3分钟部署本地大模型,零成本实现 Token 自由!
在 AI 学习和开发中,很多人会面临这些困扰:云厂商 API 计费贵、注册实名门槛高、敏感代码不敢上传、没网就不能用。
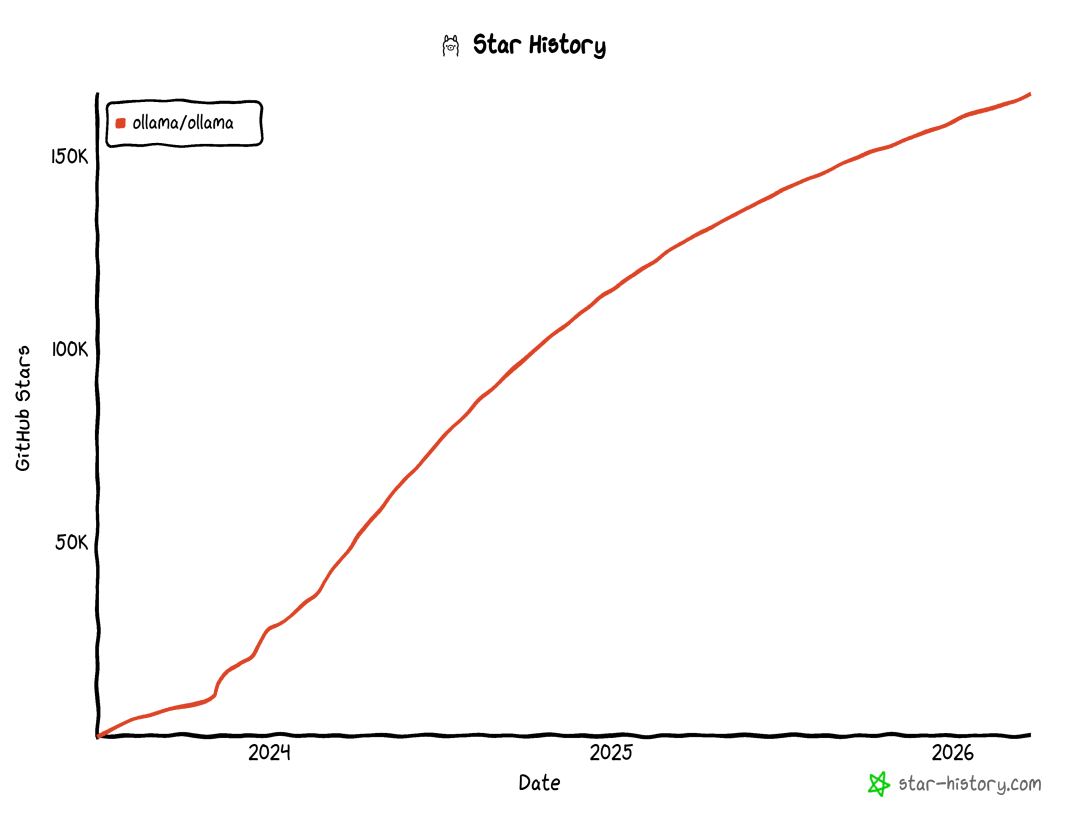
其实,本地部署早已不再复杂。目前 GitHub 上 16.6 万 Star 的开源项目 Ollama,已经把门槛降到了极致。
它能自动处理环境和硬件加速,让你在 3 分钟内拥有一套完全私有、零成本的大模型服务。
下面以 Windows 为例(macOS/Linux 流程基本一致),带你一步步上手 Ollama。
1、下载安装
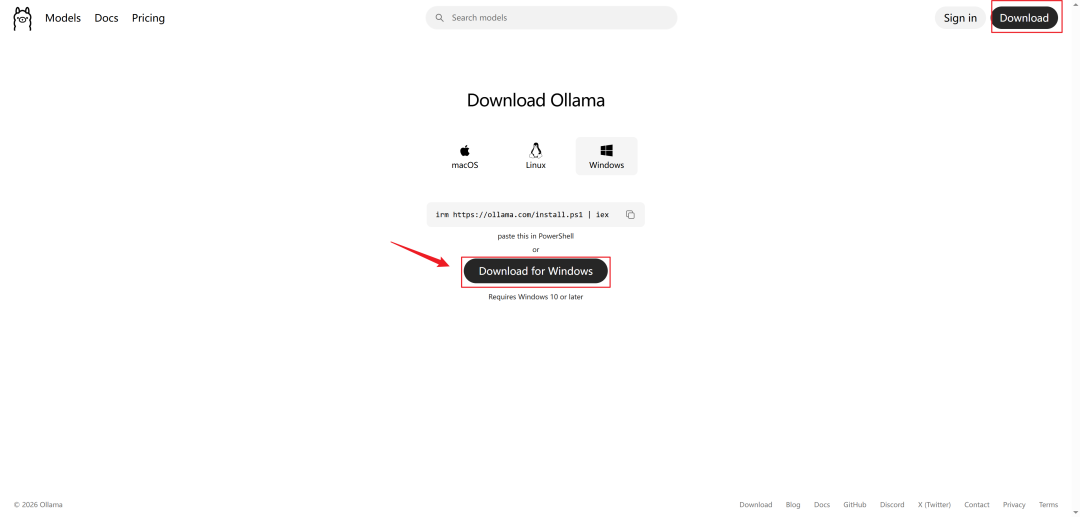
访问 Ollama 官网(https://ollama.com/download),点击Download for Windows,会自动下载 OllamaSetup.exe安装文件。
2、自定义安装路径(可选)
Ollama 默认会安装到 C 盘,下载的模型也存储在 C 盘。如果你的 C 盘空间充足,可以跳过这一步,直接完成安装即可。
