什么是Semantic Chunking?与固定长度切分有什么区别?
什么是Semantic Chunking?与固定长度切分有什么区别?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
一、从"断章取义"说起:为什么需要更聪明的文本切分
想象一下,你正在看一部精彩的电影,正要到高潮部分,突然画面卡住了,你只能看到前半段剧情。这时你问朋友"主角最后怎么样了",他却只告诉你"主角最后…",然后就没有下文了。这种感觉是不是特别难受?
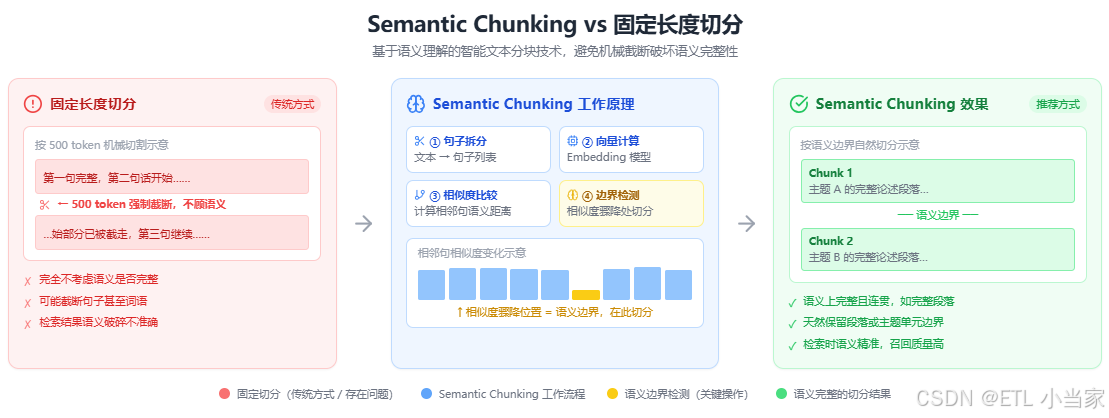
在AI的世界里,我们每天都在经历类似的事情。当我们把长文本喂给大语言模型时,必须先把文本切成一块一块的(这叫"chunking")。传统的做法是按固定长度切分——就像用尺子量着切豆腐,每500个token切一刀,不管这一刀下去是切在句子中间还是段落正当中。
这种"粗暴"的切分方式导致什么问题呢?举个例子:如果你在做一个问答系统,用户问"这个产品的退货政策是什么",结果退货政策的说明刚好被从中间切开了,前半段在chunk A,后半段在chunk B。当系统检索时,可能只找到前半段,给出的答案就是"30天无理由退货的前提条件包括…"——然后就没了!用户一脸懵逼:到底包括啥?
这就是为什么我们需要Semantic Chunking(语义切分)——一种能"读懂"文本的智能切分方法。
二、什么是Semantic Chunking
Semantic Chunking是基于语义理解进行文本分块的技术。它会分析文本的语义边界、主题转换和逻辑结构来决定在哪里切分。
简单来说,它就像一个经验丰富的编辑,在阅读文章时会自然地在段落之间、主题转换的地方停顿。具体来说,Semantic Chunking会:
- 把文本按句子拆分
- 计算每句话的语义向量(通过embedding模型)
- 比较相邻句子的语义相似度
- 当相似度出现明显下降时,就认为是一个语义单元的结束,在那里切分
这样切出来的每个chunk在语义上是完整且连贯的,就像完整的段落或主题单元。
与之相比,固定长度切分就简单粗暴得多。它完全不管语义是否完整,只是按照预设的字符数或token数机械地切分。比如你设定500个token一切,它就严格按这个数字来,可能会把一个完整的段落、甚至一句话拦腰斩断。

三、Semantic Chunking如何工作
让我们深入了解一下Semantic Chunking的技术实现。整个过程可以用一个生动的类比来理解:
想象你在读一本故事书,你会很自然地在章节之间、场景转换的地方停下来。Semantic Chunking做的就是类似的事情,只不过它是用数学方法来"感受"这些转换点。
核心实现步骤
第一步:句子拆分
先把长文本拆分成一个个句子。这看起来简单,但要处理好各种边界情况,比如缩写("Dr. Smith"中的点不是句子结束)、引号、括号等。
第二步:向量化
对每个句子,用embedding模型(比如BERT、sentence-transformers)将其转换成一个高维向量。这个向量的神奇之处在于:语义相近的句子在向量空间里的距离也近,讲不同主题的句子距离就远。
# 伪代码示意
sentences = split_text_into_sentences(long_text)
embeddings = [embedding_model.encode(s) for s in sentences]
第三步:相似度计算
计算相邻句子向量的余弦相似度。相似度接近1表示两句话说的几乎是同一件事,接近0表示完全不相干。
similarities = []
for i in range(len(embeddings) - 1):
sim = cosine_similarity(embeddings[i], embeddings[i + 1])
similarities.append(sim)
第四步:寻找切分点
设定一个阈值(比如0.6),当相邻句子的相似度低于这个阈值时,就认为这里发生了主题转换,应该切分。
split_points = [0] # 起始点
for i, sim in enumerate(similarities):
if sim < threshold: # 相似度低于阈值
split_points.append(i + 1) # 在这里切分
split_points.append(len(sentences)) # 结束点
第五步:构建chunks
根据切分点,把句子重新组合成完整的chunks。
chunks = []
for i in range(len(split_points) - 1):
start = split_points[i]
end = split_points[i + 1]
