【MOE】Understanding Yolo-Master Code

1、OptimizedMOEImproved
ultralytics/nn/modules/moe/modules.py -> class OptimizedMOEImproved(nn.Module):
1.1、整体结构
输入 x [B, C, H, W]
│
├──→ Router(选 top_k 个 Expert) ───────────────┐
│ │
├──→ Shared Expert(始终激活) │
│ │ │
│ ▼ │
└──→ 稀疏 Expert 计算(只算被选中的) │
│ │
└──────── + ─────────────────────────→ final_output
│
+ residual(若 in==out)
数据流
x [B, C, H, W]
│
├─ routing(x) → weights, indices, loss_dict
│ │
│ └─ progressive_sparsity 动态调整 top_k
│
├─ shared_expert(x) → shared_out # 全量计算
│
├─ 稀疏 Expert 循环 → expert_output # 只算被选中的
│ Expert 0: 处理 batch [0,3,7...]
│ Expert 1: 处理 batch [1,5,...]
│ Expert 2: 跳过(没人选它)
│ Expert 3: 处理 batch [2,4,6...]
│
├─ final = shared_out + expert_output
│
├─ residual(in_ch == out_ch)→ final += x
│
└─ MOE_LOSS_REGISTRY[self] = aux_loss # 训练时注册 loss
1.2、各模块详解
0. 初始化
(1)balance_loss_coeff = 0.01 — 负载均衡损失权重
total_loss += 0.01 * balance_loss
控制"Expert 使用均衡"这个约束的强度。
值越大 → 强制 Expert 尽量均衡使用,但可能干扰主任务学习
值越小 → Expert 可以自由分配,但可能出现部分 Expert 闲置
0.01 → 轻微约束,不影响主任务为主
(2) router_z_loss_coeff = 1e-3 — 路由稳定性损失权重
total_loss += 0.001 * z_loss
控制"防止 Router logits 过大"这个约束的强度。
值越大 → Router 输出更平滑,路由更保守
值越小 → Router 可以输出更极端的概率分布
1e-3 → 比 balance_loss 更轻的约束,只做稳定性兜底
两个 loss 系数的大小关系:
balance_loss_coeff (0.01) > router_z_loss_coeff (0.001)
均衡更重要 稳定性次之
(3) expert_expand_ratio = 2.0 — Expert 内部膨胀比例
控制每个 Expert 内部的通道扩展倍数,影响 Expert 的表达能力和参数量。
# 以 InvertedResidualExpert 为例
mid_channels = in_channels * expand_ratio # 128 * 2.0 = 256
# 先扩张到 256,再压缩回 out_channels
expand_ratio = 1.0 → Expert 最轻量
expand_ratio = 2.0 → Expert 中等容量(默认)
expand_ratio = 4.0 → Expert 最强但参数最多
不同 Expert 类型对应关系:
| expert_type | 使用方式 |
|---|---|
simple |
expand_ratio=2.0 |
ghost |
ratio=int(2.0)=2 |
inverted |
expand_ratio=2.0 |
spatial |
expand_ratio=2.0 |
(4)progressive_sparsity = True — 渐进式稀疏开关
# True:训练初期用全部 Expert,逐步收敛到 top_k
# False:从第一步就只用 top_k 个 Expert
expert_expand_ratio → 控制模型容量(Expert 有多强)
progressive_sparsity → 控制训练策略(怎么学会稀疏)
balance_loss_coeff → 控制 Expert 使用是否均衡
router_z_loss_coeff → 控制 Router 决策是否稳定
1. Progressive Sparsity — 渐进式稀疏
# 训练初期:top_k = num_experts(所有 Expert 都参与)
# 训练中期:top_k 逐渐从 num_experts 降到目标 top_k
# 训练后期:top_k = 目标值(真正稀疏)
warmup_steps = 5000 # 5000 步内完成过渡
progress = step / 5000
current_k = num_experts - progress * (num_experts - top_k)
step=0 → current_k = num_experts = 4 (全部 Expert 激活)
step=2500 → current_k = 3 (过渡中)
step=5000+ → current_k = top_k = 2 (目标稀疏度)
目的:避免训练初期路由不稳定,让模型先学会用所有 Expert,再逐步收敛到稀疏选择。
