提升GPU利用率:资源超分技术的原理、实践与落地
提升GPU利用率:资源超分技术的原理、实践与落地
在AI算力紧缺的当下,GPU资源利用率低下已成为企业技术负责人最头疼的问题之一。一张价值数万元的A100或H100,往往只被跑了一个小模型,平均利用率不足30%。如何让一张卡“物尽其用”?本文将系统解析资源层GPU超分技术的核心原理、工业实践与落地路径,为企业提供从理论到实施的完整参考。
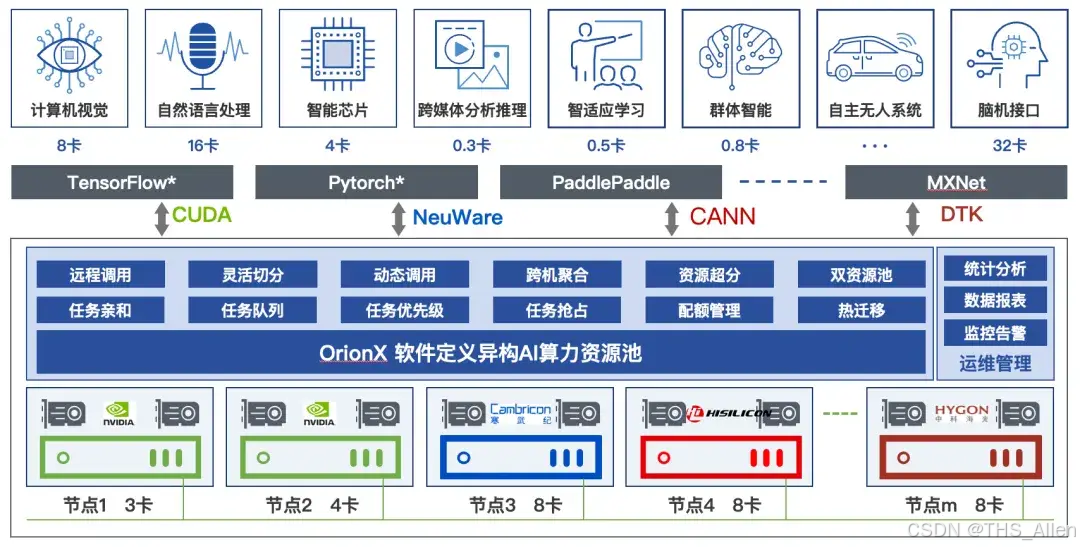
一、GPU利用率低下的症结在哪里?
1.1 典型场景:算力闲置的众生相
在云原生和AI推理的生产环境中,GPU利用率低下表现为几种典型形态:
- 小模型“占坑”:一个TTS模型或翻译模型只需要0.5G显存、10%算力,却独享整张卡
- 波峰波谷不均:在线推理服务白天高负载,夜间几乎闲置,算力被白白浪费
- 推理与训练混部困难:训练任务希望抢占资源,推理任务需要稳定SLA,两者难以共存
- 多卡部署的尴尬:微服务架构下每个服务独立占卡,卡数随服务数量线性增长
1.2 传统调度方案的局限性
| 方案 | 原理 | 问题 |
|---|---|---|
| K8s原生GPU调度 | 整卡分配,按“个数”调度 | 无法切分,小型任务浪费严重 |
| 多进程共享 | 多个进程同时使用同一张卡 | 无隔离,互相干扰,OOM风险高 |
| 时间片轮转 | 简单的时间分配 | 无法保证算力比例,QoS难保障 |
| 手动绑卡 | 人工将任务绑定到特定GPU | 运维成本高,无法弹性伸缩 |
1.3 GPU超分的核心价值
资源层GPU超分技术旨在解决上述问题,其核心价值可量化为:
- 利用率提升:从平均30%提升至70-80%
- 卡数节省:同等业务负载下,GPU卡数减少50%以上
- 成本降低:TCO(总拥有成本)显著下降,尤其在大规模集群中
二、资源层GPU超分技术体系
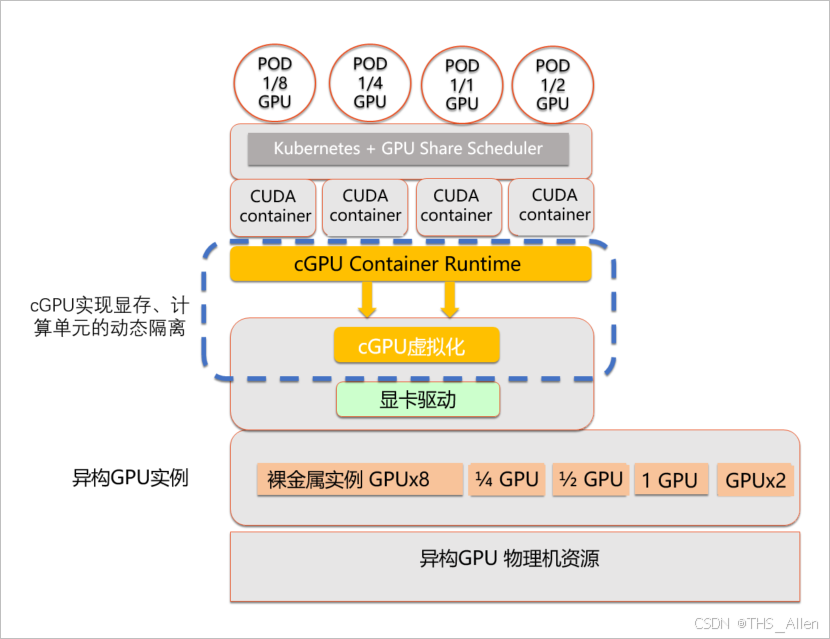
2.1 技术架构:在CUDA Runtime与Driver之间做文章
