【个人CNN学习记录之神经网络基础】
神经网络基础
主要介绍神经网络一些基础架构及概念
文章目录
前言
在日常工作中,我专注于并行计算领域,主要依托GPGPU、NPU等高算力芯片进行开发。当前,高算力与AI已深度融合,计算与人工智能二者相辅相成:底层计算为实现通用算法与算子提供基础,而AI模型则能反哺并优化传统算法的决策效率与性能。为系统构建这方面的知识体系,我在公司导师的推荐下,跟随up主“霹雳吧啦Wz”的CNN系列视频进行学习,并通过博客记录学习过程,融入自己的理解与总结。
一、CNN架构?
LeNet-5 由 Yann LeCun 于 1998 年提出,是第一个成功应用于手写数字识别的卷积神经网络,奠定了现代 CNN 的基础架构。LeNet-5 虽然小巧,但包含了现代CNN的所有关键要素。理解它是理解更复杂网络的基石。

如图所示,一个CNN结构往往包含输入层、池化层(下采样层)、全连接层、输出层这几层结构。
二、CNN发展

1986年,Rumelhart和Hinton等人发表了具有里程碑意义的论文,明确阐述了反向传播算法。CNN网络虽然巧妙,能够提取图像的局部和空间不变特征,但如果没有BP算法来训练其中的卷积核权重,这个结构无法得到训练。BP是CNN能够被训练、能够学习的唯一途径。
