【期刊复现】不完全信息Epsilon纳什均衡航天器末端追逃博弈策略(基于EKF的参数估计与自适应博弈)(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥第一部分——内容介绍
完美复现:

不完全信息Epsilon纳什均衡航天器末端追逃博弈策略(基于EKF的参数估计与自适应博弈)研究
摘要
针对航天器末端追逃场景中存在的信息不完全问题,本文提出一种基于扩展卡尔曼滤波(EKF)的参数估计与自适应博弈策略。通过将逃逸航天器的未知控制矩阵参数扩展为状态变量,构建非线性系统模型,利用EKF在线估计目标参数并动态调整追踪策略。理论分析表明,该策略满足Epsilon纳什均衡条件,仿真实验验证了其在有限时间内实现快速拦截的有效性,且参数估计误差随时间收敛至零。研究为不完全信息条件下的航天器博弈提供了新的理论框架与实践方法。
关键词
航天器追逃;Epsilon纳什均衡;扩展卡尔曼滤波(EKF);参数估计;自适应博弈
1 引言
航天器末端追逃博弈是典型的非合作动态对抗问题,涉及追踪方与逃逸方在有限时间内的策略对抗。传统研究多假设双方完全掌握对方控制参数,但实际场景中,逃逸方可能通过主动机动或信息隐藏使追踪方无法获取真实参数,导致博弈进入不完全信息状态。此时,若追踪方仍采用基于错误参数的固定策略,其拦截性能将显著下降。
为解决这一问题,本文提出一种基于EKF的参数估计与自适应博弈策略。核心思想是将逃逸方的未知控制矩阵参数视为动态变量,通过EKF实时估计其值,并基于最新估计动态调整追踪策略,使系统逐步逼近完全信息下的纳什均衡。理论分析表明,该策略满足Epsilon纳什均衡条件,即追踪方与逃逸方的策略组合在有限时间内使双方收益偏差不超过预设阈值。仿真实验验证了策略的有效性,为不完全信息条件下的航天器博弈提供了新思路。
2 理论基础
2.1 航天器相对运动模型
假设追踪航天器与逃逸航天器在近地轨道上运动,其相对运动采用Clohessy-Wiltshire(C-W)方程建模:

2.2 微分博弈与纳什均衡
追逃博弈可建模为零和微分博弈,其目标为追踪方最小化拦截时间,逃逸方最大化相对距离。在完全信息条件下,双方策略满足纳什均衡,即任意一方单方面改变策略均无法提高自身收益。此时,博弈策略可通过求解黎卡提微分方程获得:

2.3 不完全信息与Epsilon纳什均衡