资源层超分的核心技术是在CUDA Runtime层与Driver层之间插入拦截层,对GPU资源进行“劫持”与“重分配”。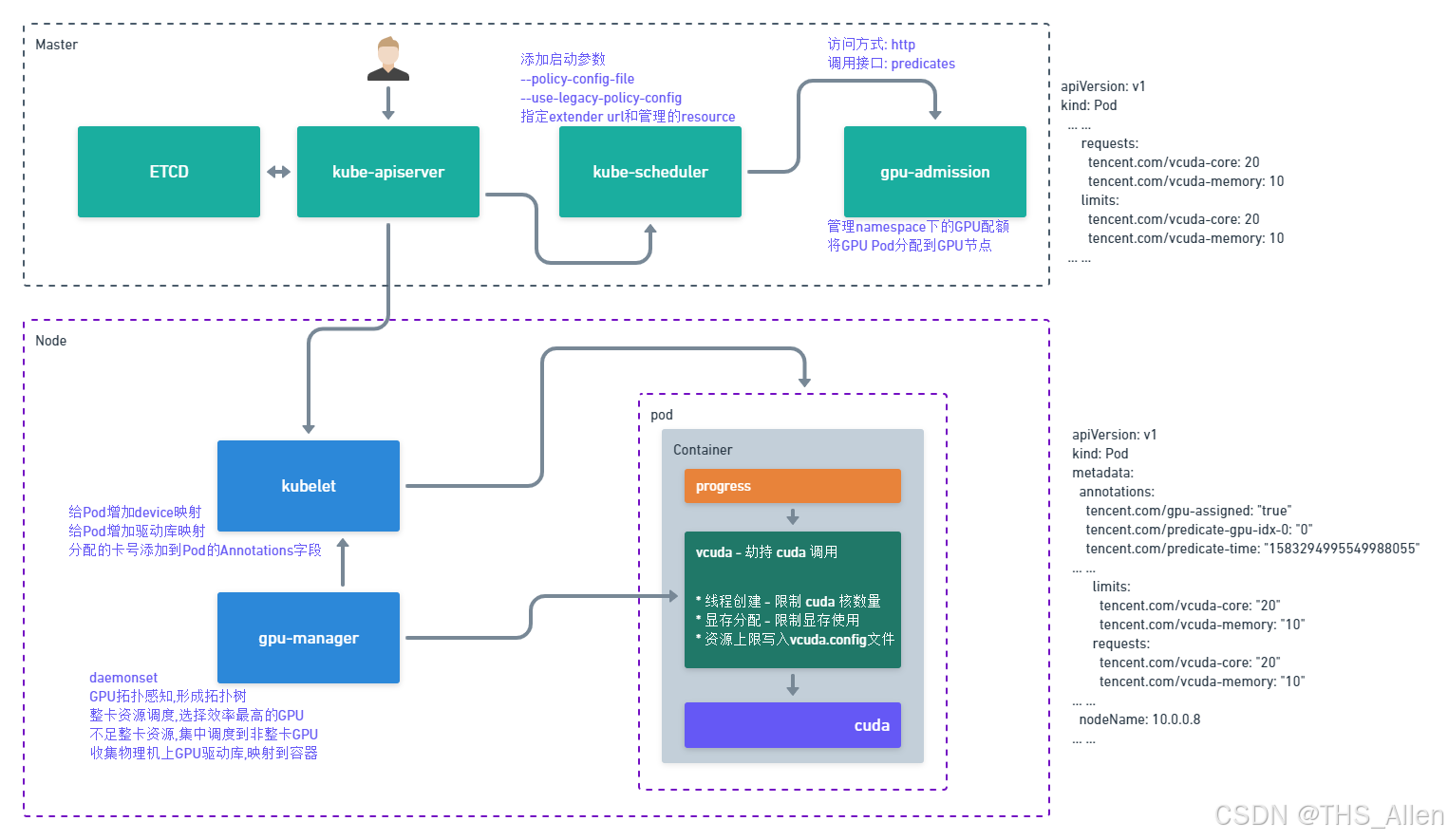
2.2 算力超分的两种实现路径
| 路径 | 原理 | 优势 | 局限 |
|---|---|---|---|
| 强算力限制 | 严格限制GPU时间片上限,确保每个任务不超过申请比例 | SLA有保障,高QPS场景稳定 | 空闲算力无法被其他任务借用 |
| 弱算力限制 | 允许任务“借用”空闲算力,争抢时按比例分配 | 利用率最大化,适合突发性任务 | 高负载时可能影响SLA |
实践中往往采用“弱限制+优先级队列”的混合模式:低优先级任务可借用空闲算力,但高优先级任务到来时立即抢占。
2.3 显存超分:统一内存与显存置换
显存超分的核心是利用CUDA Unified Memory特性,将GPU显存与系统内存统一编址,允许数据在两者之间按需交换。
技术原理:
- 应用程序申请显存时,超分层先分配虚拟地址空间
- 实际物理显存按需分配,超过物理显存的部分可“溢出”到系统内存
- 通过页面迁移机制,将常用数据保留在显存,冷数据换出到内存
应用效果:两个各需32GB显存的7B模型,可以部署在同一张24GB显存的卡上,通过显存置换保证服务运行。
2.4 优先级与QoS保障
生产环境中,不同任务对算力的敏感度不同,因此需要精细化调度:
| 优先级 | 适用任务 | 调度策略 |
|---|---|---|
| 高优先级 | 在线推理、实时服务 | 算力保障,可抢占低优先级任务 |
| 中优先级 | 离线推理、批处理 | 可用空闲算力,被抢占后可让出 |
| 低优先级 | 开发调试、训练任务 | 仅在资源空闲时运行,随时可被中断 |
关键机制:
- 时间片切分:将GPU计算时间切分为微秒级时间片,按优先级分配
- 算力保障:为高优先级任务预留最低算力比例(如50%)
- 抢占与恢复:被抢占的任务保存上下文,待资源释放后恢复
三、工业实践:主流超分方案对比