2. Router — 路由层
# 三种可选路由器
router_type = 'efficient' # 默认
router_type = 'local' # 局部路由
router_type = 'adaptive' # 自适应路由
每种路由对应一种结构
# Instantiate Router
if router_type == 'local':
self.routing = LocalRoutingLayer(in_channels, num_experts, top_k=top_k, noise_std=noise_std)
elif router_type == 'adaptive':
self.routing = AdaptiveRoutingLayer(in_channels, num_experts, top_k=top_k, noise_std=noise_std)
else:
self.routing = EfficientSpatialRouter(in_channels, num_experts, top_k=top_k, noise_std=noise_std)
输出三个值
# 输出三个值
routing_weights, # 每个 Expert 的权重(加权求和用),eg torch.Size([128, 5]),激活了 5 个专家
routing_indices, # 选中的 Expert 编号,eg torch.Size([128, 5])
loss_dict # 训练时用于计算 moe_loss 的中间量
dict_keys(['router_logits', 'router_probs', 'topk_indices'])
topk_indices 也即 routing_indices
eg:EfficientSpatialRouter 结构,以 6 个专家为例,来自 ultralytics/nn/modules/moe/routers.py
EfficientSpatialRouter(
(softmax): Softmax(dim=1)
(router): Sequential(
(0): Conv2d(128, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
(3): Conv2d(16, 6, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(6, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
)
)
三种 Router 对比
| 特性 | EfficientSpatialRouter |
AdaptiveRoutingLayer |
LocalRoutingLayer |
|---|---|---|---|
| 池化方式 | avg_pool(stride=4) | AdaptiveAvgPool→1x1 | avg_pool(stride=2) |
| 卷积核 | 3×3 + 1×1 | 1×1 + 1×1 | 3×3 + 1×1 |
| 空间感知 | ✅ 中等 | ❌ 全局压缩 | ✅ 保留更多空间信息 |
| 计算量 | 低 | 最低 | 中 |
| 适合场景 | 默认均衡选择 | 速度优先 | 空间细节重要 |
可以看到 EfficientSpatialRouter 并没有采用 global average pooling,而是 stride=4 的 pooling,AdaptiveRoutingLayer 采用了 global average pooling,LocalRoutingLayer 则采用的是 stride = 2 的 pooling
pooling 完,然后接 self.router
self.router = nn.Sequential(
nn.Conv2d(in_channels, reduced_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(reduced_channels),
nn.SiLU(inplace=True),
nn.Conv2d(reduced_channels, num_experts, 1, bias=False),
nn.BatchNorm2d(num_experts) # numerical stability
)
最后 global_logits = torch.mean(out, dim=[2, 3]) 得到 logits(torch.Size([128, 6]))
EfficientSpatialRouter 的设计意图是:用可接受的计算量,保留一定的空间感知能力,让 Router 能根据特征图的局部分布来决策选哪个 Expert,而不是只看全局均值。
train 时,非 top-k 如何获取到梯度的,因为看这部分源码是没有梯度的
class BaseRouter(nn.Module):
def __init__(self, num_experts, top_k):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.softmax = nn.Softmax(dim=1)
def _process_logits(self, logits: torch.Tensor, noise_std: float, training: bool) -> Tuple[
torch.Tensor, torch.Tensor, Dict]:
"""Unified logic to process logits into Top-K selection."""
