AI Agent学习日记 Day1
背景
我曾在22年ChatGPT爆火时体验过AI,还养了一个猫娘,但是随着对话的深入,它开始出现幻觉,并且彼时的GPT不能联网,在各个领域也喜欢胡说八道(最典型的是居然不认识cxk!),所以对我而言就相当于一个新奇的玩具,玩了一段时间就放弃了,之后很长一段时间都没有再用过,直到去年deepseek刷爆朋友圈,我就又尝试了一下,才发现原来大模型已经成熟了很多,不但能够获取实时新闻,写的代码也不再是一坨了,用来做翻译也非常准确。但我对于AI的了解和利用也仅限于此,直到26年大年初一和朋友聊天聊到AI的飞速发展,我开始关注过去一年里火遍程序员圈的AI Agent,并在自学一个多月后的今天,开始补充我的学习日记。个人日记,想到哪里写到哪里,主打一个随心所欲。
知识回顾
transformer理解
学AI怎么能绕过transformer呢?transformer架构的来龙去脉就不写了,写一下我的理解吧,虽然我也没完全搞懂。
transformer架构分编码器和解码器两部分,编码器就是将输入内容通过一系列乱七八糟的操作(输入embedding成稠密向量,对向量进行位置编码,N次注意力层→前馈层+残差连接、层归一化)最终转换成一个含义矩阵,解码器就是将这个含义矩阵通过一系列乱七八糟的操作,计算出token表中每一个token的概率,然后在概率最高的前k个token(top-k)中选择一个(温度调节)作为输出,再将输出和含义矩阵继续输入解码器得到下一个token,如此循环,直到解码器输出的下一个token为结束符,这一轮输出就结束。
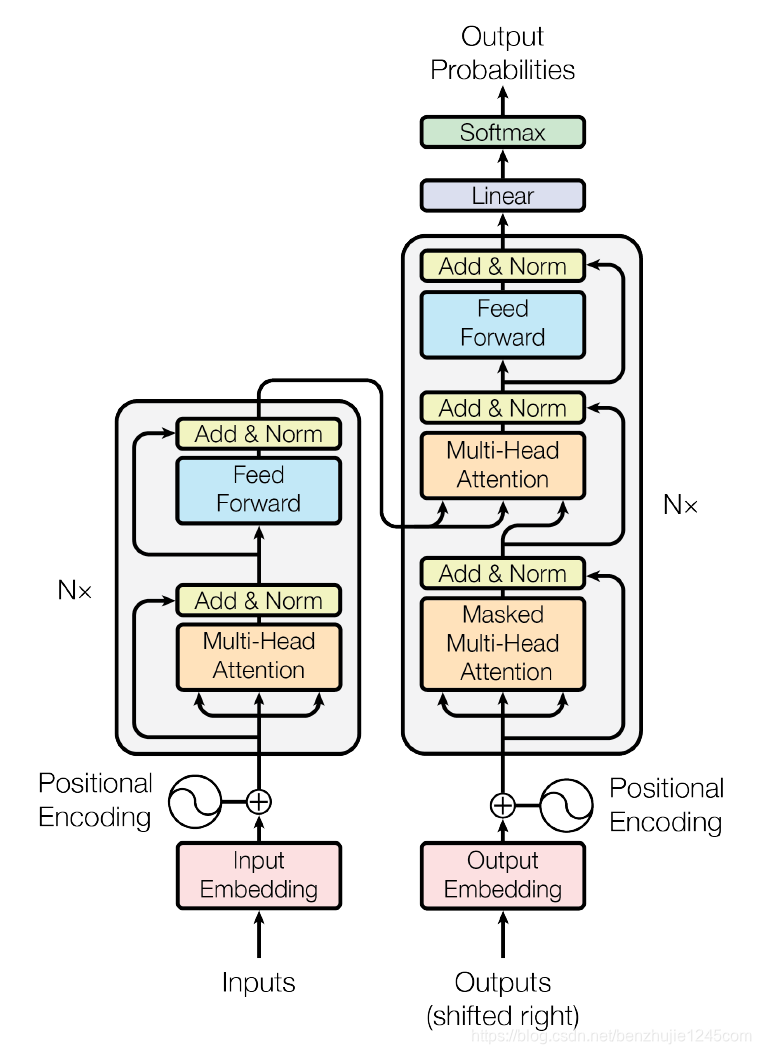
transformer本质上是翻译模型,解码器输出的内容被含义矩阵限定死了。而现在的大模型舍弃了编码器部分,即Decoder-only Transformer,输入时没有了含义矩阵,不再是翻译模型,而是变成了词语接龙,模型不断地输出下一个概率最高的token,最终实现了现在的对话型大模型。
关键组成部分
tokenizer:不属于大模型的一部分,是预处理好的词表,一个token对应一个数字id。
Embedding:用户输入的文本会被tokenizer转换成token id,但是token id本身是没有含义的,于是需要经过词嵌入将token转化为大模型能够理解的多维向量,有多少维度就有多少参数,训练这些参数也是训练大模型的一部分。
Positional Encoding:给每个token添加位置信息。Transformer 的核心是自注意力机制,它是完全并行、位置无关的,比如输入「我吃苹果」和「苹果吃我」,自注意力只会计算 token 之间的关联度,完全不关心哪个 token 在前、哪个在后,算出来的结果是一样的。
Masked Multi-Head Attention:单向 / 因果注意力,只能看当前及之前的 token,看不到后面的。QKV啥的太复杂了,暂且不表。
Add & Norm:残差连接和层归一化。残差连接原理:把子层的输入 x,直接加到子层的输出 Sublayer (x)上,公式:y=x+Sublayer(x),用于解决深度神经网络的「梯度消失 / 爆炸」和「网络退化」问题。Norm是把数值拉到稳定范围,让深层网络训得更稳、更快。
FFN:前馈网络,😵😵😵,现在很多大模型换成了MoE混合专家模型,通过稀疏激活,推理时只激活部分专家,提高了不少训练效率。
