【AI大模型前沿】FireRed-OCR:小红书开源的2B参数文档结构解析专家,以小模型大能力登顶OmniDocBench SOTA
系列篇章💥
前言
在文档数字化浪潮中,通用视觉语言模型(VLM)虽具备强大的语义理解能力,却普遍面临"结构性幻觉"难题——表格行列错乱、公式凭空捏造、阅读顺序混乱等问题严重制约了工业级OCR应用落地。2026年3月,小红书Super Intelligence团队正式开源FireRed-OCR,以仅20亿参数的轻量级架构,在权威评测OmniDocBench v1.5中斩获92.94%综合得分,超越GPT-5.2、Gemini-3.0 Pro及Qwen3-VL-235B等超大规模模型,成功实现"小模型击败大模型"的技术突破,为文档智能解析领域树立了新的标杆。

一、项目概述
FireRed-OCR是小红书团队开源的端到端文档结构解析视觉语言模型,基于Qwen3-VL-2B-Instruct架构构建,采用创新的"三阶段渐进优化"训练策略与"几何+语义"数据工厂,专为攻克文档解析中的"结构幻觉"问题而设计。该模型能够将PDF、扫描图像、学术论文、财务报告等复杂版式文档精准转换为标准Markdown格式,支持复杂表格提取、数学公式语义化解析、多级标题层级重建等核心能力。作为工业级OCR结构化专家,FireRed-OCR不仅实现了端到端方案的新SOTA(State-of-the-Art),更以Apache 2.0协议全面开源,为科研人员和开发者提供了低成本、高精度的文档数字化解决方案。
二、核心功能
(一)、复杂表格高精度提取
FireRed-OCR具备卓越的表格结构识别能力,能够从排版混乱的PDF或扫描图像中精准定位表格区域,严格维持原始行列逻辑关系。与传统OCR系统常见的表格错位、跨行断裂等问题不同,该模型通过像素级空间感知技术,确保表格单元格内容与其行列位置精确对应,支持生成标准Markdown表格语法,便于后续的数据分析和数据库入库操作。
(二)、数学公式语义化解析
针对学术论文和技术文档中的数学表达式,FireRed-OCR实现了从视觉识别到语义理解的跨越。模型能够精准捕获文档内嵌的数学公式,转换为语法正确、语义完整的LaTeX或Markdown格式代码,有效避免公式符号遗漏、结构错误等常见问题,满足学术出版和后续编辑的严苛要求。
(三)、智能层级结构重建
FireRed-OCR具备强大的文档逻辑理解能力,可自动判别H1-H6标题级别、段落缩进、有序/无序列表等视觉线索,生成符合Markdown规范的嵌套结构。这种层级重建能力确保了文档语义层次的准确还原,使转换后的电子文档保留了原文档的导航结构和阅读逻辑。
(四)、全格式文档兼容转换
模型原生支持PDF、扫描图片、学术论文、财报、合同、书籍杂志等多种文档类型的处理,能够应对单栏、双栏、多栏混排等复杂版式场景。无论是标准印刷体还是带有一定形变的扫描件,FireRed-OCR均能输出结构清晰、语义连贯的Markdown文本,实现真正的一站式文档数字化。
(五)、强抗幻觉机制
通过引入GRPO(Group Relative Policy Optimization)强化学习框架,FireRed-OCR建立了四大奖励机制:公式语法有效性奖励、表格完整性奖励、层级闭合性奖励和文本准确性奖励。这种格式约束优化策略显著抑制了内容虚构、行序颠倒、标题嵌套错误等典型结构幻觉现象,大幅提升了输出结果的可靠性。
(六)、轻量化高效部署
得益于2B参数量的精巧设计,FireRed-OCR在保持顶尖性能的同时具备极佳的推理效率。模型支持本地私有化部署与标准化API接入,可在消费级GPU甚至部分CPU环境下运行,大幅降低硬件资源消耗,完美适配中小企业及个人开发者的实际需求。
三、技术揭秘
(一)、基础架构设计
FireRed-OCR基于Qwen3-VL-2B-Instruct多模态大模型构建,继承了Qwen3-VL强大的视觉理解和文本生成能力。该架构采用视觉编码器-语言模型解码器的经典设计,能够同时处理图像像素信息和文本语义信息,为文档结构解析提供了坚实的多模态理解基础。
(二)、"几何+语义"数据工厂
为解决高质量结构化训练数据稀缺的痛点,研究团队构建了创新的数据生产引擎。与传统随机采样不同,该工厂利用几何特征聚类和多维度标注技术,通过分析文档的版面布局、元素位置、字体特征等几何属性,结合内容语义标签,合成并整理出高度均衡的数据集。这种数据构建策略有效应对了长尾版式分布和罕见文档类型的挑战,确保模型在多样化场景下的泛化能力。
(三)、三阶段渐进式训练策略
FireRed-OCR采用精心设计的渐进式训练流程,引导模型从像素级感知逐步发展到逻辑结构生成:
阶段一:多任务预对齐。同时训练区域检测、区域识别和布局转Markdown三个任务,建立模型对文档空间布局的基础感知能力,使模型学会将视觉元素与文本内容建立初步关联。
阶段二:专项SFT微调。在高质量、标准化的Markdown数据集上进行监督微调,确保模型输出的逻辑一致性和层级表达准确性,规范全图像Markdown输出格式。
阶段三:格式约束GRPO优化。应用Group Relative Policy Optimization强化学习算法,通过格式奖励机制对模型进行深度优化。该阶段强制保证输出结果的语法有效性和结构完整性,实现模型的自我修正能力。
(四)、四大奖励机制详解
GRPO强化学习框架下的奖励机制是FireRed-OCR抑制结构幻觉的核心武器:
