milvus整合langchain4j
1.基于docker安装环境
第一步:下载官方docker-compose.yml
wget https://mirrors.aliyun.com/milvus/milvus-standalone-docker-compose.yml -O docker-compose.yml
第二步:补充attu配置在service下
# 新增:Attu 可视化
attu:
container_name: attu
image: zilliz/attu:latest
environment:
- MILVUS_URL=standalone:19530 # 直接连接 Milvus 容器
ports:
- "8000:3000"
depends_on:
- standalone3. 启动 Milvus(后台)
sudo docker compose up -d
会自动启动 4 个容器:
- milvus-standalone:Milvus 主服务(端口
19530) - milvus-etcd:元数据存储
- milvus-minio:对象存储(数据文件)
- attu:milvus可视化工具
4. 检查状态
# 查看容器
docker compose ps出现以下状态即为成功:
PS E:\soft\dockerconfig> docker compose ps
STATUS PORTS
attu zilliz/attu:latest "docker-entrypoint.s…" attu 22 hours
ago Up 37 seconds 0.0.0.0:8000->3000/tcp, [::]:8000->3000/tcp
milvus-etcd quay.io/coreos/etcd:v3.5.5 "etcd -advertise-cli…" etcd 40 hours
ago Up 39 seconds (healthy) 2379-2380/tcp
milvus-minio minio/minio:RELEASE.2023-03-20T20-16-18Z "/usr/bin/docker-ent…" minio 40 hours
