CART决策树基本原理
文章目录
一、引言
决策树(Decision Tree)是一种基本的分类与回归方法。它通过对数据集中的特征进行递归划分,构建一棵树形结构来进行预测。决策树模型具有可读性强、分类速度快、无需特征缩放等优点,是机器学习中应用最广泛的模型之一。
CART(Classification and Regression Trees,分类与回归树)是由 Leo Breiman 等人于 1984 年提出的决策树算法,与 ID3、C4.5 等早期决策树算法相比,CART 具有以下核心特点:
| 特性 | 说明 |
|---|---|
| 二叉树结构 | 每次分裂只产生两个子节点,非多叉树 |
| 双任务支持 | 既支持分类任务,也支持回归任务 |
| 分裂准则 | 分类:基尼指数(Gini Index);回归:平方误差 |
| 特征复用 | 同一特征可在不同节点多次使用 |
| 剪枝策略 | 代价复杂度剪枝(Cost-Complexity Pruning) |
二、决策树模型
2.1 决策树的学习
决策树学习的本质是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有多个,也可能一个也没有。我们需要的是一个与训练数据矛盾较小的同时具有很好的泛化能力的决策树。
决策树学习用损失函数表示这一目标,其损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。
2.2 决策树的生成
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割的过程。
基本算法流程:
- 构建根节点:将所有训练数据都放在根节点
- 选择最优特征:选择一个最优特征,按照该特征将训练数据集分割成子集
- 递归构建子树:如果子集能够被基本正确分类,则构建叶节点;否则,对子集递归执行步骤 2-3
- 返回决策树:直到所有子集都能被基本正确分类,或者没有合适的特征为止
2.3 特征选择问题
特征选择在于选取对训练数据具有分类能力的特征。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。
典型的特征选择准则包括:
- 信息增益(ID3 算法使用)
- 信息增益比(C4.5 算法使用)
- 基尼指数(CART 分类树使用)
- 平方误差(CART 回归树使用)
三、CART 分类树
3.1 模型定义
输入:训练数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } D = \{(\mathbf{x}_1, y_1), (\mathbf{x}_2, y_2), \ldots, (\mathbf{x}_N, y_N)\} D={(x1,y1),(x2,y2),…,(xN,yN)},其中特征向量 x i ∈ X \mathbf{x}_i \in \mathcal{X} xi∈X,类别标签 y i ∈ Y y_i \in \mathcal{Y} yi∈Y。
输出:一棵二叉决策树 T T T。
CART 分类树是一棵二叉树,每个内部节点表示一个特征判断,每个叶节点表示一个类别。给定一个新样本,从根节点开始,根据各内部节点的判断条件,沿相应分支向下传递,直到到达某个叶节点,该叶节点的类别即为预测结果。
3.2 基尼不纯度
**基尼不纯度(Gini Impurity)**是 CART 分类树用于度量数据集纯度的指标。
对于包含 N N N 个样本的数据集 D D D,假设第 k k k 类样本有 N k N_k Nk 个,则第 k k k 类的概率估计为 p ^ k = N k / N \hat{p}_k = N_k / N p^k=Nk/N。数据集 D D D 的基尼不纯度定义为:
Gini ( D ) = ∑ k = 1 K p ^ k ( 1 − p ^ k ) = 1 − ∑ k = 1 K p ^ k 2 \text{Gini}(D) = \sum_{k=1}^{K} \hat{p}_k (1 - \hat{p}_k) = 1 - \sum_{k=1}^{K} \hat{p}_k^2 Gini(D)=k=1∑Kp^k(1−p^k)=1−k=1∑Kp^k2
直观解释:从数据集 D D D 中随机抽取一个样本,将其类别随机标记为 k k k 的概率为 p ^ k \hat{p}_k p^k,则分类错误的概率为 1 − p ^ k 1 - \hat{p}_k 1−p^k。基尼不纯度即为这一随机实验分类错误的期望概率。
性质:
| 数据分布 | 基尼不纯度值 | 说明 |
|---|---|---|
