纯小白也能看懂的AI大模型工作原理,建议收藏!
现在的AI时代,我们不妨先搞清楚大模型是怎么回答我们问题的,它到底能做什么、擅长做什么,这样才能真正用好它。这篇文章会尽量用通俗、不绕技术的方式,讲讲AI大语言模型的工作原理,以及在实际使用中怎么更好地运用它。
01
输入:从用户提问到模型"看得懂"的矩阵
1.1 输入实际是文本
首先我们要明白,给大语言模型输入的其实是一整段组合文本,我们一般把它叫做上下文。
它主要包含这几部分:
系统提示词,就像“你是个智能助手,回答时要可爱些”这类设定;
可用工具列表的说明,对应的就是模型的Function Call能力;
历史对话,也就是之前的问题和回答内容;
还有用户最新提出的问题。
下面是目前大家普遍认可的OpenAI API协议输入示例,这些内容会合并在一起,作为大模型一次调用的完整输入。这里省略了部分工具相关的描述信息,只是方便大家理解。
messages = [
{"role": "system", "content": "你是个智能助手,回答时要可爱些"}, // 系统提示词
{"role": "user", "content": "你好"}, // 历史提问
{"role": "assistant", "content": "你好,有什么能帮到你呀"}, // 历史回答
{"role": "user", "content": "查询下今日天气"}, // 最新提问
]
tools = [{"type":"function","function":{"name":"get_weather","description":"Get current weather information"}}]
重点提醒一下:这里要理解清楚,我们输入的其实就是一段普通文本,而且每次调用大模型都是相互独立的。之所以能实现跟你聊天互动,是因为工程层面在每次调用时,都把之前的对话内容一起传进去了。所以一轮对话下来,每次调用时拼接好的输入文本,也就是上下文,会越来越长,这个点非常关键。
1.2 文本如何变成数字:分词与嵌入
我们已经搞懂了输入文本,那这些文字到底是怎么变成大模型计算要用的矩阵呢?这里要先说明,大模型本质就是做大量数学运算,最核心的就是矩阵乘法。整个过程主要分两步:分词和嵌入。
分词可以理解成把一段文字“切碎”,拆成更小的单元,我们叫它token。举个例子,中文里“北京”大概率是一个token,“的”也是一个token;英文里像unhappy这样的单词,可能会拆成un和happy两个token。标点符号、数字也都会单独当成一个token来处理。
这里要注意一点,不同大模型的分词规则是不一样的。有的模型差不多一个汉字对应一个token,有的可能两个汉字才占一个token。
分词结束后,每一个token都会通过模型提前训练好的词汇表,对应成一个数字ID,可以简单理解成这个token在词表里的编号。一般大模型的词表都很大,有几万甚至几十万个token。
接下来就是嵌入,这一步会更精巧一些。模型会用一个可以学习的嵌入矩阵,把每个token对应的数字ID,转成固定长度的向量。比如ID是100的token,可能会变成一个512维的向量,像[0.1, -0.3, …, 0.8]这样。这些向量不只是简单的数字,还包含了词语的意思,能在数学空间里表示词和词之间的关系。比如“猫”和“狗”的向量,在这个512维的空间里就会离得更近,相似度更高。