Linear:线性层,把模型内部的 d_model 维向量(比如 4096 维),投影到词表大小的长度(比如 32000 维),输出的是一堆原始分数(logits),相当于是Embedding的逆操作。
softmax:一个归一化计算函数,把模型最后算出来的一堆 “裸分”,转换成总和为 1 的概率分布,让模型能选出下一个 token。
学习计划
好了,了解了现代大模型的基石,该正式开始学习AI Agent了。该怎么做呢?第一步当然是问一下AI该怎么学习了。哦不对,在此之前需要搞清楚一些经常听到的名词,AI的兴起造就了许多新词,对于初学者的我来说简直是一团乱麻,令人头大。大语言模型(LLM),Agent,MCP,skills,Langchain,dify,Claude code,openclaw,RAG,PyTorch,LLaMA等等等等,😵😵😵。
好在现在学习知识没有壁垒,不管什么问题直接扔给AI就好,于是我知道了:
第一梯队:理论地基
transformer是一切的地基,是所有现代AI的祖宗,是在17年谷歌的论文attention is all you need里提出的神经网络架构。
第二梯队:大模型底座(毛坯房)
基于transformer的decoder部分训练出来的大语言模型,始于22年发布的ChatGPT,到现在各大厂商的百花齐放,如deepseek,Gemini,豆包,LLaMA等都属于LLM。
第三梯队:开发工具(装修工具&施工队)
PyTorch是最核心的底层框架,所有的LLM底层都是用PyTorch写的。
Langchain是大模型应用的开发框架,PyTorch写出了大模型,而在此之上继续对大模型进行开发则是Langchain做的事,我的终极目标开发一个Agent就需要用到Langchain。
如果说你想做一个Agent却又不会敲代码,那么就可以放弃Langchain改用dify,dify是低代码/无代码平台(相当于装配工),身为计算机科班出身的我当然要用Langchain从0开始写才过瘾。
第四梯队:装修材料
Agent和LLM有什么不一样?差异点就在于LLM像一个学识渊博却没有手脚的人,而Agent就是给LLM装上手脚并提供工具后的状态。MCP,skills,function calling,tools等等就是让毛坯房变成精装房的装修材料。
第五梯队:成品应用(精装房)
Agent就是精装房,Claude code,openclaw这些都属于Agent。
好了,搞清楚了这些名词,也就理清了接下来的学习计划。理论地基transformer我反复看了n遍视频已经有了基本了解,LLM也有基础使用经验,我不需要从0开始训练大模型,所以PyTorch我不需要特意学习,Langchain是必学项,dify可以简单体验一下,各个装修材料必须要理解,成品Agent当然要体验一下,我选择了vscode的插件copilot。
刚好公司有中日英文档互相翻译的需求,之前都是靠人工一句一句发给豆包翻译,再一句一句复制回去,我被一个超长文档折磨得欲死欲仙,CV得手抽筋,痛定思痛决定写一个文档整个翻译的工具,刚好可以用copilot试试水。
当我把需求发给copilot后,它开始思考并哼哧哼哧地干活,不断地创建文件,写代码改代码,调试bug,写测试代码,自己测自己改,我一边惊叹一遍默哀,感觉程序员的天塌了,以后可能都得失业。但是当它写完后,我发现一运行还是有各种问题,然后我给它反馈,它继续改代码,最后直到我的免费token用光了也没解决,我崩溃了。于是我决定改用时下最火的龙虾(openclaw),三下五除二就装好了,不明白为什么网上盛传499装龙虾服务,这不有手就行?我选择了千问的qwen-plus作为底层模型,哦不对,确实还是没那么简单,我记得好像先在安装的时候选择了qwen,但是没有让我填api key,做了一下网页认证,使用的是免费的qwen-portal,然后没说几句话就给我报错