B = logits.shape[0]
# 1) Add noise during training (simplified Gumbel-Softmax trick)
if training and noise_std > 0:
logits = logits + torch.randn_like(logits) * noise_std
# 2) Compute probabilities
probs = F.softmax(logits.float(), dim=1).type_as(logits) # 对应论文公式 6
# 3) Select Top-K
topk_vals, topk_indices = torch.topk(probs, self.top_k, dim=1)
# 4) Normalize weights
sum_vals = topk_vals.sum(dim=1, keepdim=True) + 1e-6
topk_vals = topk_vals / sum_vals # 对应论文公式 8
# 5) Collect loss-related info (train only)
loss_dict = {}
if training:
loss_dict['router_logits'] = logits
loss_dict['router_probs'] = probs
loss_dict['topk_indices'] = topk_indices
return topk_vals, topk_indices, loss_dict
作者采用了下面三种机制来实现非 top-K 来获取梯度,也即 soft top-k for train
torch.topk 切断非 top-k 梯度
│
├─ noise_std → 随机让非top-k进入top-k,获得直接梯度
│
├─ balance_loss → 通过完整 probs 给非top-k间接梯度
│
└─ z_loss → 通过完整 logits 给非top-k间接梯度
源码 restore routing.top_k 解读
# Restore routing.top_k
self.routing.top_k = original_top_k
self.routing.top_k 还原的目的:
① 推理时行为正确 training=False 不走 sparsity 调度,必须保持 top_k=2
② 模型保存正确 序列化的是还原后的 top_k,不是训练中间状态
③ 职责清晰 routing 只负责执行,不负责记录调度状态
调度状态由 self.current_top_k buffer 统一管理
正确设计:
self.current_top_k (buffer) → 记录当前应该用几个 Expert
│
└─ 临时写入 self.routing.top_k → 执行 forward
│
└─ 执行完立刻还原为 self.top_k
关键设计意图
3×3 卷积 → 感知局部空间纹理(比 1×1 更有空间感知能力)
pool_scale=4 → 大幅降低计算量,同时保留足够的空间信息
BN 在最后 → 防止 logits 数值过大,稳定 softmax 输出
noise_std → 训练时引入随机性,避免路由坍塌到固定 Expert
训练时给 Router logits 加随机噪声
- 让原本排名靠后的 Expert 有机会被选中
- 防止路由坍塌(所有样本都选同几个 Expert)
没有噪声会发生什么?
初始化后某个 Expert 略占优势
│
▼
被更多样本选中 → 得到更多梯度更新
│
▼
变得更强 → 被选中概率更高
│
▼
其他 Expert 几乎不被选中 → 梯度稀少 → 退化
│
▼
最终退化成普通单一网络(MoE 失效)
3. Shared Expert — 共享专家
结构
self.shared_expert = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.SiLU(inplace=True)
)
forward
shared_out = self.shared_expert(x)
输入和输出的 shape 相同
self.shared_expert = nn.Sequential(
Conv2d → BN → SiLU
)
shared_out = self.shared_expert(x) # 每次都算,不参与路由竞争
目的:提供稳定的基础特征,防止稀疏路由导致某些信息完全丢失。
核心作用:提供稳定的基础特征
输入 x
│
├──→ Shared Expert(每次都算)→ 基础特征
│
├──→ Router → 选 top_k Expert
│ └──→ 稀疏 Expert(只算被选中的)→ 专业特征
│
└──→ final = shared_out + expert_output
无论 Router 怎么选,shared_expert 始终处理全部输入
- 保证每次 forward 都有稳定的基础输出
- 相当于给模型兜底
普通 MoE(无 Shared Expert),全靠稀疏 Expert,信息可能丢失
x → Router → [E1, E2, E3, E4] 选2个 → 输出
YOLO-Master MoE(有 Shared Expert):
x → Shared Expert ──────────────────┐
x → Router → [E1, E2] 选2个 ────→ + → 输出
基础特征兜底 专业特征补充
4. 稀疏 Expert 计算
for i in range(num_experts):
mask = (indices_flat == i) # 找出被分配到 Expert i 的样本
if mask.any():
inp = x[batch_idx] # 只取相关样本
out = experts[i](inp) # 只计算被选中的 Expert
w = weights_flat[...] # 对应路由权重
expert_output.index_add_(0, batch_idx, out * w) # 加权累加
关键点:没被选中的 Expert 完全不计算,这是 MoE 省计算量的核心。
5. MOE_LOSS_REGISTRY — loss 注册机制
# 训练时把 aux_loss 存入全局注册表
MOE_LOSS_REGISTRY[self] = aux_loss
这就是你之前 moe_loss 打印为 0 的关键——loss 不是直接返回,而是存进全局字典,由外部 trainer 统一收集。
forward() 不返回 loss
│
└──→ MOE_LOSS_REGISTRY[self] = aux_loss
│
▼
trainer 训练循环里
统一遍历 MOE_LOSS_REGISTRY
累加所有 MoE 层的 loss
加入总 loss 反向传播
排查 moe_loss=0 的方向:
# 搜索 trainer 里如何读取这个注册表
grep -rn "MOE_LOSS_REGISTRY" \
/mnt/data/ym/code/YOLO-Master-main/ --include="*.py"
2、MoELoss
ultralytics/nn/modules/moe/loss.py -> class MoELoss(nn.Module):
# 🐧Please note that this file has been modified by Tencent on 2026/02/13. All Tencent Modifications are Copyright (C) 2026 Tencent.