- 公式语法有效性奖励:确保生成的数学公式符合LaTeX语法规范,避免括号不匹配、符号错误等问题;
- 表格完整性奖励:验证表格行列结构的完整对应关系,防止表格未闭合或单元格错位;
- 层级闭合性奖励:检查Markdown标题层级标签的正确闭合,确保文档结构树的合法性;
- 文本准确性奖励:提升文字识别精度和内容保真度,减少漏识和错识现象。
(五)、端到端优化架构
FireRed-OCR采用端到端的一体化设计,直接从视觉输入生成结构化Markdown,无需传统OCR的多阶段流水线(检测→识别→版面分析→格式化)。这种架构消除了各阶段间的误差累积问题,显著提升了复杂文档的解析精度和处理效率。
四、基准测试
(一)、OmniDocBench v1.5权威评测
在文档解析领域最具权威性的OmniDocBench v1.5基准测试中,FireRed-OCR取得了**92.94%**的综合得分,在端到端方案中全面领跑。该评测涵盖文本识别、公式解析、表格结构、阅读顺序等多个维度,FireRed-OCR在各项指标上均展现出卓越性能。
(二)、端到端方案对比优势
与同类端到端OCR模型相比,FireRed-OCR展现出压倒性优势:
- 相比DeepSeek-OCR 2高出1.85分
- 相比OCRVerse高出4.38分
- 相比dots.ocr高出4.53分
在表格结构识别子任务中,FireRed-OCR取得了90.31分的优异成绩,显著优于其他端到端方案,证明了其在复杂版面理解方面的专业能力。
(三)、跨量级模型对比突破
更令人瞩目的是,FireRed-OCR在与超大规模通用VLM的对比中实现了"以小搏大"的突破: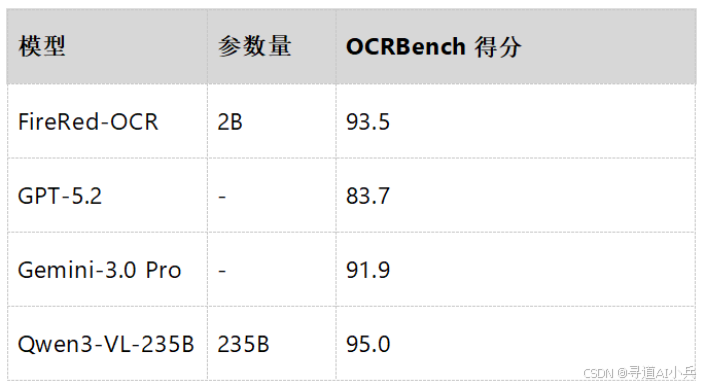
这一结果充分证明,通过专门化的训练策略和架构优化,轻量级专业模型能够在特定任务上达到甚至超越巨型通用模型的性能,为AI模型的高效化发展提供了重要参考。
五、应用场景
(一)、财务报告智能解析
在企业财务数字化领域,FireRed-OCR可高效提取上市公司年报、审计意见书中的多维财务表格与关键指标,生成结构化Markdown文档。这种能力支撑自动化财务建模、数据入库和趋势分析,大幅提升金融分析师和数据工程师的工作效率,降低人工录入错误率。
(二)、科研文献智能处理
针对学术论文场景,FireRed-OCR能够精准识别论文中的公式推导、图表说明、参考文献编号体系,输出符合学术出版规范的Markdown内容。这为文献管理、知识图谱构建、学术搜索引擎开发提供了高质量的结构化数据源,加速科研知识的数字化传播。
(三)、法律文书结构化处理
在法务领域,FireRed-OCR可将扫描件合同、判决书、尽调报告转化为带条款锚点、责任主体标注的可检索Markdown文档。这种结构化处理能力显著提升了法务尽职调查与风险审查的效率,使法律从业者能够快速定位关键条款,进行合规性检查。
(四)、出版物数字化工程
对于出版社和图书馆,FireRed-OCR能够复原纸质书籍、期刊的目录树、章节结构与图文混排逻辑,快速生成支持全文搜索与语义标注的数字资产。这为文化遗产保护、数字图书馆建设和在线教育内容生产提供了强有力的技术支撑。
(五)、教学资源结构化建设
在教育科技领域,FireRed-OCR可自动解析教材例题、试卷填空、课件公式等教学要素,输出适配LMS平台(如Moodle、Canvas)的标准化Markdown教学包。这种能力有助于构建智能化在线教育平台,实现个性化学习路径推荐和自动化作业批改。
(六)、历史档案数字化保护
面向档案馆、博物馆等机构,FireRed-OCR支持批量处理手写笔记、老票据、旧公文等非结构化历史材料,构建具备时间轴、关键词、实体链接能力的智能档案库。这为历史研究、文化传承和档案管理现代化提供了创新解决方案。
六、快速使用
(一)、环境准备与依赖安装
FireRed-OCR基于Python生态构建,使用前需确保环境满足以下要求:
# 安装核心依赖
pip install transformers
pip install qwen-vl-utils
# 克隆项目仓库
git clone https://github.com/FireRedTeam/FireRed-OCR.git
cd FireRed-OCR
建议运行环境配置:
- GPU: 支持BF16精度的NVIDIA显卡(推荐显存≥8GB)
- Python: 3.8及以上版本
- PyTorch: 2.0及以上版本
(二)、模型加载与初始化
使用HuggingFace Transformers库可快速加载FireRed-OCR模型:
import torch
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
from conv_for_infer import generate_conv
# 加载模型(自动下载权重)
model = Qwen3VLForConditionalGeneration.from_pretrained(
"FireRedTeam/FireRed-OCR-2B",
torch_dtype=torch.bfloat16,
device_map="auto",
)
# 加载处理器
processor = AutoProcessor.from_pretrained("FireRedTeam/FireRed-OCR-2B")