BP+CNN的组合,使得网络可以从原始的像素输入,直接学习到最终的分类输出。整个过程实现了完全的自动化特征工程。在BP算法之前,人们无法有效训练“深度”网络。BP算法通过系统性的误差反馈和梯度计算,自动化了学习过程,使机器能够从海量数据中自我优化。
三、全连接层
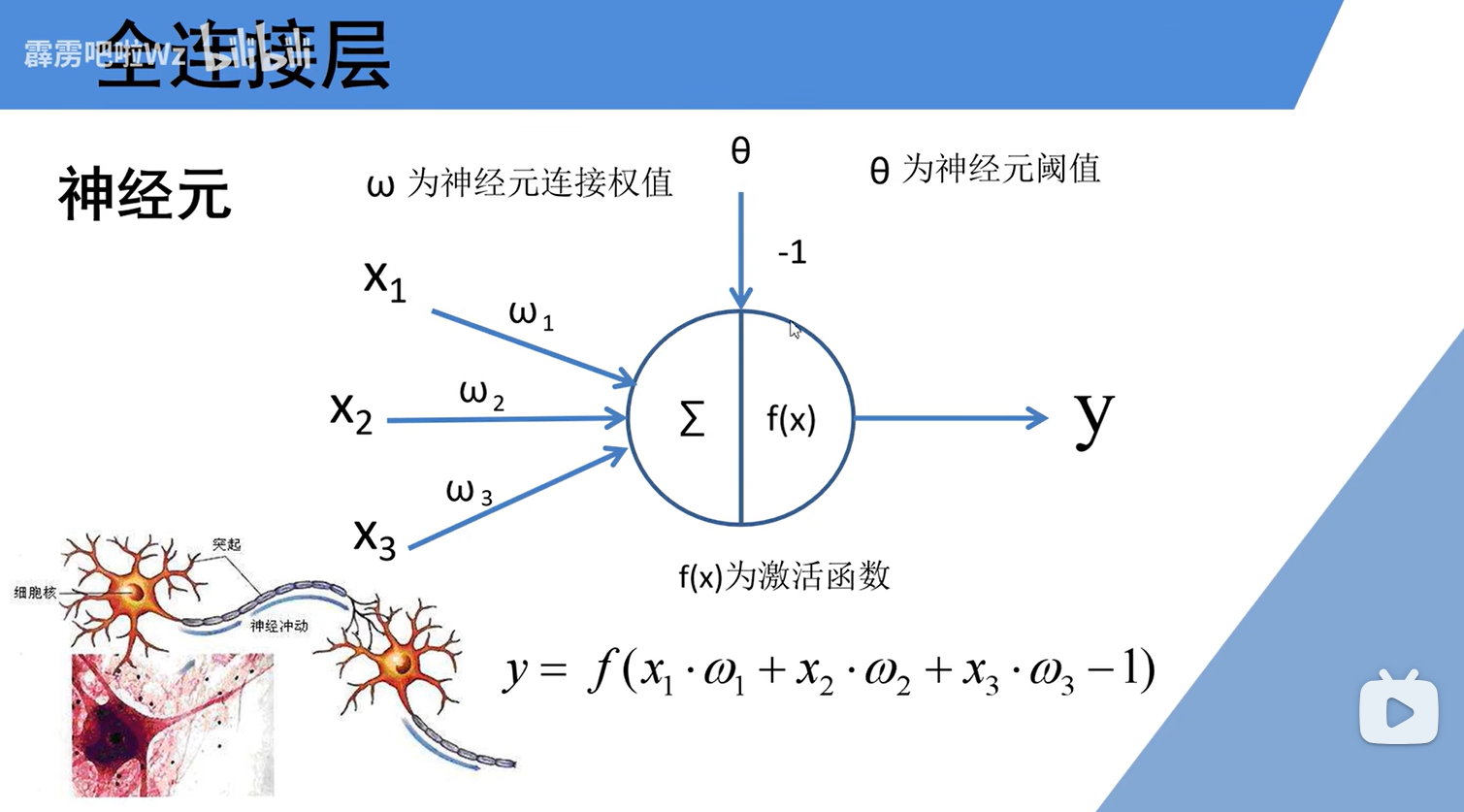
在网络末端,经多次卷积和池化后,特征图被展平成一维向量,输入到经典的全连接层。此时,神经元完全如图中所示工作。末端的全连接层中的每个神经元,都综合了前面所有特征的信息,其权重代表了不同特征对最终判断的贡献度。
输入 → 加权求和 → 加偏置 → 激活函数 → 输出
输入 (x₁, x₂, x₃):来自前一层神经元的输出或原始数据。在全连接层,这里的输入就是经过卷积层计算出的特征数据。
权重 (ω₁, ω₂, ω₃):连接的重要性系数。学习的关键所在,训练过程就是通过大量数据不断调整这些权重,使得整个网络的输出接近预期。
求和单元 (Σ):执行 加权求和:z = x₁·ω₁ + x₂·ω₂ + x₃·ω₃。这一步是线性变换,将输入信息进行综合。
偏置 / 阈值 (θ,图中固定为 -1):一个可学习的常数项。其作用是平移整个线性函数,使神经元能够在未达到某个“激发阈值”时保持静默,为模型提供更大的灵活性。公式中体现为 z + b(其中 b = -θ)。