| 所有样本属于同一类 | Gini ( D ) = 0 \text{Gini}(D) = 0 Gini(D)=0 | 最纯状态 |
| 各类均匀分布 | Gini ( D ) = 1 − 1 K \text{Gini}(D) = 1 - \frac{1}{K} Gini(D)=1−K1 | 最不纯状态 |
| 二分类,比例 1:1 | Gini ( D ) = 0.5 \text{Gini}(D) = 0.5 Gini(D)=0.5 | 最大不纯度 |
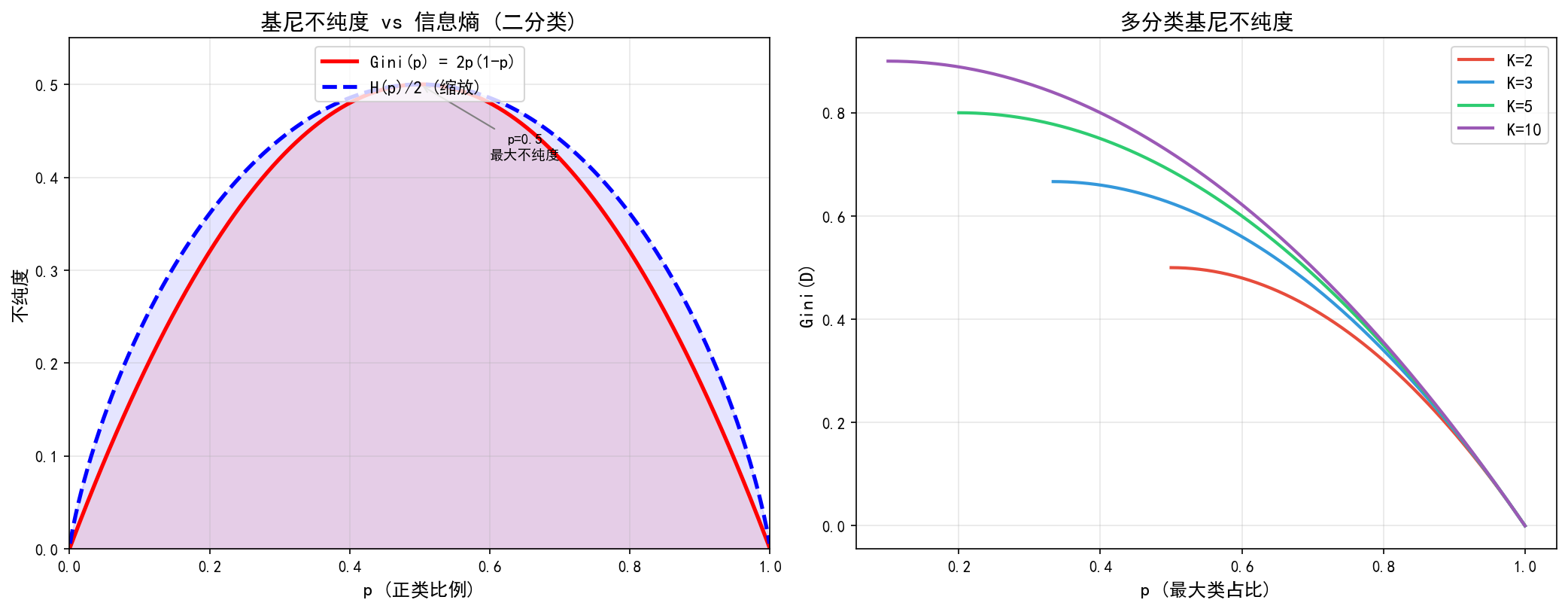
基尼不纯度与熵的比较:
基尼不纯度和信息熵都可以度量数据集的不确定性。对于二分类问题:
- 基尼不纯度: Gini ( p ) = 2 p ( 1 − p ) \text{Gini}(p) = 2p(1-p) Gini(p)=2p(1−p)
- 信息熵: H ( p ) = − p log p − ( 1 − p ) log ( 1 − p ) H(p) = -p\log p - (1-p)\log(1-p) H(p)=−plogp−(1−p)log(1−p)
两者的曲线形状相似,在 p = 0.5 p = 0.5 p=0.5 时达到最大值,在 p = 0 p = 0 p=0 或 p = 1 p = 1 p=1 时为 0。基尼不纯度的计算不涉及对数,因此计算开销略低。
3.3 基尼增益
**基尼增益(Gini Gain)**度量了分裂带来的不纯度减少量。
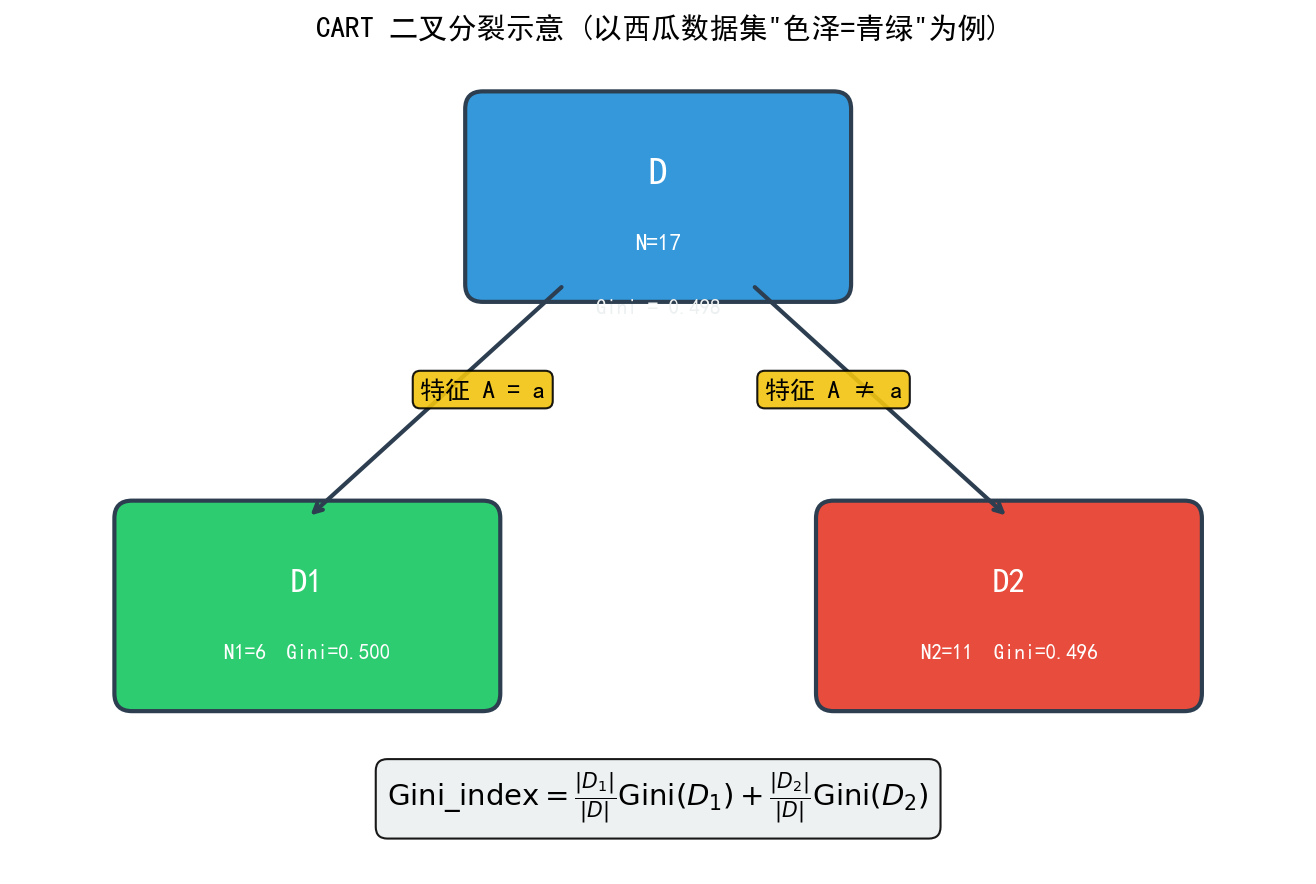
给定数据集 D D D,假设根据特征 A A A 的某个取值 a a a 将 D D D 分割为 D 1 D_1 D1 和 D 2 D_2 D2 两部分,其中 D 1 = { ( x , y ) ∈ D ∣ A ( x ) = a } D_1 = \{(\mathbf{x}, y) \in D \mid A(\mathbf{x}) = a\} D1={(x,y)∈D∣A(x)=a}, D 2 = D ∖ D 1 D_2 = D \setminus D_1 D2=D∖D1,则特征 A A A 对数据集 D D D 的基尼增益定义为:
Δ Gini ( D , A ) = Gini ( D ) − ∣ D 1 ∣ ∣ D ∣ Gini ( D 1 ) − ∣ D 2 ∣ ∣ D ∣ Gini ( D 2 ) \Delta \text{Gini}(D, A) = \text{Gini}(D) - \frac{|D_1|}{|D|} \text{Gini}(D_1) - \frac{|D_2|}{|D|} \text{Gini}(D_2) ΔGini(D,A)=Gini(D)−∣D∣∣D1∣Gini(D1)−∣D∣∣D2∣Gini(D2)
基尼增益 Δ Gini ( D , A ) \Delta \text{Gini}(D, A) ΔGini(D,A) 表示得知特征 A A A 的信息后,数据集 D D D 的不确定性减少的程度。基尼增益越大,说明使用特征 A A A 进行划分所获得的"纯度提升"越大。
3.4 基尼指数
在 CART 算法的原始文献中,**基尼指数(Gini Index)**指的是分裂后各子集基尼不纯度的加权平均:
Gini_index ( D , A ) = ∣ D 1 ∣ ∣ D ∣ Gini ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ Gini ( D 2 ) \text{Gini\_index}(D, A) = \frac{|D_1|}{|D|} \text{Gini}(D_1) + \frac{|D_2|}{|D|} \text{Gini}(D_2) Gini_index(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
三者关系:
基尼增益 = 基尼不纯度(父) − 基尼指数(子) \text{基尼增益} = \text{基尼不纯度(父)} - \text{基尼指数(子)} 基尼增益=基尼不纯度(父)−基尼指数(子)
由于父节点的基尼不纯度是常数,最小化基尼指数等价于最大化基尼增益。
3.5 最优特征选择
CART 分类树在每一步递归中,选择使基尼指数最小的特征作为划分特征。
对于数据集 D D D 的当前节点,遍历所有特征 A A A 和所有可能的切分点 a a a,计算基尼指数 Gini_index ( D , A , a ) \text{Gini\_index}(D, A, a) Gini_index(D,A,a),选择使该值最小的 ( A ∗ , a ∗ ) (A^*, a^*) (A∗,a∗) 作为最优划分:
