Transformer 架构剖析
文章目录
初识 Transformer
-
2018年google发表了BERT模型并横扫了NLP领域11项任务,而BERT中Transformer发挥了重要作用,使得Transformer架构流行起来
-
Transformer 的优势
RNN、LSTM、GRU 处理长文本存在梯度消失,计算慢,无法并行
-
Transformer 能够利用分布式GPU进行并行训练,提升模型训练效率
-
在分析预测长文本时,捕捉间隔较长的语义关联效果更好
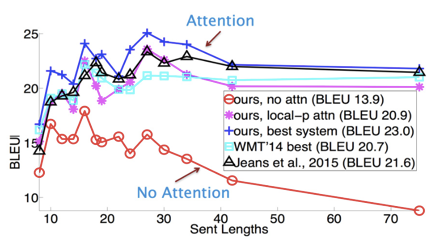
-
Transformer 架构
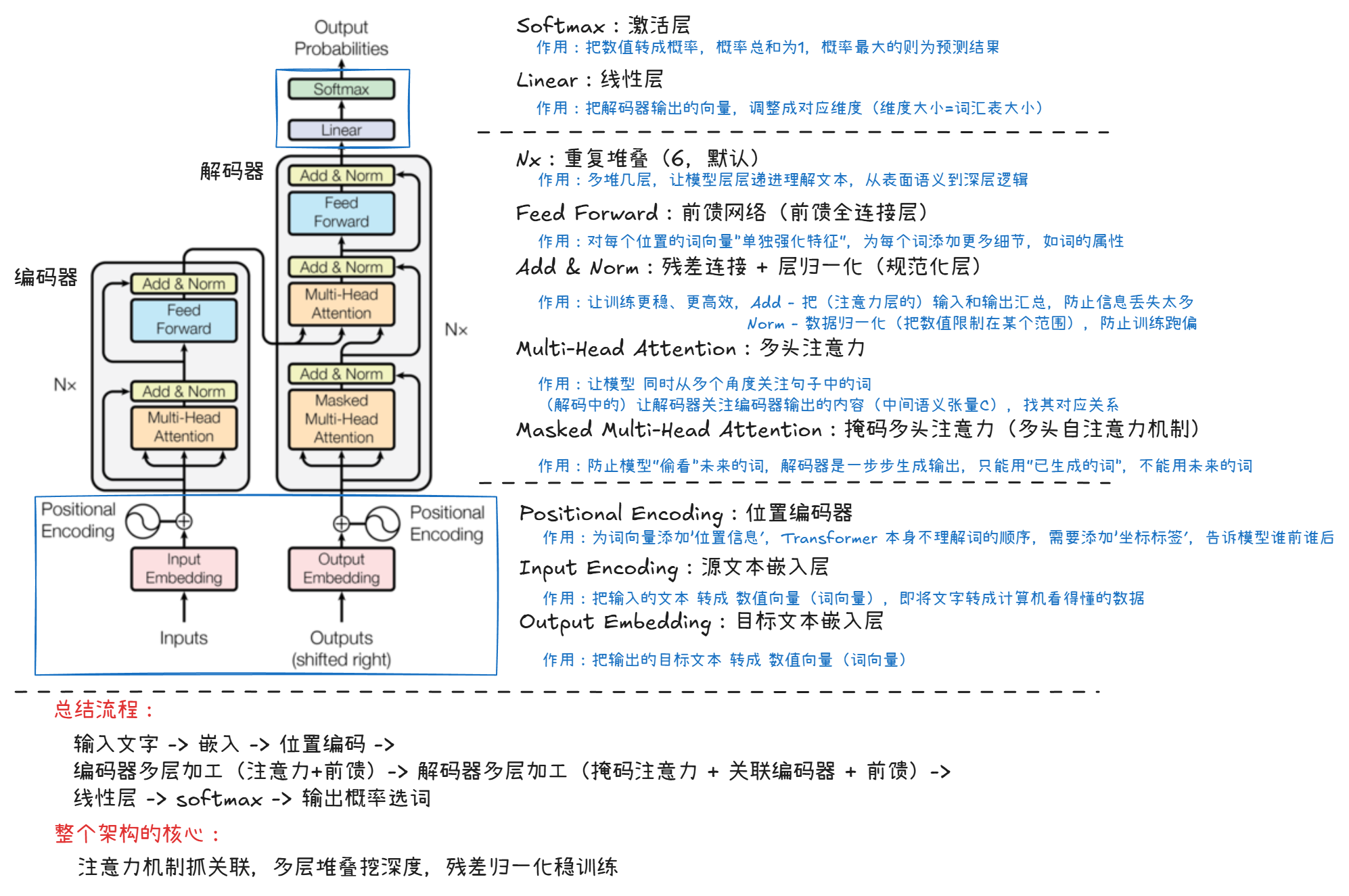
组件
import copy
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
词嵌入层
# 词嵌入层
class Embedding(nn.Module):
def __init__(self, vocab_size, embed_dim):
"""
:param vocab_size: 词汇表大小
:param embed_dim: 词嵌入的维度
"""
super().__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.embedding = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
# 进行缩放:输入词的词向量 * √词嵌入的维度
# 目的:平衡梯度,避免梯度爆炸或者梯度消失
return self.embedding(x) * math.sqrt(self.embed_dim)
位置编码
-
核心作用:
Transformer 是并行处理所有词的,模型不知道词的前后顺序,需要给每个词加上一个“位置编号”,让模型知道这个词在句子中的第几个位置
-
位置编码通过什么生成
Transformer 编码位置信息:使用 正弦函数和余弦函数 生成
偶数维度用sin,奇数维度用cos
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i d m o d e l ) \begin{align*} PE_{(pos, 2i)} &= \sin\left( \frac{pos}{10000^{\frac{2i}{d_{model}}}} \right) \\ PE_{(pos, 2i+1)} &= \cos\left( \frac{pos}{10000^{\frac{2i}{d_{model}}}} \right) \end{align*} PE(pos,2i)PE(pos,2i+1)=sin(10000dmodel2ipos)=cos(10000dmodel2ipos)
-
其中:
p o s pos pos:位置(第几个词), i i i:维度索引(从 0 0 0开始, 2 i 2i 2i 需要覆盖词向量的全部维度), d m o d e l d_{model} dmodel:词向量的维度
10000 2 i d m o d e l 10000^{\frac{2i}{d_{model}}} 10000dmodel2i:周期缩放因子,不同的 i i i 会让周期不一样( i i i 越大,周期越长)
使用三角函数的优点:位置 p o s + k pos+k pos+k 的编码 = = = 位置 p o s pos pos 的编码的 线性组合(简单的乘加运算),不是每个位置都要重算三角函数
为什么能做到,因为三角函数
sin ( α + β ) = sin ( α ) cos ( β ) + cos ( α ) sin ( β ) cos ( α + β ) = cos ( α ) cos ( β ) − sin ( α ) sin ( β ) \begin{align*} \sin(\alpha + \beta) &= \sin(\alpha)\cos(\beta) + \cos(\alpha)\sin(\beta) \\ \cos(\alpha + \beta) &= \cos(\alpha)\cos(\beta) - \sin(\alpha)\sin(\beta) \end{align*} sin(α+β)cos(α+β)=sin(α)cos(β)+cos(α)sin(β)=cos(α)cos(β)−sin(α)sin(β)
α α α 对应 p o s pos pos 相关的部分, β β β 对应 k k k 相关的部分
-
-
例子
假设词向量维度为4,即每个位置的编码是一个4维向量。
维度为4时, i i i 取 0 0 0 和 1 1 1。
当 p o s = 2 pos = 2 pos=2 时:
i = 0 i = 0 i=0:
- 第0维: P E ( 2 , 0 ) = sin ( 2 / 1 ) = sin ( 2 ) PE(2, 0) = \sin(2/1) = \sin(2) PE(2,0)=sin(2/1)=sin(2)
- 第1维: P E ( 2 , 1 ) = cos ( 2 / 1 ) = cos ( 2 ) PE(2, 1) = \cos(2/1) = \cos(2) PE(2,1)=cos(2/1)=cos(2)
i = 1 i = 1 i=1:
- 第2维: P E ( 2 , 2 ) = sin ( 2 / 100 ) = sin ( 1 / 50 ) PE(2, 2) = \sin(2/100) = \sin(1/50) PE(2,2)=sin(2/100)=sin(1/50)