# 启用Flash Attention 2加速(可选,推荐用于多图场景)
# model = Qwen3VLForConditionalGeneration.from_pretrained(
# "FireRedTeam/FireRed-OCR-2B",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
(三)、单文档推理实践
以下代码演示如何对单张文档图像进行结构化解析:
# 准备输入图像
image_path = "./examples/complex_table.png"
messages = generate_conv(image_path)
# 构建推理输入
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
# 执行推理
generated_ids = model.generate(**inputs, max_new_tokens=8192)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
# 解码输出结果
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(output_text[0]) # 输出结构化Markdown文本
(四)、批量处理与API封装
对于生产环境部署,建议将模型封装为API服务:
from fastapi import FastAPI, File, UploadFile
import uvicorn
app = FastAPI()
@app.post("/ocr")
async def ocr_endpoint(file: UploadFile = File(...)):
# 保存上传文件
contents = await file.read()
with open("temp.png", "wb") as f:
f.write(contents)
# 调用FireRed-OCR推理
messages = generate_conv("temp.png")
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=8192)
result = processor.batch_decode(outputs, skip_special_tokens=True)
return {"markdown": result[0]}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
(五)、性能优化与量化部署
针对资源受限环境,可采用量化技术降低显存占用:
# 使用8位量化加载
model = Qwen3VLForConditionalGeneration.from_pretrained(
"FireRedTeam/FireRed-OCR-2B",
load_in_8bit=True,
device_map="auto",
)
# 或使用4位量化(需安装bitsandbytes)
model = Qwen3VLForConditionalGeneration.from_pretrained(
"FireRedTeam/FireRed-OCR-2B",
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
device_map="auto",
)
量化后的模型在保持较高精度的同时,显存占用可降低50%-75%,适合在消费级显卡或边缘设备上部署。
结语
FireRed-OCR的发布标志着文档智能解析领域进入了一个新的发展阶段。通过"通用VLM到专业结构化专家"的范式创新,小红书团队证明了专门化训练策略相比简单参数堆叠的显著优势。这款仅20亿参数的轻量级模型不仅在权威评测中登顶SOTA,更以开源姿态为整个行业提供了可复现、可商用的高质量解决方案。
对于开发者而言,FireRed-OCR提供了低门槛、高效率的文档数字化工具;对于研究者而言,其"三阶段渐进优化"和"格式约束GRPO"等技术方案为多模态模型专业化训练提供了宝贵参考;对于企业用户而言,Apache 2.0协议确保了技术的无障碍商用。随着文档数字化需求的持续增长,FireRed-OCR有望在RAG知识库构建、智能办公自动化、数字资产管理等领域发挥越来越重要的作用。
项目地址
- GitHub开源仓库: https://github.com/FireRedTeam/FireRed-OCR
- HuggingFace模型权重: https://huggingface.co/FireRedTeam/FireRed-OCR
- HuggingFace在线体验: https://huggingface.co/spaces/FireRedTeam/FireRed-OCR
- ModelScope模型权重: https://modelscope.cn/models/FireRedTeam/FireRed-OCR
- ModelScope在线体验: https://www.modelscope.cn/studios/FireRedTeam/FireRed-OCR
- 技术报告论文: https://github.com/FireRedTeam/FireRed-OCR/blob/main/assets/FireRed_OCR_Technical_Report.pdf

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)