3.1 顺丰科技EffectiveGPU(EGPU)
EGPU是顺丰科技自研的GPU超分方案,已在生产环境大规模验证。
核心能力:
- 算力切分:支持1%粒度的算力分配
- 显存隔离:精确限制每个容器的显存上限
- 强弱算力模式:根据业务特征灵活选择
- 优先级调度:支持高优先级任务抢占
应用效果:
- GPU利用率从30%提升至70%以上
- 硬件成本降低超过50%
- 支撑TTS、OCR、翻译等数十个AI服务混部
3.2 腾讯vCUDA
腾讯云推出的vCUDA方案,已集成到腾讯云TKE容器服务中。
核心能力:
- 细粒度切分:支持1%算力、1MB显存粒度的切分
- 动态超分:允许任务突破申请上限,但受全局限额约束
- 跨卡共享:支持多个容器共享一张或多张GPU
使用方式(K8s资源定义示例):
resources:
limits:
tencent.com/vcuda-core: 30 # 30%算力
tencent.com/vcuda-memory: 4096 # 4GB显存
3.3 阿里云cGPU
阿里云cGPU方案已在ACK(阿里云容器服务)中广泛应用。
核心特点:
- 无侵入:用户无需修改应用代码
- 多租户隔离:显存和算力双重隔离
- 弹性超分:支持算力超卖,提高集群整体利用率
3.4 技术方案对比
| 方案 | 算力切分粒度 | 显存隔离 | 优先级调度 | 侵入性 | 适用场景 |
|---|---|---|---|---|---|
| EffectiveGPU | 1% | ✅ | ✅ | 低 | 大规模混部 |
| 腾讯vCUDA | 1% | ✅ | ✅ | 低 | 云原生场景 |
| 阿里云cGPU | 5% | ✅ | 部分 | 低 | 企业级混合部署 |
| NVIDIA MPS | 无 | ❌ | 有 | 中 | 多进程共享 |
| NVIDIA MIG | 固定切片 | ✅ | 无 | 低 | 硬件级隔离(仅部分卡支持) |
四、落地实践:从技术选型到生产部署
4.1 业务画像:哪些场景适合GPU超分?
