AI 工程化实战:拒绝“开盲盒”,像写代码一样搞定提示词工程
本文全面介绍了提示词相关内容,包括提示词工程的重要性,如何写好一个提示词 Prompt,以及使用 Coze 平台进行实操,适合零基础小白入门。
面对汹涌而来的 AI 浪潮,很多研发同学感到焦虑。但其实,对于非算法背景的我们来说,不需要成为研发「发动机」的算法科学家,而是要成为能够驾驭「赛车」的 AI 工程师。
今天,我们就来学习第一项、也是最核心的驾驶技术:提示词工程(Prompt Engineering,简称 PE)。
提示词工程听上去很高大上,实际上说白了就是我们给大模型写指示,想办法让它更听话。
这就像带实习生一样:你说得越清楚,他干得越靠谱。如果任务没说清楚,实习生可能会把事情办砸;大模型也一样,Prompt 写得好不好,直接决定它能不能完美完成任务。
- 重要性:为什么PE 是必备技能?
翻开现在各大公司的 AI 工程师招聘 JD,你会发现“熟练掌握提示词工程”几乎已经成了硬性标配。

很多纯开发的同学可能会不屑:“写提示词不就是跟机器人聊天吗?这玩意儿有什么技术含量?”
这实际上是一个巨大的认知误区。
(1) 从“自由闲聊”到“工程协议”
在普通用户眼里,Prompt 是对话;但在开发者眼里,Prompt 其实是代码逻辑的自然语言化。
- 用户在“对话”: 输出是发散、随性的,好坏全看 AI 心情。
- 工程在“封装”: 我们需要输出是收敛、确定、格式化的。
如果 Prompt 写得不好,大模型哪怕只是多返回了一个句号,或者 JSON 格式稍微错位,业务系统在解析数据时可能就会直接报错,导致整个业务链路崩溃。
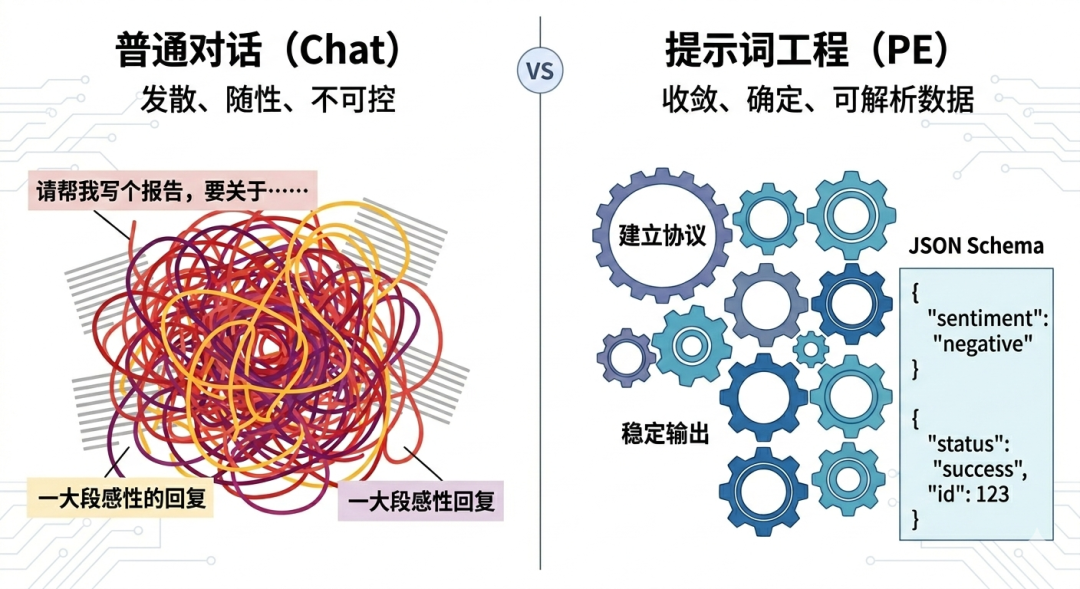
因此,PE 的核心价值在于:建立一套人机交互的工程化协议,让原本不可控的“黑盒”,变成一个能稳定输出结果的“函数”。
(2)ROI(投资回报率)极高的 AI 技能
对于普通开发者而言,PE 是最容易掌握、见效最快的 AI 核心能力。
- 零成本: 你不需要深究底层的复杂数学原理,不需要排队购买昂贵的显卡去微调模型,甚至不需要改动一行的业务逻辑代码。
- 高收益: 仅仅是把提示词写清楚,同一个任务的准确率就能从 60%(勉强及格) 飙升到 90% 以上(工业级水平)。这中间 30% 的差距,往往就是你的 AI 业务能不能落地、老板和用户满不满意的关键决胜点!