但如果你的 C 盘空间紧张,建议自定义安装路径和模型存储路径。
首先打开 CMD 窗口,进入到安装包所在目录,执行以下命令:
OllamaSetup.exe /DIR="D:/Ollama"
这样会将软件安装到D:/Ollama路径下(你可以根据需要修改路径)。
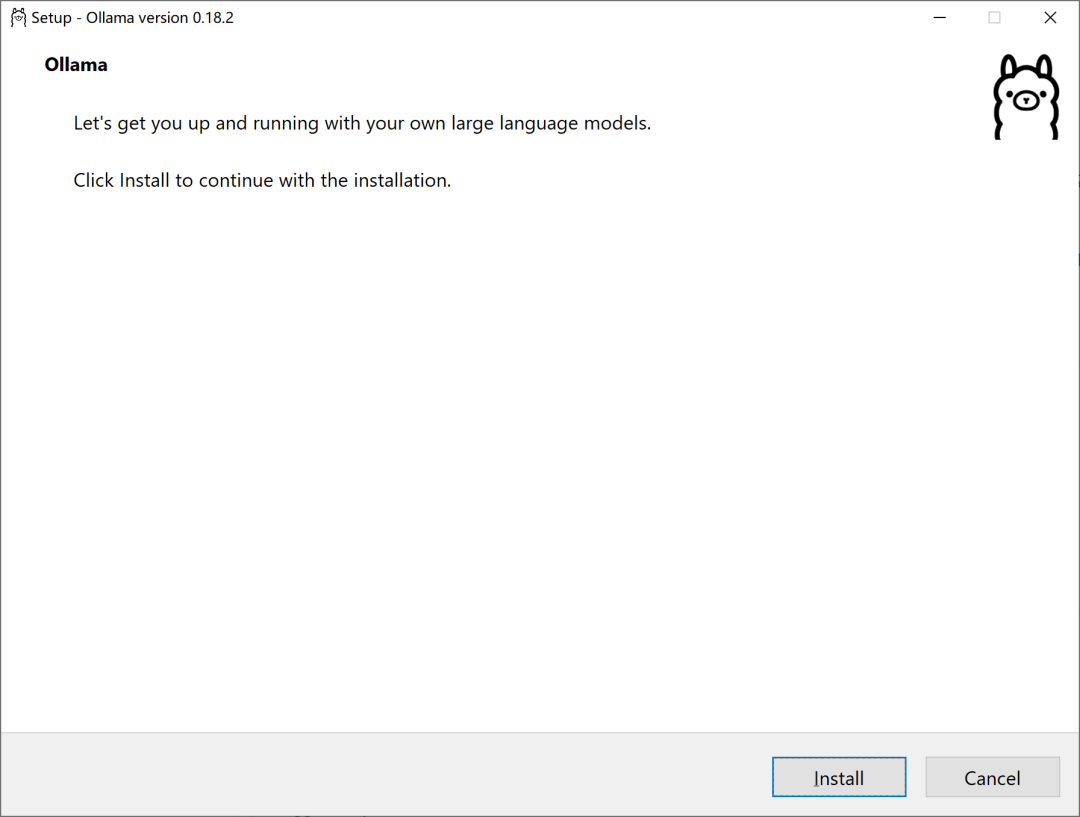
在弹出的安装界面点击Install,等待安装完成。
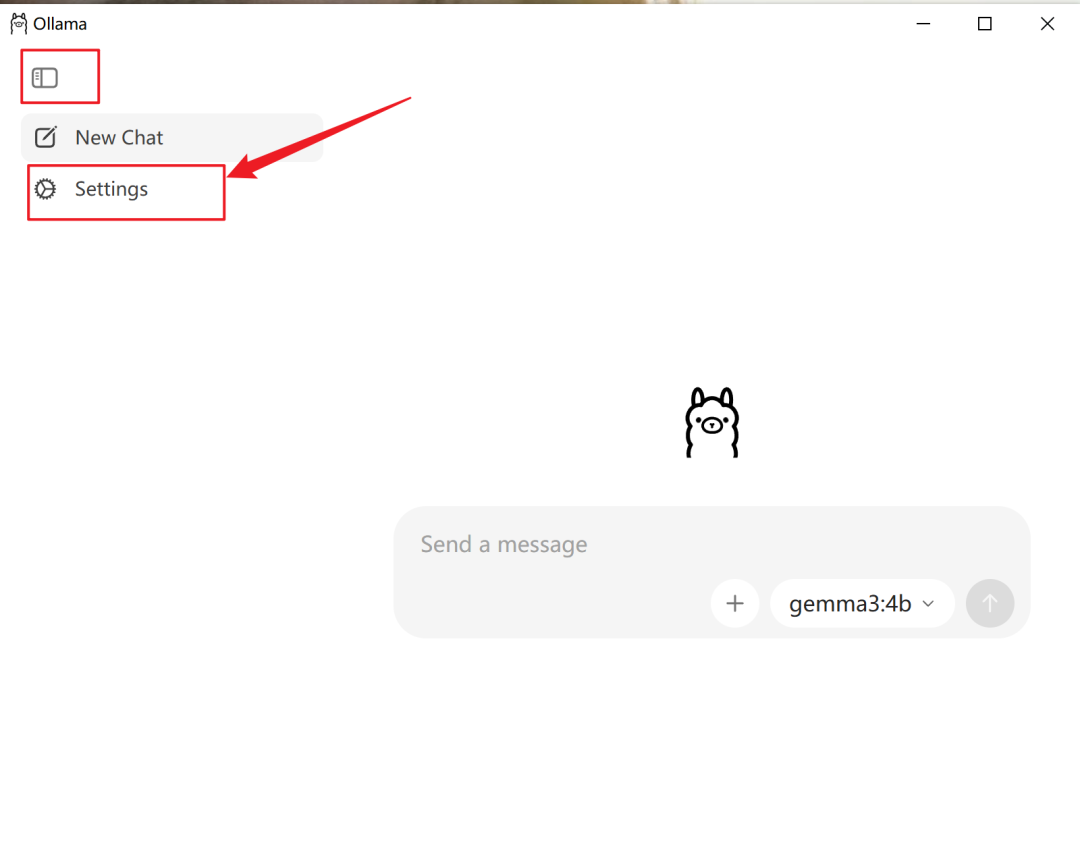
安装完成后,会弹出 Ollama 的对话界面。先别急着开始对话,我们先调整一下模型存储路径。
点击界面左侧按钮,选择Settings,然后点击Browse选择模型要存放的路径即可。
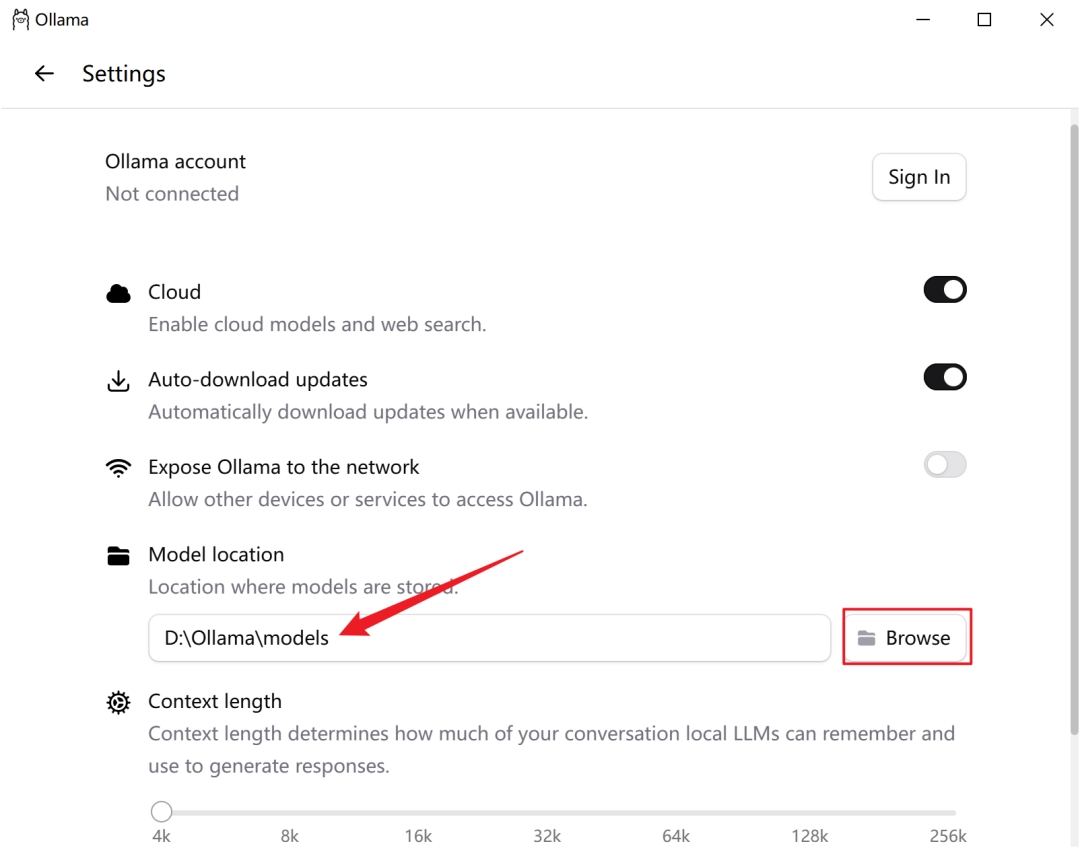
3、下载模型
在 Ollama 中,模型名字后的数字(如 3B, 7B, 32B)代表参数量,单位是"十亿"(Billion)。