- 第3维: P E ( 2 , 3 ) = cos ( 2 / 100 ) = cos ( 1 / 50 ) PE(2, 3) = \cos(2/100) = \cos(1/50) PE(2,3)=cos(2/100)=cos(1/50)
因此,位置 p o s = 2 pos=2 pos=2的4维位置编码向量为:
[ sin ( 2 ) , cos ( 2 ) , sin ( 1 / 50 ) , cos ( 1 / 50 ) ] [\sin(2), \cos(2), \sin(1/50), \cos(1/50)] [sin(2),cos(2),sin(1/50),cos(1/50)]
数值近似为: [ 0.909 , − 0.416 , 0.020 , 0.998 ] [0.909, -0.416, 0.020, 0.998] [0.909,−0.416,0.020,0.998]
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=60):
"""
:param d_model: 词向量的维度(词嵌入的维度), 512
:param dropout: 随机失活概率
:param max_len: 最大序列长度, 60
"""
super().__init__()
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_len, d_model) # Positional Encoding,存放位置编码信息
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 位置索引 shape=[max_len, 1]
# 1/10000^(2i/d_model) = 1/e^( (2i/d_model)*(ln(10000) ) = e^(2i* (-ln(10000)/d_model)) )
# torch.arange(0, d_model, 2) -> [0, 2, 4, 6, 8, ..., d_model-2] 偶数维度,+1 变成奇数维度
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # 1/周期缩放因子 shape=[1, d_model/2]
position_values = position * div_term # 位置索引 * 1/周期缩放因子 shape=[max_len, d_model/2] -> [60, 512]
pe[:, 0::2] = torch.sin(position_values) # 偶数维度
pe[:, 1::2] = torch.cos(position_values) # 奇数维度
pe = pe.unsqueeze(0) # 升维:添加 batch_size 维度 shape=[1, 60, 512]
self.register_buffer('pe', pe) # 缓存位置编码信息, 避免每次训练时重新计算
【扩展】绘制词汇向量中特征的分布曲线
# 可视化位置编码
def plot_position_encoding():
pe = PositionalEncoding(d_model=20, dropout=0.1, max_len=100)
x = torch.zeros(1, 100, 20) # [batch_size, seq_len, d_model]
y = pe(x) # shape=[1, 100, 20]
# 绘图
plt.figure(figsize=(20, 10))
plt.plot(np.arange(100), y[0, :, 4:8].detach().numpy())
plt.legend([f'dim {p}'for p in [4, 5, 6, 7]])
plt.show()
【扩展】掩码张量
掩码张量是一个由 0 和 1 组成的张量,用于在 Transformer 等模型中遮挡或替换另一张量的部分数值,避免模型在训练时提前利用未来信息,保证生成逻辑的合理性。
import torch
import numpy as np
import matplotlib.pyplot as plt
# 上三角矩阵
def np_triu(x):
arr = np.ones((x, x))
print(arr) # 创建一个行列一致的矩阵
# print(np.triu(arr, 1)) # 对角线上移
# print(np.triu(arr, -1)) # 对角线下移
return np.triu(arr)
x = 5
up_trius = torch.triu(torch.ones((x, x))) # 上三角矩阵
print(up_trius)
low_trius = torch.from_numpy(1 - np.triu(np.ones((x, x)), 1)) # 下三角矩阵
print(low_trius.data)
# 掩码张量可视化
def plot_mask(mask):
plt.figure(figsize=(5, 5))
plt.imshow(mask)
plt.show()
plot_mask(torch.triu(torch.ones((10, 10))))
# 黄色(1)代表没有被遮掩, 紫色(0)代表被遮掩的信息
# 横坐标:目标词汇的位置, 纵坐标:可查看的位置
多头注意力机制
多头注意力机制,是将经线性变换得到的Q、K、V张量沿词嵌入维度切分为多个头,分别独立执行注意力计算后再融合结果,以此捕获序列不同表示子空间的语义与依赖关系的注意力机制。
![![[Pasted image 20260331160240.png]]](https://i-blog.csdnimg.cn/direct/34d36a1d238b4f9085b73470ba657c9a.png)