一句话总结:提示词工程,就是让大模型更听话。这是我们普通人最容易掌握、见效最快的 AI 能力。
- 理论:如何写好一个 Prompt?
我们知道 LLM 本质上是一个“概率预测机”,它读取文本,计算概率,预测下一个词,循环往复。在这个过程中,我们给 LLM 的所有输入统称为 Prompt(提示词)。
但这里有个工程难题:如果输入是发散的,输出必然也是发散的。
举个例子,我们想让 LLM 判断用户反馈是正面还是负面:
- ❌写法 A:
这条评论是正面的还是负面的?用户说界面太丑了,卸载了。
- LLM 可能回答: “是负面的”、“负面情绪” 或者 “由于用户提到了卸载,这显然是负面的…”。
- 后果:输出不稳定,回答可能五花八门。这在聊天时没问题,但如果需要解析结果(比如存入数据库、触发告警),这种不统一的格式简直是开发者的噩梦。
- ✅写法B:
你是一个情感分析专家。请判断以下用户反馈的情感倾向,只返回"正面"或"负面"或"中性",不要输出任何解释。用户反馈:"界面太丑了,卸载了!"
- LLM 回答: 负面。
- 后果: 输出更加稳定。
这就是*提示词工程(Prompt Engineering)*的核心:通过精心设计 Prompt,让 LLM 的输出更稳定、更准确、更符合业务需求。
我们继续用"判断用户反馈情感"这个例子,按照以下几个步骤进行调优:
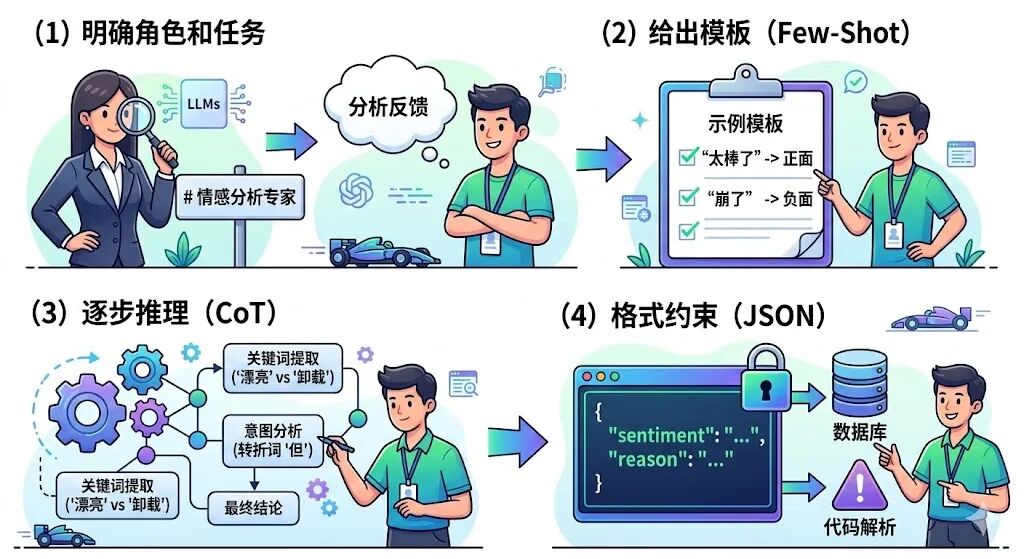
(1) 先把话清楚:明确角色和任务
第一步是“定义人设”,告诉 LLM:你是谁,要做什么。在 API 开发中,这通常通过 System Prompt(系统提示词) 来实现。
- 角色定义:“你是一个情感分析专家”——这样 LLM 会自动调整"专业程度",知道要从用户反馈中提取情感信号。
- 任务指令:“请判断用户反馈的情感倾向”——不要让 LLM 去猜你想干什么,直接说清楚。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向,只返回"正面"或"负面"或"中性":
(2)给出模板:让 LLM 照着做
直接下指令,LLM 有时仍会“放飞自我”。比如你要求“只返回正面或负面”,它可能会输出“这条反馈是负面的”或者“Negative”。这些都是"负面"的意思,但格式不一致。这时候,给他几个示例最有效,这叫 少样本学习(Few-Shot Learning)。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向,只返回"正面"或"负面"或"中性":
# 示例
## 示例1输入:
这个APP太棒了!