2.1、整体结构
router_probs [B, E] router_logits [B, E] expert_indices [B, k]
│ │ │
▼ ▼ ▼
balance_loss z_loss (hard balancing用)
负载均衡损失 路由稳定损失
│ │
│ entropy_loss(默认关闭)
│ │
└──────────────────────┘
│
total_loss
输入,eg 6 个专家,top-k = 5
loss_dict['router_logits'] = logits # torch.Size([128, 6])
loss_dict['router_probs'] = probs # torch.Size([128, 6])
loss_dict['topk_indices'] = topk_indices # torch.Size([128, 5]), eg tensor([0, 4, 5, 1, 3], device='cuda:0')
1. balance_loss — 负载均衡损失
self._get_global_mean 的作用,让 balance_loss 基于全局数据做判断而不是每张卡各自为政,产生冲突的梯度
单卡 → tensor.mean(dim=0) 直接求均值
多卡 → all_reduce 汇总后再求均值 保证所有卡看到一致的全局分布
balance_loss 目的:让所有 Expert 被均匀使用
两种模式:
Soft Balancing(use_soft_balancing=True):
importance = router_probs.mean(dim=0) # [E] 每个Expert的平均概率
usage = importance # 直接用概率近似使用率
balance_loss = E * sum(importance * usage)
# = E * sum(importance²) # 最小化时 → 均匀分布
梯度可以流回 router_probs → 完全可微,训练更稳定
Hard Balancing(默认,use_soft_balancing=False):
# 统计每个 Expert 实际被选中的次数
flat_indices = expert_indices.view(-1) # [B*K]
local_expert_counts = one_hot(flat_indices).sum(dim=0) # [B*K, E] -> [E]
usage = local_expert_counts / (B * top_k) # [E] 归一化为频率,每个 Expert 实际被使用的频率(客观事实)
usage = usage.detach() # ← 离散选择不可微,必须 detach
balance_loss = E * sum(importance * usage)
# ↑ ↑
# 可微(概率) × 不可微(计数)
importance(概率)有梯度 → router 可以学习调整概率
usage(计数)无梯度 → 只作为统计信号
balance_loss 最小化的含义:
E * sum(importance * usage) 最小
→ importance 和 usage 相关性最小
→ 概率高的 Expert 不应该被过度使用
→ 所有 Expert 使用趋于均匀(均值 = 1/E)
下面用具体的例子来解读这段代码
(1)假设条件
num_experts = 4
top_k = 2
batch_size = 6
use_soft_balancing = False(默认 Hard 模式)
(2)Step 1:输入数据
# Router softmax 后的概率分布 [B=6, E=4]
router_probs = tensor([
[0.5, 0.3, 0.1, 0.1], # 样本0 偏好 Expert0
[0.4, 0.4, 0.1, 0.1], # 样本1 偏好 Expert0,1
[0.1, 0.1, 0.6, 0.2], # 样本2 偏好 Expert2
[0.1, 0.1, 0.1, 0.7], # 样本3 偏好 Expert3
[0.6, 0.2, 0.1, 0.1], # 样本4 偏好 Expert0
[0.5, 0.3, 0.1, 0.1], # 样本5 偏好 Expert0
])
# top_k=2,每个样本选了哪2个Expert [B=6, k=2]
expert_indices = tensor([
[0, 1], # 样本0 选了 Expert0, Expert1
[0, 1], # 样本1 选了 Expert0, Expert1
[2, 3], # 样本2 选了 Expert2, Expert3
[3, 2], # 样本3 选了 Expert3, Expert2
[0, 1], # 样本4 选了 Expert0, Expert1
[0, 1], # 样本5 选了 Expert0, Expert1
])
(3)Step 2:计算 importance
