机器学习 01高斯混合模型(Gaussian Mixture Model:GMM)_基础知识与认识
公式:

应用:高斯混合模型本质是用多个高斯分布叠加,去拟合任意复杂的数据分布,常用来做聚类、密度估计、数据生成、异常检测等:
第一步:基本认识“高斯模型”:从“一个高斯”开始
什么是高斯分布?
高斯分布就是正态分布,也就是我们常说的钟形曲线。
想象一下你们班的身高分布:
-
大部分同学的身高都在平均值附近(比如165cm)
-
特别矮和特别高的人都很少
画成图就是中间高、两边低的钟形曲线——这就是高斯分布。
一个高斯分布只能描述“一群”数据,比如全班同学的身高。
第二步:为什么需要“多个高斯”?
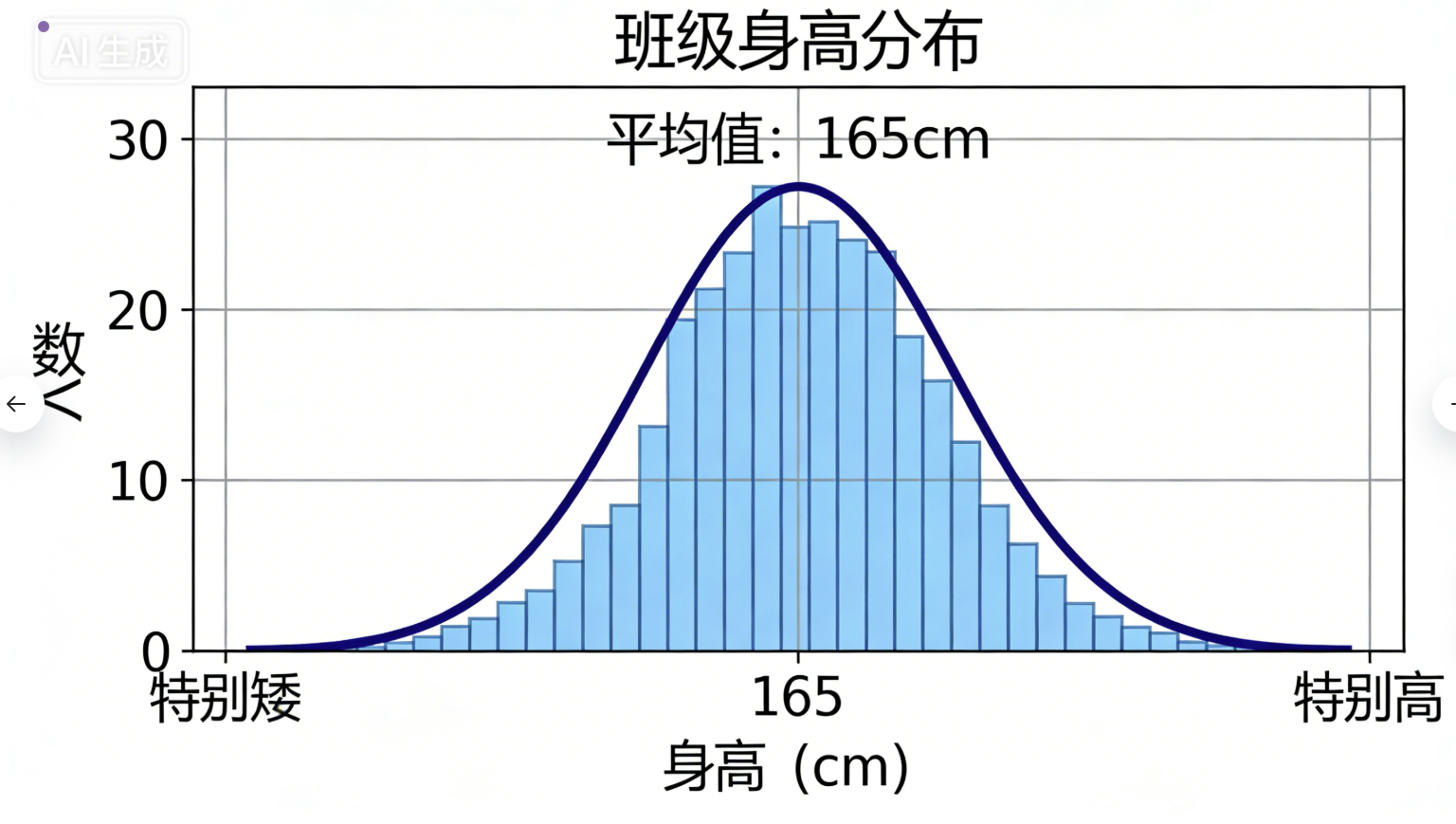
现在想象一个更复杂的场景:
你们学校有男生和女生,你想用身高数据来建模。
男生的身高平均值是 170cm(一个高斯分布)
女生的身高平均值是 160cm(另一个高斯分布)
如果你只用一个高斯分布去拟合所有数据,你会得到一条扁平的、不太准确的曲线。
但如果你用两个高斯分布(一个代表男生,一个代表女生),然后把它们混合起来,就能完美描述整体分布。
这就是高斯混合模型的本质:用多个简单的高斯分布,组合成一个复杂的分布。
第三步:混合模型概念与核心要素
1.什么是混合模型,K是什么意思?