## 示例1输出:
正面
## 示例2输入:
用了一天就崩了,垃圾软件。
## 示例2输出:
负面
就像给实习生一个"参考答案模板",他看了几个例子,自然就明白该怎么干了。而且这不需要重新训练模型,完全靠 LLM 强大的"上下文学习能力",给它几个例子,它就能学会新任务的规律。
(3)让它慢下来:逐步推理
在处理复杂情感时(比如阴阳怪气、转折句),LLM 容易直接“跳步”给错答案。
比如用户评论:“界面漂亮但反应慢,每次加载都要等一分钟,果断卸载了”。LLM 可能看到“漂亮”就直觉式地判断为“正面”,忽略了核心的负面诉求。
如果加一句话: “请逐步思考(Let’s think step by step)” ,准确率会神奇地提升。这就是 CoT(Chain of Thought,思维链)。
LLM 的内部逻辑流会变为:
-
关键词提取:“界面漂亮”(正)、“反应慢”(负)、“想卸载”(极负)。
-
意图分析:虽然有视觉上的夸赞,但最终行为是卸载,表达了强烈的挫败感。
-
最终结论:负面。
核心逻辑: 强迫 LLM 先把推理过程写出来,这个过程会成为后续生成的“上下文”,相当于模型在“自我检查”,确保结论是推导出来的,而不是“猜”出来的。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向。请逐步思考后再输出结果。只返回"正面"或"负面"或"中性":
# 示例
## 示例1输入:
这个APP太棒了!
## 示例1输出:
正面
## 示例2输入:
界面漂亮但反应慢,每次加载都要等一分钟,果断卸载了。
## 示例2输出:
负面
除了简单地加上"请逐步思考"外,更有效的方式是我们在 Prompt 中定义好大模型的每一步推理过程,给出固定模板:
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向。请按照以下步骤逐步思考后再输出结果,只返回"正面"或"负面"或"中性":
# 分析步骤
1. **关键词提取:从句子中找出所有具有情感倾向的词,标注每个词汇的情感极性(正面/负面/中性)**
2. **上下文分析:**
- 分析词汇间的逻辑关系(转折、递进、并列、正话反说等),判断核心情感诉求(如转折句中,后半句通常为核心;正话反说需结合语境判断真实情绪);
- 识别中性场景:若反馈中无明显正面/负面词汇,仅为客观描述,或正面与负面词汇权重相当、相互抵消,均判定为中性场景;
- 区分网络用语的情感倾向(如“666”表示认可<正面>,“6”表示讽刺<负面>,“还行”表示中性);
3. **情感权重判断:对提取的情感词汇进行权重排序,核心诉求对应的词汇权重高于次要描述;中性词汇不参与权重竞争,仅在无明显正负倾向或正负权重相当时生效;**
4. **最终结论:**
- 正面信号权重>负面信号权重,返回“正面”;
- 负面信号权重>正面信号权重,返回“负面”;