激活函数 (f(x)):对加权和的结果 z + b进行非线性变换。这是赋予神经网络强大表达能力的关键,主要在于非线性部分。如果没有它,多层网络叠加仍等价于一个线性模型,无法学习复杂模式。常见的激活函数包括Sigmoid、ReLU等。
输出 (y):y = f(z + b)。这个输出将成为下一层某个神经元的输入。
权重(ω)和偏置(b) 是所有神经元通过反向传播(BP)算法不断调整和优化的对象。整个CNN的训练,本质上就是优化网络中所有神经元的这些参数,使网络的整体输出误差最小化。
如图所示,BP包括前向传播和后向传播,前向传播计算误差,后向传播更新权重。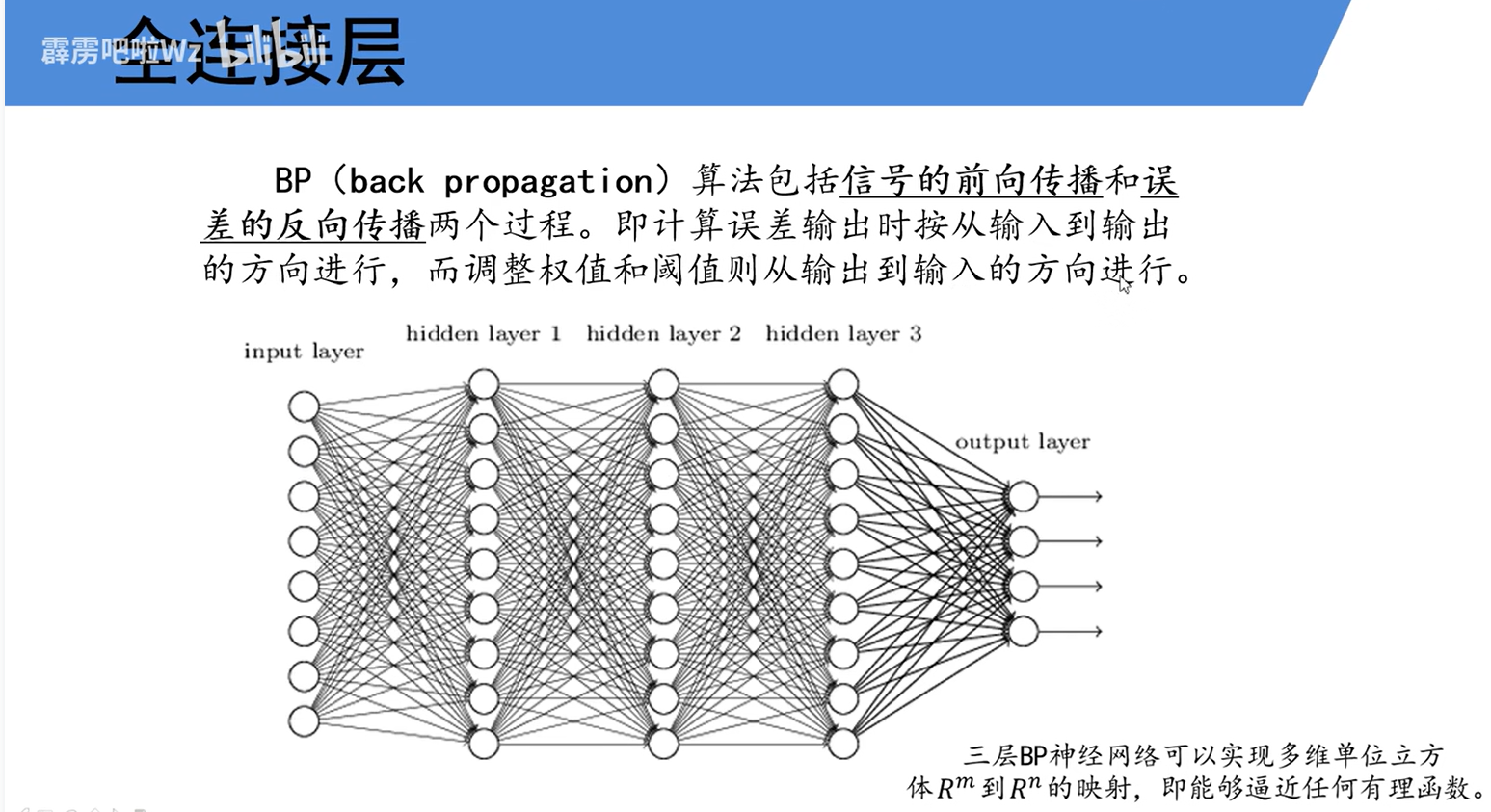
这个图刚出现的时候让我一下有点晕。。把hidden layer当池化层了,发现怎么都对不上。后来才发现这是为了介绍BP而展示的三层BP神经网络。与CNN网络不通,他的每一层的每一个神经元都与下一层的所有神经元相连。这种方式在CNN中一般只在全连接层这么用。
四、实例展示
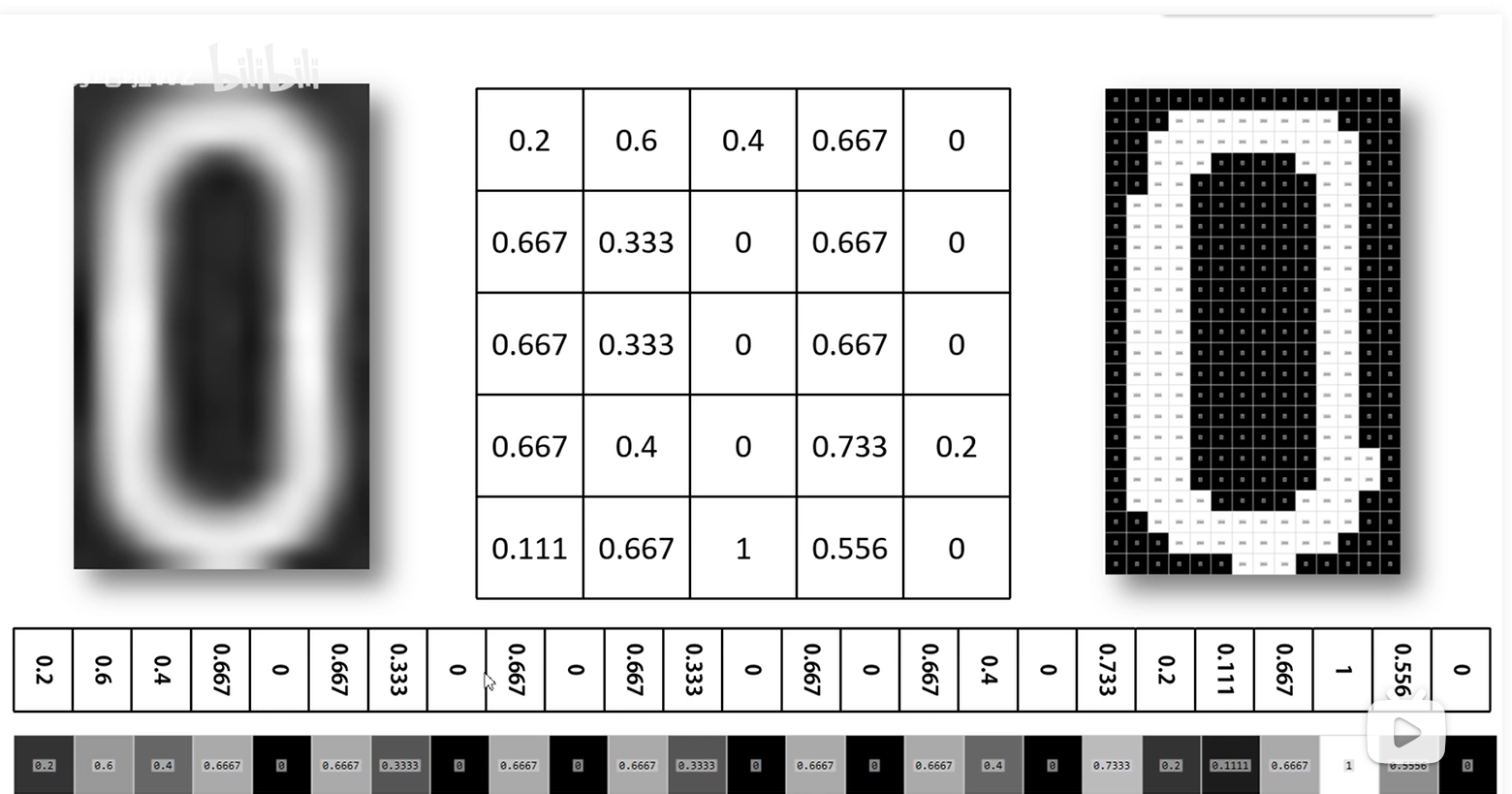
图中展示了一个手写数字识别的实例,首先一幅图每个像素点都有对应的RGB值,通过灰度化得到黑白后的一个维度固定值,在通过卷积层,下采样层等得到最终的特征矩阵,将特征矩阵展平得到特征向量。