ago Up 39 seconds (healthy) 0.0.0.0:9000-9001->9000-9001/tcp, [::]:9000-9001->9000-9001/tcp
milvus-standalone milvusdb/milvus:v2.4.12 "/tini -- milvus run…" standalone 40 hours
ago Up 38 seconds (healthy) 0.0.0.0:9091->9091/tcp, [::]:9091->9091/tcp, 0.0.0.0:19530->19530/tcp, [::]:19
530->19530/tcp2.通过8000端口访问attu 配置collection
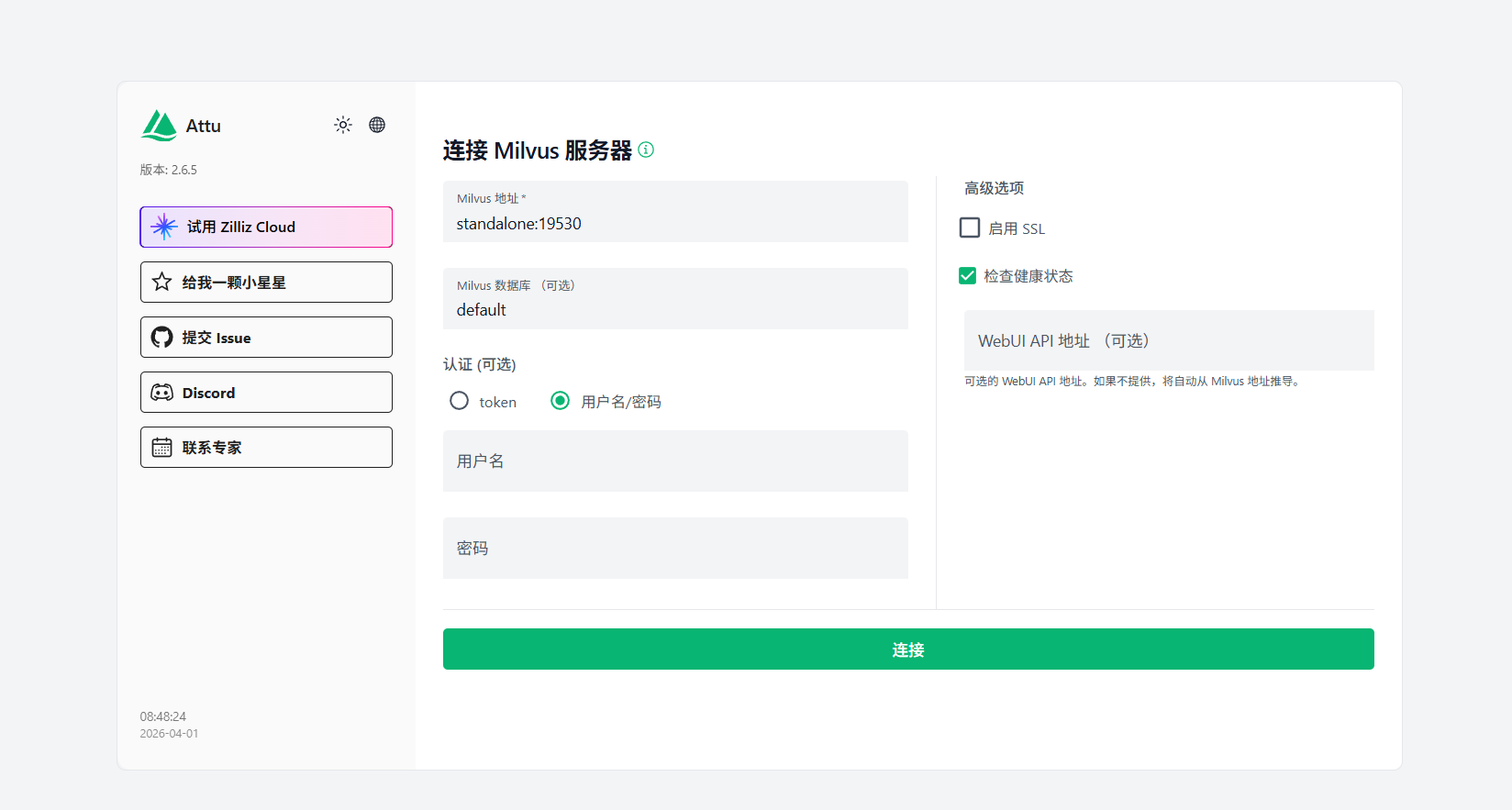
直接连接进入
milvus核心概念
1. Collection= 数据表
-
对应 MySQL 的 表
-
用来存储向量 + 结构化字段
-
必须先创建 Collection,才能插入数据、做检索
创建时必须指定:
- 字段名、字段类型
- 主键字段(唯一标识)
- 向量字段(必须指定维度 dim)
2. Field(字段)= 列
Collection 里的每一列叫 Field,支持 3 类:
-
主键字段 (Primary Key)
- 唯一标识一条数据
- 类型:INT64 / VARCHAR
-
向量字段 (Vector Field)
- 存储浮点数 / 二进制向量
- 必须指定维度 dim
- 一个 Collection 可以有多个向量字段
-
标量字段 (Scalar Field)
- 普通数据:整型、浮点、字符串、布尔、数组
-
用于过滤检索(where 条件)
3. Entity(实体)= 行
一条数据 = 一个 Entity对应 MySQL 的 一行记录包含:主键 + 向量 + 若干标量字段
4. Partition(分区)
- 对 Collection 做逻辑分区
- 作用:加速查询、按业务隔离数据
- 默认自带:
_default分区 - 场景示例:按年份 / 用户类型 / 地区分区
5. Index(索引)
向量必须创建索引才能检索!