# 注意力计算
def attention(query, key, value, mask=None, dropout=None):
"""
计算注意力
:param query: 查询张量, shape=[batch_size, seq_len, d_model]
:param key: 键张量, shape=[batch_size, seq_len, d_model]
:param value: 值张量, shape=[batch_size, seq_len, d_model]
:param mask: 掩码张量, shape一般和 score 匹配
:param dropout: 随机失活,防止过拟合
:return: 输出张量(融合信息) 和 注意力权重
"""
# 自注意力公式:softmax(Q * K^T / sqrt(d_k)) * V
d_k = query.size(-1) # 获取Q的特征维度(最后一个维度 d_model)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 掩码处理(可选),处理后再进行softmax的权重会接近于0
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
# 随机失活处理
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
模块克隆
# 克隆模块
def clones(module, N):
"""
创建N个相同的模块,深拷贝,每个模块的参数都是独立的
:param module: 被克隆的模块
:param N: 堆叠的层数
:return: 有N个相同模块的ModuleList
"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
多头注意力机制
# 多头注意力机制
# 把词向量维度映射到多个头,并行计算多个头,最后再拼接起来
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout_p=0.1):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
# 分头
assert d_model % num_heads == 0 # 维度必须可以被头数整除
self.depth = d_model // num_heads # 每个头的词嵌入维度
# 4个线性层
self.linears = clones(nn.Linear(d_model, d_model), 4)
# dropout
self.dropout = nn.Dropout(dropout_p)
# 注意力权重
self.attn = None
def forward(self, query, key, value, mask=None):
# query, key, value: [batch_size, seq_len, d_model]
# mask: [batch_size, seq_len, seq_len]
# 是否需要掩码
if mask is not None:
mask = mask.unsqueeze(0)
# 获取批量大小
batch_size = query.size(0)
# 线性变化
# [model(x) for model, x in zip(...)] 取前 3 个linear 分别对应给 Q、K、V 做线性变换
# view() 将d_model拆成 num_heads × depth ,目的:分头
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, num_heads, depth]
# [2, 4, 512] -> [2, 4, 8, 64]
# transpose() 交换维度,目的:让 seq_len, depth 紧贴一起,方便后续计算注意力
# [batch_size, seq_len, num_heads, depth] -> [batch_size, num_heads, seq_len, depth]
# [2, 4, 8, 64] -> [2, 8, 4, 64]
query, key, value = [
model(x).view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))
]
# 多头注意力计算
# 注意力输出、注意力权重:[batch_size, num_heads, seq_len, depth]、[batch_size, num_heads, seq_len, seq_len]
x, self.attn = attention(query, key, value, mask, self.dropout)
# 合并多头:[batch_size, seq_len, num_heads, depth] -> [batch_size, seq_len, d_model]
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.depth)
# 线性变换
return self.linears[-1](x)
前馈全连接层
在Transformer中前馈全连接层就是具有两层线性层的全连接网络
考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力
# 前馈全连接层
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.dropout(F.relu(x))
x = self.fc2(x)
return x
规范化层
核心目的:解决深度神经网络训练中的内部协变量偏移问题