[agent/embedded] embedded run agent end: runId=bce96c24-ef8e-4eae-bf73-19055e2e474c isError=true error=⚠️ API rate limit reached. Please try again later.
API 限流了,于是我想换成qwen-plus,毕竟阿里云百炼给了每个模型100万token的免费额度。按豆包给的操作步骤在OpenClaw 配置面板一通操作,结果老给我报错
Agent failed before reply: Unknown model: bailian/qwen-plus. Logs: openclaw logs --follow
最后我把openclaw.json发给豆包,让它帮忙check,最后才成功配置好。所以还是有一丢丢难度的。
配置好以后,我就开始让龙虾帮我写文档翻译的代码,结果这家伙运行了几分钟一直卡着不动,我让它暂停,并告诉我卡在哪一步,还要求它实时输出正在执行的内容,他嘴上说着好好好,一转头又给我卡着不动,经过5轮对话,我发现我的100万token已经只剩下一半了,而龙虾还啥也没干成。。。垃圾,拜拜了您嘞!
只要思想不滑坡,办法总比困难多。尝试过两个Agent后,我发现最核心的问题在于,成熟的Agent是自主行动的,他的目标是想尽一切办法来实现用户的指令,至于他的行动和想法是不太可控的,而他还没有强大到能够完成我给的所有指令,他遇到问题只会闭门造车,而不会像我求助。我觉得应该反过来,我作为主体,遇到问题向AI求助,这样既能加深我的学习,又让整个工程对我透明,风险和bug都可控。于是我放弃了Agent,转而使用豆包帮我写代码。不得不说,豆包还是挺能干的(当时我还不知道这家伙会坑惨我),他给我的代码很快就跑起来了,使用python-pptx库解析PPT文件,遍历所有有文本的元素,逐个调用千问api key进行翻译,再将翻译好的文本回填回去。可是很快又出现问题了,就是每次翻译的文档不完整,比如PPT只翻译前面两三页,后面就不翻译了,豆包告诉我是因为调用千问api太过频繁,被限流了,于是我加了个time.sleep(delay),每次调用后停顿个2秒,确实解决了。
实现了PPT翻译,接下来就该实现Excel翻译了。
知识回顾先写到这,下次继续
今日日记
今天打算给我的文档翻译工具加上word翻译功能,计划使用win32com来实现,但是word的结构好像要比PPT和Excel更复杂,不仅不好实现并行翻译,甚至目前翻译结束后会丢失图片和目录等元素,之后需要解决这些问题。
同事让我帮忙将JSON文件内容转换成Excel格式,我让豆包给我写了转换代码并成功实现,但我觉得这类小脚本可以使用agent实现,核心是给agent添加两个工具,一个创建本地文档,一个操作CLI,这样就能实现agent自己写脚本自己执行了,不过需要准备沙箱环境,防止agent乱搞。我准备新建一个专门用来做这个的agent,和现有agent结合,搞个multi-agent系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)