( A ∗ , a ∗ ) = arg min A , a Gini_index ( D , A , a ) (A^*, a^*) = \underset{A, a}{\arg\min} \; \text{Gini\_index}(D, A, a) (A∗,a∗)=A,aargminGini_index(D,A,a)
离散特征的处理:对于取值集合为 { a 1 , a 2 , … , a L } \{a_1, a_2, \ldots, a_L\} {a1,a2,…,aL} 的离散特征 A A A,CART 枚举所有将其取值划分为两个非空子集的方式(共 2 L − 1 − 1 2^{L-1} - 1 2L−1−1 种),对每种划分计算基尼指数,选择基尼指数最小的划分方案。
连续特征的处理:对于连续特征 A A A,假设其在 D D D 上有 n n n 个不同的取值 { a 1 , a 2 , … , a n } \{a_1, a_2, \ldots, a_n\} {a1,a2,…,an}(已排序),则候选切分点为相邻取值的中点:
{ a i + a i + 1 2 ∣ 1 ≤ i ≤ n − 1 } \left\{ \frac{a_i + a_{i+1}}{2} \mid 1 \leq i \leq n-1 \right\} {2ai+ai+1∣1≤i≤n−1}
遍历所有候选切分点,选择使基尼指数最小的切分点。
3.6 CART 分类树生成算法
算法 3.1:CART 分类树生成算法
输入:训练数据集 D D D,停止条件参数(最大深度 d max d_{\max} dmax、最小样本数 N min N_{\min} Nmin、最小基尼增益 ϵ \epsilon ϵ)
输出:CART 分类树 T T T
- 若 D D D 中所有实例属于同一类 C k C_k Ck,则 T T T 为单节点树,类标记为 C k C_k Ck,返回 T T T
- 若 ∣ D ∣ < N min |D| < N_{\min} ∣D∣<Nmin 或当前深度 ≥ d max \geq d_{\max} ≥dmax,则 T T T 为单节点树,类标记为 D D D 中样本数最多的类,返回 T T T
- 否则,按如下步骤计算:
- 对每个特征 A A A,对其每个可能取值 a a a,根据 A = a A = a A=a 将 D D D 分割为 D 1 D_1 D1 和 D 2 D_2 D2,计算基尼指数 Gini_index ( D , A , a ) \text{Gini\_index}(D, A, a) Gini_index(D,A,a)
- 选择使基尼指数最小的特征 A ∗ A^* A∗ 及其切分点 a ∗ a^* a∗: ( A ∗ , a ∗ ) = arg min A , a Gini_index ( D , A , a ) (A^*, a^*) = \arg\min_{A, a} \text{Gini\_index}(D, A, a) (A∗,a∗)=argminA,aGini_index(D,A,a)
- 计算基尼增益 Δ Gini ( D , A ∗ ) = Gini ( D ) − Gini_index ( D , A ∗ , a ∗ ) \Delta \text{Gini}(D, A^*) = \text{Gini}(D) - \text{Gini\_index}(D, A^*, a^*) ΔGini(D,A∗)=Gini(D)−Gini_index(D,A∗,a∗)
- 若 Δ Gini ( D , A ∗ ) < ϵ \Delta \text{Gini}(D, A^*) < \epsilon ΔGini(D,A∗)<ϵ,则 T T T 为单节点树,类标记为 D D D 中样本数最多的类,返回 T T T
- 依最优切分点 a ∗ a^* a∗ 分割数据集为 D 1 D_1 D1 和 D 2 D_2 D2,分别对 D 1 D_1 D1 和 D 2 D_2 D2 递归调用步骤 1-4,得到子树 T 1 T_1 T1、 T 2 T_2 T2
- 返回树 T T T,其根节点的划分特征为 A ∗ A^* A∗,切分点为 a ∗ a^* a∗,左子树为 T 1 T_1 T1,右子树为 T 2 T_2 T2
3.7 数值示例:西瓜数据集
以下使用周志华《机器学习》中的西瓜数据集 3.0 演示 CART 分类树的构建过程。
数据集(17 个样本,9 个特征,2 类别):
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