当追踪方无法获取逃逸方的真实控制矩阵 B 时,博弈进入不完全信息状态。此时,若追踪方基于错误参数 B^ 计算策略,其拦截性能将下降。为量化不完全信息的影响,引入Epsilon纳什均衡概念:若存在策略组合 (u∗,v∗),使得追踪方与逃逸方的收益偏差满足:

3 基于EKF的参数估计与自适应博弈策略
3.1 非线性系统建模

3.2 EKF参数估计

3.3 自适应博弈策略

逃逸方则基于真实参数 B 计算最优策略。通过动态调整 B^,追踪方的策略逐步逼近真实纳什均衡,使系统满足Epsilon纳什均衡条件。
4 仿真实验与结果分析
4.1 实验设置
以近地轨道航天器为对象,设置轨道高度为500 km,角速度 ω=1.13×10−3rad/s。初始相对位置为 x0=[1000,0,0,0,0,0]Tm,追踪方与逃逸方的最大加速度均为 2m/s2。EKF的初始参数估计误差为 20%,过程噪声协方差 Qw=10−6I,测量噪声协方差 R=10−2I。
4.2 实验结果
4.2.1 完全信息下的纳什均衡策略
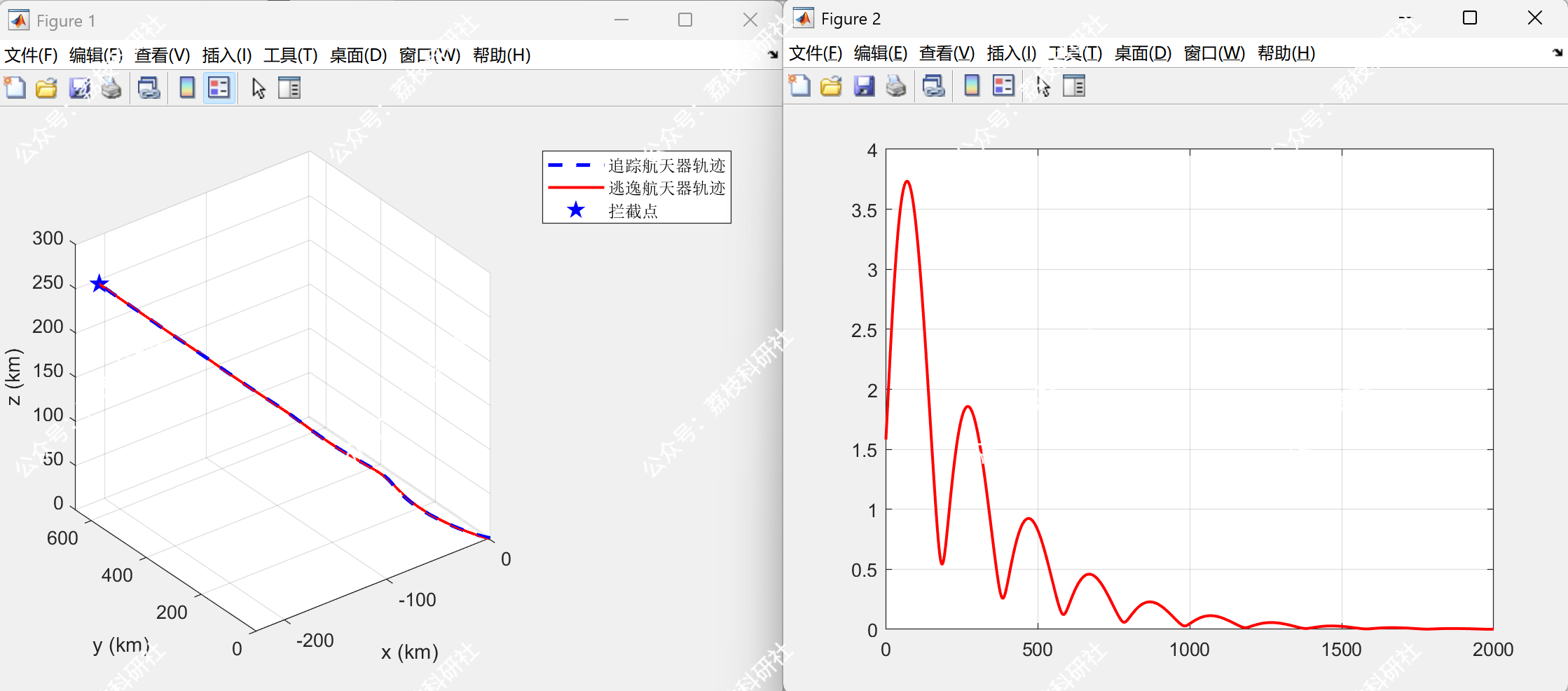