importance = router_probs.mean(dim=0) # 每个Expert的平均概率 [E=4]
# 逐列求均值
Expert0: (0.5+0.4+0.1+0.1+0.6+0.5) / 6 = 2.2/6 = 0.367
Expert1: (0.3+0.4+0.1+0.1+0.2+0.3) / 6 = 1.4/6 = 0.233
Expert2: (0.1+0.1+0.6+0.1+0.1+0.1) / 6 = 1.1/6 = 0.183
Expert3: (0.1+0.1+0.2+0.7+0.1+0.1) / 6 = 1.3/6 = 0.217
importance = [0.367, 0.233, 0.183, 0.217]
# ↑ Expert0 概率最高,Router 偏爱它
含义:Router 认为每个 Expert 有多重要(主观概率)
(4)Step 3:计算 usage(Hard 模式)
# 统计每个 Expert 实际被选中几次
flat_indices = expert_indices.view(-1)
# = [0,1, 0,1, 2,3, 3,2, 0,1, 0,1] 共12个选择
local_expert_counts = one_hot(flat_indices, num_classes=4).sum(dim=0)
# Expert0 被选: 4次 (样本0,1,4,5各选了Expert0)
# Expert1 被选: 4次 (样本0,1,4,5各选了Expert1)
# Expert2 被选: 2次 (样本2,3)
# Expert3 被选: 2次 (样本2,3)
# counts = [4, 4, 2, 2]
total_samples = B * top_k = 6 * 2 = 12
usage = [4/12, 4/12, 2/12, 2/12]
= [0.333, 0.333, 0.167, 0.167]
usage = usage.detach() # 离散计数,不传梯度
含义:每个 Expert 实际被使用的频率(客观事实)
(5)Step 4:计算 balance_loss
balance_loss = num_experts * sum(importance * usage)
= 4 * sum([0.367, 0.233, 0.183, 0.217]
*[0.333, 0.333, 0.167, 0.167])
# 逐元素相乘
= 4 * (0.367×0.333 + 0.233×0.333 + 0.183×0.167 + 0.217×0.167)
= 4 * (0.122 + 0.078 + 0.031 + 0.036 )
= 4 * 0.267
= 1.068
(6)Step 5:理解为什么这个公式能度量"不均衡"
理想均衡情况:
所有 Expert 被等概率选中
importance = [0.25, 0.25, 0.25, 0.25]
usage = [0.25, 0.25, 0.25, 0.25]
balance_loss = 4 * sum([0.25×0.25] × 4)
= 4 * (0.0625 × 4)
= 4 * 0.25
= 1.0 ← 最小值
极端不均衡情况:
Expert0 承包所有工作
importance = [1.0, 0.0, 0.0, 0.0]
usage = [1.0, 0.0, 0.0, 0.0]
balance_loss = 4 * sum([1.0×1.0, 0, 0, 0])
= 4 * 1.0
= 4.0 ← 最大值
balance_loss 范围:
最小 1.0 ← 完全均衡(理想状态)
最大 N ← 完全集中(最差状态,N=num_experts)
当前示例:1.068 稍微偏离均衡,Expert0,1 过载
(7)Step 6:梯度如何引导均衡
# usage.detach() → 不可微,只是统计信号
# importance → 可微,梯度流回 router_probs → router 参数
balance_loss = 4 * sum(importance * usage)
↑
对 importance 求梯度
d(balance_loss)/d(importance[i]) = 4 * usage[i]
Expert0: 梯度 = 4 × 0.333 = 1.332 ← 梯度最大,被强力压制
Expert1: 梯度 = 4 × 0.333 = 1.332 ← 同上
Expert2: 梯度 = 4 × 0.167 = 0.668 ← 梯度小,轻微压制
Expert3: 梯度 = 4 × 0.167 = 0.668 ← 同上
使用越多的 Expert → 梯度越大 → router 被迫降低其概率
使用越少的 Expert → 梯度越小 → router 概率自然上升
最终趋势:
Expert0,1 概率被压低 → usage 减少
Expert2,3 概率被抬高 → usage 增加
→ 逐渐趋向均衡
usage 不可微的原因:torch.topk 返回的是离散整数索引,离散选择天然不可微。