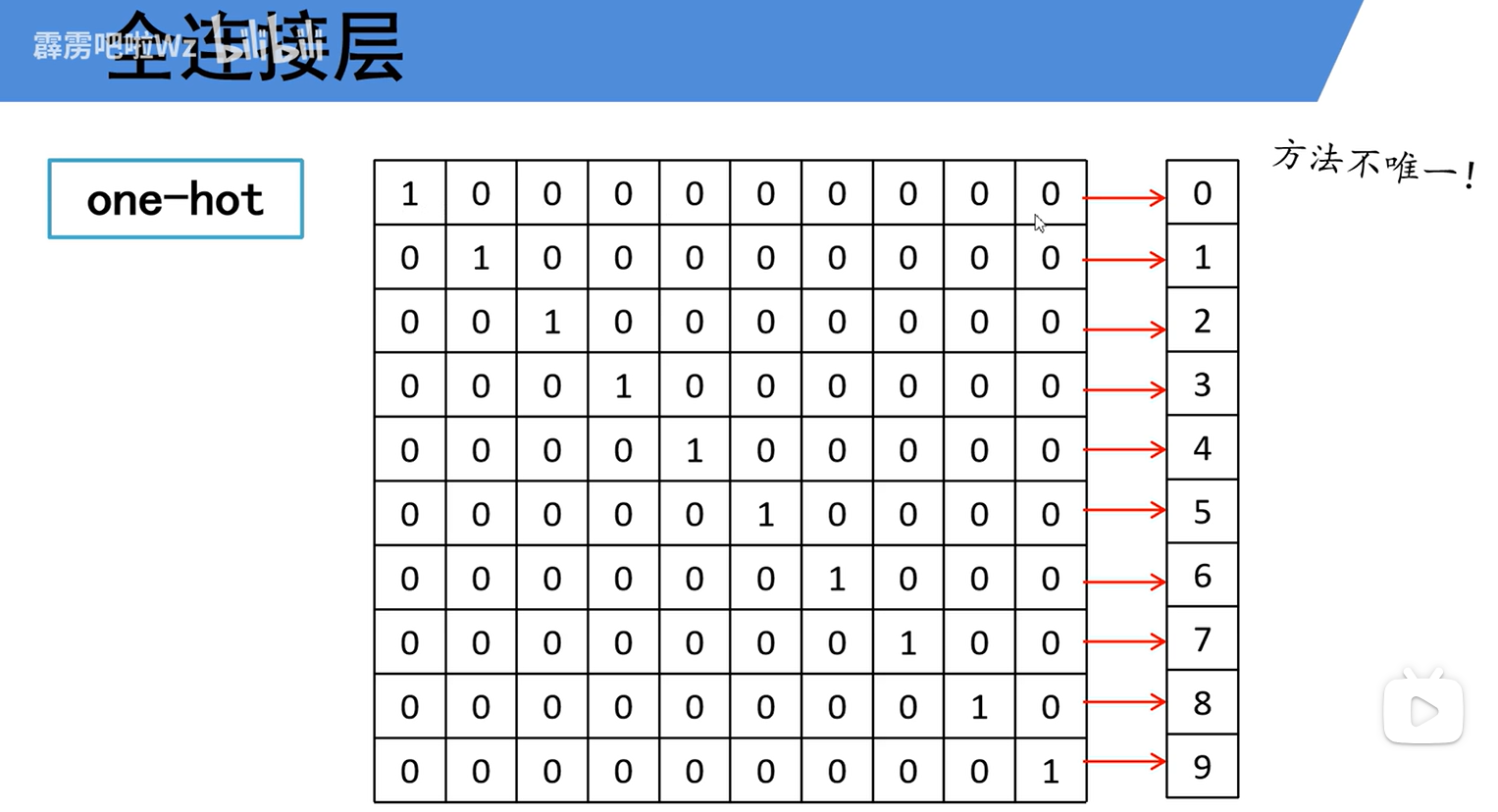 One-hot编码是一种将类别标签转换为机器更容易处理的数值格式的方法。专门用在网络的“末端”——即计算损失函数。方法就是用一个仅有一位是1,其余位都是0的二进制向量来表示一个类别。
One-hot编码是一种将类别标签转换为机器更容易处理的数值格式的方法。专门用在网络的“末端”——即计算损失函数。方法就是用一个仅有一位是1,其余位都是0的二进制向量来表示一个类别。
CNN的最终目标是进行预测。为了让它“学会”预测,我们需要告诉它预测得“对不对”,以及“错多远”。这就需要两个东西:
网络的预测输出:一个概率分布。
真实的标签:一个可供比较的标准。
One-hot编码的作用,就是为真实的类别标签提供一个完美的、可计算的“标准答案”格式。
适配输出层:CNN在分类任务末端通常使用 Softmax层。该层会将最后一个全连接层的输出转换为一个概率分布。例如,对于3分类,输出可能是 [0.05, 0.90, 0.05],表示模型认为有90%的概率是“狗”。
便于计算损失:我们需要一个数学上的“距离”来衡量预测概率 [0.05, 0.90, 0.05]和真实答案之间的差距。最常用的损失函数是交叉熵损失。