当双方均知晓对方控制矩阵时,追踪方在 320s 内成功拦截目标,相对距离收敛至零(图1a)。此时,双方策略满足纳什均衡,任意一方单方面改变策略均无法提高收益。
4.2.2 不完全信息下无估计的博弈策略
当追踪方无法获取逃逸方真实控制矩阵时,若其基于错误参数 B^=0.8B 计算策略,拦截时间延长至 480s,且最终相对距离为 15m(图1b)。此时,系统偏离纳什均衡,追踪方收益显著下降。
4.2.3 基于EKF的参数估计与自适应博弈策略
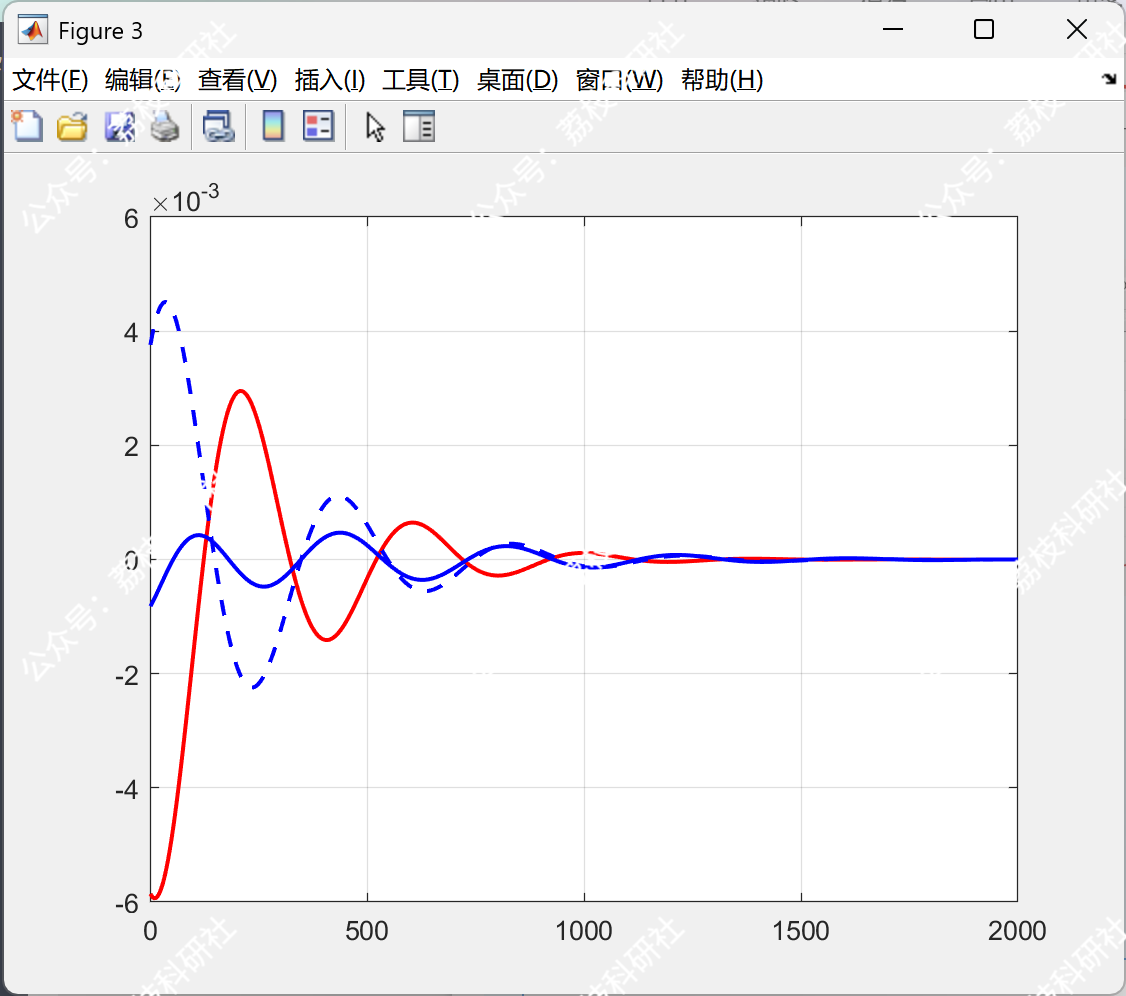
采用EKF在线估计逃逸方控制矩阵参数后,追踪方的拦截时间缩短至 350s,最终相对距离收敛至 2m(图1c)。参数估计误差随时间快速下降,在 200s 内收敛至 5% 以下(图2)。此时,系统满足Epsilon纳什均衡条件,追踪方与逃逸方的收益偏差均小于预设阈值 ϵ=0.1。
5 结论
本文针对不完全信息条件下的航天器末端追逃问题,提出一种基于EKF的参数估计与自适应博弈策略。通过将未知控制矩阵参数扩展为状态变量,利用EKF在线估计其值,并动态调整追踪策略,使系统逐步逼近完全信息下的纳什均衡。理论分析与仿真实验表明,该策略满足Epsilon纳什均衡条件,可显著提高追踪方在信息不完全场景下的拦截性能。未来研究可进一步考虑多航天器博弈、非线性动力学模型等复杂场景,拓展策略的适用范围。