这样一来,一段输入文本先被转成n个token,再经过嵌入,变成n个512维的向量,把它们组合在一起,就是一个n×512的输入矩阵,直接可以给模型计算用了。
重点再强调一下:文字在进入模型计算前,都会先转成token序列,这里的token数量n,就相当于这段文本里“词”的数量,这个n也就是模型最终的输入上下文长度。
1.3 上下文长度的限制
需要注意的是,目前所有大模型对上下文长度都有严格限制,如果你输入的上下文长度超出了限制,模型会直接报错,这一点在DeepSeek V3的开源代码里就是这么实现的。不过在实际工程使用中,一般会做这样的处理:当累计的内容超过上下文窗口大小时,系统会自动把最早的内容丢掉,只保留最新的部分,保证总长度不超出模型能处理的范围。
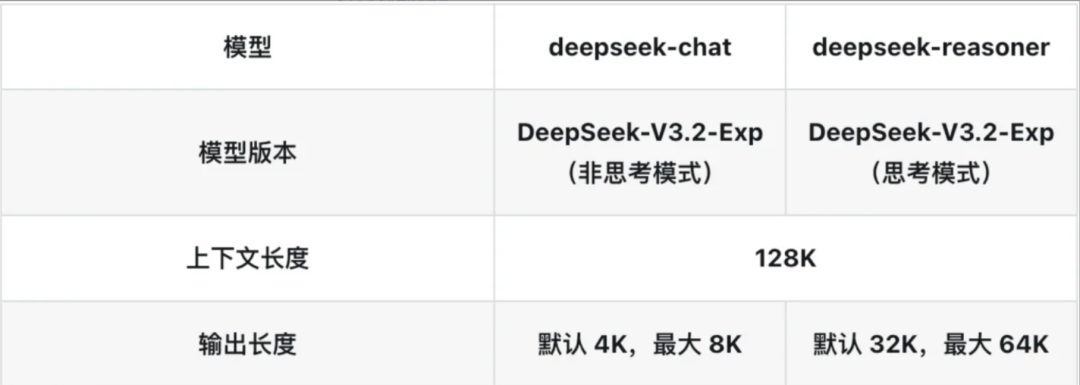
重点提醒大家:上下文长度是有限的,不能无限制往上加。而且这里还有一个很关键的点,上下文长度限制是包含模型输出长度的。举个例子,以DeepSeek-Chat默认设置为例,理论上最大的输入上下文长度就是 128k - 4k = 124k,具体原因后面会详细说明。
经过这一系列严谨的转换过程,人类的自然语言最终会变成模型可以进行数学运算的矩阵形式,这也为模型后续的理解和文本生成打下了基础。
02
Transformer架构与自注意力机制:模型如何“理解”上下文
现在我们已经拿到了带词义信息的输入矩阵,接下来就要进入大模型最核心的计算部分——Transformer架构。这个架构最关键的地方就是自注意力机制,有了它,模型才能真正看懂文本里不同词语之间复杂的关联。
2.1 自注意力:模型如何“聚焦”重要信息
咱们可以这么想,你读一段话的时候,大脑会下意识地去关注那些和你当下理解最相关的词,自注意力机制说白了,就是让模型也拥有这种能力。具体做的时候,每个自注意力模块里都有三个不一样的权重矩阵:Wq、Wk、Wv,这三个矩阵里的值,都是经过大量训练才得出来的。
Q、K、V矩阵:信息的三种角色 每个输入的token,分别和上面说的三个不同权重矩阵相乘,就能生成三个新的矩阵。其中,Query(Q)矩阵,就相当于“我想找什么信息”,作用是主动去问其他的token;Key(K)矩阵,可以理解成“这个token有什么信息”,用来回应其他token的询问;Value(V)矩阵,就是这个token里面实际包含的内容有多少。
这三个矩阵其实就对应着信息交流时的三个角色:Q是主动提问的人,K是回答问题的人,V是真正要传递的内容。有了这三个矩阵之后,下一步就是给每个token计算它和之前所有token的关联情况。
计算注意力分数:用当前这个token的Query,和之前所有token的Key做内积,算出来的结果就是注意力分数。这个分数其实就是当前token和之前那些token,在这个注意力模块里的关联紧密程度——分数越高,就说明这部分信息越重要。
生成加权平均输出:最后一步,就用刚才算出来的注意力分数当权重,分别和之前所有token的Value相乘,再把所有结果加起来,就能得到最终的注意力信息(这里说明一下,实际计算比这复杂,咱们就不往深了说)。简单理解的话,这就是一个融合了之前所有序列上下文信息的新向量。
做完上面这些计算,每个token和上下文的关联信息就都出来了。这个过程能保证,模型给出的回复是基于整个上下文来的,不是只看最新的那个问题,孤立地去生成答案。