| 6 | 青绿 | 稍蜷 | 沉闷 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 糊稍 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 糊稍 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 糊稍 | 稍凹 | 硬滑 | 0.639 | 0.161 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 糊稍 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.36 | 0.37 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 糊稍 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
第一步:计算根节点的基尼不纯度
好瓜 8 个,坏瓜 9 个,共 17 个样本。
Gini ( D ) = 1 − ( 8 17 ) 2 − ( 9 17 ) 2 = 1 − 0.2216 − 0.2803 = 0.498 \text{Gini}(D) = 1 - \left(\frac{8}{17}\right)^2 - \left(\frac{9}{17}\right)^2 = 1 - 0.2216 - 0.2803 = 0.498 Gini(D)=1−(178)2−(179)2=1−0.2216−0.2803=0.498
第二步:以"色泽"为例计算基尼指数
色泽取值:{青绿(6), 乌黑(6), 浅白(5)}
所有二分方案:
- {青绿}|{乌黑,浅白}
- {乌黑}|{青绿,浅白}
- {浅白}|{青绿,乌黑}
计算方案 {青绿}|{乌黑,浅白}:
- D 1 D_1 D1(青绿):6 个样本,3 好 3 坏
- Gini ( D 1 ) = 1 − ( 3 / 6 ) 2 − ( 3 / 6 ) 2 = 0.5 \text{Gini}(D_1) = 1 - (3/6)^2 - (3/6)^2 = 0.5 Gini(D1)=1−(3/6)2−(3/6)2=0.5
- D 2 D_2 D2(乌黑,浅白):11 个样本,5 好 6 坏
- Gini ( D 2 ) = 1 − ( 5 / 11 ) 2 − ( 6 / 11 ) 2 = 0.496 \text{Gini}(D_2) = 1 - (5/11)^2 - (6/11)^2 = 0.496 Gini(D2)=1−(5/11)2−(6/11)2=0.496
- Gini_index = 6 17 × 0.5 + 11 17 × 0.496 = 0.497 \text{Gini\_index} = \frac{6}{17} \times 0.5 + \frac{11}{17} \times 0.496 = 0.497 Gini_index=176×0.5+1711×0.496=0.497
类似地计算其他方案,最终选择基尼指数最小的划分。
第三步:选择最优划分特征
遍历所有离散特征(色泽、根蒂、敲声、纹理、脐部、触感)的所有二分方案,以及连续特征(密度、含糖率)的所有候选切分点,选择使基尼指数最小的 ( A ∗ , a ∗ ) (A^*, a^*) (A∗,a∗) 作为根节点的划分依据。
四、CART 回归树
4.1 模型定义
输入:训练数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } D = \{(\mathbf{x}_1, y_1), (\mathbf{x}_2, y_2), \ldots, (\mathbf{x}_N, y_N)\} D={(x1,y1),(x2,y2),…,(xN,yN)},其中特征向量 x i ∈ X ⊆ R p \mathbf{x}_i \in \mathcal{X} \subseteq \mathbb{R}^p xi∈X⊆Rp,输出 y i ∈ R y_i \in \mathbb{R} yi∈R 为连续值。
输出:一棵二叉回归树 T T T。
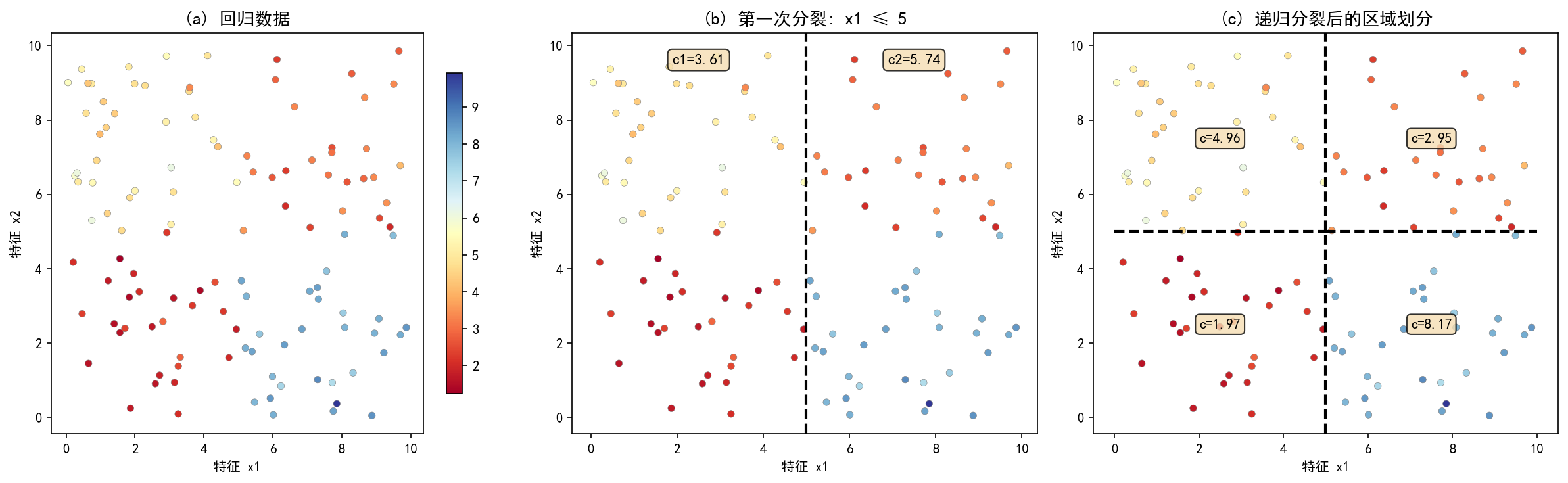
CART 回归树假设输出 y y y 与输入特征之间的关系可以用一棵二叉树来近似。树的每个叶节点对应一个常数值(该节点训练样本输出的均值),每个内部节点对应一个特征判断。
4.2 平方误差准则
优化目标:将输入空间 X \mathcal{X} X 划分为 M M M 个互不相交的区域 R 1 , R 2 , … , R M R_1, R_2, \ldots, R_M R1,R2,…,RM,在每个区域上确定输出的常量值 c m c_m cm,使得平方误差最小:
min R m , c m ∑ m = 1 M ∑ x i ∈ R m ( y i − c m ) 2 \min_{R_m, c_m} \sum_{m=1}^{M} \sum_{\mathbf{x}_i \in R_m} (y_i - c_m)^2 Rm,cmminm=1∑Mxi∈Rm∑(yi−cm)2
最优常数值:当区域的划分 R m R_m Rm 确定后,最优的 c m c_m cm 是该区域内所有样本输出的均值:
c ^ m = 1 N m ∑ x i ∈ R m y i \hat{c}_m = \frac{1}{N_m} \sum_{\mathbf{x}_i \in R_m} y_i c^m=Nm1xi∈Rm∑yi
其中 N m N_m Nm 是区域 R m R_m Rm 中的样本数。
区域的不纯度:用平方误差度量区域 R m R_m Rm 的不纯度:
SSE ( R m ) = ∑ x i ∈ R m ( y i − c ^ m ) 2 \text{SSE}(R_m) = \sum_{\mathbf{x}_i \in R_m} (y_i - \hat{c}_m)^2 SSE(Rm)=xi∈Rm∑(yi−c^m)2
4.3 最优划分的选择
启发式算法:采用贪心策略,递归地将输入空间划分为两个子区域,并确定每个子区域的输出值。
对于当前节点对应的区域 R R R 和数据集 D R = { ( x i , y i ) ∣ x i ∈ R } D_R = \{(\mathbf{x}_i, y_i) \mid \mathbf{x}_i \in R\} DR={(xi,yi)∣xi∈R},选择最优切分变量 j j j 和切分点 s s s,求解:
min j , s [ min c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + min c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] \min_{j, s} \left[ \min_{c_1} \sum_{\mathbf{x}_i \in R_1(j,s)} (y_i - c_1)^2 + \min_{c_2} \sum_{\mathbf{x}_i \in R_2(j,s)} (y_i - c_2)^2 \right] j,smin c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2
其中 R 1 ( j , s ) = { x ∣ x ( j ) ≤ s } R_1(j,s) = \{\mathbf{x} \mid x^{(j)} \leq s\} R1(j,s)={x∣x(j)≤s}, R 2 ( j , s ) = { x ∣ x ( j ) > s } R_2(j,s) = \{\mathbf{x} \mid x^{(j)} > s\} R2(j,s)={x∣x(j)>s}。
求解过程:
- 遍历所有输入变量 j = 1 , 2 , … , p j = 1, 2, \ldots, p j=1,2,…,p
- 对于固定切分变量 j j j,遍历其所有候选切分点 s s s(连续特征取相邻值中点)
- 对每个 ( j , s ) (j, s) (j,s),计算:
- R 1 ( j , s ) R_1(j,s) R1(j,s) 中样本的均值 c ^ 1 \hat{c}_1 c^1 和平方误差 SSE ( R 1 ) \text{SSE}(R_1) SSE(R1)
- R 2 ( j , s ) R_2(j,s) R2(j,s) 中样本的均值 c ^ 2 \hat{c}_2 c^2 和平方误差 SSE ( R 2 ) \text{SSE}(R_2) SSE(R2)
- 总平方误差 SSE ( j , s ) = SSE ( R 1 ) + SSE ( R 2 ) \text{SSE}(j,s) = \text{SSE}(R_1) + \text{SSE}(R_2) SSE(j,s)=SSE(R1)+SSE(R2)
- 选择使 SSE ( j , s ) \text{SSE}(j,s) SSE(j,s) 最小的 ( j ∗ , s ∗ ) (j^*, s^*) (j∗,s∗) 作为最优划分
4.4 CART 回归树生成算法
算法 4.1:CART 回归树生成算法
输入:训练数据集 D D D,停止条件参数
输出:CART 回归树 T T T
- 若 D D D 中所有样本的输出值相同,或 ∣ D ∣ < N min |D| < N_{\min} ∣D∣<Nmin,或达到最大深度,则 T T T 为单节点树,输出值为 D D D 中样本输出的均值,返回 T T T