深层网络经过多层计算后参数可能会出现过大或过小的情况,这会导致学习过程出现异常、模型收敛缓慢
通过规范层对数值进行规范化,使其特征数值在合理范围内,能有效缓解深层网络堆叠带来的数值不稳定问题
在Transformer中,该模块通常由层归一化(Layer Normalization)实现
f ( x ) = λ ⋅ x − E ( x ) Var ( x ) + ϵ + β f(x) = \lambda \cdot \frac{x - E(x)}{\sqrt{\text{Var}(x)} + \epsilon} + \beta f(x)=λ⋅Var(x)+ϵx−E(x)+β
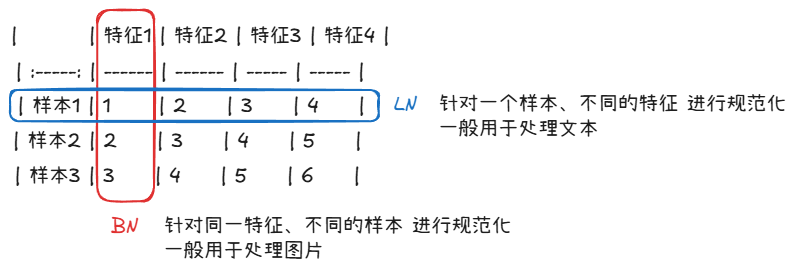
BN和LN的区别:
# 规范化层
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
"""
:param features: 词嵌入维度(特征数)
:param eps: 小常数,避免除零(分母为零)
"""
super().__init__()
# 线性公式:y = a * x + b
# a: 对标准化后的数据进行缩放,b: 对标准化后的数据进行平移
self.a = nn.Parameter(torch.ones(features)) # 可学习的缩放系数
self.b = nn.Parameter(torch.zeros(features)) # 可学习的平移系数
self.eps = eps
def forward(self, x):
x_mean = x.mean(-1, keepdim=True) # 计算每个样本(最后一个维度,词嵌入维度)的 均值
x_std = x.std(-1, keepdim=True) # 计算每个样本(最后一个维度,词嵌入维度)的 标准差
return self.a * (x - x_mean) / (x_std + self.eps) + self.b # 规范化后的结果
子层连接
编码器由两个子层堆叠而成:多头自注意力子层(Multi-Head Self-Attention)和前馈神经网络子层(Feed-Forward Network)。每个子层后面都跟随残差连接和层归一化操作。
import torch.nn as nn
from element import *
# 构建子层
class SublayerConnection(nn.Module):
def __init__(self, d_model, dropout=0.1):
super().__init__()
# 规范化层(层归一化)
self.norm = nn.LayerNorm(d_model)
# 随机失活
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# x: 输入张量 [batch_size, seq_len, d_model]
# sublayer: 子层对象(如:多头注意力层、前馈全连接层等)
# 方式一:先子层处理,再规范化层处理,最后随机失活并残差连接
result1 = x + self.dropout(self.norm(sublayer(x)))
# 方式二:先规范化层处理,再子层处理,最后随机失活并残差连接
# result2 = x + self.dropout(sublayer(self.norm(x)))
return result1
# 编码器层
class EncoderLayer(nn.Module):
def __init__(self, d_model, attn_obj, feed_forward, dropout=0.1):
super().__init__()
self.d_model = d_model # 词嵌入维度
self.attn_obj = attn_obj # 注意力对象
self.feed_forward = feed_forward # 前馈全连接对象
self.sublayer = clones(SublayerConnection(d_model, dropout), 2) # 克隆子层(2个)
def forward(self, x, mask):
# 第1个子层(多头自注意力层)
x = self.sublayer[0](x, lambda x: self.attn_obj(x, x, x, mask))
# 第2个子层(前馈全连接层)
x = self.sublayer[1](x, lambda x: self.feed_forward(x))
return x
# 解码器层
class DecoderLayer(nn.Module):
def __init__(self, d_model, mask_attn, attn, feed_forward, dropout=0.1):
super().__init__()
self.d_model = d_model # 词向量维度
self.mask_attn = mask_attn # 掩码多头注意力
self.attn = attn # 多头注意力
self.feed_forward = feed_forward # 前馈全连接层
self.sublayer = clones(SublayerConnection(d_model, dropout), 3) # 3个子层连接
def forward(self, x, encoder_output, source_mask, target_mask):
"""
:param x: 解码器的输入,即 源序列 的词嵌入+位置编码
:param encoder_ouyput: 编码器的输出,即 源序列 的词嵌入+位置编码
:param source_mask: 源序列 的掩码,用于 编码器-解码器 注意力