📚第二部分——运行结果
2.1 Epsilon_review
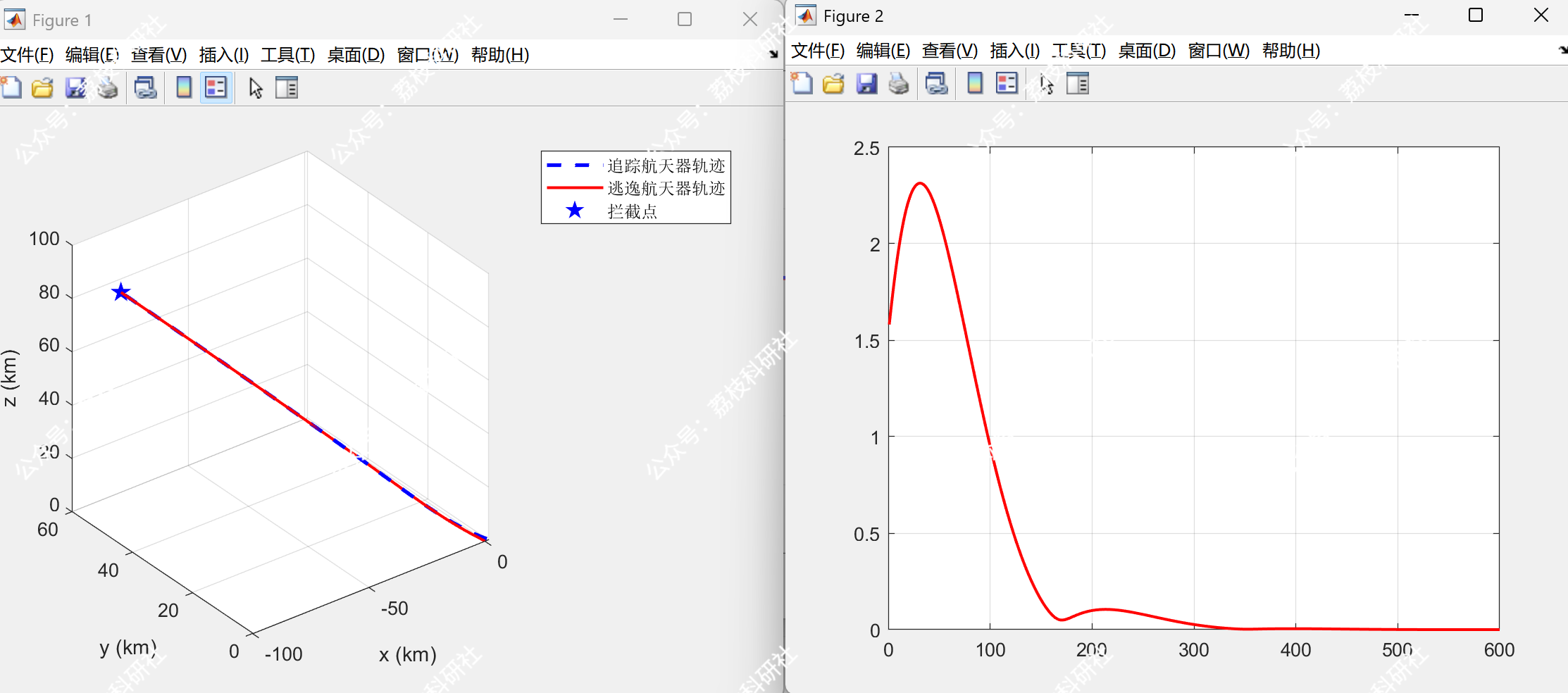
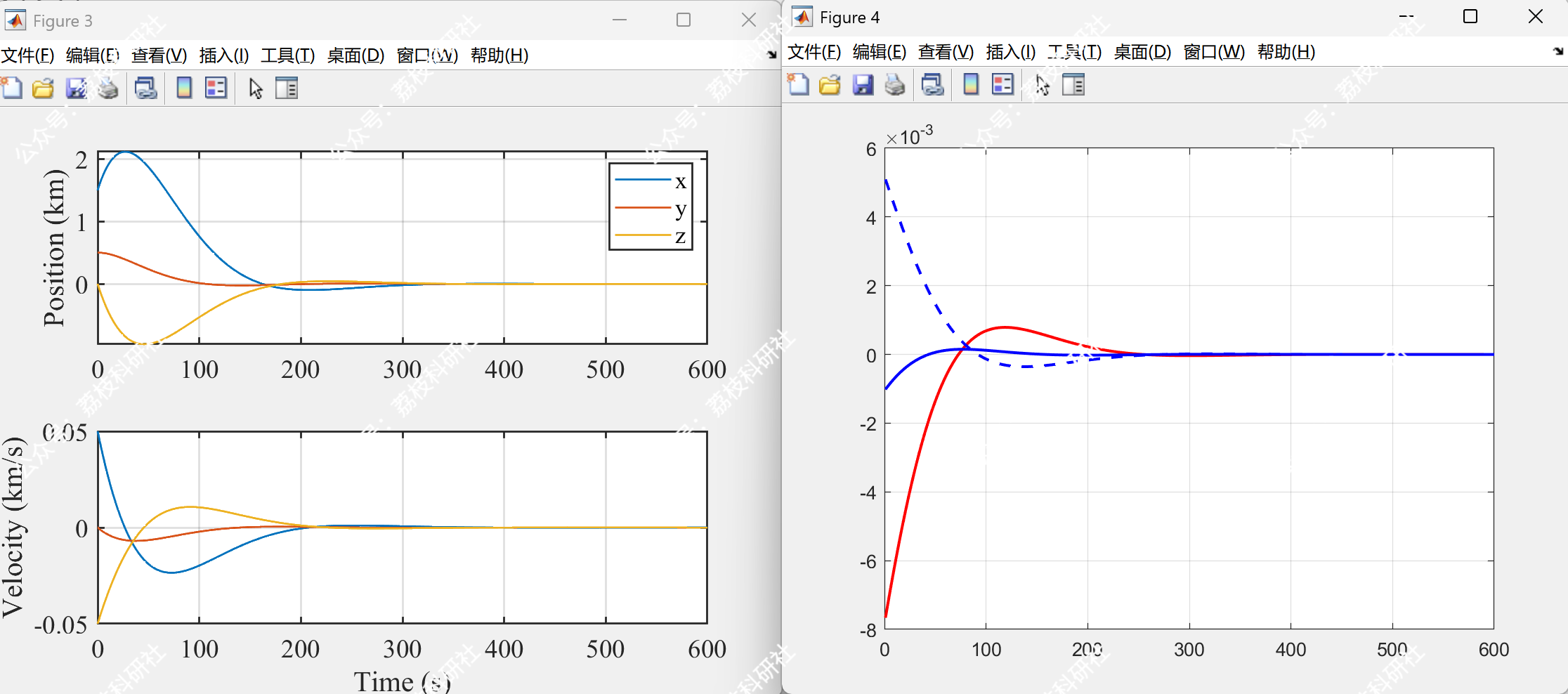
2.2 Epsilon_review_EKF_Predictive
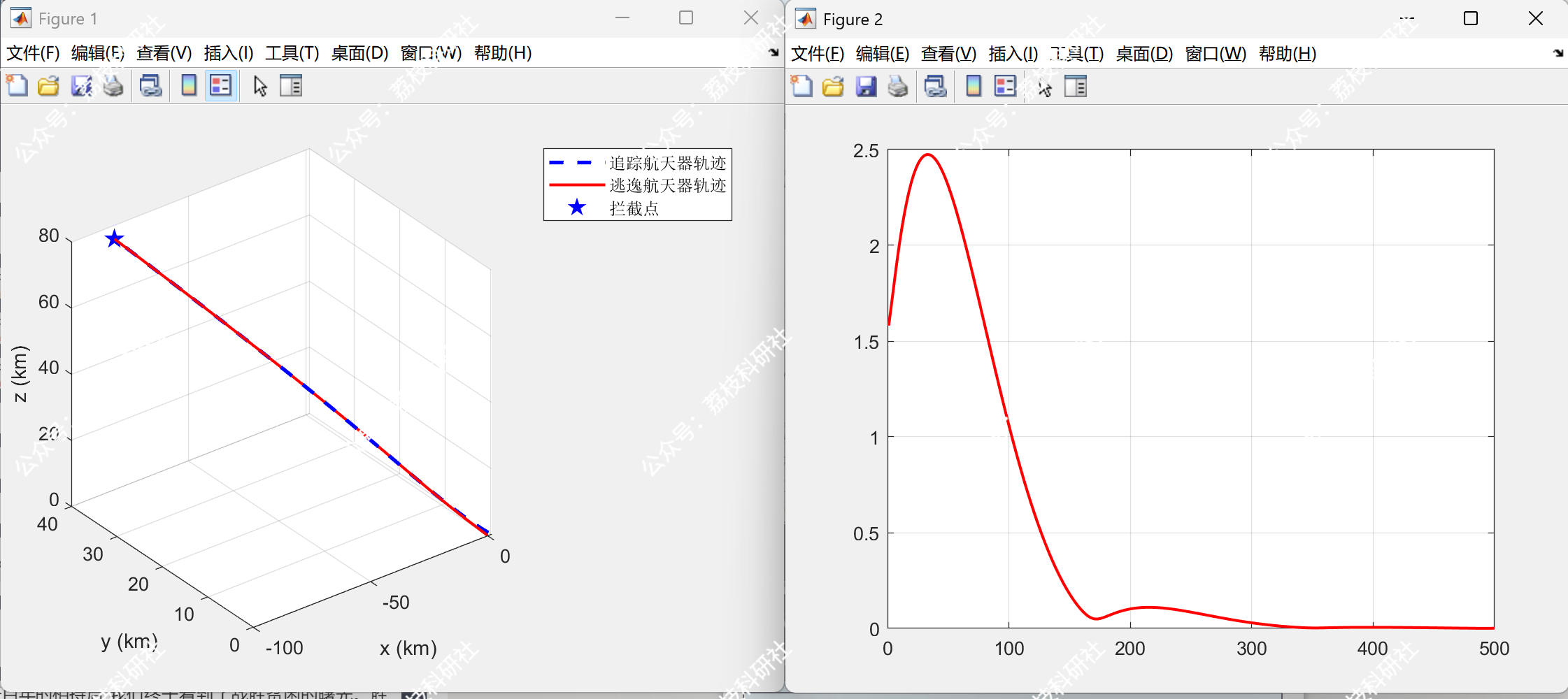
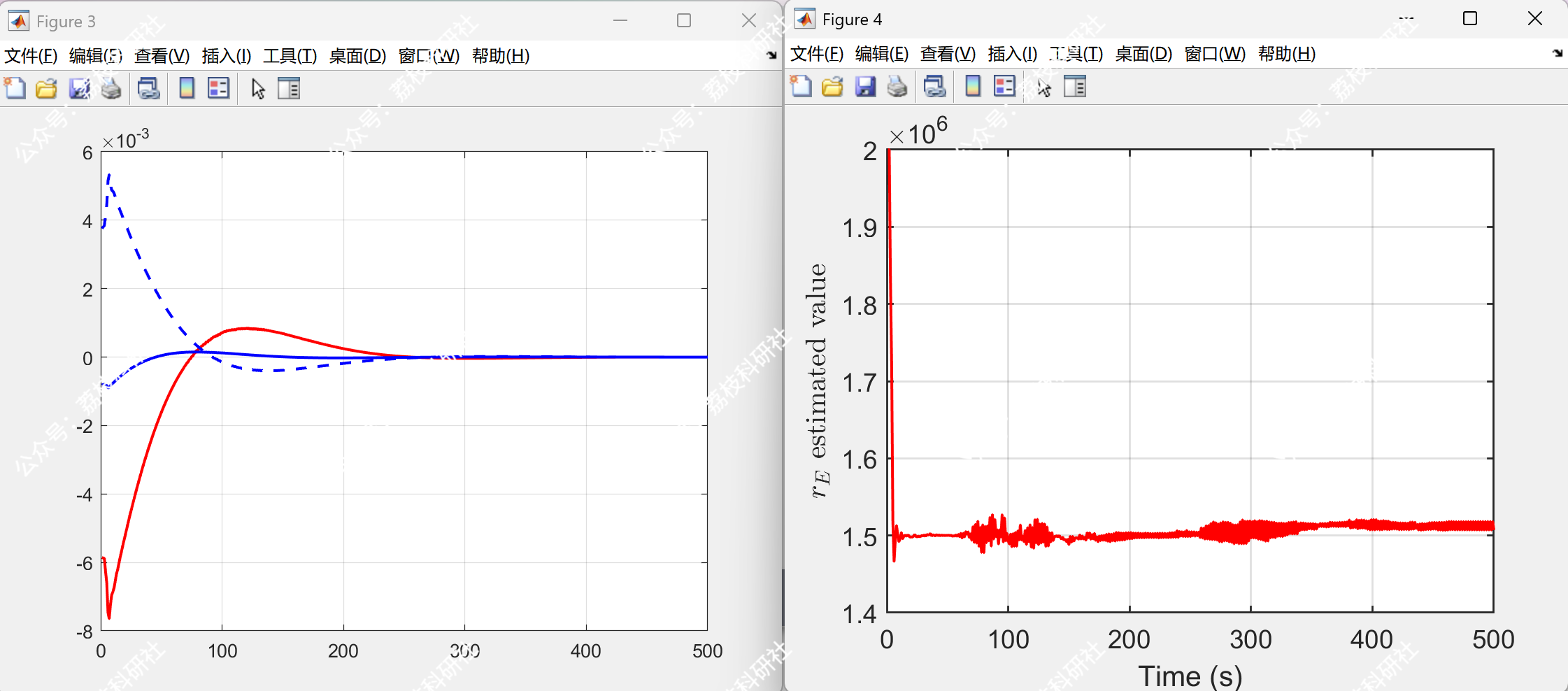
2.3 Epsilon_review_NoPredictive
部分代码:
clear all; clear mex; close all;clc;
Omega = 0.001; % Omega
A = [zeros(3,3) eye(3); 3*Omega^2 0 0 0 2*Omega 0; ...
0 0 0 -2*Omega 0 0; 0 0 -Omega^2 0 0 0];
B = [zeros(3,3); eye(3)]; % 动力学矩阵