chunk = " ".join(sentences[start:end])
chunks.append(chunk)
一个具体例子
假设有4句话:
- A: “我们的退货政策非常简单明了”
- B: “在购买商品后的30天内,您可以无理由退货”
- C: “只要商品保持原包装,我们就可以全额退款”
- D: “关于配送,我们提供全国包邮服务”
计算相似度:
- sim(A, B) = 0.85(都在讲退货)
- sim(B, C) = 0.82(还在讲退货)
- sim(C, D) = 0.43(从退货跳到了配送)
看到C和D之间的相似度断崖式下跌了吗?这就是语义边界!Semantic Chunking会在这里切一刀,把前三句放在一起(完整的退货政策),把D单独放或者和后面的配送相关内容放一起。
优化策略:滑动窗口
实际应用中,单纯比较相邻两句可能判断不准。因为有时一句话只是短暂的过渡或举例,单句对比会误判为主题切换。
聪明的做法是使用滑动窗口:把连续3-5句话的向量取平均,然后比较相邻窗口的相似度。这样能平滑掉局部的语义波动,让切分点的判断更稳定。
# 滑动窗口策略
window_size = 3
window_embeddings = []
for i in range(len(embeddings) - window_size + 1):
window_vec = average_vectors(embeddings[i:i+window_size])
window_embeddings.append(window_vec)
# 然后比较相邻的window_embeddings
四、Semantic Chunking的优缺点
| 维度 | Semantic Chunking | 固定长度切分 |
|---|---|---|
| 语义完整性 | ✅ 优势:保持语义单元完整,不会切断主题 | ❌ 劣势:可能切断段落、句子,破坏语义连贯性 |
| 检索准确性 | ✅ 优势:RAG系统中召回的chunk内容更完整,答案质量高 | ❌ 劣势:关键信息可能被分割,影响检索效果 |
| 计算成本 | ❌ 劣势:需要embedding计算,预处理慢(O(n)复杂度的embedding推理) | ✅ 优势:纯字符串操作,极快(O(n)的字符串切割) |
| 实现复杂度 | ❌ 劣势:需要embedding模型、相似度计算、阈值调优等 | ✅ 优势:几行代码就能实现,简单直接 |
| chunk大小分布 | ⚠️ 挑战:chunk大小不均匀,可能出现过短或过长的块 | ✅ 优势:chunk大小完全可控,分布均匀 |
| 适用场景 | 知识库、问答系统、需要高准确性的场景 | 实时处理、文档频繁更新、成本敏感的场景 |
深度分析:为什么计算成本高?
Semantic Chunking的主要开销在embedding推理。假设一个文档有1000句话:
- 串行处理:如果用BERT-large这种模型,单句推理可能需要50毫秒,1000句就是50秒!
- 批量处理:把100句一起送进GPU,可能只需要1秒,吞吐量提升100倍
- 缓存策略:维护一个"句子→向量"的映射缓存,相同句子不用重复计算
相比之下,固定长度切分就是简单的字符串操作:
# 可能1秒都用不了
chunks = [text[i:i+500] for i in range(0, len(text), 500)]
但记住:这个成本是一次性的预处理开销。切分完后存储起来,检索时的查询性能不受影响。所以对于相对稳定的知识库,这个投入完全值得。
五、Semantic Chunking的实际应用与发展趋势
实际应用场景
1. RAG(检索增强生成)系统
这是Semantic Chunking最典型的应用场景。RAG的核心矛盾就是检索准确性——你必须让模型能找到完整的上下文。
案例:构建技术文档问答系统
- 用户提问:“如何配置Redis集群?”
- 固定切分的问题:配置步骤被切成三段,系统只召回第一步,用户只能看到"第一步:安装Redis",后面没了
- Semantic Chunking的解决方案:完整的配置流程被识别为一个语义单元,保存在同一个chunk里。检索召回后,答案自然完整:“1. 安装Redis 2. 修改配置文件 3. 启动集群 4. 验证节点状态”
2. 法律文档分析
在法律领域,语义完整性至关重要。一条法律条款被切断可能导致完全不同的解释。
案例:分析合同条款
- 固定切分的风险:“乙方应在收到货物后的7天内完成验收,如发现质量问题”——切到这里,后面的"应立即通知甲方并保留证据"到了下一个chunk,导致理解偏差
- Semantic Chunking的优势:完整的条款保存在一起,确保法律条文的完整性
3. 医疗问答系统
医疗领域容错率极低,不完整的医学信息可能带来严重后果。
案例:查询药物使用说明
- 用户提问:“这种降压药有什么注意事项?”