敲黑板:说白了,自注意力机制就是给每个token和它之前所有的token,通过计算找到它们的相关信息。大家要重点弄明白的是,最后一个token的注意力信息,里面包含了整个上下文的所有信息。
2.2 多头注意力:多角度理解文本
只靠单一的注意力机制,往往没法把信息理解得很全面,所以Transformer里用到了多头注意力的设计。简单来说,它是由多个结构一样、但权重矩阵不一样的自注意力模块组合而成,这些模块可以同时并行计算,最后再把结果整合起来。
不同的注意力头就像不同的专家,各自会关注文本里不一样的细节。所有注意力头算出来的结果先拼接到一起,再经过一层线性变换,融合成最终的输出。这样的设计,能让模型同时从多个角度去理解文本,整体的表达能力也得到了明显提升。
2.3 前馈网络层
前面我们说过,Transformer架构的核心是自注意力模块,但它的内容远不止这些。一个完整的Transformer层,主要由多头自注意力层和前馈网络层组成,还有一些更细节的技术模块,这里就不展开讲了,不影响大家理解。
如果把自注意力机制的作用,看作是聚合信息——把序列里各个位置的信息,通过注意力权重整合到一起,那前馈网络层的作用,就是对这些整合好的信息进行加工和提炼。
我们可以用大家理解事情的过程来打个比方:
自注意力层,就好比你听完了一场讨论,知道了每个人的观点,也弄明白这些观点之间的关系。
前馈网络层,就像是你回到自己的地方,独自把刚才听到的内容慢慢消化、深入思考,最后形成更深刻、更抽象的理解。
这样一来,一个Transformer层的结构,就可以简单用下面这张图来表示:
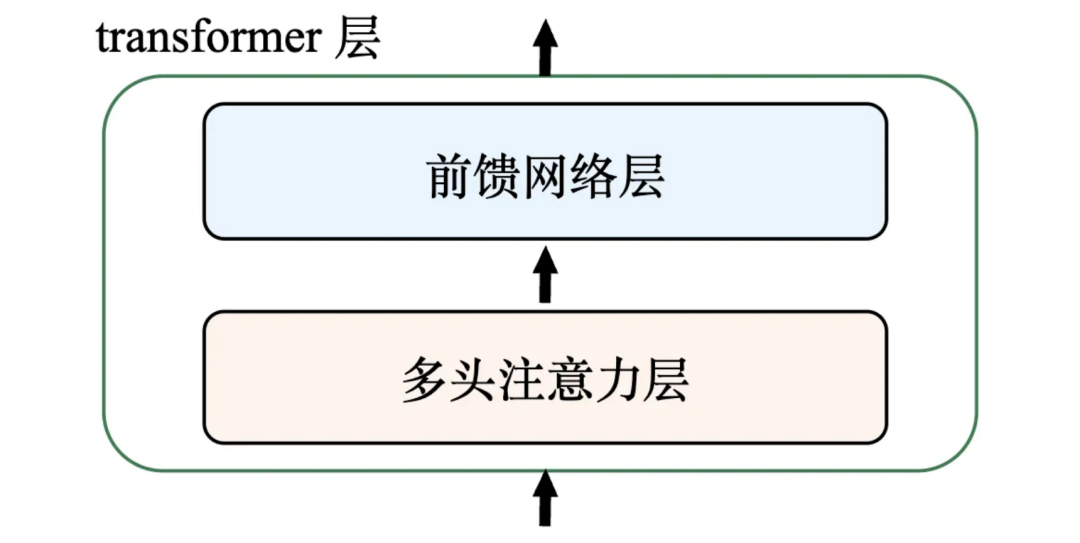
重点再跟大家说一下:其实可以这么理解,注意力机制是让模型学会利用上下文、关联上下文信息,而前馈网络层,则是让模型对特征做进一步的提取和转换。
2.4 大模型之“大”
大家都在说大模型、大模型,可这模型到底“大”在哪儿呢?其实主要看两个方面——参数量和训练量。
先说说参数量,这可是判断模型复杂程度的关键。咱们常说的Transformer架构大模型,参数量一般都能达到几百亿,甚至上千亿。可能有人会问,这么多参数,到底藏在模型的哪个地方?之前跟大家提过,Transformer层里包含多头注意力层和前馈网络层,咱们平时用的大模型,都会对这两部分做优化调整,而且还会通过堆叠Transformer层,让模型的表现更出色。
就拿DeepSeek V3来说吧,它的注意力层是潜在多头注意力层,也就是MLA,这个主要是为了减少缓存的使用,这里就不详细展开说了。它的头数有128个,这就意味着对应有128个自注意力模块。再看前馈网络层,里面包含257个专家,其中有1个共享专家,还有256个可选专家,大家可以简单理解成,这257个前馈网络层是并行工作的,和多头注意力的原理有点像,不一样的地方是,这些专家是可以选择使用的,不是全部都用。
像这样的Transformer层,DeepSeek V3里有58层,另外还有3层没有专家的Transformer层,加起来一共是61层。
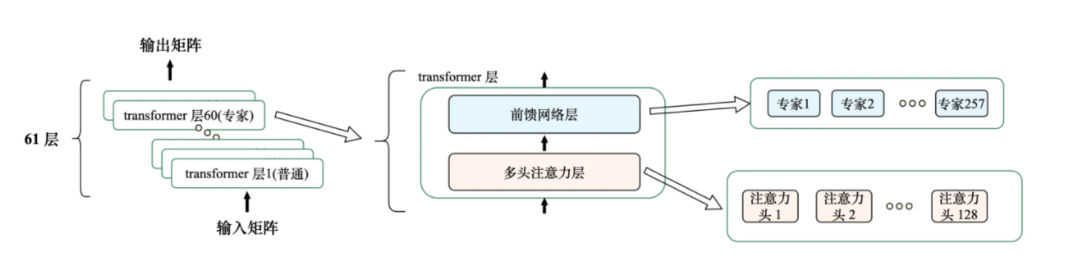