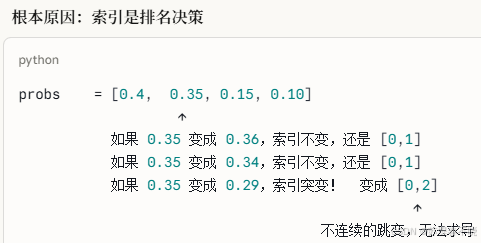
(8)整体过程一句话总结
importance(Router主观偏好)× usage(客观选择频率)
两者都高 → 说明某个Expert又被偏爱又被过度使用 → loss大 → 梯度压制
两者都低 → 说明某个Expert被冷落 → loss贡献小 → 概率自然回升
最终趋向:importance均匀 且 usage均匀
2. z_loss — 路由稳定性损失
l o g ( s u m ( e x p ( x ) ) ) 2 log(sum(exp(x)))^2 log(sum(exp(x)))2
log_z = torch.logsumexp(router_logits, dim=1) # [B]
z_loss = mean(log_z²)
目的:约束 logits 数值幅度,防止路由极端化
logits 很大 → softmax 极端 → 某个Expert概率→1,其余→0
→ 退化成固定路由,MoE失效
logsumexp(logits)² 惩罚大数值
→ 迫使 logits 保持在合理范围
→ softmax 输出更平滑,路由更多样
logits = [10, 0, 0, 0] → logsumexp ≈ 10 → z_loss = 100 惩罚大
logits = [1, 0, 0, 0] → logsumexp ≈ 1 → z_loss = 1 惩罚小
logits = [0.1,0.1,0.1,0.1] → logsumexp小 → z_loss ≈ 0 几乎不惩罚
3. entropy_loss — 路由确定性损失(默认关闭)
entropy_loss_coeff = 0.0 # 默认关闭
entropy = -sum(p * log(p + 1e-8), dim=1).mean()
p p p 是 router_probs
目的:鼓励 Router 做出确定的选择
与 z_loss 方向相反:
z_loss → 防止 logits 过大 → 概率分布平滑
entropy_loss → 鼓励概率集中 → 做出确定选择
两者是对立的,一般二选一:
- 路由不稳定 → 开 z_loss
- 路由太模糊 → 开 entropy_loss(调大 entropy_loss_coeff)
4. total_loss 加权求和
total_loss = 0.01 * balance_loss # 均衡权重最大
+ 0.001 * z_loss # 稳定性次之
+ 0.0 * entropy_loss # 默认关闭
balance_loss_coeff (0.01) >> z_loss_coeff (0.001)
均衡是主要目标 稳定性是辅助约束
5. 分布式支持
def _get_global_mean(self, tensor):
if not dist.is_initialized():
return tensor.mean(dim=0) # 单卡直接均值
# 多卡:收集所有 GPU 的数据再求均值
dist.all_reduce(local_sum, op=SUM)
dist.all_reduce(local_count, op=SUM)
return local_sum / local_count
单卡训练:importance = batch 内均值
多卡训练:importance = 所有 GPU 的全局均值
→ 避免每张卡只看自己的 batch,均衡判断更准确
2.2、各组件职责总结
| 组件 | 解决的问题 | 作用对象 | 是否可微 |
|---|---|---|---|
balance_loss |
Expert 使用不均衡 | router_probs | ✅ importance可微 |
z_loss |
logits 数值过大 | router_logits | ✅ 完全可微 |
entropy_loss |
路由决策模糊 | router_probs | ✅ 完全可微 |
all_reduce |
多卡均衡不一致 | importance | — |
3、语法
fill_(v)所有元素填充为 v,PyTorch 中所有以 _ 结尾的方法都是原地操作(in-place),直接修改原 tensor,不创建新对象。- torch.randn_like(x) # 标准正态分布 N(0, 1)
理论上是 (-∞, +∞),没有硬边界。 ### 实际概率分布 范围 概率 ────────────────── [-1, +1] 68.3% [-2, +2] 95.4% [-3, +3] 99.7% ← 通常认为的"实际范围" [-4, +4] 99.99% 超出 ±4 极少出现
4、总结
- code 和 paper 还是有些差异的地方,因为 code 升级过
- 实现 soft top-k 采用了工程上的兜底,单纯 mask 是没有梯度的
- shared_expert 作为 residual 的 x 保证每个专家 train 时都参与到了反向传播

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)