| 场景 | 超分价值 | 注意事项 |
|---|---|---|
| 高并发小模型推理(TTS、OCR、翻译) | 极高 | 最适合混部的场景 |
| 低QPS大模型推理(7B/13B对话) | 高 | 适合显存超分 |
| 在线推理+离线训练混部 | 高 | 需配置优先级抢占 |
| 开发测试环境 | 中 | 共享资源,成本节约显著 |
| 单任务独占GPU | 低 | 无需超分 |
4.2 部署模式选择
| 模式 | 适用场景 | 说明 |
|---|---|---|
| 整卡独占 | 大模型训练、高SLA服务 | 最稳妥,但利用率低 |
| 固定切分 | 资源需求稳定的服务 | 如1/2卡推理服务 |
| 弹性超分 | 波峰波谷明显的服务 | 动态调整算力上限 |
| 混部超卖 | 多种服务混合部署 | 利用率最高,需精细调度 |
4.3 落地三步走
第一步:资源评估与画像
- 采集当前GPU使用率、显存占用、QPS等指标
- 识别适合混部的服务类型(小模型、低延迟要求)
- 评估超分后的容量与SLA风险
第二步:试点验证
- 选择非核心业务或测试环境进行试点
- 配置超分策略(算力比例、显存限制、优先级)
- 观察稳定性、性能、资源利用率变化
第三步:规模化推广
- 制定超分使用规范(申请流程、配额管理)
- 建立监控告警体系(利用率、争抢、OOM风险)
- 持续优化调度策略
4.4 关键监控指标
| 指标 | 说明 | 告警阈值建议 |
|---|---|---|
| GPU利用率 | 实际使用算力与上限比例 | 持续>90%需增加资源 |
| 显存占用 | 物理显存使用量 | >物理显存80%需关注 |
| 算力争抢次数 | 高优先级任务抢占次数 | 频繁抢占需调整配额 |
| 任务排队时间 | 等待GPU调度的时间 | >1秒需优化调度 |
| OOM事件 | 显存不足导致的失败 | 0容忍 |
五、未来趋势:从静态超分到智能调度
5.1 当前局限与挑战
- 模型感知缺失:当前超分层不感知模型类型,无法针对性优化
- 跨节点调度复杂:多卡任务与超分技术结合困难
- 调试诊断困难:超分后的性能问题难以定位
5.2 技术演进方向
1. 智能超分:基于历史负载预测,动态调整算力配额
2. 模型感知调度:识别模型类型(Transformer、CNN等),优化显存布局
3. 跨卡超分:单个任务可突破单卡限制,跨多卡分配资源
4. 与K8s调度器深度融合:超分能力成为K8s原生能力
5.3 与AI Agent的结合
资源超分技术正在与AI Agent场景深度融合:
- 智能体推理服务:多个Agent共享GPU,通过超分技术降低成本
- 弹性调度:Agent负载波动时,自动调整算力配额
- 任务优先级管理:核心Agent任务自动获得更高优先级
六、总结:让每一分算力都产生价值
GPU超分技术不是“魔法”,而是工程化调度能力。它通过精细化的算力切分、显存隔离和优先级调度,让一张GPU卡承载更多任务,从而大幅提升资源利用率。
对于企业而言,采用GPU超分技术可以实现:
- 成本直降:同等业务负载下GPU卡数减少50%以上
- 利用率跃升:从不足30%提升至70%以上
- 弹性增强:轻松应对业务波峰波谷
在AI算力成本高企的今天,让每一分算力都产生价值,不仅是技术追求,更是商业必然。无论是云原生环境的大规模混部,还是边缘场景的资源受限部署,GPU超分技术都正在成为标配。
未来,随着智能调度与模型感知能力的引入,GPU超分将从“静态切分”走向“动态优化”,让算力资源利用的每一份潜力都被充分释放。
参考资料
[1] 江山山. 突破传统方案瓶颈,EffectiveGPU如何实现GPU大幅降本? DBAplus, 2026.
[2] 顺丰科技. EffectiveGPU技术白皮书.
[3] 腾讯云. vCUDA产品文档.
[4] 阿里云. cGPU容器共享技术文档.
[5] NVIDIA. Multi-Process Service (MPS) Documentation.
[6] NVIDIA. Multi-Instance GPU (MIG) User Guide.
[7] CSDN博客. GPU的算力超分和显存扩容探索. 2021.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 38
38 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)