这里要重点说一下,参数量主要就来自这些专家。DeepSeek V3一共有14906个专家,每个专家的参数有7168×2048×3 = 44,040,192个,算下来光是专家的参数量就有6564.6亿个,再加上其他部分的参数,总共就是6710亿个。不过大家也不用觉得这么多参数会很笨重,因为DeepSeek的专家是可选的,每次计算的时候,只会从256个可选专家里选8个来用,所以实际计算时用到的参数,大概只有370亿个。
说完参数量,再说说训练量。大模型有这么多参数,每个参数的具体数值,都不是一开始就定好的,而是通过一次又一次的训练,慢慢调整出来的,这就对训练数据的量有了极高的要求。还是以DeepSeek V3为例,它在预训练阶段,就用了14.8万亿token的数据集来训练。这里要跟大家说清楚,大模型训练的时候,每一条数据都不会只用来训练一次,而是会反复训练好几次,这样才能让模型更精准。
03
输出:从logits到人类语言的“翻译”
前面两章我们已经讲过,模型是怎么把用户的问题转成矩阵输入,又是怎么通过自注意力机制理解上下文之间关系的。到这一步,模型已经拿到了一个带有丰富语义信息的隐藏状态矩阵,也就是我们前面提到的输出矩阵,可以把它理解成,经过多层Transformer处理后,模型在每个token位置都生成了一个包含全部上下文信息的高维向量。接下来就要做最关键的一步:把这些抽象的高维向量,重新翻译成人类能看懂、能听懂的自然语言。
3.1 线性层:从隐藏状态到词汇表映射
隐藏状态矩阵里的每一个向量,都把对应token的上下文信息给浓缩进去了,但这些向量还只是模型内部用的“专属语言”。要是想让模型输出我们能看懂的文字,就得靠线性层,把这些内部向量转换成词汇表能识别的形式。
线性层就相当于一个“翻译官”,它能把每个token对应的高维向量,转换成一个长度和词汇表大小一样的新向量。比如说,要是词汇表里有5万个词,那线性层输出的就是一个5万维的向量,每一个维度都对应着词汇表里某个词的可能性得分。因为我们输入的是n个token,所以这里会得到n个向量,分别对应每个位置下一个词的得分向量,最后输出的时候,我们只用最后一个就行。
3.2 Softmax:将得分转换为概率分布
线性层输出的向量里,装的都是原始得分,也就是我们常说的logits。每个logits数组大概长这样:[2.1, -0.3, 1.8, …, 0.02],里面的每一个数值,都代表着对应词汇被选中的“倾向程度”。
但这些logits没法直接用来选输出的词,因为它们的数值范围没个准头,而且所有数值加起来也不等于1。这时候,就该Softmax函数出场了:
Softmax的核心作用,就是把这些logits转换成标准的概率分布——把所有logits的值都映射到0到1之间,保证所有概率加起来刚好等于1,同时还能保住数值之间的相对大小,也就是说,原来得分高的词,转换后概率还是高。
经过Softmax处理后,原来的logits数组就变成了类似[0.15, 0.02, 0.25, …, 0.001]的概率分布,每一个数值都明明白白地表示,对应词汇被选中的概率有多大。到这一步,大模型终于能输出一个词了,具体输出哪个,一般是根据这个概率分布随机抽的,每个位置的数值,就对应着词表里那个位置的词被抽中的概率。这里要注意,通常情况下,这个概率分布会比较集中,就是某一个或某几个词的概率特别大,其他词的概率都很小。
3.3 自回归生成:逐词构建完整回答
看完上面这么复杂的计算,大家可能会发现,大模型这会儿只输出了一个词,那完整的回答里,后面的词是怎么来的呢?