- 正面与负面信号权重相当,或无明显正负信号、仅为客观描述,返回“中性”。
# 示例
## 示例1输入:这个APP太棒了!
## 示例1输出:正面
## 示例2输入:界面漂亮但反应慢,每次加载都要等一分钟,果断卸载了。
## 示例2输出:负面
CoT 虽然能够带来准确率的提升,但也会增加推理成本和响应延迟。因此我们需要根据任务复杂度灵活使用:
- 简单任务(如情感分析、分类) :无需使用 CoT 优化。
- 优点:响应快、Token 成本低
- 适用场景:输入清晰的简单分类、问答
- 复杂任务(如代码生成、多步骤推理) :必须开启 CoT。
- 优点:显著提升准确率
- 适用场景:数学题、代码生成、需要多步骤思考的复杂任务
(4)格式约束:让程序能读懂
前面解决的是“答得对”,但在代码场景下,还有一个关键问题:让 LLM “答得能被程序解析”。
业务系统中,我们通常希望 LLM 返回 JSON 这种结构化数据。但 LLM 是个“话痨”,你让它返回 JSON,它可能随口回一句:“好的,这是你要的结果:{…}”。这多出来的几个字,就会导致 json.loads() 直接报错。
为了解决这个问题,工程上通常采用“事前约束 + 事后纠错”的组合拳:
- 结构化 Prompt(事前约束)
直接给模型一个标准的 JSON 模板,并约束它不要输出多余的解释。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向。请按照以下步骤逐步思考后再输出结果,只返回"正面"或"负面"或"中性":
# 分析步骤
1. **关键词提取:从句子中找出所有具有情感倾向的词,标注每个词汇的情感极性(正面/负面/中性)**
2. **上下文分析:**
- 分析词汇间的逻辑关系(转折、递进、并列、正话反说等),判断核心情感诉求(如转折句中,后半句通常为核心;正话反说需结合语境判断真实情绪);
- 识别中性场景:若反馈中无明显正面/负面词汇,仅为客观描述,或正面与负面词汇权重相当、相互抵消,均判定为中性场景;
- 区分网络用语的情感倾向(如“666”表示认可<正面>,“6”表示讽刺<负面>,“还行”表示中性);
3. **情感权重判断:对提取的情感词汇进行权重排序,核心诉求对应的词汇权重高于次要描述;中性词汇不参与权重竞争,仅在无明显正负倾向或正负权重相当时生效;**
4. **最终结论:**