交叉熵损失的计算,需要将真实标签表示为概率分布。而One-hot编码 [0, 1, 0]正是一个理想的“概率分布”:真实类别的概率为100%(1),其他类别概率为0%。
这样,损失函数就能清晰地计算出模型预测 [0.05, 0.90, 0.05]与标准答案 [0, 1, 0]之间的差异,并给出一个具体的损失值。这个损失值正是反向传播算法的起点,网络根据这个损失值来调整所有权重(包括卷积核的参数)。
五、卷积层
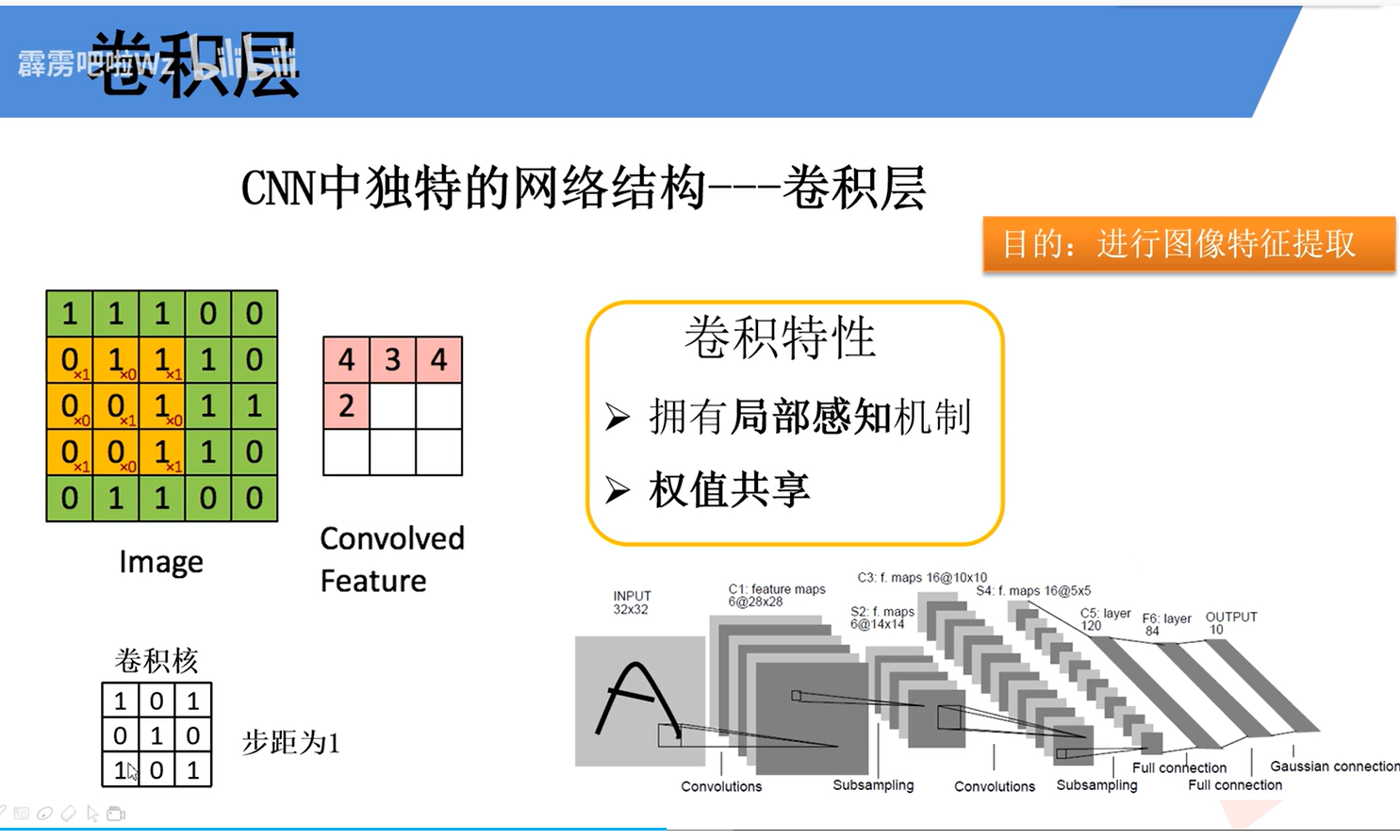
卷积层是CNN的“特征提取引擎”,其核心任务是自动从原始像素中学习并提取出有意义的视觉特征。
输入:一个二维图像矩阵(或上一层的特征图)。
卷积核:一个尺寸远小于输入的小矩阵(如3x3, 5x5),其内部的数值即为需要学习的权重参数。
输出:通过计算生成的新矩阵,称为特征图。
计算过程:
卷积核在输入矩阵上按指定步距滑动。图中标注了 “步距为1”,即每次移动1个像素。在每个位置,卷积核与其覆盖的局部区域进行逐元素相乘后求和,计算结果填入输出特征图的对应位置。此过程遍历整个输入,最终生成特征图。该特征图反映了输入中与卷积核模式相匹配的区域。
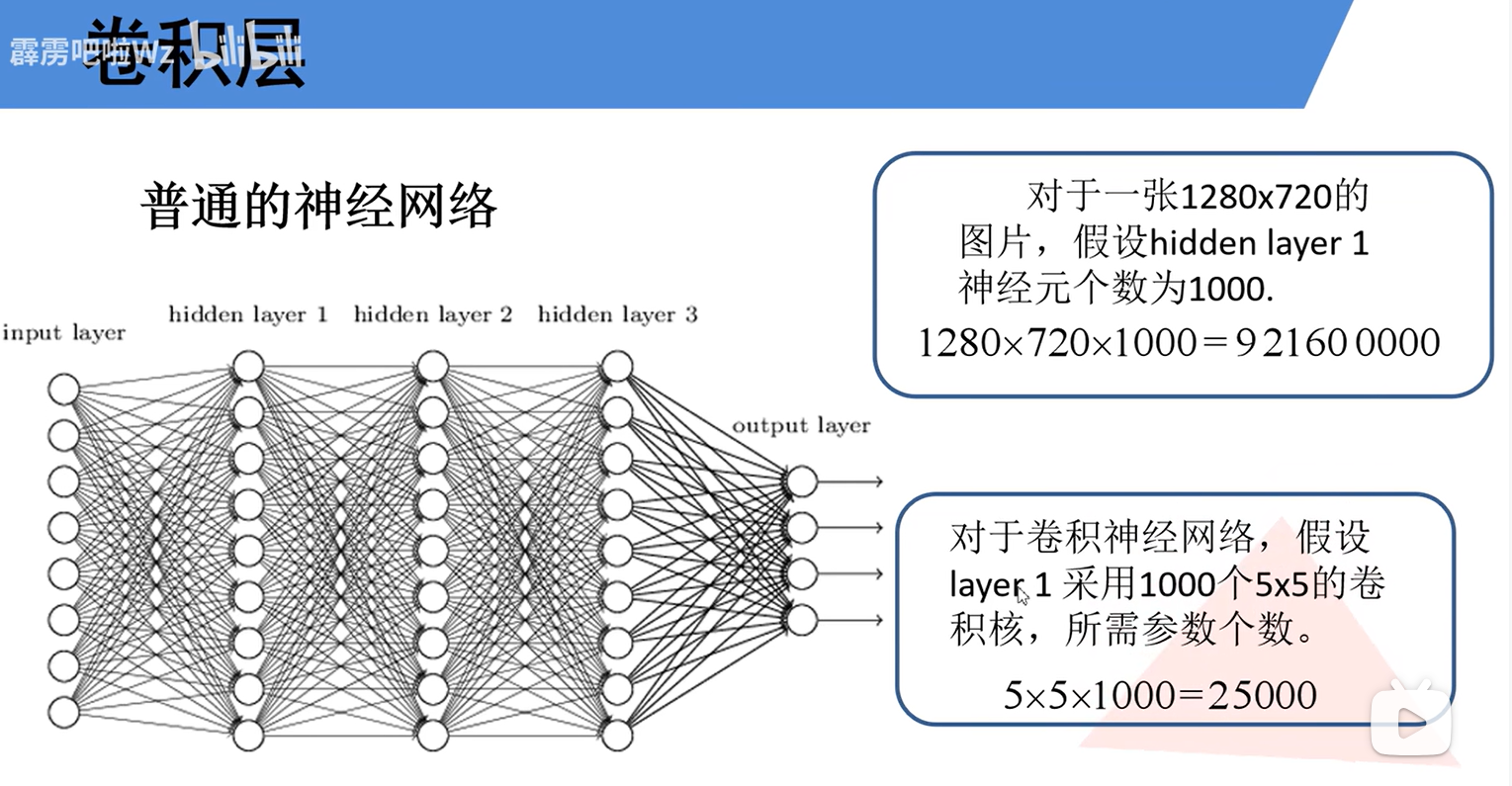