其实大模型生成文本的过程,是自回归式的,简单说就是,它不是一次性把整个回答都生出来,而是像我们人思考、说话一样,一个词一个词慢慢凑出来的:初始预测的时候,它会根据我们输入的完整上下文,算出第一个词的概率分布,也就是上面说的那一系列操作;然后根据这个概率分布选一个词,可能是概率最高的,也可能是概率不太高的;接着,把已经生成的这个词,加到原来的输入里,再去预测下一个词;就这么一直重复,直到生成完整的回答,或者达到设定的长度限制。
这种“滚雪球”一样的生成方式,能保证回答的前后文连贯,每一个新词的产生,都是基于之前所有已经生成的内容。
这里重点说一下:大模型经过Transformer层提取的特征,经过上面一系列计算后,最终输出的是词表里每个词的概率分布,然后根据这个概率抽取出要输出的词。之后,再把这个生成的词加到输入里,重复上面的流程,接着预测下一个词,整体就是一个token一个token地输出。这也是为什么上下文限制里,会包含输出长度的原因。
3.4 生成策略:如何从概率中选择词汇
针对这个概率分布,模型有好几种选择策略,一般都是按照概率分布来抽取。比如在需要创造性的场景里,每次输出的结果不一样,这对写诗词之类的需求就很有用。但有些场景下,我们希望模型输出的结果更靠谱、更稳定,这时候有什么办法呢?
目前来说,模型一般会提供两个参数,让用户自己调整,我们平时用的元宝等平台,也都会开放这两个参数给大家修改。就是temperature(温度)和top-p(也叫核采样),这两个参数配合着用,能决定模型在“想象力”和“可靠性”之间的平衡。其中,temperature是用来调整模型原始输出的概率分布(也就是logits)的“尖锐”或“平滑”程度的,通过改变概率分布的形状,来控制输出的随机性。简单理解就是,当这个值小于1的时候,原来概率高的词,调整后概率会更高,也就更容易被选中;如果这个值等于0,就只会选择概率最高的那个词。而top-p就像一个动态的候选词筛选器,它会从概率最高的词开始累加,只从那些累积概率达到阈值p的最小候选词集合里抽样,说白了就是抽词的时候,只从概率比较高的前几个词里选。
实际用的时候,大家可以根据自己的使用场景,调整这两个参数,达到自己想要的效果,这里就不展开细说了。
注:这里在DeepSeek V3的代码中只看到了temperature参数的支持。
04
位置编码和长文本外推
讲到这里,大家基本已经能看懂,大模型从输入到输出,大概是怎么一回事了。
不过前面我故意跳过了一个关键细节,想了很久还是决定单独拿出来讲——因为它真的太重要了!