这里出现一个新概念“混合模型”:
混合模型是一个可以用来表示在总体分布(distribution)中含有 K 个子分布的概率模型,换句话说,混合模型表示了观测数据在总体中的概率分布,它是一个由 K 个子分布组成的混合分布。混合模型不要求观测数据提供关于子分布的信息,来计算观测数据在总体分布中的概率。(上述定义来源于:(4 封私信 / 4 条消息) 高斯混合模型(GMM) - 知乎)
我认为这里的混合,它描述的是一种数据生成方式——数据并非来自单一的一个“源头”,而是来自多个不同的“源头”的叠加。
例如,假设我们需要在一个教室里测量所有人的身高。
-
如果教室里只有大学生,身高分布大致是一个钟形曲线(单一高斯分布)。
-
但如果教室里既有小学生,又有大学生,还有篮球运动员,那么总体的身高直方图看起来会有几个“驼峰”。
这里的“混合”就是指:总体的概率分布是由几个不同的子分布(高斯分布)按照一定比例组合而成的。 你无法用一个简单的“平均值”来描述这个群体,因为这是一个“混合群体”。这里这个K,我理解为组成高斯分布的子集。
第四步:高斯混合模型是什么样子,对应的参数意义是什么?
1.高斯模型的公式
基于上述分析,我们知道高斯混合模型可以认为是多个高斯模型“组合而成”,公式如下:
2.混合模型的三个要素与特征(具体的参数表示什么意思?)
假设我们有 2 个高斯分布(K=2):
(1)每个高斯有自己的“位置”和“形状”
-
均值 (μ):这个高斯分布的中心在哪里
-
比如:男生中心在 170cm
-
-
协方差 (Σ):这个分布的“胖瘦”和“形状”
-
比如:男生的身高变化范围是多大
-
(2) 每个高斯有“权重” (π)
-
代表这个高斯分布有多“重要”
-
比如:学校有 60% 是男生(π₁=0.6),40% 是女生(π₂=0.4)
-
所有权重加起来等于 1
(3)每个数据点有“归属概率”
-
GMM 不直接说“这个人是男生”
-
它说:“这个人有 80% 的概率是男生,20% 的概率是女生”
这就是软聚类——不是非黑即白,而是概率化的判断。
第五步:用“学生分组”的类比来理解 EM 算法
如何计算高斯混合模型的参数呢?对于每个观测数据点来说,事先并不知道它是属于哪个子分布。所以借助 EM算法(Expectation-Maximization Algorithm,期望最大化算法)。
(EM 算法:机器学习 01高斯混合模型(Gaussian Mixture Model:GMM)_EM算法-CSDN博客)
假设你是老师,看到一个班级的学生(数据点),但不知道谁是男生谁是女生(隐藏信息)。你想估计:
-
男生的平均身高
-
女生的平均身高
-
男女生各占多少比例

声明:上述内容借助网络资料与ai整理,仅供个人学习并记录,欢迎讨论,敬请批评指正!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)