- 固定切分的问题:“肾功能不全者应减量使用"被切断,用户只看到"肾功能不全者”,不知道该怎么办
- Semantic Chunking的解决方案:完整的用药指导和注意事项被完整保留
选择策略:什么场景用哪种方法?
决定是否使用Semantic Chunking,要看三个关键维度:
| 维度 | 推荐Semantic Chunking | 推荐固定长度切分 |
|---|---|---|
| 文档特征 | 非结构化文本、主题变化频繁、需要语义连贯性 | 结构化文档(API文档、规范)、每条记录独立 |
| 更新频率 | 文档相对稳定,更新不频繁 | 文档频繁更新,需要快速处理 |
| 质量要求 | 高准确性场景(法律、医疗、技术问答) | 成本敏感、实时性要求高的场景 |
技术发展趋势
1. 混合策略的兴起
实际项目中,单一的切分策略很难适配所有场景。新的趋势是混合策略:
- 结构化部分用固定规则:标题、章节、列表项按规则切分
- 长文本用语义切分:正文内容用Semantic Chunking
- 递归切分:先按段落粗切,过长的段落再用语义方法细切
这样既保留了文档的逻辑结构,又保证了语义完整性,而且chunk大小分布更均匀。
2. 轻量级embedding模型
为了解决计算成本问题,研究者们开发了各种蒸馏后的轻量模型:
- DistilBERT:比BERT快60%,体积小40%,效果只下降3%
- MiniLM:在移动设备上也能流畅运行
- 领域专用模型:针对法律、医疗等领域训练的专用embedding模型
3. 多语言语义切分
随着全球化需求增长,多语言语义切分成为热点:
- 挑战:不同语言的句子长度、表达方式差异大
- 解决方案:使用LASER、LaBSE等多语言embedding模型,并在不同语言上分别调优阈值
当前局限性与改进方向
局限性:
- chunk大小不均匀:可能产生过短的chunk,在检索时被长chunk的噪声淹没
- 阈值设定困难:没有万能公式,需要在开发集上反复实验
- 领域适应性:通用embedding模型在专业领域可能表现不佳
改进方案:
- 最小长度约束:设置最小chunk长度(如100个token),过短的chunk与下一个合并
- 动态阈值:根据文档类型、领域特征动态调整相似度阈值
- 领域自适应:在专业语料上微调embedding模型
六、总结与思考
知识点总结
Semantic Chunking和固定长度切分的本质区别不在于技术实现,而在于设计哲学的不同:
- 固定长度切分:追求处理效率,像工厂流水线一样机械地切割文本
- Semantic Chunking:追求内容质量,像经验丰富的编辑一样理解文本的语义结构
在实际应用中,Semantic Chunking通过以下三步实现智能切分:
- 句子向量化 → 2. 相似度计算 → 3. 语义边界识别
虽然计算成本更高,但换来了语义完整性和检索准确性的显著提升,在RAG系统、法律、医疗等高要求场景中价值巨大。
深度思考
1. 技术选择的平衡艺术
选择哪种切分方法,本质上是在准确性、性能、成本这个不可能三角中寻找平衡点。没有银弹,只有最适合当前场景的trade-off。
这让我想到一个更深的问题:**我们追求技术进步,到底是为了什么?**是为了让机器更快地处理数据,还是为了让技术更好地服务于人类理解?Semantic Chunking的选择,某种程度上反映了我们对"质量"和"效率"的价值排序。
2. 预处理的哲学
Semantic Chunking的高成本引发了一个有趣的思考:预处理的投资回报率。在AI系统中,我们经常面临选择——是把计算成本花在预处理阶段,还是花在实时推理阶段?
Semantic Chunking告诉我们:对于相对稳定的数据,在预处理阶段投入更多计算资源,换取实时查询的质量提升,往往是更明智的选择。这种"先苦后甜"的策略,体现了工程实践中的长期主义思维。
3. 语义理解的边界
尽管Semantic Chunking很强大,但它仍然依赖于embedding模型的语义理解能力。这提醒我们:当前AI的"理解",本质上是基于统计模式的相似度计算,而非真正的认知理解。
当我们说"语义切分"时,我们实际上在说"基于向量空间相似度的统计切分"。认识到这一点,能帮助我们在赞叹技术进步的同时,保持必要的清醒和谦逊。
真正的技术成熟度,不在于盲目追求最新的方法,而在于深刻理解各种方法的适用边界,并在具体场景中做出最明智的选择。
希望这篇文章能帮助你理解Semantic Chunking的本质!如果你有任何问题或想法,欢迎在评论区交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)