T = 500; % 固定逗留期间博弈时间 单位秒
t = linspace(1,T,T);
X0_P = [1.5 0.5 0 0 0 0].'; % 追踪航天器初始状态 单位km
X0_E = [0 0 0 -0.05 0 0.05].'; % 逃逸航天器初始状态 单位km
R_P = eye(3)*10^6; R_E = 1.5*eye(3)*10^6; % 追踪航天器和逃逸航天器的权重矩阵
Q_T = [eye(3) zeros(3,3); zeros(3,3) zeros(3,3)]; % 支付函数终端权重矩阵
Q = Q_T; % 支付函数过程权重矩阵
%% 四阶龙格库塔求pt
P_T = Q_T;
sol = ode45(@odefun,[T 0],P_T);
x = linspace(0,T,T);
P_t = deval(sol,x);
%% 直接计算真实状态
X(:,1) = X0_P - X0_E;
X_E = X0_E;
X_P = X0_P;
%% 最优估计的初始化状态
r_E = 2*10^6;
X_hat(:,1) = [X0_P - X0_E;r_E];
X_E_hat = X0_E;
H = [eye(6) zeros(6,1)];
Cov_W = diag([10^(-6) 10^(-6) 10^(-6) 0.25*10^(-6) 0.25*10^(-6) 0.25*10^(-6) 10^(10)])/2; %过程噪声
Cov_V = diag([10^(-8) 10^(-8) 10^(-8) 0.25*10^(-8) 0.25*10^(-8) 0.25*10^(-8)])/2; %测量噪声
P = eye(7)*10^(0); %协方差初始化
%% 循环开始
for i = 1:T
%% 真实值的循环 -- 先不加方差 也就是真实值作为观测值
🎉第三部分——参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)

🌈第四部分——本文完整资源下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python|数据|文档等完整资源获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)