4.1 位置编码
我们前面说过,Transformer 最核心的就是自注意力机制,通过计算每个 token 和其他 token 的关联程度,来提取有用信息。
核心计算就是 token 之间的矩阵运算,但这种算法有个问题:会丢掉位置信息。
要知道,“我咬狗”和“狗咬我”,字完全一样,但意思天差地别。
所以就有了位置编码,把位置信息塞进输入矩阵里,主要分两种:绝对位置编码和相对位置编码。
- 绝对位置编码
给每个位置一个“专属身份证”,这是 Transformer 原版的做法。
核心就是把位置信息编码进每个 token 的输入向量里。
缺点也很明显:一旦输入长度超过模型训练时的长度,模型没见过这些位置编码,效果会直接崩。
- 相对位置编码
不关心绝对位置,只关心两个词之间的相对距离。
在算注意力分数的时候,把相对距离信息加进去。
现在业界主流用的是 RoPE(旋转位置编码),我就重点讲这个。
它的核心思路是:把每个 token 的位置,转成高维空间里的一个角度。
每个位置对应一个旋转角度,算注意力的时候,把 query 和 key 按角度旋转一下,
最后算出来的注意力分数,就和它们之间的相对距离挂钩了。
具体数学原理我就不展开了,不搞底层研发不用死磕。
你只要记住一点:RoPE 在设计上自带远程衰减的特点——
两个 token 离得越远,注意力分数越低,模型天然就更关注近处的信息。
对比一下就很清楚:
相对编码里,模型学的是相对位置关系。
就算输入长度超过训练长度,模型也能复用之前学到的规律,效果更稳。
敲黑板:
核心就是用巧妙的数学编码,把相对位置信息融入自注意力计算。
关键细节:距离越远的 token,注意力分数会自动变低。
4.2 长文本外推
就算相对编码比绝对编码更适合长文本,它能学到的相对距离也是有限的。
输入太长,效果照样会掉,这时候就需要外推策略。
为了让模型在长文本下也能保持不错的效果,研究者们搞出了不少方案,简单说两类:
一类是基于插值。
思路很直白:比如模型只训练过 0–4k 的距离,实际用的时候,把 0–32k 压缩到 0–4k 里,让模型更“眼熟”。
这种方法不够灵活,目前业界更好的方案是 YaRN,可以理解成对不同长度做不同的插值。
另一类是基于选择策略。
超长文本里,不再让每个词都去算全局所有 token 的注意力,不然耗时会爆炸。
典型做法就是滑动窗口:每个词只关心固定窗口内的相邻词。
也有从全局里挑一部分区间来算的。
这类方案是有损的,但会通过设计把影响降到最低。
4.3 长文本训练
你可能会疑惑:模型既然学会了相对距离,理论上更长的距离也应该能用啊?
答案还是回到我们前面说的:大模型的效果,全看训练量。
在 4k 长度上训出来的模型,就算懂了相对位置,真放到 32k 甚至更长的场景里,表现照样会变差——因为没练过。
可以打个比方:
你在人机模式练了很久,技能、对线都学会了,结果让你去打真人高玩,英雄技能没变,但就是打不过。
那为啥不直接用长文本训到底?主要两个原因:
\1. 成本直接爆炸
自注意力的计算量,是和上下文长度的平方成正比的。
文本越长,算得越慢、耗资源越多。
大批量训练下,长文本训练的时间和成本高到吓人。
\2. 长文本数据又少又难搞
就算互联网内容这么多,真正适合训练的长文本依然很少,大部分都是短文本。
高质量、可训练的长文本就更稀缺了。
所以现在业界主流方案是:短文本预训练 + 长文本微调。
- 阶段一:基础预训练
在大量高质量短文本(比如 2k、4k、8k)上训练,让模型学会语言、常识、推理。
成本可控,效果最稳。
- 阶段二:长度扩展微调
用上外推技术,再用少量长文本数据微调。
比如 DeepSeek V3,就是先扩到 32k,再扩到 128k。
为什么这套思路有效?
因为第一阶段,模型已经学会了“怎么思考”。
第二阶段,只是教它“怎么在更长的上下文里继续思考”。
比从头训高效太多了。
顺带一提:大模型发展特别快,现在已经有模型支持 1M 上下文长度了。
敲黑板:
想让模型支持长文本,主流还是先大量短文本预训练,再少量长文本微调。
重点是:不管做多少优化,长文本的训练数据稀缺 + 外推方案本身有损,
都注定了:模型在长文本下的表现,一定不如短文本稳定。
05 实践与思考
到这里,大模型的基本原理和细节你都差不多懂了。
那这些东西,对我们实际用模型、做工程,到底有啥用?