- 不创建索引:只能暴力检索(慢)
- 创建索引:百万 / 千万级向量毫秒级查询
- 常用索引:FLAT、IVF_FLAT、IVF_SQ8、HNSW(高性能)
配置collection
进入创建collection,设置id,vector,text,metadata字段
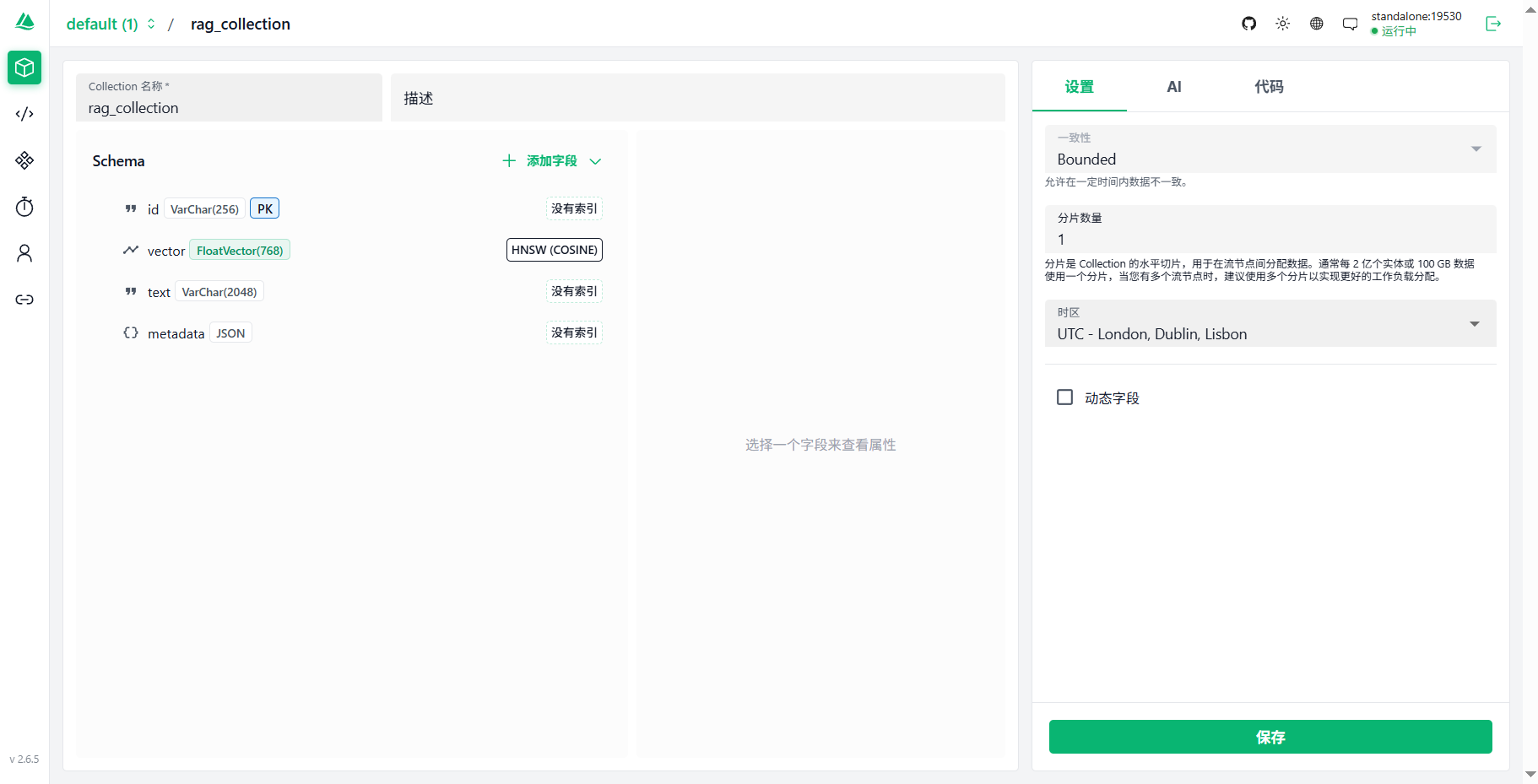
设置多少维度可以根据向量模型和具体需求设置。
https://milvus.io/docs/zh/hnsw.md
常用HNSW索引,以下是HNSW索引的配置参数,我们这边M设置16,efConstruction设置256即可
-
M:图中每个节点在层次结构的每个层级所能拥有的最大边数或连接数。M越高,图的密度就越大,搜索结果的召回率和准确率也就越高,因为有更多的路径可以探索,但同时也会消耗更多内存,并由于连接数的增加而减慢插入时间。如上图所示,M = 5表示 HNSW 图中的每个节点最多与 5 个其他节点直接相连。这就形成了一个中等密度的图结构,节点有多条路径到达其他节点。 -
efConstruction:索引构建过程中考虑的候选节点数量。efConstruction越高,图的质量越好,但需要更多时间来构建。
3.Langchain4j集成milvus
第一步:配置pom.xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.12.2-beta22</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-milvus</artifactId>
<version>1.12.2-beta22</version>
</dependency>第二步:配置向量化模型和milvus
#langchain4j
langchain4j:
open-ai:
embedding-model:
api-key: sk-
base-url: https:
model-name: embedding
dimensions: 768
milvus:
host: localhost
port: 19530
collection-name: rag_collection
dimension: 768 # OpenAI embedding 维度
第三步:配置bean
配置milvus客户端和EmbeddingStore
package com.zlj.ragproject.config;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.milvus.MilvusEmbeddingStore;
import io.milvus.client.MilvusServiceClient;
import io.milvus.param.ConnectParam;
import io.milvus.param.IndexType;
import io.milvus.param.MetricType;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConfigurationProperties(prefix = "langchain4j.milvus")
@Data
public class MilvusConfig {
private String host;
private Integer port;
private String collectionName;
private Integer dimension;
// 1. Milvus 客户端
@Bean
public MilvusServiceClient milvusClient() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(host)
.withPort(port)
.build();
return new MilvusServiceClient(connectParam);
}
// 2. LangChain4j 向量存储
@Bean
public EmbeddingStore<TextSegment> embeddingStore(MilvusServiceClient milvusClient) {
return MilvusEmbeddingStore.builder()
.milvusClient(milvusClient)
.collectionName(collectionName)
.dimension(dimension)
.indexType(IndexType.HNSW)
.metricType(MetricType.COSINE)
// 固定字段名(正常情况必须加,否则自动创建表会不兼容)
//不过以下都是默认会注入的字段可不加,如果字段值变了得加
// .idFieldName("id")
// .vectorFieldName("vector")
// .textFieldName("text")
// .metadataFieldName("metadata")
.build();
}
}配置向量化模型
package com.zlj.ragproject.config;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConfigurationProperties("langchain4j.open-ai.embedding-model")
@Data
public class EmbeddingConfig {
private String baseUrl;
private String apiKey;
private String modelName;
private Integer dimensions;