:param target_mask: 目标序列 的掩码,用于 自注意力
:return: 解码器的输出,即目标序列 的词嵌入+位置编码
"""
# 第1个子层(多头自注意力层)
x = self.sublayer[0](x, lambda x: self.mask_attn(x, x, x, target_mask))
# 第2个子层(多头注意力层)
x = self.sublayer[1](x, lambda x: self.attn(x, encoder_output, encoder_output, source_mask))
# 第3个子层(前馈全连接层)
x = self.sublayer[2](x, lambda x: self.feed_forward(x))
return x
编码器和解码器
import copy
import torch.nn.functional as F
from element import *
from sublayer import *
# 编码器
class Encoder(nn.Module):
def __init__(self, layer, N):
super().__init__()
self.layers = clones(layer, N) # 克隆编码器层(N个)
self.norm = LayerNorm(layer.d_model) # 层规范化
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
# 解码器
class Decoder(nn.Module):
def __init__(self, layer, N):
super().__init__()
self.layers = clones(layer, N) # 克隆解码器层(N个)
self.norm = LayerNorm(layer.d_model) # 层规范化
def forward(self, x, encoder_output, source_mask, target_mask):
for layer in self.layers:
x = layer(x, encoder_output, source_mask, target_mask)
return self.norm(x)
模型搭建
# Transformer 模型构建
class EncoderDecoder(nn.Module):
def __init__(self, source_embed, encoder, target_embed, decoder, generator):
super().__init__()
self.source_embed = source_embed # 源语言嵌入
self.encoder = encoder # 编码器
self.target_embed = target_embed # 目标语言嵌入
self.decoder = decoder # 解码器
self.generator = generator # 输出层
def forward(self, source_x, target_y, source_mask, target_mask):
"""
Transformer 前向传播,先编码,再解码
:param source_x: 编码器输入 [batch_size, sen_len]
:param target_y: 解码器输入 [batch_size, sen_len]
:param sorce_mask: 源语言掩码张量,padding_mask 填充掩码,防止填充的pad子影响注意力计算
:param target_mask: 目标语言掩码张量,sentence_mask 句子掩码,防止未来的信息被提前利用
:return: 模型预测结果(概率分布结果) [batch_size, sen_len, vocab_size]
"""
encoder_output = self.encode(source_x, source_mask)
decoder_output = self.decode(target_y, encoder_output, source_mask, target_mask)
return self.generator(decoder_output)
def encode(self, source_x, source_mask):
return self.encoder(self.source_embed(source_x), source_mask)
def decode(self, target_y, encoder_output, source_mask, target_mask):
# encoder_output: 编码器输出
return self.decoder(self.target_embed(target_y), encoder_output, source_mask, target_mask)
# 输出部分:线性层 + 激活层
class Generator(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.fc = nn.Linear(d_model, vocab_size) # 线性层
def forward(self, x):
return F.log_softmax(self.fc(x), dim=-1)
# 测试模型
def model_construction():
c = copy.deepcopy
d_model = 512
droput_p = 0.2
# 编码部分
source_embed = Embedding(vocab_size=1000, embed_dim=d_model) # 词嵌入