- 正面信号权重>负面信号权重,返回“正面”;
- 负面信号权重>正面信号权重,返回“负面”;
- 正面与负面信号权重相当,或无明显正负信号、仅为客观描述,返回“中性”。
# 输入格式
{
"feedback": "<用户反馈内容>"
}
# 输出格式
{
"sentiment": "正面/负面/中性",
"reason": "<原因分析>"
}
# 约束
1. **必须仅返回 JSON 数据,禁止任何解释性文字**
2. **sentiment 字段只能是 "正面" 或 "负面" 或 "中性"**
3. **reason字段需结合关键词提取、上下文分析,说明判断依据,中性反馈需明确“无明显正负倾向”“客观描述”等核心依据,不遗漏核心情感点。**
# 示例
## 示例1输入
{"feedback": "这个APP太棒了!"}
## 示例1输出
{"sentiment": "正面", "reason": "用户使用正面词汇 “太棒了” 直接夸赞 APP,核心情感为满意,无负面诉求,情感倾向正面"}
## 示例2输入
{"feedback": "界面漂亮但反应慢,每次加载都要等一分钟,果断卸载了"}
## 示例2输出
{"sentiment": "负面", "reason": "提取到正面词汇 “漂亮”,负面词汇 “反应慢”“加载要等一分钟”“果断卸载”;上下文通过 “但” 转折,后半句为核心诉求,负面描述及卸载行为体现用户的不满,负面信号权重远高于正面信号权重,情感倾向负面"}
- 工程化鲁棒性(事后纠错) 在实际业务中,单靠 Prompt 依然会有概率遇到非法格式。研发通常会引入以下兜底方案:
- 原生 JSON 模式:调用 API 时开启模型自带的
response_format: { "type": "json_object" }模式,强制模型输出。(如果平台支持的话)。 - 自动修复(Repair):使用类似
json_repair的库。这些库利用算法修复模型输出中缺失的引号、括号或多余的解释语。 - 重试机制(Retry):如果解析失败,自动进行 2-3 次重试,或者在重试时把错误信息返还给模型(“你刚才返回的格式错了,请修正”)。
- 实战:Coze 平台构建智能体
理论讲完了,现在我们上实战。
在现代 AI 开发中,将 Prompt 与代码解耦是最佳实践。硬编码 Prompt 不仅维护困难,而且难以测试和迭代。