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel
.builder()
.apiKey(apiKey)
.baseUrl(baseUrl)
.modelName(modelName)
.dimensions(dimensions)
.build();
}
}第四步:创建RagService
调用EmbeddingStore的方法
package com.zlj.ragproject.service;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
@RequiredArgsConstructor
public class RagService {
// 向量化存储
private final EmbeddingStore<TextSegment> embeddingStore;
/**
* 存储 向量 + 文本
*/
public void save(Embedding embedding, TextSegment textSegment) {
embeddingStore.add(embedding, textSegment);
}
/**
* 批量存储
*/
public void saveBatch(List<Embedding> embeddings, List<TextSegment> segments) {
embeddingStore.addAll(embeddings, segments);
}
/**
* 向量搜索
*/
public EmbeddingSearchResult<TextSegment> search(EmbeddingSearchRequest request) {
return embeddingStore.search(request);
}
}第五步:测试向量化存储和查询
package com.zlj.ragproject;
import com.zlj.ragproject.model.enums.ConditionEnum;
import com.zlj.ragproject.model.enums.LogicEnum;
import com.zlj.ragproject.service.RagService;
import com.zlj.ragproject.utils.FilterCondition;
import com.zlj.ragproject.utils.MilvusFilterUtil;
import dev.langchain4j.data.document.Metadata;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.filter.Filter;
import dev.langchain4j.store.embedding.filter.comparison.IsEqualTo;
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import static com.zlj.ragproject.model.enums.ConditionEnum.IS_EQUAL_TO;
@SpringBootTest
class RagServiceTest {
@Resource
private RagService ragService;
@Resource
private EmbeddingModel embeddingModel;
@Test
void search() {
// 1. 文本
String text = "milvus测试";
// 2. 转向量
Response<Embedding> embed = embeddingModel.embed(text);
Map<String, String> map = new HashMap<>();
map.put("author","张三");
map.put("title","milvus");
map.put("count","20");
TextSegment textSegment = TextSegment.textSegment(text, Metadata.from(map));
// 3. 存入
ragService.save(embed.content(), textSegment);
// 4. 搜索
IsEqualTo filter = new IsEqualTo("author", "张三");
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder().filter(filter).queryEmbedding(embed.content()).build();
EmbeddingSearchResult<TextSegment> search = ragService.search(build);
System.out.println(search.matches().toString());
}
}就可以检索到以下内容,embedding向量默认不返回,不然数据太多了
[EmbeddingMatch { score = 1.0000000596046448, embedded = TextSegment { text = "milvus测试" metadata = {count=20, title=milvus, author=张三} }, embeddingId = 48b2fe4f-0d74-4414-97b1-1dfad9492da5, embedding = null }]
但是这个检索中对于filter的配置不太灵活,并且没有提供直接的构造,所以进行一下封装
第六步:封装Filter工具
条件枚举类ConditionEnum