source_pos_encoding = PositionalEncoding(d_model, dropout=0.1) # 位置编码
multi_head_attn = MultiHeadAttention(d_model, num_heads=8) # 多头注意力层
feed_forward = FeedForward(d_model, d_ff=2048) # 前馈全连接层
encoder_layer = EncoderLayer(d_model, multi_head_attn, feed_forward, droput_p) # 编码器层
encoder = Encoder(encoder_layer, N=6)
# 解码部分
target_embed = c(source_embed) # 词嵌入
target_pos_encoding = c(source_pos_encoding) # 位置编码
mask_attn = c(multi_head_attn) # 掩码多头注意力层
attn = c(multi_head_attn) # 多头注意力层
ff = c(feed_forward)
decoder_layer = DecoderLayer(d_model, mask_attn, attn, ff, droput_p)
decoder = Decoder(decoder_layer, N=6)
# 输出部分
generator = Generator(d_model, vocab_size=1000)
# 模型搭建
model = EncoderDecoder(
nn.Sequential(source_embed, source_pos_encoding),
encoder,
nn.Sequential(target_embed, target_pos_encoding),
decoder,
generator
)
print(f"模型结构: {model}")
# 模型前向测试
source_x = torch.LongTensor([[1, 3, 5, 7],[2, 4, 6, 8]])
target_y = torch.LongTensor([[0, 1, 3, 5],[1, 2, 4, 6]])
source_mask = torch.zeros(8, 4, 4)
target_mask = c(source_mask)
output = model(source_x, target_y, source_mask, target_mask)
print(f"模型输出: {output.shape}")
if __name__ == '__main__':
model_construction()
输出:
模型结构: EncoderDecoder(
(source_embed): Sequential( # 输入层(编码器)
(0): Embedding( # 词嵌入
(embedding): Embedding(1000, 512)
)
(1): PositionalEncoding( # 位置编码
(dropout): Dropout(p=0.1, inplace=False)
)
)
(encoder): Encoder( # 编码器
(layers): ModuleList(
(0-5): 6 x EncoderLayer( # 编码器层
(attn_obj): MultiHeadAttention( # 多头注意力
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): FeedForward( # 前馈全连接层
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList( # 层规范化 + 残差连接
(0-1): 2 x SublayerConnection(
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(target_embed): Sequential( # 输入层(解码器)
(0): Embedding(
(embedding): Embedding(1000, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(decoder): Decoder( # 解码器
(layers): ModuleList(
(0-5): 6 x DecoderLayer( # 解码器层
(mask_attn): MultiHeadAttention( # 多头自注意力(sentence-mask)
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(attn): MultiHeadAttention( # 多头注意力(padding-mask)
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): FeedForward( # 前馈全连接层
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList( # 层规范化 + 残差连接
(0-2): 3 x SublayerConnection(
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(generator): Generator( # 输出层
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
)
模型输出: torch.Size([2, 4, 1000])

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)