作者还拿普通的神经网络作对比,CNN这种卷积层最大的好处就是减少参数量。卷积层为什么参数少还这么好用?主要在于两点:
局部感知机制
每个神经元(即卷积核在某一位置的输出)只与前一层输入数据的一个局部小区域相连,而非全部输入。仿照生物视觉系统,一个视觉神经元只感受视野中的某一小部分(感受野)。这样可以大幅减少参数数量,降低模型复杂度,并专注于提取基础的局部特征。
权值共享
在滑动卷积的过程中,同一个卷积核的权重参数在整个输入上是固定不变的。极大降低参数量:无论输入图像多大,一个卷积核只使用一组参数。赋予模型平移不变性:同一个特征(如一个边缘)无论出现在图像中的哪个位置,都由同一个卷积核检测,使网络对特征的位置变化具有一定鲁棒性。参数共享意味着卷积层是在用同一种模式(卷积核)扫描整张图像,寻找该模式出现的所有位置。
卷积层有两个重要的输出输出尺寸概念一定要记住,在后面代码的研读中能够感受到这方面的应用:
1、卷积核的channel和输入特征层的channel相同
2、输出的特征矩阵channel和卷积核个数相同。
如VGG网络中
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
这里的channel指维度。
对于输入层,这个值是固定的:
对于彩色图像:通道数 C = 3 (即RGB三通道)。这是绝大多数图像识别任务的输入。对于灰度图像:通道数 C = 1。
对于中间隐藏层,由模型设计者决定,并且逐层变化:
例如:输入(3) -> 卷积层1(64) -> 卷积层2(128) -> 卷积层3(256) -> 卷积层4(512)…
参考上面的代码更加清晰。
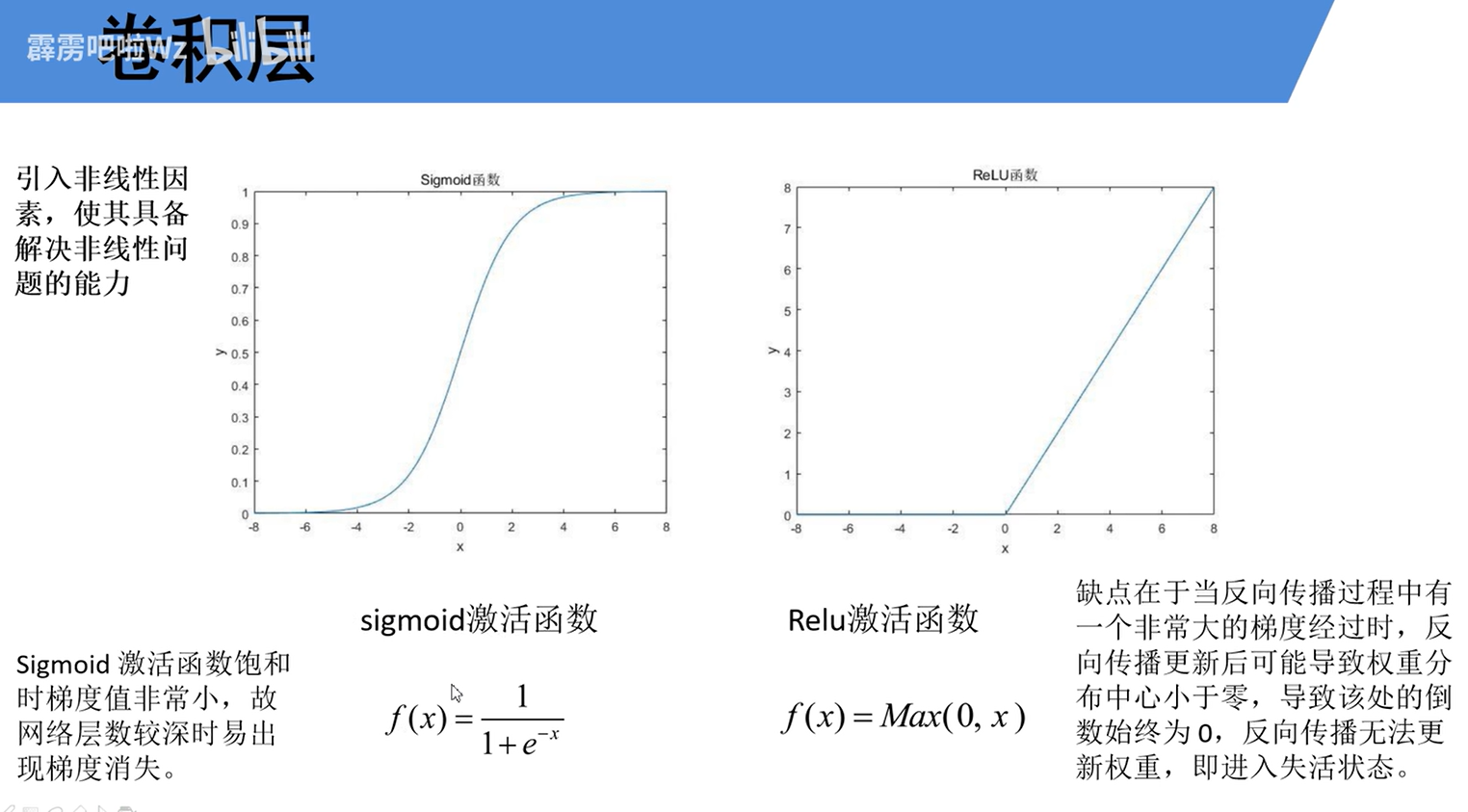
卷积层引入激活函数主要是为了引入非线性因素,让模型具备非线性能力。igmoid易梯度消失,ReLU计算高效但存在失活风险。ReLU在CNN中一般是主流选择,占据了 大部分的应用场景。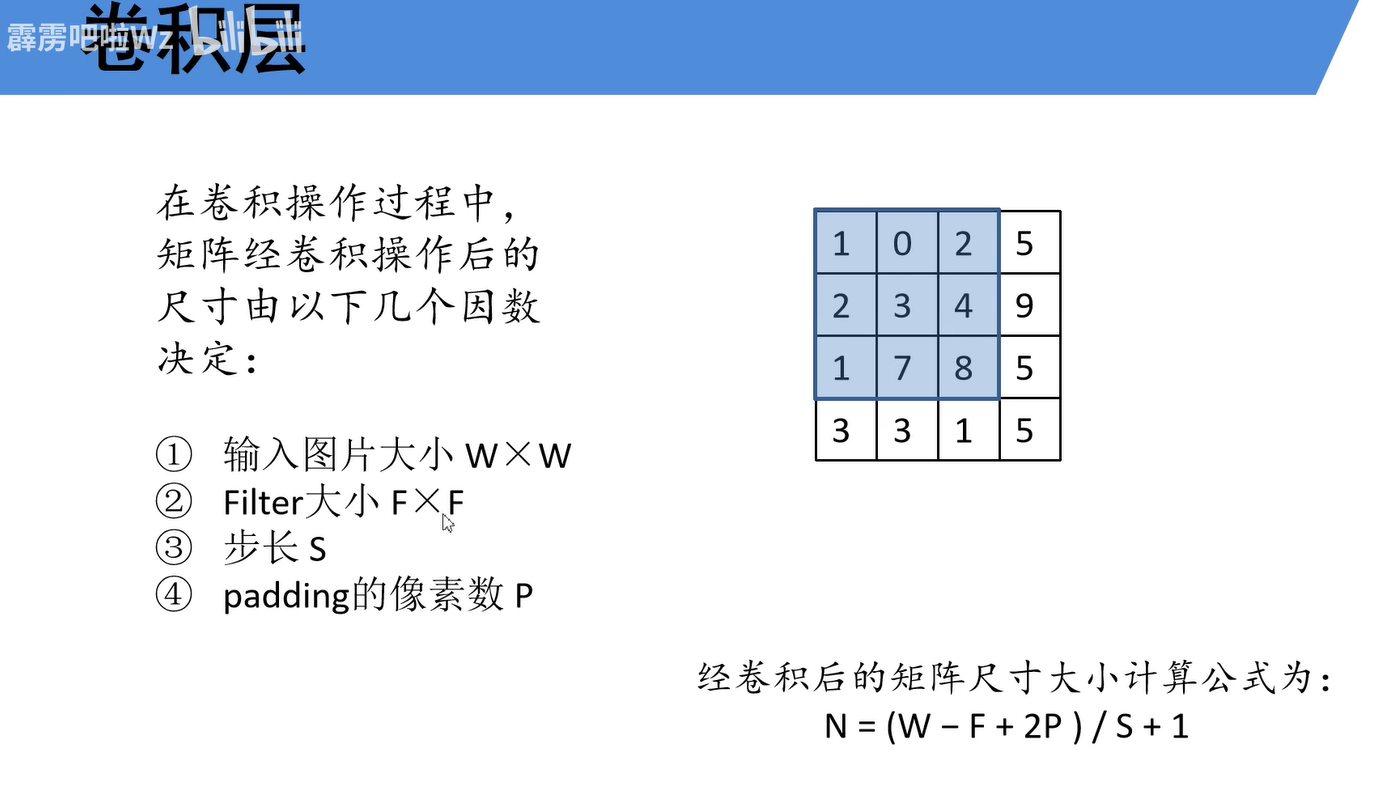
记住这个计算公式N=(W-F+2P)/S+1,W输入尺寸,F卷积核大小,步长S,padding像素数P。根据公式推演几种常用场景:
情况一:标准卷积(无填充,步长1)
设 P=0,S=1
计算:N=(32−3+0)/1+1=30
结果:输出 30×30的特征图。
情况二:保持尺寸卷积(Same卷积,步长1)
设 P=1,S=1
计算:N=(32−3+2)/1+1=32
结果:输出 32×32的特征图,与输入尺寸相同。
疑惑点
1、CNN下的卷积层怎么和信号处理的卷积,卷积的数学性质联系起来?