package com.zlj.ragproject.model.enums;
import lombok.Getter;
/**
* LangChain4j Filter 条件枚举
* 对应 Filter 接口的所有比较运算符实现类,用于前端/参数传递时的条件映射
*/
@Getter
public enum ConditionEnum {
CONTAINS_STRING,
IS_EQUAL_TO,
IS_GREATER_THAN,
IS_GREATER_THAN_OR_EQUAL_TO,
IS_IN,
IS_LESS_THAN,
IS_LESS_THAN_OR_EQUAL_TO,
IS_NOT_EQUAL_TO,
IS_NOT_IN;
}逻辑枚举类LogicEnum
package com.zlj.ragproject.model.enums;
//逻辑枚举
public enum LogicEnum {
AND,
OR,
NOT
}过滤条件类FilterCondition
package com.zlj.ragproject.utils;
import com.zlj.ragproject.model.enums.ConditionEnum;
import com.zlj.ragproject.model.enums.LogicEnum;
import lombok.Data;
/***
*
* 过滤条件类
*/
@Data
public class FilterCondition {
// 字段
private String key;
// 值
private Object value;
// 比较条件
private ConditionEnum condition;
// 逻辑枚举,第一个可为null
private LogicEnum logic;
public FilterCondition() {
}
public FilterCondition(String key, Object value, ConditionEnum condition, LogicEnum logic) {
this.key = key;
this.value = value;
this.condition = condition;
this.logic = logic;
}
}milvus过滤条件工具类 MilvusConditionUtil
package com.zlj.ragproject.utils;
import com.zlj.ragproject.model.enums.LogicEnum;
import dev.langchain4j.store.embedding.filter.Filter;
import dev.langchain4j.store.embedding.filter.comparison.ContainsString;
import dev.langchain4j.store.embedding.filter.comparison.IsEqualTo;
import dev.langchain4j.store.embedding.filter.comparison.IsGreaterThan;
import dev.langchain4j.store.embedding.filter.comparison.IsGreaterThanOrEqualTo;
import dev.langchain4j.store.embedding.filter.comparison.IsIn;
import dev.langchain4j.store.embedding.filter.comparison.IsLessThan;
import dev.langchain4j.store.embedding.filter.comparison.IsLessThanOrEqualTo;
import dev.langchain4j.store.embedding.filter.comparison.IsNotEqualTo;
import dev.langchain4j.store.embedding.filter.comparison.IsNotIn;
import java.util.List;
public class MilvusFilterUtil {
/***
* @description 拼接过滤条件
* @param conditions
* @return dev.langchain4j.store.embedding.filter.Filter
*/
public static Filter buildFilter(List<FilterCondition> conditions) {
// Return null if conditions list is null or empty
if (conditions == null || conditions.isEmpty()) {
return null;
}
Filter finalFilter = null;
for (FilterCondition dto : conditions) {
// 1. 构建单个比较条件
Filter current = buildSingleFilter(dto);
// NOT 单独处理
if (dto.getLogic() == LogicEnum.NOT) {
current = Filter.not(current);
}
// 2. 组合 and / or
if (finalFilter == null) {
finalFilter = current; // 第一个条件
} else {
if (dto.getLogic() == LogicEnum.AND) {
finalFilter = finalFilter.and(current);