- 否则:
- 遍历所有特征 j j j 和所有候选切分点 s s s
- 计算划分后的总平方误差 SSE ( j , s ) \text{SSE}(j,s) SSE(j,s)
- 选择使 SSE ( j , s ) \text{SSE}(j,s) SSE(j,s) 最小的 ( j ∗ , s ∗ ) (j^*, s^*) (j∗,s∗)
- 若最优划分的误差减少量小于阈值 ϵ \epsilon ϵ,则 T T T 为单节点树,返回 T T T
- 依最优切分点 s ∗ s^* s∗ 分割数据集为 D 1 D_1 D1 和 D 2 D_2 D2,分别对 D 1 D_1 D1 和 D 2 D_2 D2 递归调用步骤 1-3,得到子树 T 1 T_1 T1、 T 2 T_2 T2
- 返回树 T T T,其根节点的划分特征为 j ∗ j^* j∗,切分点为 s ∗ s^* s∗,左子树为 T 1 T_1 T1,右子树为 T 2 T_2 T2
4.5 回归树与分类树的对比
| 对比项 | 分类树 | 回归树 |
|---|---|---|
| 输出类型 | 离散类别 | 连续值 |
| 不纯度度量 | 基尼不纯度 | 平方误差(SSE) |
| 叶节点输出 | 多数类别 | 样本均值 |
| 分裂准则 | 最小化基尼指数 | 最小化平方误差 |
| 剪枝准则 | 误分类率 | 平方误差 |
五、决策树剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。
解决过拟合的方法是考虑决策树的复杂度,对已生成的树进行简化,称为剪枝(Pruning)。
5.1 预剪枝(Pre-pruning)
预剪枝是在决策树生成过程中提前停止树的增长。
停止条件:
- 节点纯度达标:节点中所有样本属于同一类别(分类)或输出值相同(回归)
- 样本数不足:节点中样本数小于预设阈值 N min N_{\min} Nmin
- 深度限制:树的深度达到预设上限 d max d_{\max} dmax
- 增益不足:分裂带来的基尼增益(或误差减少量)小于阈值 ϵ \epsilon ϵ
- 信息不足:划分后的某个子集样本数为 0
优点:
- 降低过拟合风险
- 显著减少训练时间和测试时间
- 降低模型复杂度
缺点:
- "贪心"本质,可能导致欠拟合
- 当前划分虽不能提升性能,但后续的划分可能显著提升性能
预剪枝 vs 后剪枝:
| 对比项 | 预剪枝 | 后剪枝 |
|---|---|---|
| 剪枝时机 | 构建过程中 | 构建完成后 |
| 计算开销 | 低 | 高(需要构建完整树) |
| 过拟合风险 | 较高 | 较低 |
| 欠拟合风险 | 较高 | 较低 |
| 泛化能力 | 一般 | 通常更好 |
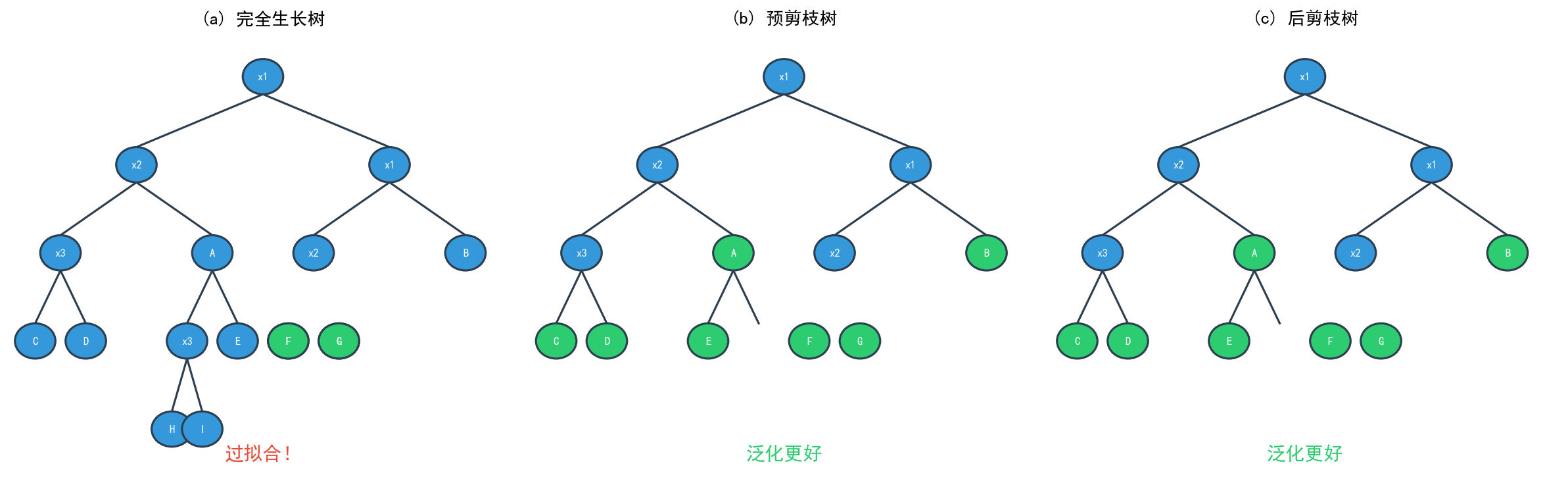
5.2 后剪枝:代价复杂度剪枝(CCP)
5.2.1 基本思想
后剪枝是先从训练集生成一棵完整的树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来泛化性能提升,则将该子树替换为叶节点。
CART 采用代价复杂度剪枝(Cost-Complexity Pruning, CCP),通过引入正则化参数 α \alpha α 在模型的拟合能力和复杂度之间取得平衡。
5.2.2 代价复杂度准则
对于一棵树 T T T,定义其代价复杂度为:
R α ( T ) = R ( T ) + α ∣ T ~ ∣ R_\alpha(T) = R(T) + \alpha |\tilde{T}| Rα(T)=R(T)+α∣T~∣
其中:
- R ( T ) R(T) R(T) 是树 T T T 在训练集上的经验风险(分类:误分类率;回归:均方误差)
- ∣ T ~ ∣ |\tilde{T}| ∣T~∣ 是树 T T T 的叶节点数,表示模型复杂度
- α ≥ 0 \alpha \geq 0 α≥0 是复杂度参数,控制对模型复杂度的惩罚力度
参数 α \alpha α 的作用:
- α = 0 \alpha = 0 α=0:只考虑拟合能力,得到完整树 T 0 T_0 T0
- α → ∞ \alpha \to \infty α→∞:只考虑复杂度,最优树退化为根节点
5.2.3 子树序列的生成
关键问题:对于固定的 α \alpha α,如何找到使 R α ( T ) R_\alpha(T) Rα(T) 最小的子树?
定理:对于固定的 α \alpha α,存在唯一的最小子树 T α T_\alpha Tα 使得 R α ( T α ) R_\alpha(T_\alpha) Rα(Tα) 最小。