参数量越大,模型越聪明,但对电脑配置要求越高,Ollama 会自动优化配置策略,有 GPU 时优先使用 GPU 加速,没有 GPU 时自动切换到CPU运行。
为了帮你快速选择合适的模型,这里有一个简单的参考对照表:
| 参数量 | 模型大小 | 内存/显存要求 | 推荐场景 |
|---|---|---|---|
| 2B-3B | 1.5-2.2GB | 4GB | 基础对话、简单问答 |
| 7B-8B | 3.8-4.7GB | 8GB | 日常对话、代码辅助 |
| 13B-14B | 7.4-8.8GB | 16GB | 复杂推理、长文本 |
| 30B-32B | 18-20GB | 32GB | 专业领域、深度分析 |
| 70B | 39-40GB | 64GB | 高级推理、接近GPT-3.5 |
| 120B+ | 70GB+ | 80GB+ | 接近GPT-4级别 |
Ollama 客户端界面提供了一些热门模型,你可以直接和它对话,系统会自动下载所需的模型。
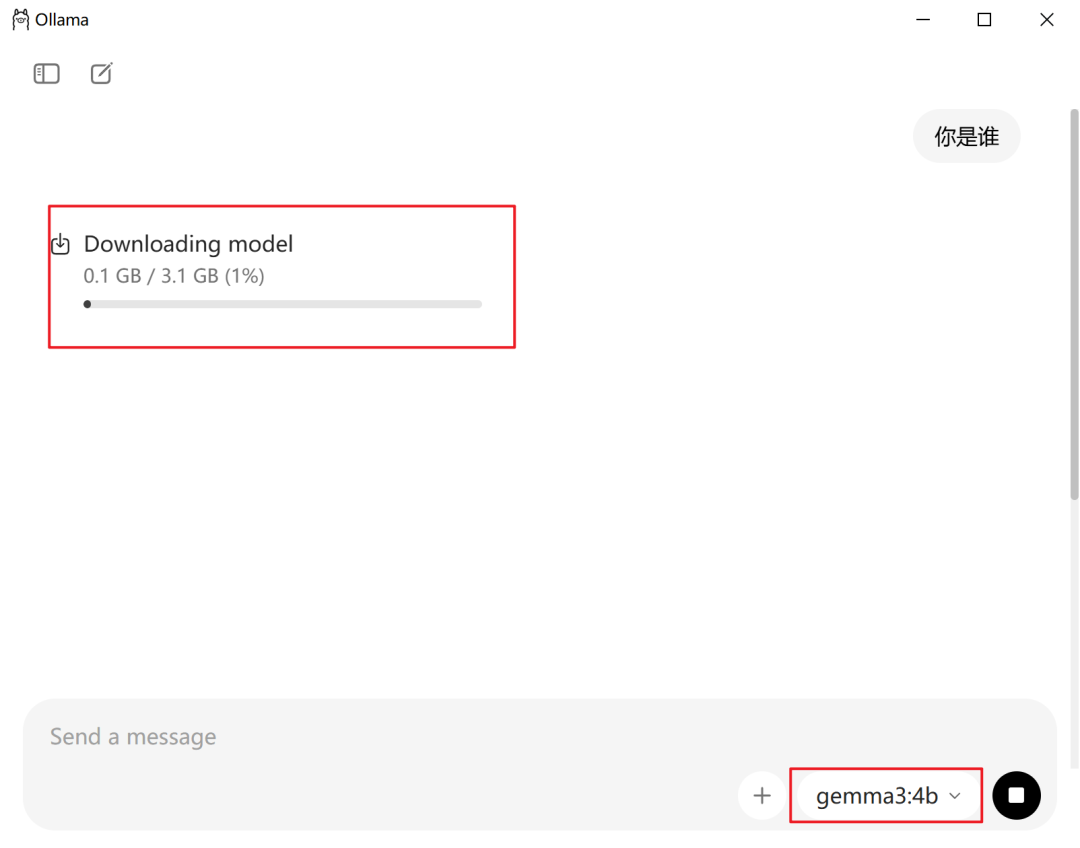