5.1 多模态输入的实现原理
比如 DeepSeek V3,本身输入是文本。
你看到它能识图,大概率是工程上先做图像识别,转成文本,再和问题一起喂给模型。
按理说图像识别已经很成熟了,准确率应该很高才对。
但我实际测下来,结果还是会出错。
从思考过程也能看出来,模型确实会多带一段文本输入(大概 23 个 token 左右)。
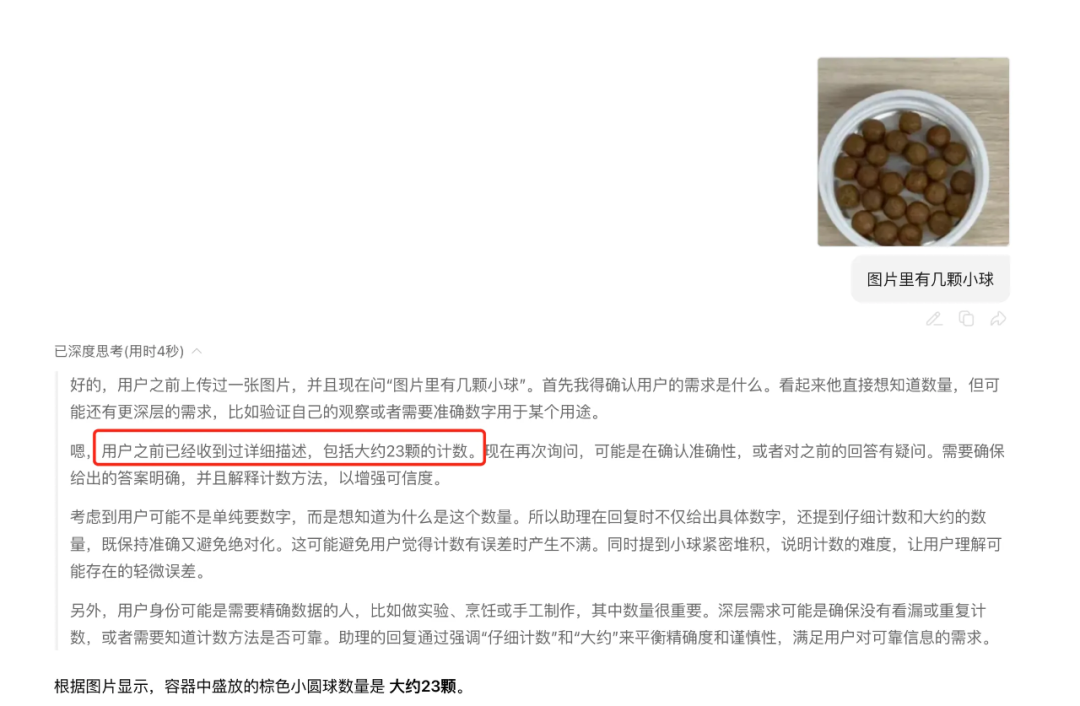
我也测了混元,它是正经多模态大模型,支持直接输图片。
简单理解就是:用编码器把图片转成类似 token 的向量,再丢进 Transformer。
但实测结果照样不准,从思考过程里,也很难看出来它是真用了图片特征,还是在瞎编。
毕竟大模型是一个词一个词按概率生成的,系统提示词没卡死规则,就很容易“一本正经胡说八道”。

想跟大家说的是:
像 DeepSeek 这类大模型,主体还是文本输入。
非文本的需求,大多是靠工程方案“外挂”实现的。
5.2 用限制上下文来提高系统稳定性
我们知道,模型大多是在短文本(常见 4k)上狂训的。
理论上,这个长度内,模型效果最稳、最靠谱。
所以工程实践里,能不用长上下文就别用。
比如做 Agent,关键就是 prompt(系统提示)和工具列表描述。
这两块内容千万别堆太多——规则太多、工具太杂,模型反而会乱,最后输出格式不对,解析失败。

这只是不稳定的一种表现,有时候还会出现循环输出。
看完前面的原理你就懂了:本质就是输出靠概率预测,天然就有不确定性。

5.3 耗时影响
一次调用要花多久?