} else if (dto.getLogic() == LogicEnum.OR) {
finalFilter = finalFilter.or(current);
}
}
}
return finalFilter;
}
// 单个条件转换
private static Filter buildSingleFilter(FilterCondition condition) {
String key = condition.getKey();
Object value = condition.getValue();
Comparable<?> comparable = toComparable(value);
return switch (condition.getCondition()) {
case IS_EQUAL_TO -> new IsEqualTo(key, value);
case IS_NOT_EQUAL_TO -> new IsNotEqualTo(key, value);
case IS_GREATER_THAN -> new IsGreaterThan(key, comparable);
case IS_GREATER_THAN_OR_EQUAL_TO -> new IsGreaterThanOrEqualTo(key, comparable);
case IS_LESS_THAN -> new IsLessThan(key, comparable);
case IS_LESS_THAN_OR_EQUAL_TO -> new IsLessThanOrEqualTo(key, comparable);
case IS_IN -> new IsIn(key, (List<?>) value);
case IS_NOT_IN -> new IsNotIn(key, (List<?>) value);
case CONTAINS_STRING -> new ContainsString(key, (String) value);
default -> throw new RuntimeException("不支持的条件类型");
};
}
/**
* 自动把传的 value 转成 Comparable 类型
* 解决 gt/gte/lt/lte 类型报错问题
*/
public static Comparable<?> toComparable(Object value) {
if (value == null) {
throw new IllegalArgumentException("比较条件的值不能为 null");
}
// 如果已经是 Comparable 类型(数字、字符串、日期),直接返回
if (value instanceof Comparable<?>) {
return (Comparable<?>) value;
}
// 如果是字符串,尝试转数字
try {
return Long.parseLong(value.toString());
} catch (Exception ignored) {}
try {
return Double.parseDouble(value.toString());
} catch (Exception ignored) {}
// 都不行就返回字符串
return value.toString();
}
}第七步:使用filter工具类
查询数量大等于20或作者包含张的数据
@Test
void search() {
// 1. 文本
String text = "milvus测试";
// 2. 转向量
Response<Embedding> embed = embeddingModel.embed(text);
Map<String, String> map = new HashMap<>();
map.put("author","张三");
map.put("title","milvus");
map.put("count","20");
TextSegment textSegment = TextSegment.textSegment(text, Metadata.from(map));
// 3. 存入
// ragService.save(embed.content(), textSegment);
// 4. 搜索
FilterCondition count = new FilterCondition("count", "20", ConditionEnum.IS_GREATER_THAN_OR_EQUAL_TO, null);
FilterCondition filterCondition = new FilterCondition("author", "张", ConditionEnum.CONTAINS_STRING, LogicEnum.OR);
List<FilterCondition> count1 = List.of(count,filterCondition);
Filter filter = MilvusFilterUtil.buildFilter(count1);
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder().filter(filter).queryEmbedding(embed.content()).build();
EmbeddingSearchResult<TextSegment> search = ragService.search(build);
System.out.println(search.matches().toString());
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)