最弱连接剪枝算法:
对于树 T T T 的内部节点 t t t,设以 t t t 为根的子树为 T t T_t Tt。定义剪去 T t T_t Tt 的临界参数:
g ( t ) = R ( t ) − R ( T t ) ∣ T ~ t ∣ − 1 g(t) = \frac{R(t) - R(T_t)}{|\tilde{T}_t| - 1} g(t)=∣T~t∣−1R(t)−R(Tt)
其中:
- R ( t ) R(t) R(t) 是将 t t t 视为叶节点时的经验风险
- R ( T t ) R(T_t) R(Tt) 是子树 T t T_t Tt 的经验风险
- ∣ T ~ t ∣ |\tilde{T}_t| ∣T~t∣ 是子树 T t T_t Tt 的叶节点数
算法步骤:
- 计算当前树所有内部节点的 g ( t ) g(t) g(t)
- 找到 g ( t ) g(t) g(t) 最小的节点 t ∗ t^* t∗(最弱连接)
- 将 T t ∗ T_{t^*} Tt∗ 剪枝为叶节点 t ∗ t^* t∗
- 设 α k + 1 = g ( t ∗ ) \alpha_{k+1} = g(t^*) αk+1=g(t∗),得到子树 T k + 1 T_{k+1} Tk+1
- 重复步骤 1-4,直到树只剩根节点
生成的子树序列:
通过上述过程,生成一个嵌套的子树序列:
T 0 ⊃ T 1 ⊃ T 2 ⊃ ⋯ ⊃ T m T_0 \supset T_1 \supset T_2 \supset \cdots \supset T_m T0⊃T1⊃T2⊃⋯⊃Tm
对应的复杂度参数序列:
0 = α 0 < α 1 < α 2 < ⋯ < α m < ∞ 0 = \alpha_0 < \alpha_1 < \alpha_2 < \cdots < \alpha_m < \infty 0=α0<α1<α2<⋯<αm<∞
对于任意 α ∈ [ α k , α k + 1 ) \alpha \in [\alpha_k, \alpha_{k+1}) α∈[αk,αk+1),使 R α ( T ) R_\alpha(T) Rα(T) 最小的子树恰好是 T k T_k Tk。
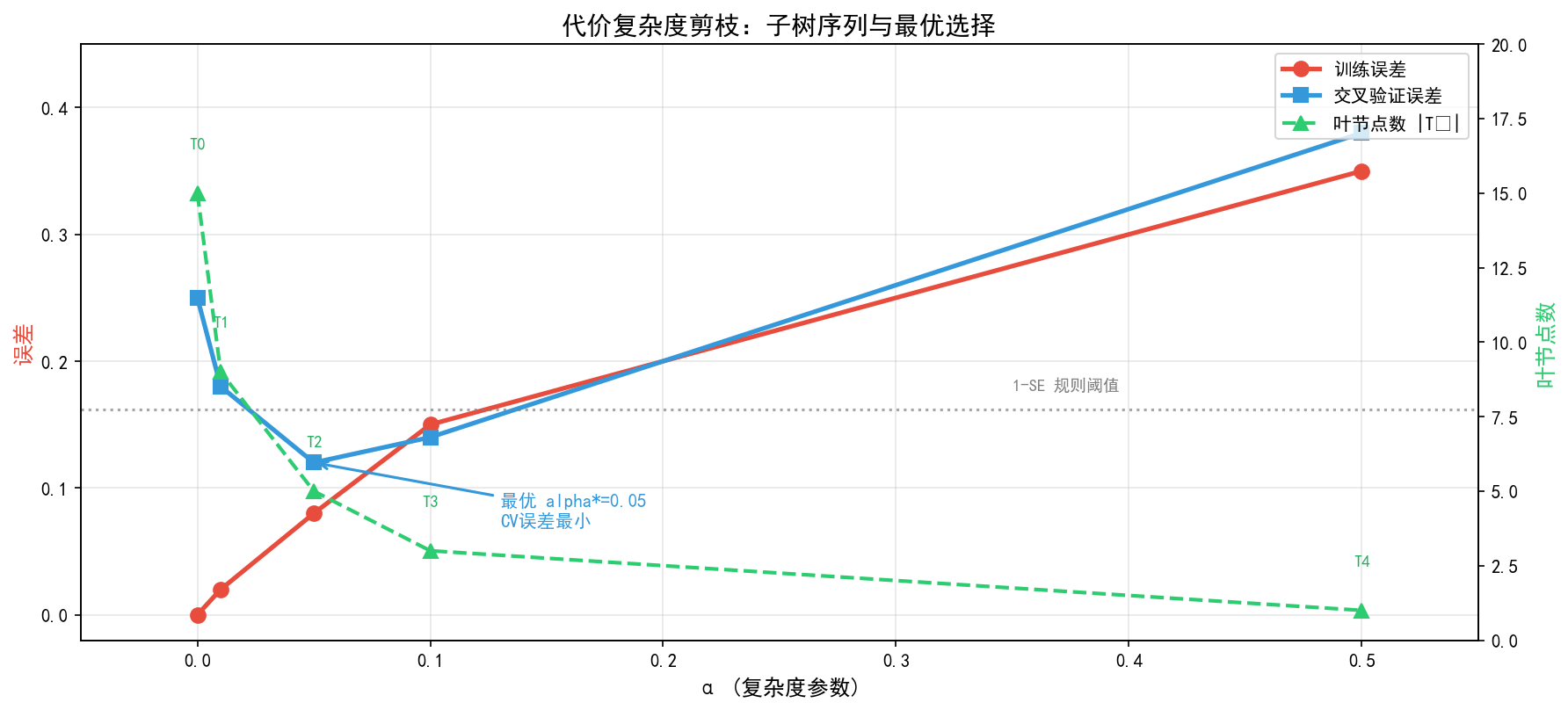
5.2.4 最优子树的选择
交叉验证选择:
- 划分数据:将训练数据划分为 V V V 个折叠
- 生成序列:对每个训练子集,生成子树序列 T 0 ( v ) , T 1 ( v ) , … T_0^{(v)}, T_1^{(v)}, \ldots T0(v),T1(v),…
- 计算误差:对每个 α k \alpha_k αk,用验证集计算交叉验证误差
- 选择最优:选择使交叉验证误差最小的 T k T_k Tk 作为最终模型
1-SE 规则:
选择满足以下条件的最简单的子树:
R C V ( T k ) ≤ R min C V + S E ( R min C V ) R^{CV}(T_k) \leq R^{CV}_{\min} + SE(R^{CV}_{\min}) RCV(Tk)≤RminCV+SE(RminCV)
其中 R min C V R^{CV}_{\min} RminCV 是最小交叉验证误差, S E SE SE 是标准误差。
5.3 剪枝的效果
剪枝能够有效缓解决策树的过拟合问题:
- 预剪枝:通过"早停"限制树的生长,简单高效但可能欠拟合
- 后剪枝:通过生成子树序列并选择最优子树,通常能获得更好的泛化性能
剪枝能够有效缓解决策树的过拟合问题:
- 预剪枝:通过"早停"限制树的生长,简单高效但可能欠拟合
- 后剪枝:通过生成子树序列并选择最优子树,通常能获得更好的泛化性能
六、CART 与 ID3、C4.5 的比较
| 特性 | ID3 | C4.5 | CART |
|---|---|---|---|
| 提出者 | Quinlan (1986) | Quinlan (1993) | Breiman et al. (1984) |
| 树结构 | 多叉树 | 多叉树 | 二叉树 |
| 分裂准则 | 信息增益 | 信息增益比 | 基尼指数 / 平方误差 |
| 支持任务 | 分类 | 分类 | 分类 + 回归 |
| 特征类型 | 离散 | 离散 + 连续 | 离散 + 连续 |
| 缺失值 | 不支持 | 支持 | 支持(代理分裂) |
| 剪枝 | 无 | 悲观误差剪枝 | 代价复杂度剪枝 |
| 特征复用 | 否 | 否 | 是 |
6.1 信息增益与基尼指数的比较
信息增益(ID3/C4.5 使用):