我觉得可以思考卷积层为什么能提取特征?
对于学习过信号处理的我来说,卷积确实是没少接触,从信号处理的角度看,卷积之所以能进行特征提取,是因为它本质上是一个“加权滑动平均 + 模式匹配”的过程。它利用线性、时不变性等数学性质,对输出结果赋予意义:输出值越大,说明当前窗口的信号与卷积核的波形越相似。这意味着图像中的复杂信号可以被拆解成“边缘+纹理+噪声”的各种线性组合,卷积核就可以单独提取出其中某一种成分。
2、卷积核的初始值?同一个卷积层的各个卷积核初始权重一样的吗?
查了一下一般使用 He 初始化 (Kaiming Normal),这是 CNN + ReLU 组合的黄金标准。且卷积核权重不一样,目的是学习输入数据在不同方面的特征。
# 最常见的写法(默认即针对 ReLU)
conv = nn.Conv2d(in_channels, out_channels, kernel_size)
nn.init.kaiming_normal_(conv.weight, mode='fan_in', nonlinearity='relu')
六、池化层
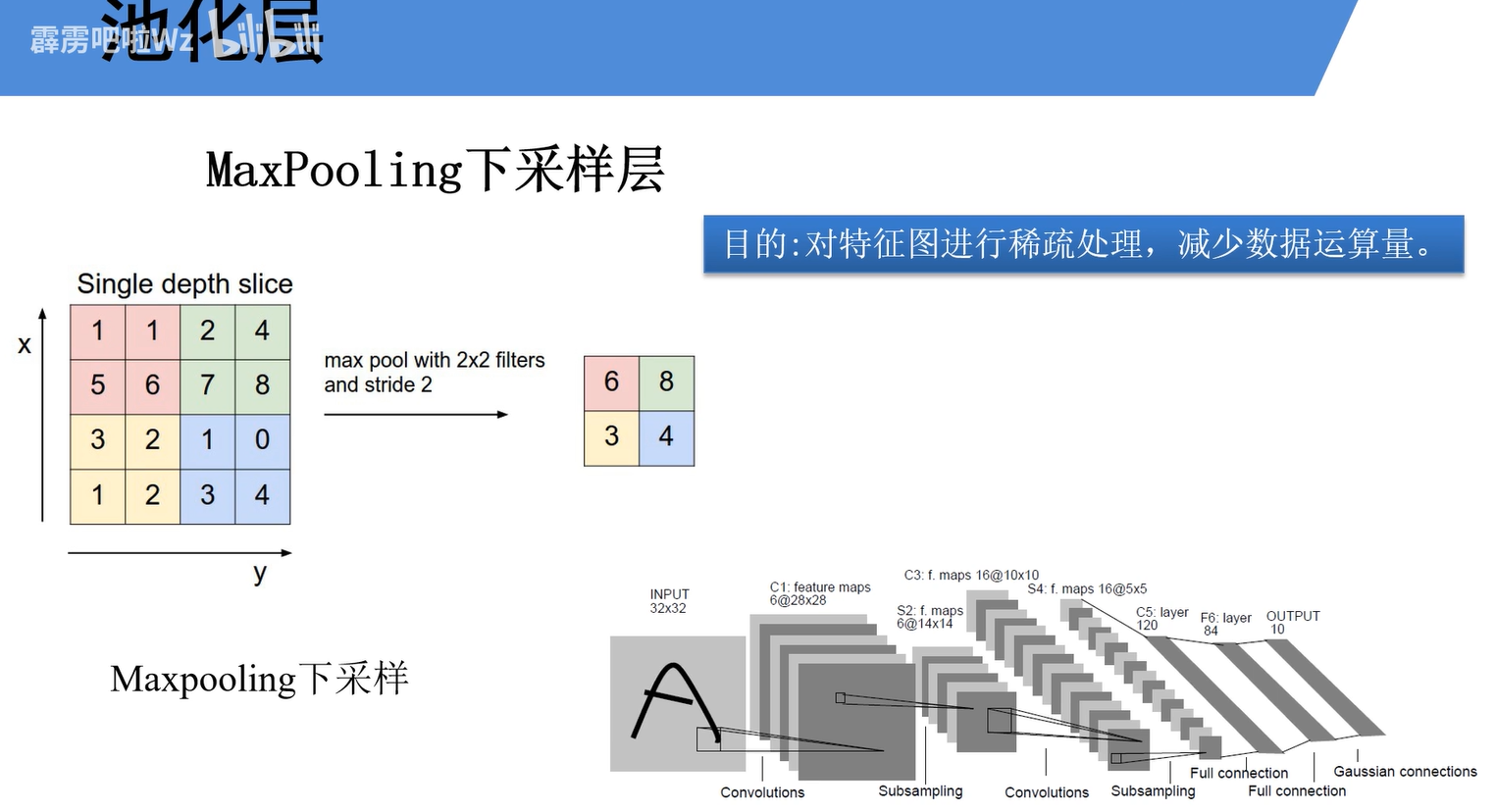

介绍了最大池化下采样层和平均池化下采样层,根本都是为了对图像进行稀疏处理,减少运算量。
池化层具有一些特殊特征:
不改变channel,只改变w和h,一般poolsize和stide相同,这样就可以数据不重叠。
总结
以上就是今天总结的内容,主要是CNN网络整体架构的概念理解,继续加油。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)