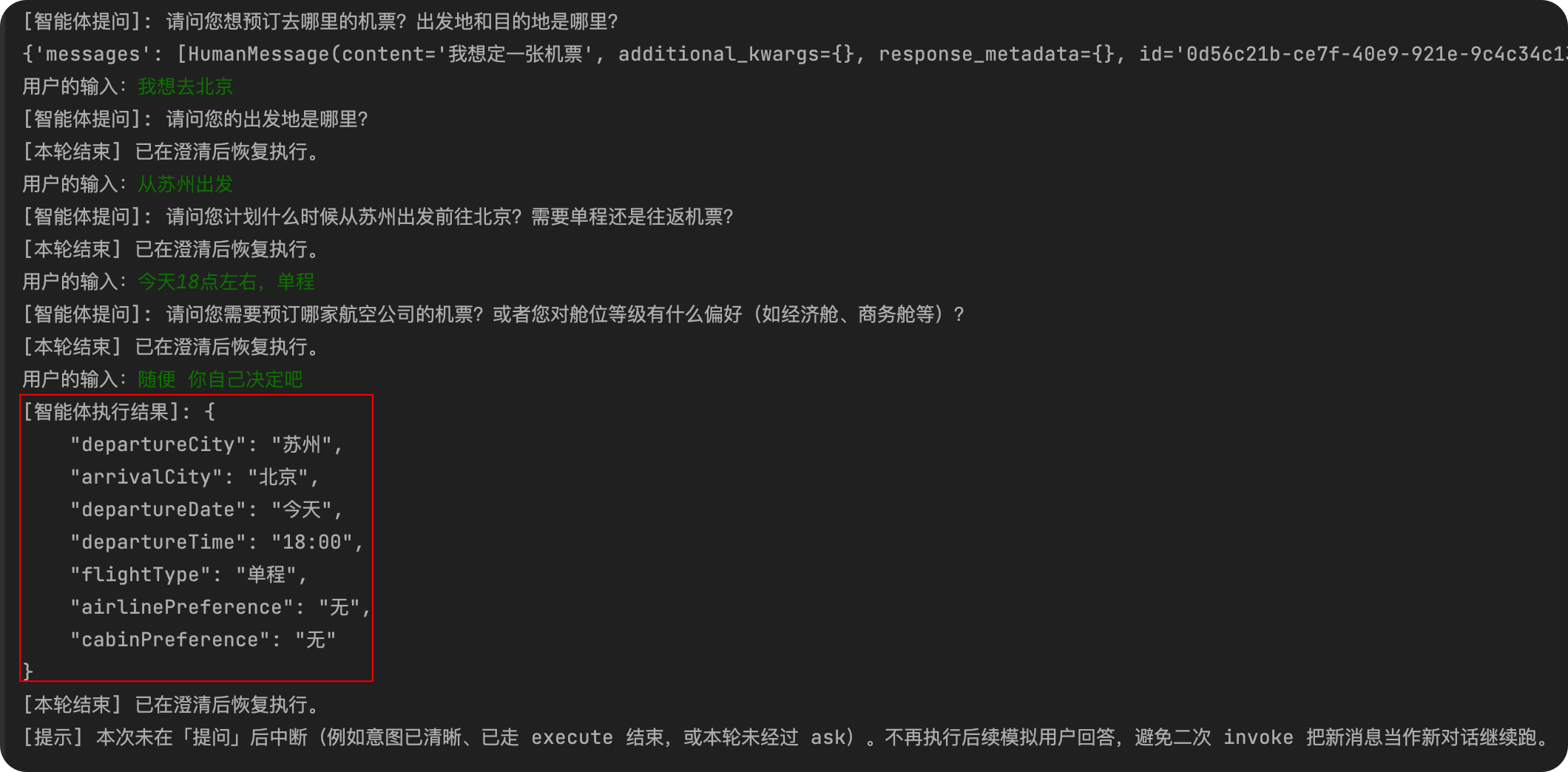
user_input = "我想定一张机票" #input("用户的输入:")
#print(f"[用户输入]: {user_input}")
# 第一次运行:若需澄清会走 ask,并在 ask 之后中断;若未走 ask 则直接 execute 到 END,不会中断
result = app.invoke({"messages": [HumanMessage(content=user_input)]}, config=config)
#print(result)
while True:
if not _is_paused_after_ask(app, config, result):
print(
"[提示] 本次未在「提问」后中断(例如意图已清晰、已走 execute 结束,或本轮未经过 ask)。"
"不再执行后续模拟用户回答,避免二次 invoke 把新消息当作新对话继续跑。"
)
break
else:
# 仅在真正中断时,才模拟用户补充回答并继续
user_answer = input("用户的输入:")
#print(f"[用户回答]: {user_answer}")
# interrupt_after:同一 thread_id 再次 invoke,合并新消息并从 checkpoint 继续
result = app.invoke(
{"messages": [HumanMessage(content=user_answer)]},
config=config,
)
#print("[本轮结束] 已在澄清后恢复执行。")
四、总结
多轮对话不是简单的聊天功能,而是一种结构化的、目标导向的交互范式。它通过模拟人类沟通中的"确认"和"追问"行为,有效地解决了因用户输入不完美而导致的服务失败问题。
最终,多轮对话的目标是在最少的交互轮次内,以最自然的方式,达成对用户意图的100%准确理解,从而提供可靠、高效且令人满意的服务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)