- 基于信息熵,有明确的概率解释
- 对可取值数目较多的属性有所偏好
- C4.5 使用信息增益比进行校正
基尼指数(CART 分类树使用):
- 计算简单,无需对数运算
- 同样是度量数据不纯度的有效指标
- 与信息增益在效果上相近
6.2 多叉树与二叉树的比较
多叉树(ID3/C4.5):
- 每个节点根据特征的每个取值产生一个分支
- 对于离散特征,分支数等于特征取值数
- 树可能较浅但较宽
二叉树(CART):
- 每个节点只产生两个分支(是/否)
- 对于多值离散特征,需要枚举二分方案
- 树可能较深但结构统一
- 优势:同一特征可多次使用,实现多路划分的等效效果
七、CART 决策树的优缺点
7.1 优点
-
模型可解释性强
- 决策树结构清晰,可直观展示决策规则
- 易于理解和解释,适合需要可解释性的场景
-
数据预处理简单
- 无需特征缩放(标准化/归一化)
- 自动处理特征选择,无需手动筛选
- 对缺失值有一定的处理能力
-
适用范围广
- 同时支持分类和回归任务
- 支持离散和连续特征
- 支持多输出预测
-
计算效率高
- 训练和预测的时间复杂度较低
- 预测时只需沿着树路径进行判断
- 适合大规模数据
-
非参数化方法
- 不对数据分布做假设
- 能够捕捉非线性关系
7.2 缺点
-
容易过拟合
- 单棵决策树容易学习到训练数据的噪声
- 需要通过剪枝或集成方法来控制
-
不稳定性
- 数据的微小变化可能导致完全不同的树结构
- 对样本分布敏感
-
贪心算法的局限
- 每次选择局部最优分裂,不一定是全局最优
- 无法回溯修改早期决策
-
偏向多值特征
- 取值较多的特征更容易被选中
- (基尼指数相比信息增益,这一偏差较小)
-
难以表达复杂关系
- 难以拟合线性关系(需要大量分段)
- 对异或等复杂逻辑表达能力有限
八、决策树在集成学习中的应用
决策树因其简单高效的特点,成为集成学习中最常用的基学习器。
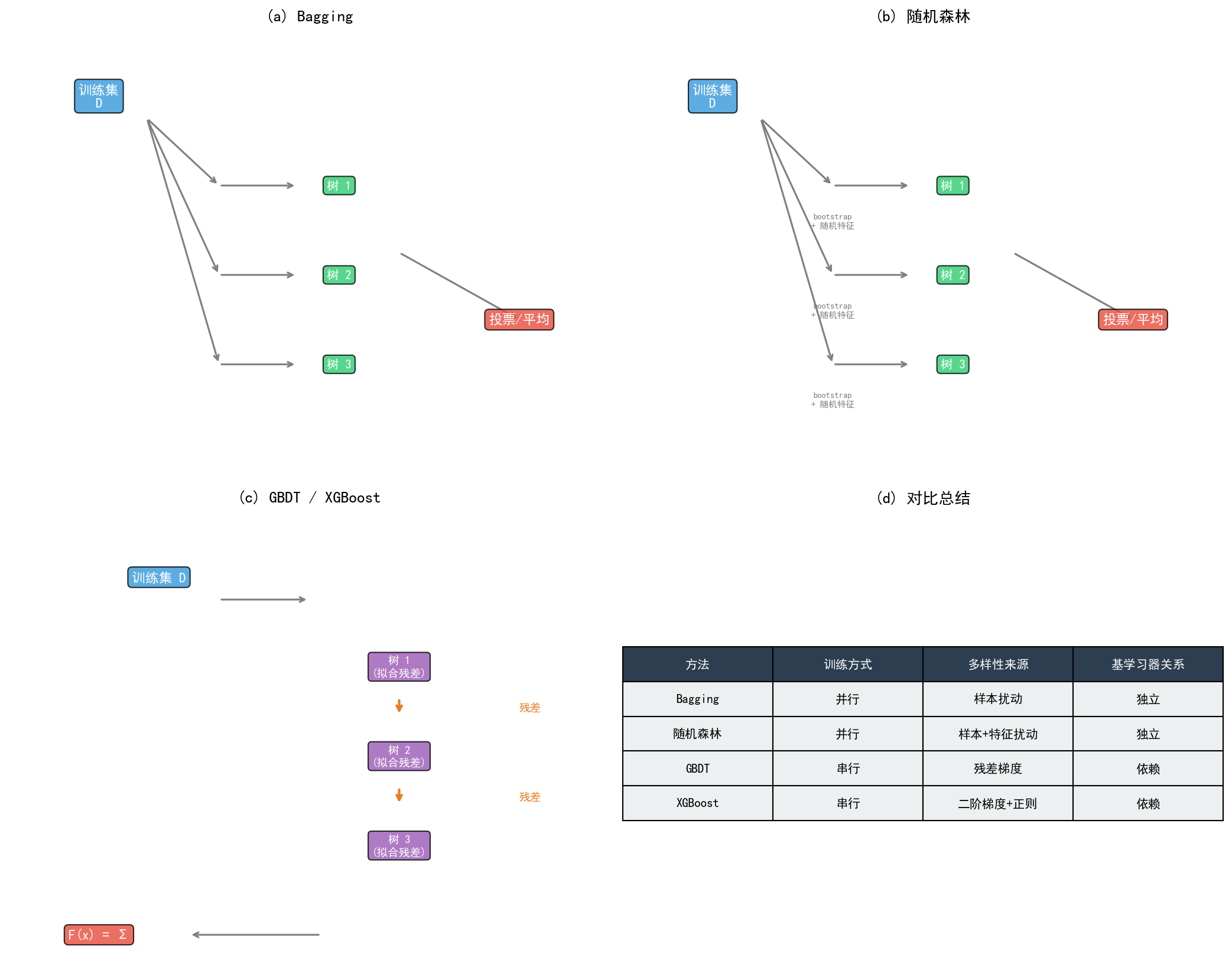
8.1 Bagging 与随机森林
Bagging:并行训练多棵决策树,通过自助采样(bootstrap)构建不同的训练子集,降低方差。
随机森林:在 Bagging 的基础上,引入随机特征选择,进一步增强树的多样性。
- 每棵树使用不同的样本子集(bootstrap)
- 每个节点分裂时,随机选择 m m m 个特征进行考察( m ≪ p m \ll p m≪p)
- 最终预测:分类用投票,回归用平均
8.2 Boosting 方法
GBDT(梯度提升决策树):
- 串行训练多棵决策树,每棵树拟合前面所有树的残差
- 使用浅层树(如深度为 3-6)作为基学习器
- 通过梯度下降的方式优化损失函数
XGBoost:
- 在 GBDT 基础上引入二阶泰勒展开
- 加入正则化项控制模型复杂度
- 支持列采样和行采样
- 高效的直方图算法和并行计算
LightGBM:
- 采用直方图算法加速训练
- **叶子优先(Leaf-wise)**的树生长策略
- 特征捆绑和互斥特征合并优化
CatBoost:
- 自动处理类别特征
- 使用有序提升减少过拟合
8.3 为什么决策树适合集成
- 高方差、低偏差:单棵树容易过拟合(高方差),但基学习器之间差异大,集成效果好
- 计算速度快:单棵树训练和预测都快,适合构建大规模集成模型
- 非线性能力强:能够捕捉复杂的非线性关系
- 易于扰动:对样本和特征的扰动敏感,有利于产生多样化的基学习器
九、典型应用场景
9.1 金融风控
- 信用评分:预测客户违约概率
- 欺诈检测:识别异常交易模式
- 贷款审批:自动化审批决策
9.2 医疗健康
- 疾病诊断:根据症状和检查结果预测疾病
- 患者分诊:评估病情严重程度
- 药物响应预测:预测患者对药物的反应
9.3 商业分析
- 客户流失预测:识别可能流失的客户
- 推荐系统:基于用户特征进行推荐
- 市场细分:识别不同客户群体
9.4 工业应用
- 设备故障诊断:预测设备是否需要维护
- 质量检测:判断产品是否合格
- 过程控制:优化生产流程
十、总结
CART 决策树是机器学习中最基础也是最重要的算法之一,其核心贡献包括:
- 统一的二叉树框架:通过二叉树统一处理分类和回归任务
- 基尼指数准则:提供了高效且有效的分裂准则
- 代价复杂度剪枝:为决策树剪枝提供了理论基础和实用算法
CART 作为基学习器,在 Bagging、随机森林、GBDT、XGBoost、LightGBM 等集成学习方法中广泛应用,是现代机器学习的重要组成部分。
理解 CART 的原理是学习树模型和集成学习的必要基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)