这里以 Coze(扣子)平台作为演示。作为一个极佳的 Bot 构建平台,它的优势在于:
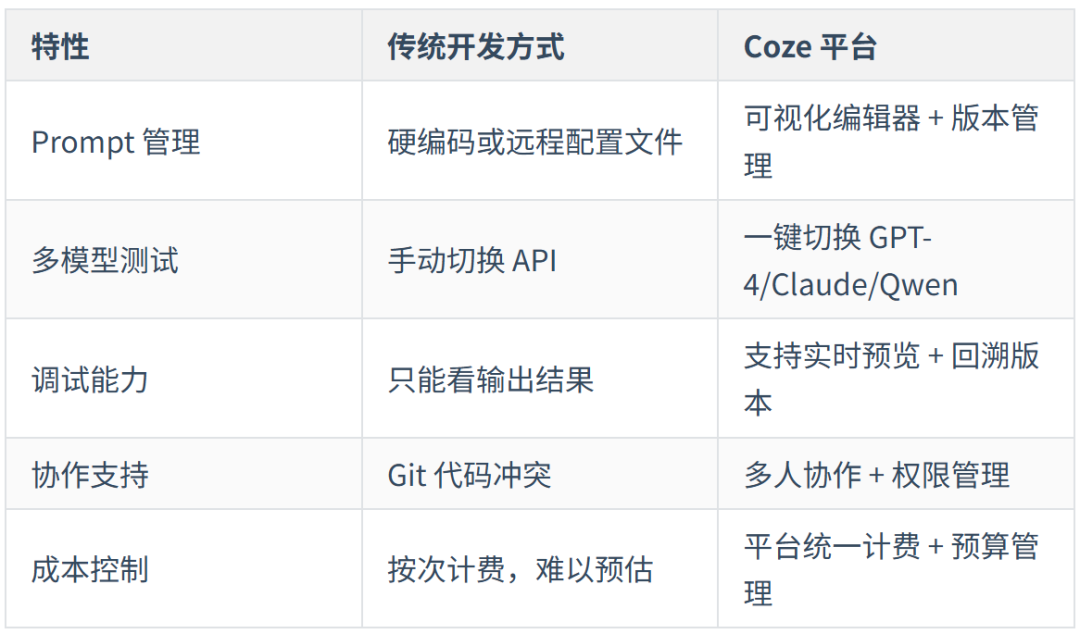
注:Coze 平台也支持知识库、工作流等能力,后续讲到 RAG、Workflow 等内容时会再次用到。
下面通过 Coze 平台快速上手,完成情感分析 Bot:
-
登录 Coze 平台,网站:https://www.coze.cn/home
-
点击
创建->创建智能体,命名:情感分析助手
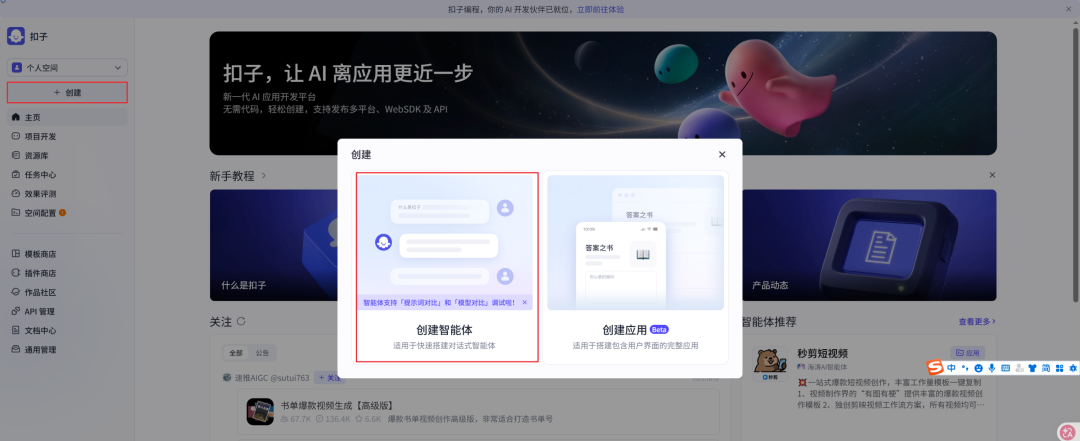
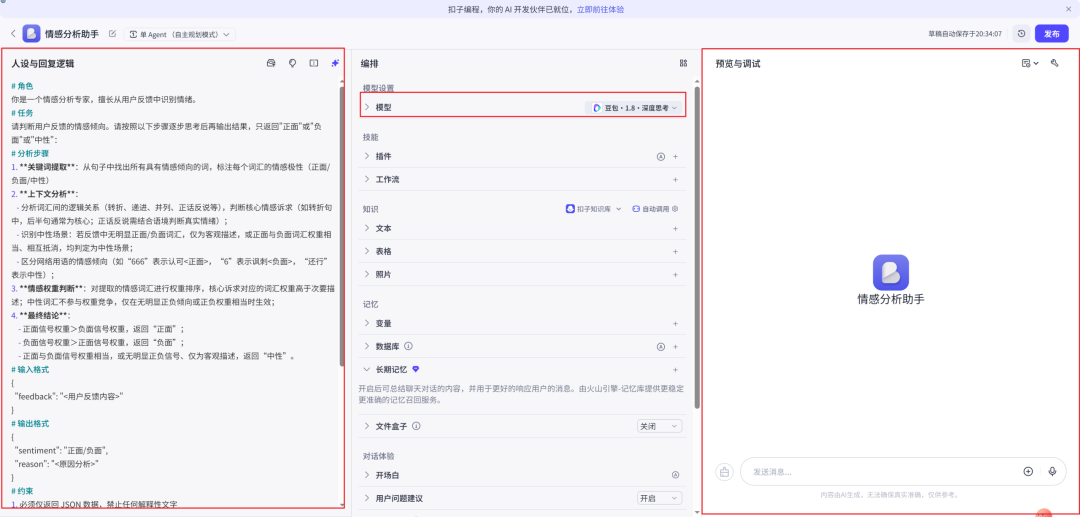
- 配置
人设与回复逻辑(也就是我们理论部分的 System Prompt),模型使用默认即可。
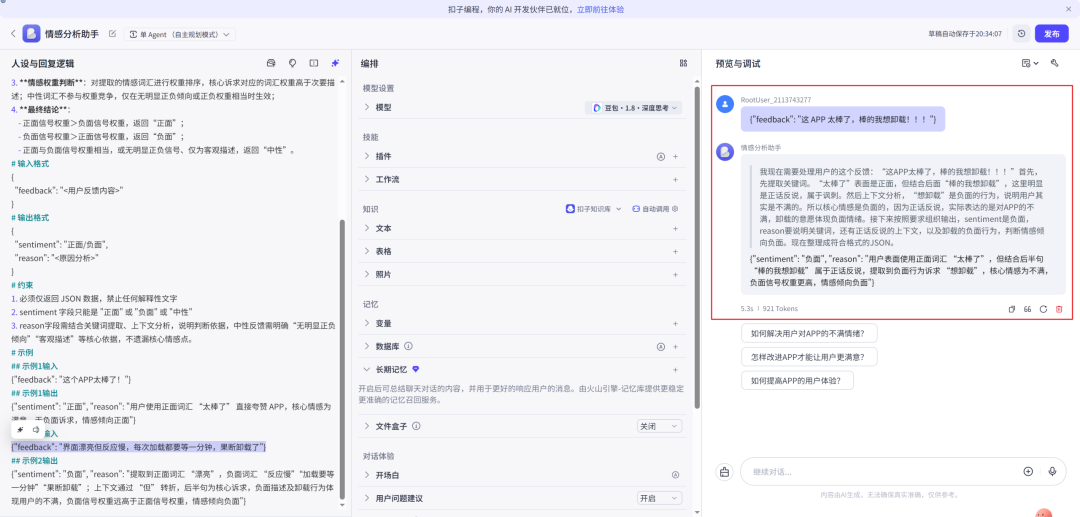
- 在右侧对话区输入测试数据进行实时调试,比如输入
{"feedback": "这 APP 太棒了,棒的我想卸载!!!"},模型便会分析出对应情感。
- 如果希望通过 API 调用,可以参考官方文档:https://www.coze.cn/open/docs/developer_guides/coze_api_overview。
- 总结
Prompt Engineering 绝非简单的“搭话”,它是目前连接自然语言与计算机代码最重要的一座桥梁。
通过定义角色、明确约束、提供示例 (Few-Shot) 以及 激发思维链 (CoT)等方式,我们能把一个不稳定的概率模型,变成业务中可靠的“智能外脑”。
而借助 Coze 这样的平台,我们能完美实现 Prompt 与代码的解耦,让 AI 工程化变得前所未有的顺畅。
上一篇文章 我们全面概述了大模型的相关知识,今天则正式解锁了至关重要的提示词工程 (PE)。
但这仅仅是开始。在接下来的实战系列中,我将继续带大家深度解锁更多 AI 核心知识点:检索增强生成(RAG)、工作流(Workflow)、智能体(Agent)、LangChain、Coze、n8n 等等。
如果觉得文章还不错,别忘了关注、点赞、推荐三连支持!
让我们一起持续进化,成为真正能够驾驭“赛车”的 AI 工程师。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)