不过客户端上展示的模型不全,如果想要下载更多模型,可以去官网 https://ollama.com/search 查找,支持按照流行度/发布时间排序,还可以通过标签筛选是否支持深度思考,是否支持 Function Calling 功能等能力。
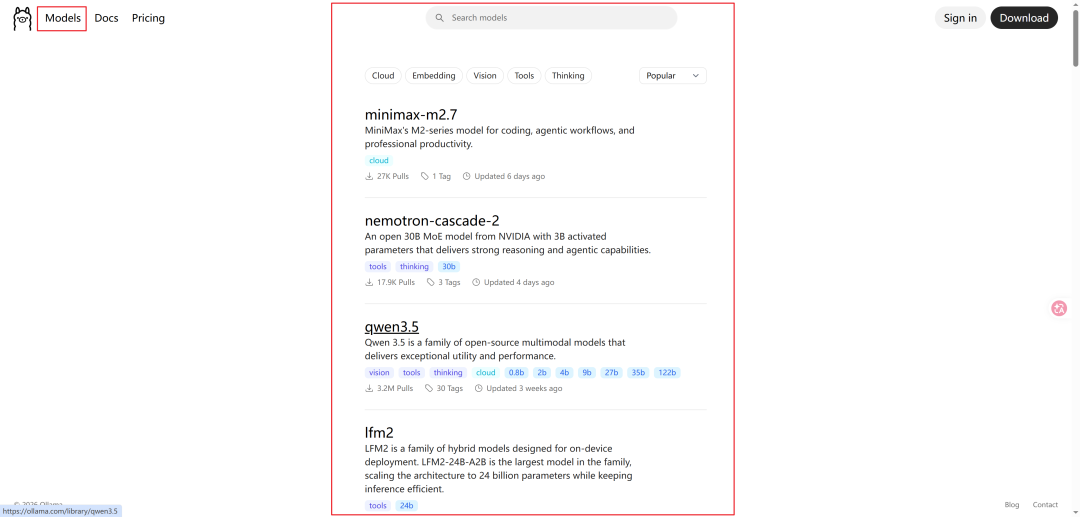
如果找到了想要的模型,可以通过 CMD 命令行下载,示例如下:
# 下载通义千问
ollama pull qwen3.5:4b
# 查看已下载的模型
ollama list
# 输出:
# NAME ID SIZE MODIFIED
# gemma3:4b a2af6cc3eb7f 3.3 GB 37 seconds ago
# qwen3.5:4b 2a654d98e6fb 3.4 GB 55 seconds ago
4、代码调用模型
Ollama 的一大优势是兼容 OpenAI API 格式,这意味着你可以直接使用 OpenAI SDK 调用本地模型,只需改一行 URL,就能从云端无缝切换到本地。
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/', # 指向本地 Ollama 默认端口 11434
api_key='ollama-local', # 可随意填写,Ollama 不做强制校验
)
response = client.chat.completions.create(
model="gemma3:4b", # 确保调用的model名称已下载
messages=[
{"role": "user", "content": "你是谁?"}
]
)
print(response.choices[0].message.content)
就是这么简单——你不需要学习新的 API,所有熟悉的OpenAI调用方式都能直接复用。
5、总结
Ollama 为我们提供了一条零成本、无限制、数据私有的本地大模型部署路径。无论是日常学习、代码辅助,还是处理敏感数据,它都能成为你可靠的工作伙伴。
从今天开始,告别 Token 焦虑,拥抱 AI 自由吧!
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)