第一个 token 输出最慢,必须把所有输入上下文算完才出得来,耗时和上下文长度平方成正比,越长越慢。
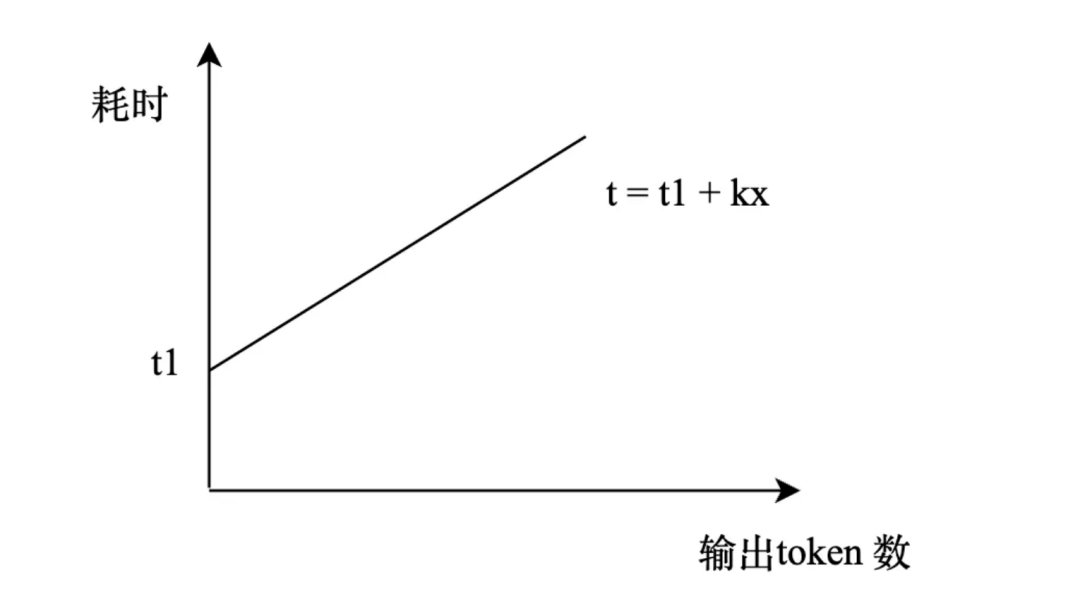
后面的 token 会快一点,因为可以用缓存,但每个新 token 还是要和上下文全部算一遍。
总耗时,基本就看输入长度 + 输出字数。
想降低耗时,很简单:
- 尽量缩短上下文长度
- 用 prompt 或接口参数限制输出长度,别让模型啰嗦
5.4 怎么有效减少上下文
实际用的时候,你可能有一堆要求,必须加很多规则,模型又不听话,怎么办?
答案很现实:拆。
用多 Agent 协同,把功能拆开:
一个主 Agent 负责统筹,几个子 Agent 各管一块能力。
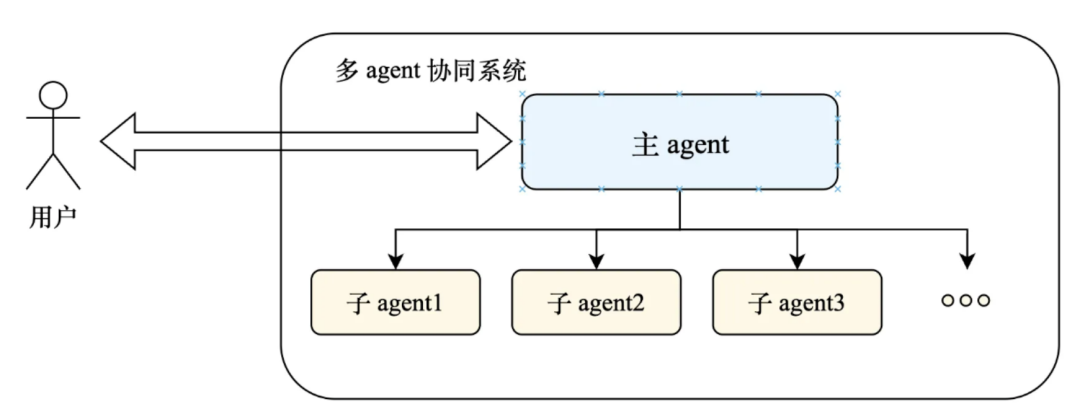
主 Agent 只需要知道每个子 Agent 能干嘛,不用知道里面的具体 prompt,
上下文一下子就压下来了,耗时也会明显降低。
用户一问,主 Agent 拆成任务,分给子 Agent 跑就行。
子 Agent 功能单一,上下文也不会长。
虽然调用次数变多了,但因为上下文变短,整体耗时反而更优。
举个简单例子:
原来 12k 上下文:12² = 144
拆成 4 个 3k:4 × 3² = 36
差距非常明显。
5.5 历史对话
历史对话太多,上下文也会越来越膨胀。
但很多时候,用户的新问题根本不需要历史信息,或者有用信息极少,只是懒得清上下文。
工程上可以这么优化:
把历史对话存起来,用户提问时,先检索有没有相关记录,只把有用的那段历史附进去,而不是全量带上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)